iPython的优势:揭秘交互式开发的强大力量
发布时间: 2024-06-21 21:39:13 阅读量: 99 订阅数: 34 

ipython交互
# 1. iPython概述
iPython是一个交互式命令行和基于Python的交互式开发环境,它为交互式编程、科学计算和机器学习提供了强大的工具。与标准Python解释器相比,iPython具有许多优势,包括:
* **交互式命令行:**iPython提供了一个交互式命令行,允许用户直接输入Python代码并立即获得结果,从而简化了开发和调试过程。
* **代码自动补全和语法高亮:**iPython提供代码自动补全和语法高亮功能,这有助于减少输入错误并提高编码效率。
# 2. iPython的交互式编程优势
iPython作为一款交互式编程环境,为程序员提供了诸多交互式编程优势,极大地提升了编程效率和开发体验。
### 2.1 iPython的交互式命令行
iPython的交互式命令行提供了类似于Python解释器的交互式环境,允许用户直接在命令行中输入Python代码并立即获得执行结果。这种交互式编程方式极大地简化了代码开发和调试过程。
**代码块:**
```python
# 在iPython交互式命令行中执行Python代码
>>> print("Hello, world!")
Hello, world!
```
**逻辑分析:**
上述代码块演示了在iPython交互式命令行中执行Python代码。`print()`函数将字符串"Hello, world!"打印到标准输出。
### 2.2 iPython的代码自动补全和语法高亮
iPython提供了强大的代码自动补全和语法高亮功能,极大地提高了代码编写效率和准确性。
* **代码自动补全:**当用户输入代码时,iPython会自动补全可能的代码片段,包括函数、变量、关键字等。这可以帮助用户快速找到所需的代码元素,减少输入错误。
* **语法高亮:**iPython对代码进行语法高亮,使用不同的颜色和样式突出显示不同的语法元素,例如关键字、标识符、字符串等。这可以提高代码的可读性和可维护性。
**代码块:**
```python
# iPython的代码自动补全和语法高亮
import pandas as pd
# 自动补全pandas模块中的函数
pd.read_csv()
```
**逻辑分析:**
上述代码块演示了iPython的代码自动补全功能。当用户输入`pd.read_csv()`时,iPython会自动补全`pandas`模块中的`read_csv()`函数。
### 2.3 iPython的调试和错误处理
iPython提供了丰富的调试和错误处理功能,帮助用户快速定位和解决代码问题。
* **调试器:**iPython内置了强大的调试器,允许用户逐步执行代码,检查变量值,设置断点等。这可以帮助用户快速找到代码中的错误。
* **错误处理:**iPython提供了丰富的错误处理机制,包括异常处理、堆栈跟踪等。这可以帮助用户快速定位和解决代码中的错误。
**代码块:**
```python
# iPython的调试器
import ipdb; ipdb.set_trace()
# 在代码中设置断点
def my_function():
ipdb.set_trace()
```
**逻辑分析:**
上述代码块演示了iPython的调试器功能。`ipdb.set_trace()`函数在代码中设置断点,当代码执行到该断点时,调试器将被触发,允许用户检查变量值、设置断点等。
# 3. iPython的科学计算能力
### 3.1 iPython对NumPy和SciPy的支持
iPython与NumPy和SciPy等科学计算库无缝集成,为用户提供了强大的科学计算能力。NumPy提供了多维数组和矩阵操作的功能,而SciPy提供了科学和技术计算的广泛函数库。
```python
import numpy as np
import scipy as sp
# 创建一个NumPy数组
array = np.array([1, 2, 3, 4, 5])
# 使用NumPy进行数组操作
print(array + 10) # 加法
print(array * 2) # 乘法
