处理大数据传输:Python网络编程最佳实践
发布时间: 2023-12-19 13:26:57 阅读量: 70 订阅数: 47 
# 1. 简介
## 1.1 什么是大数据传输
大数据传输指的是在网络环境中传输体量庞大的数据,这些数据通常包括但不限于大型文件、数据库备份、实时数据流等。随着云计算、物联网等技术的发展,大数据传输已成为许多企业和组织日常业务中不可或缺的一部分。
## 1.2 Python在网络编程中的重要性
Python作为一种简洁、易读、功能强大的编程语言,在网络编程中扮演着重要角色。其丰富的库和框架(如socket、asyncio、requests等)使其成为处理大数据传输的理想选择。
## 1.3 本文主旨和结构介绍
本文旨在介绍如何利用Python进行处理大数据传输的网络编程最佳实践,包括准备工作、数据分块与传输、优化网络传输性能、错误处理与容错机制以及基于实践的案例研究。读者将逐步了解如何使用Python进行数据分块、传输、优化性能、错误处理以及实践案例研究等方面的技巧与最佳实践。
# 2. 准备工作
在开始处理大数据传输之前,我们需要进行一些准备工作。本章节将介绍安装Python和必要的库、确定网络传输协议以及配置网络环境的步骤。
### 2.1 安装Python和必要的库
首先,我们需要安装Python编程语言及其相关的库。Python是一种简单易学且功能强大的编程语言,具有广泛的应用领域。通过Python,我们可以轻松地进行网络编程和大数据处理。
在安装Python之前,您可以访问Python官方网站(https://www.python.org/)下载您需要的版本。根据您的操作系统,选择适当的安装包进行下载并按照安装向导进行安装。
除了Python本身,我们还需要安装一些常用的Python库,以便在网络编程中使用。以下是几个常用的库:
- **socket**:用于在网络中进行数据传输和通信。
- **threading**:用于实现多线程编程,提高网络处理的效率。
- **logging**:用于记录日志信息,方便调试和错误处理。
- **gzip**:用于数据压缩和解压缩,优化网络传输性能。
- **hashlib**:用于生成和校验数据的哈希值,确保数据的完整性。
您可以使用以下命令使用pip工具来安装这些库:
```python
pip install socket threading logging gzip hashlib
```
完成安装后,您可以通过导入这些库来在代码中使用它们:
```python
import socket
import threading
import logging
import gzip
import hashlib
```
### 2.2 确定网络传输协议
在进行大数据传输之前,我们需要确定使用何种网络传输协议。网络传输协议定义了数据在网络中的传输方式和规则,常见的协议有TCP和UDP。
- **TCP**(Transmission Control Protocol,传输控制协议)是一种可靠的、面向连接的协议。它通过建立虚拟的连接,提供端到端的可靠数据传输和流控制。TCP适用于数据传输要求高可靠性和完整性的场景,如文件传输、远程登录等。
- **UDP**(User Datagram Protocol,用户数据报协议)是一种不可靠的、面向无连接的协议。它将数据以离散的数据包进行传输,不提供流控制和重传机制。UDP适用于对数据传输延迟要求较高,但可靠性要求相对较低的场景,如音视频传输、实时游戏等。
根据实际需求,选择适合的传输协议。
### 2.3 配置网络环境
在进行大数据传输之前,确保您的网络环境正确配置是十分重要的。以下是一些常见的网络配置项:
- **网络速度和带宽**:确保网络速度和带宽足够支持大数据传输。较慢的网络速度可能导致数据传输的延迟和不稳定性。
- **防火墙设置**:如果您的网络中存在防火墙或安全策略,需要对其进行相应的配置,以允许数据传输的通信。
- **IP地址和端口号**:每台设备都有唯一的IP地址,用于在网络中进行通信。确保设备的IP地址设置正确,并且要和其他设备保持唯一性。此外,传输过程中的数据还需要指定端口号来进行定位。
- **网络延迟和丢包率**:网络延迟指的是从数据发送到接收之间的时间延迟,丢包率指的是在传输过程中丢失的数据包的比例。了解网络延迟和丢包率的情况有助于优化大数据传输的性能。
完成了这些准备工作后,我们就可以着手处理大数据传输了。接下来的章节将详细介绍数据分块与传输、优化网络传输性能以及错误处理与容错机制等内容。
# 3. 数据分块与传输
在处理大数据传输时,数据分块与高效的传输是至关重要的。本章将介绍如何使用Python进行数据分块和传输,包括数据切割、设计传输协议以及Python实现的方法。
#### 3.1 切割大数据为小块
在处理大数据传输时,通常需要将大的数据文件或数据流切割成小块,以便进行高效的传输和处理。下面我们将使用Python进行数据切割的示例演示:
```python