print(np.sqrt(array)) # 平方根
# 使用SciPy进行科学计算
print(sp.stats.norm.pdf(0, 1, 2)) # 正态分布概率密度函数
print(sp.linalg.inv(array)) # 矩阵求逆
```
逻辑分析:
* 导入NumPy和SciPy库。
* 创建一个NumPy数组。
* 使用NumPy进行数组加法、乘法和平方根运算。
* 使用SciPy计算正态分布概率密度函数和矩阵求逆。
### 3.2 iPython的绘图和数据可视化
iPython提供了强大的绘图和数据可视化功能,允许用户轻松创建各种图表和图形。
```python
import matplotlib.pyplot as plt
import seaborn as sns
# 创建一个Seaborn数据框
df = sns.load_dataset("iris")
# 绘制散点图
sns.scatterplot(data=df, x="sepal_length", y="sepal_width")
plt.show()
# 绘制直方图
sns.histplot(data=df, x="petal_length", hue="species")
plt.show()
```
逻辑分析:
* 导入Matplotlib和Seaborn绘图库。
* 创建一个Seaborn数据框。
* 使用Seaborn绘制散点图,展示花萼长度和花萼宽度的关系。
* 使用Seaborn绘制直方图,展示花瓣长度的分布情况,并按物种着色。
### 3.3 iPython的并行计算和分布式计算
iPython支持并行计算和分布式计算,允许用户在多核处理器或分布式系统上并行执行任务,从而提高计算效率。
```python
import dask.array as da
# 创建一个Dask数组
array = da.random.normal(size=(10000, 10000), chunks=(1000, 1000))
# 使用Dask进行并行计算
result = array.mean().compute()
print(result)
```
逻辑分析:
* 导入Dask并行计算库。
* 创建一个Dask数组,将数据划分为块。
* 使用Dask计算数组的均值,并行执行计算任务。
# 4. iPython的机器学习应用
### 4.1 iPython对机器学习库的支持
iPython与流行的机器学习库无缝集成,包括:
- **NumPy:**用于科学计算和数据操作。
- **SciPy:**用于科学和技术计算。
- **Pandas:**用于数据操作和分析。
- **scikit-learn:**用于机器学习算法和模型。
- **TensorFlow:**用于深度学习。
### 4.2 iPython的机器学习模型训练和评估
iPython提供了交互式环境,用于训练和评估机器学习模型:
- **模型训练:**使用`fit()`方法训练模型,并使用`predict()`方法进行预测。
- **模型评估:**使用`score()`方法评估模型的准确性,并使用`confusion_matrix()`方法分析分类模型的性能。
### 4.3 iPython的机器学习项目管理
iPython还支持机器学习项目管理:
- **代码组织:**使用`%run`和`%load`魔术命令导入和执行外部脚本。
- **版本控制:**使用`%history`魔术命令查看命令历史记录,并使用`%save`魔术命令保存工作区。
- **协作:**使用`%paste`魔术命令与他人共享代码片段。
**代码示例:**
```python
# 导入scikit-learn
from sklearn.linear_model import LogisticRegression
# 加载数据
data = pd.read_csv('data.csv')
# 分割数据
X = data.drop('target', axis=1)
y = data['target']
# 训练模型
model = LogisticRegression()
model.fit(X, y)