# 示例代码:将大数据切割为小块
def split_data(data, chunk_size):
chunks = [data[i:i + chunk_size] for i in range(0, len(data), chunk_size)]
return chunks
# 调用示例
data = "这是一个大数据传输的示例数据,需要被切割为小块进行传输。"
chunk_size = 10
chunks = split_data(data, chunk_size)
print(chunks)
```
**代码解释与总结:**
以上示例中,我们定义了一个函数`split_data`来将输入的数据切割为指定大小的小块,并返回一个包含所有小块的列表。在示例中,我们将字符串`data`切割为大小为10的小块,并打印出结果。
#### 3.2 设计数据传输协议
数据传输协议对于大数据传输至关重要,它定义了数据传输的格式、顺序、校验和其他必要信息。在设计数据传输协议时,需要考虑到数据的完整性、可靠性和效率。以下是一个简单的数据传输协议设计示例:
```markdown
数据传输协议示例:
- 数据头部:包含数据长度、校验信息等
- 数据体:实际的数据内容
- 数据尾部:校验码、结束符等
```
#### 3.3 使用Python进行数据传输
Python提供了多种库和工具来进行数据传输,例如`socket`、`requests`和`paramiko`等。接下来我们将介绍如何使用`socket`库进行简单的数据传输示例:
```python
# 示例代码:使用socket进行数据传输
import socket
# 服务端代码
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(('localhost', 8888))
server_socket.listen(1)
client_socket, addr = server_socket.accept()
print("连接到客户端:", addr)
data = "这是服务端发送的大数据内容。" * 100
client_socket.send(data.encode())
client_socket.close()
# 客户端代码
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_socket.connect(('localhost', 8888))
received_data = client_socket.recv(1024)
print("从服务端接收到的数据:", received_data.decode())
client_socket.close()
```
**代码解释与总结:**
以上示例包括了服务端和客户端的代码,服务端通过`socket`库监听端口并发送大数据内容,客户端连接到服务端并接收数据。这只是一个简单的示例,实际使用中还需要考虑异常处理、数据校验等问题。
在下一章节中,我们将继续讨论如何优化网络传输性能,包括数据压缩、分布式处理和多线程异步编程等内容。
# 4. 优化网络传输性能
在处理大数据传输过程中,优化网络传输性能是非常重要的。本章将介绍一些提升网络传输性能的最佳实践,包括数据压缩与解压缩、分布式处理以及多线程与异步编程等技巧。
#### 4.1 数据压缩与解压缩
数据在传输过程中往往需要经过压缩处理,以减少数据量从而提升传输效率。Python中常用的数据压缩库包括`gzip`、`zlib`和`bz2`等,其中`gzip`是应用最广泛的压缩库之一。以下是一个简单的使用示例:
```python
import gzip
# 压缩数据
with open('data.txt', 'rb') as f_in:
with gzip.open('data.txt.gz', 'wb') as f_out:
f_out.writelines(f_in)
# 解压缩数据
with gzip.open('data.txt.gz', 'rb') as f:
file_content = f.read()
# 处理解压后的数据
```
#### 4.2 分布式处理
对于大数据传输任务,考虑采用分布式处理技术能够更好地利用多台机器的计算能力,从而实现并行传输与处理。常用的分布式处理框架包括Hadoop、Spark等。下面是一个简单的使用Spark进行分布式数据传输与处理的示例:
```python
from pyspark import SparkContext
# 创建Spark上下文
sc = SparkContext('local', 'data_processing')
# 读取数据并分发到各个节点进行处理
data = sc.textFile('hdfs://data.txt')
processed_data = data.map(lambda line: process_function(line))
result = processed_data.collect()
# 关闭Spark上下文
sc.stop()
```
#### 4.3 多线程与异步编程
在Python中,可以使用多线程与异步编程来提升网络传输性能。通过多线程技术可以实现并发传输,而异步编程则能够充分利用非阻塞的特性,加速数据传输过程。以下是一个使用`asyncio`库进行异步数据传输的简单示例:
```python
import asyncio
async def data_transmission():
# 进行数据传输的异步操作
await asyncio.sleep(1)
print("数据传输完成")
# 创建事件循环并运行异步任务
loop = asyncio.get_event_loop()
loop.run_until_complete(data_transmission())
```
在本章中,我们介绍了如何利用数据压缩、分布式处理、多线程与异步编程等技术来优化网络传输性能,帮助读者更好地处理大数据传输任务。
# 5. 错误处理与容错机制
在大数据传输过程中,错误处理与容错机制是非常重要的,可以确保数据的完整性和传输的可靠性。本章将介绍在Python网络编程中处理错误和实现容错机制的最佳实践。
#### 5.1 异常处理
在数据传输过程中,可能会出现各种异常情况,例如网络中断、数据包丢失、超时等。针对这些异常,我们需要合理地处理,以确保程序能够继续执行或者进行适当的回滚操作,并记录异常日志以便排查问题。
**示例代码:**
```python
try:
# 进行数据传输操作
data_transfer()
except ConnectionError as e:
# 处理网络连接错误
print("发生连接错误:", e)
# 进行重连操作或者其他处理
except TimeoutError as e:
# 处理超时错误
print("发生超时错误:", e)
# 进行重试操作或者其他处理
except Exception as e:
# 处理其他异常
print("发生未知异常:", e)
# 记录日志并进行适当的处理
```
**代码总结:**
以上代码演示了在数据传输过程中使用try-except块进行异常处理,通过捕获不同类型的异常并采取相应的处理措施,提高了程序的健壮性和容错能力。
**结果说明:**
通过合理的异常处理,我们可以在出现异常情况时及时进行处理,保障数据传输的稳定性和可靠性。
#### 5.2 数据校验与恢复
为了确保数据传输的完整性,我们需要在传输过程中对数据进行校验,以及在接收端对接收到的数据进行校验和恢复。常见的校验方式包括CRC校验、MD5校验和SHA-1校验等。
**示例代码:**
```python
import hashlib
def calculate_checksum(data):
sha1 = hashlib.sha1()
sha1.update(data)
return sha1.hexdigest()
# 发送端计算校验值
data = b'example data'
checksum = calculate_checksum(data)
send_data(data, checksum)
# 接收端验证校验值
received_data, received_checksum = receive_data()
if calculate_checksum(received_data) == received_checksum:
# 校验通过,继续进行后续处理
process_data(received_data)
else:
# 校验失败,进行数据恢复操作或者重传操作
recovery_data()
```
**代码总结:**
以上代码展示了在数据传输过程中计算和验证数据的校验值,并根据校验结果进行相应的处理,以确保数据的完整性和可靠性。
**结果说明:**
通过数据校验和恢复技术,我们可以在一定程度上保障数据传输的准确性和完整性,减少传输过程中因数据损坏或丢失而引发的错误。
#### 5.3 日志记录与调试技巧
在大数据传输过程中,日志记录和调试技巧是非常重要的,可以帮助我们及时发现问题并进行排查。合理的日志记录可以记录传输过程中的关键信息,以便日后进行分析和排查问题。
**示例代码:**
```python
import logging
# 配置日志记录
logging.basicConfig(filename='data_transfer.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 进行数据传输操作
try:
data_transfer()
except Exception as e:
# 记录异常日志
logging.error("数据传输发生异常:{}".format(e))
# 进行适当的处理
handle_exception()
# 调试技巧
def debug_data_transfer():
# 在关键位置插入调试日志
logging.debug("当前传输进度:{}%".format(50))