# 评估模型
score = model.score(X, y)
print('模型准确率:', score)
```
**逻辑分析:**
- `from sklearn.linear_model import LogisticRegression`:导入LogisticRegression分类器。
- `data = pd.read_csv('data.csv')`:从CSV文件加载数据。
- `X = data.drop('target', axis=1)`:从数据中删除目标列,创建特征矩阵。
- `y = data['target']`:创建目标向量。
- `model = LogisticRegression()`:实例化LogisticRegression模型。
- `model.fit(X, y)`:使用训练数据训练模型。
- `score = model.score(X, y)`:使用训练数据评估模型的准确性。
- `print('模型准确率:', score)`:打印模型的准确性。
# 5. iPython的扩展性和定制化
### 5.1 iPython的扩展机制
iPython提供了一个强大的扩展机制,允许用户自定义和扩展其功能。扩展可以是Python模块、函数或类,它们可以修改iPython的命令行、添加新的命令或修改现有的命令。
扩展可以通过以下方式加载:
- **自动加载:**将扩展放在iPython的扩展目录中(通常位于`~/.ipython/extensions`)。
- **手动加载:**使用`%load_ext`命令加载扩展,例如:`%load_ext autoreload`。
- **配置加载:**在iPython配置文件(`~/.ipython/profile_default/ipython_config.py`)中指定扩展。
### 5.2 iPython的配置文件和环境变量
iPython使用配置文件来存储其设置和首选项。配置文件位于`~/.ipython/profile_default/ipython_config.py`。用户可以修改配置文件以自定义iPython的行为,例如:
- **改变命令行提示符:**`c.InteractiveShell.prompt_in1 = 'MyPrompt> '`
- **启用自动补全:**`c.InteractiveShell.auto_pushd = True`
- **设置历史记录大小:**`c.HistoryManager.history_size = 1000`
此外,iPython还支持环境变量来配置其行为。例如,`IPYTHON_OPTS`环境变量可以用于设置启动iPython时的选项,例如:`IPYTHON_OPTS="--pylab=inline"`。
### 5.3 iPython的第三方扩展和插件
iPython社区开发了大量的第三方扩展和插件,以进一步扩展其功能。这些扩展和插件可以从PyPI或GitHub等软件包管理器中安装。
一些流行的iPython扩展和插件包括:
- **autoreload:**自动重新加载修改过的模块。
- **ipython-sql:**在iPython中执行SQL查询。
- **ipywidgets:**创建交互式小部件。
- **jupyter-nbextensions:**扩展Jupyter Notebook的功能。
通过使用扩展和插件,用户可以根据自己的需要和偏好定制iPython,从而提高其生产力和效率。
# 6. iPython在实际项目中的应用
### 6.1 iPython在数据分析和可视化中的应用
iPython在数据分析和可视化领域发挥着至关重要的作用。它提供了交互式环境,允许用户快速探索数据、执行分析并创建可视化。
#### 数据探索和分析
iPython提供了强大的数据探索和分析功能。它支持NumPy和SciPy等库,可用于数据操作、统计分析和科学计算。例如,以下代码使用NumPy和Pandas库加载和探索数据集:
```python
import numpy as np
import pandas as pd
# 加载数据
data = pd.read_csv('data.csv')
# 查看数据摘要
print(data.head())