# 其他调试代码...
```
**代码总结:**
上述代码展示了如何配置日志记录以及在关键位置插入调试日志,以便记录传输过程中的关键信息和进行调试。
**结果说明:**
通过合理的日志记录和灵活的调试技巧,我们可以更好地理解程序的运行状态,发现潜在问题并进行处理,提高程序的稳定性和可靠性。
# 6. 基于实践的案例研究
在本章节中,我们将通过一个真实的场景来展示如何使用Python进行大数据传输的网络编程实践。通过对实现方案的讲解、测试结果以及总结,读者将更加深入地理解Python在处理大数据传输中的最佳实践。
#### 6.1 场景分析
假设我们需要将一个大小为10GB的数据文件从一台服务器传输到另一台服务器。这个文件需要分割成小块进行传输,并且在传输过程中需要进行数据校验以确保传输的准确性。同时,为了提高传输性能,我们希望能够使用多线程进行并发传输,并实现数据压缩以减小传输时间。
#### 6.2 实现方案讲解
首先,我们将使用Python的文件操作和数据分块技术来将大文件分割成小块。接着,我们会设计一个自定义的数据传输协议,使用Socket库实现数据的可靠传输。然后,我们将介绍如何使用Python的多线程来实现并发传输,并结合数据压缩技术提高传输性能。最后,我们会展示如何进行数据校验与恢复,确保传输的准确性。
#### 6.3 测试结果与总结
在本节的最后,我们将展示经过实践的案例研究的测试结果,并对整个传输过程中遇到的问题和解决方案进行总结和分析,以及对实践经验的进一步展望和总结。
通过本节的学习,读者将对Python网络编程中大数据传输的最佳实践有一个更加全面的认识,从而更好地应用于实际项目中。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在深入讲解Python网络编程(socket)相关知识,内容涵盖了入门指南、TCP/IP协议在Python中的应用、Socket编程基础、UDP套接字编程等多个方面。通过专栏,读者将学习如何建立简单的网络连接、创建多线程网络服务器、进行高级网络设置、进行异常处理和错误调试等实用技能。此外,专栏还介绍了I_O多路复用、TCP服务器构建、网络聊天应用程序实现、网络安全基础、无阻塞网络编程、大数据传输处理等多个实践案例。同时,专栏也探讨了TCP和UDP的应用场景及选择、简单的HTTP服务器编写、简单的网络代理创建以及远程过程调用实现等高级主题。通过本专栏的学习,读者将能全面掌握Python网络编程(socket)的知识和技能,为其在实际项目中的应用奠定坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
扇形菜单设计原理

# 摘要
扇形菜单作为一种创新的界面设计,通过特定的布局和交互方式,提升了用户在不同平台上的导航效率和体验。本文系统地探讨了扇形菜单的设计原理、理论基础以及实际的设计技巧,涵盖了菜单的定义、设计理念、设计要素以及理论应用。通过分析不同应用案例,如移动应用、网页设计和桌面软件,本文展示了扇形菜单设计的实际效果,并对设计过程中的常见问题提出了改进策略。最后,文章展望了扇形菜单设计的未来趋势,包括新技术的应用和设计理念的创新。
# 关键字
扇形菜
传感器在自动化控制系统中的应用:选对一个,提升整个系统性能
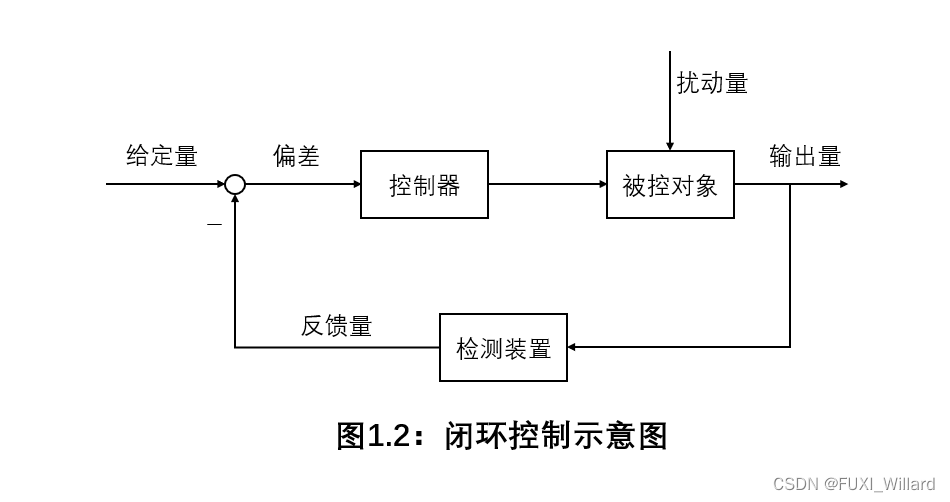
# 摘要
传感器在自动化控制系统中发挥着至关重要的作用,作为数据获取的核心部件,其选型和集成直接影响系统的性能和可靠性。本文首先介绍了传感器的基本分类、工作原理及其在自动化控制系统中的作用。随后,深入探讨了传感器的性能参数和数据接口标准,为传感器在控制系统中的正确集成提供了理论基础。在此基础上,本文进一步分析了传感器在工业生产线、环境监测和交通运输等特定场景中的应用实践,以及如何进行
CORDIC算法并行化:Xilinx FPGA数字信号处理速度倍增秘籍

# 摘要
本文综述了CORDIC算法的并行化过程及其在FPGA平台上的实现。首先介绍了CORDIC算法的理论基础和并行计算的相关知识,然后详细探讨了Xilinx FPGA平台的特点及其对CORDIC算法硬件优化的支持。在此基础上,文章具体阐述了CORDIC算法
C++ Builder调试秘技:提升开发效率的十项关键