# 计算统计指标
print(data.describe())
```
#### 数据可视化
iPython还集成了Matplotlib和Seaborn等可视化库,允许用户轻松创建各种图表和图形。以下代码使用Matplotlib绘制散点图:
```python
import matplotlib.pyplot as plt
# 创建散点图
plt.scatter(data['x'], data['y'])
plt.xlabel('x')
plt.ylabel('y')
plt.show()
```
### 6.2 iPython在机器学习和深度学习中的应用
iPython是机器学习和深度学习项目的理想工具。它提供了对流行库(如Scikit-learn、TensorFlow和PyTorch)的支持,并允许用户交互式地训练和评估模型。
#### 模型训练和评估
iPython允许用户快速迭代机器学习模型。它提供了交互式环境,用户可以在其中调整超参数、探索不同算法并评估模型性能。例如,以下代码使用Scikit-learn训练和评估逻辑回归模型:
```python
from sklearn.linear_model import LogisticRegression
# 训练模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 评估模型
score = model.score(X_test, y_test)
print(score)
```
#### 模型管理
iPython还简化了机器学习项目的管理。它允许用户保存和加载模型、跟踪实验并管理数据集。例如,以下代码使用Pickle库保存和加载训练好的模型:
```python
import pickle
# 保存模型
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
# 加载模型
with open('model.pkl', 'rb') as f:
model = pickle.load(f)
```
### 6.3 iPython在Web开发和自动化中的应用
iPython不仅限于数据科学领域。它还可用于Web开发和自动化任务。
#### Web开发
iPython可以与Jupyter Notebook和Flask等框架结合使用,以创建交互式Web应用程序。例如,以下代码使用Flask创建简单的Web应用程序:
```python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run()
```
#### 自动化
iPython还可用于自动化重复性任务。它提供了与操作系统和文件系统的交互功能。例如,以下代码使用os库创建新目录:
```python
import os
# 创建新目录
os.mkdir('new_directory')
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 iPython 和 Python 之间的异同,重点关注交互式开发环境的优势和局限性。它揭示了 iPython 的交互式开发能力,但也指出了其局限性,并提供了替代方案。此外,专栏还探讨了 Python 的局限性,并建议了替代方案。它还提供了最佳实践,以融合两种工具的优势,并比较了它们的性能、调试技巧、扩展性和在各个领域的应用,包括数据科学、机器学习、Web 开发、自动化、云计算、教育、研究、金融、医疗保健和生物信息学。通过提供全面的见解,本专栏帮助读者了解 iPython 和 Python 的优点和缺点,从而做出明智的决策,以满足他们的特定需求。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电力系统设计:如何确保数据中心的稳定性和效率(IT专家策略)

# 摘要
数据中心作为现代计算的基石,其电力系统设计对于保证数据中心的稳定运行和高效能效至关重要。本文首先介绍了数据中心电力系统设计的基础知识,然后深入探讨了设计原则,包括电力需求理解、动态负载管理、关键参数选择以及高效电力分配的重要性。接着,文章详细分析了数据中心电力系统的主要组件与技术,包括UPS
【速达3000Pro数据库优化速成课】:掌握性能调优的捷径
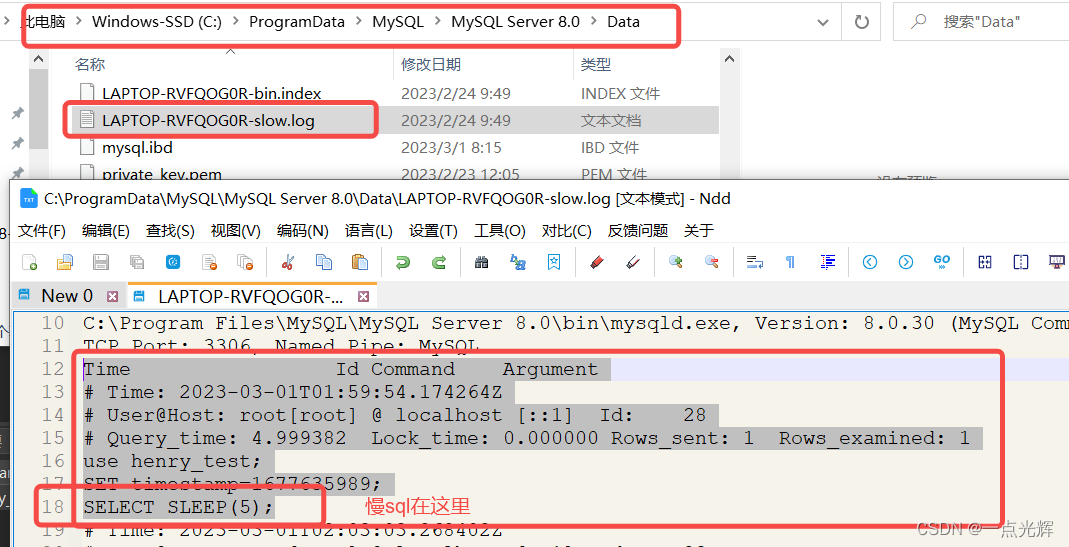
# 摘要
本文围绕速达3000Pro数据库优化技术展开全面探讨,旨在为读者提供入门指导与深入的理论知识。首先介绍了数据库性能调优的重要性,阐述了识别性能瓶颈和优化目标的意义。随后,探讨了数据库设计优化原则,包括数据模型的重要性和正规化与反正规化的平衡。在实践调优技巧章节中,详细讨论了查询优化技术、系统配置优化以及数据库维护与管理的策略。高级优化技术章节进一步涵盖了分布式数据库优化、事务处理优化以及
易语言与API深度结合:实现指定窗口句柄的精准获取

# 摘要
本文系统地介绍了易语言与API的基础概念和在易语言中的基础运用,重点探讨了窗口句柄的精准获取及其在实践应用中的高级技巧。文中首先概述了API的基本
VSS安装使用指南:新手入门的终极向导,零基础也能搞定

# 摘要
本文系统地介绍了版本控制系统(VSS)的基础知识、安装流程、使用技巧、实践应用、进阶应用以及与其他工具的集成方法。首先,概述了VSS的基本概念和安装步骤,随后详细阐述了用户界面功能、文件操作、版本管理以及高级功能如标签和分支的使用。进一步地,本文探讨了VSS在软件开发和项目管理中的应用实例
【Linux性能提升】:makefile编写技巧大公开,优化指南助你提高编译效率
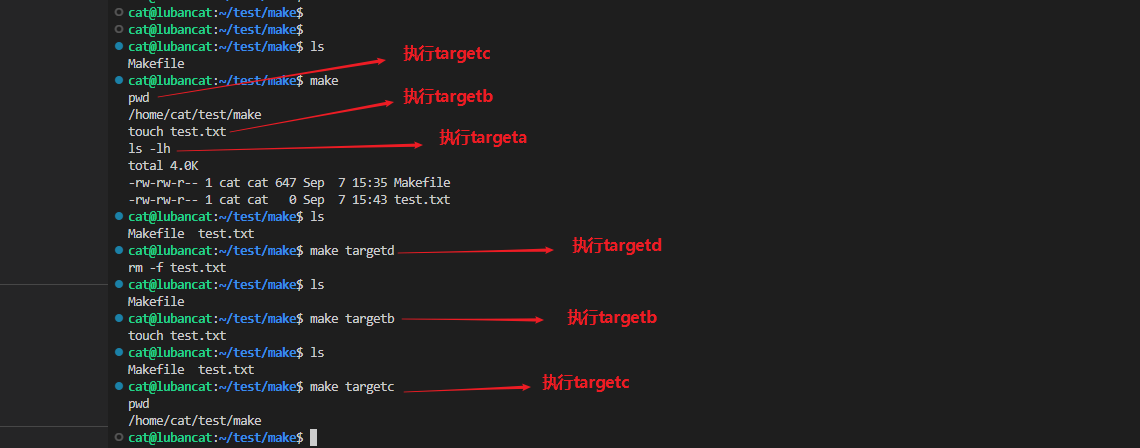
# 摘要
本文详细探讨了Makefile在软件编译过程中的基础原理与高级编写技巧,并分析了在复杂项目构建、团队协作以及优化编译效率方面的应用实践。通过对Makefile核心概念的解析,包括规则、目标、变量、函数以及模式规则和自动化变量的运用,本文进一步阐述了条件判断、多目标构建、静态与动态模式规则、以及自
【高级性能调优策略】:掌握AVX-SSE转换penalty的应对艺术

# 摘要
随着处理器技术的不断进步,AVX指令集作为新一代的向量指令集,相较于SSE指令集,提供了更强大的计算能力和更优的数据处理效率。然而,在从SSE向AVX转换的过程中,存在着性能损失(penalty),这一现象在数据密集型和计算密集型应用中尤为显著。本文深入探讨了AVX-SSE转换的背景、影响、penalty的定义及影响因素,并对不同应用场景中转换的性能表现进行了分析。同时,
企业级Maven私服构建指南:Nexus的高级扩展与定制技术

# 摘要
本文全面介绍了Nexus作为企业级存储库管理工具的部署、高级配置、优化、扩展开发以及在企业级环境中的应用实践。首先概述了Nexus的基本概念和基础部署方法,然后深入探讨了其高级配置选项,包括存储库管理、用户权限设置以及性能调优。接着,本文详细
VMware与ACS5.2河蟹版协同工作指南:整合与最佳实践
# 摘要
本文旨在探讨VMware与ACS5.2河蟹版如何实现协同工作,以及如何在虚拟环境中整合这两种技术以提升网络管理和安全性。文章首先介绍了VMware的基础知识与配置,包括虚拟化技术原理、产品系列、安装步骤以及高级配置技巧。接着,文章概述了ACS5.2河蟹版的功能优势,并详细阐述了其安装、配置和管理方法。最后,文章着
【Docker容器化快速入门】:简化开发与部署的九个技巧
# 摘要
Docker作为当前主流的容器化技术,极大地推动了软件开发、测试和部署流程的自动化和简化。本文对Docker容器化技术进行了全面的概述,从基础命令与镜像管理到Dockerfile的编写与优化,再到网络配置、数据管理和高级应用。通过细致地探讨容器生命周期管理、安全镜像构建和网络数据持久化策略,本文旨在为开发人员提供实用的容器化解决方案
LIN 2.0协议安全宝典:加密与认证机制的全方位解读

# 摘要
本文旨在全面分析LIN 2.0协议的安全特性,包括其加密技术和认证机制。首先介绍了LIN 2.0协议的基础知识及其在安全背景下的重要性。随后,深入探讨了LIN 2.0协议所采用的加密技术,如对称加密、非对称加密、DES、AES以及密钥管理策略。在认证机制方面,分析了消息摘要、哈希函
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )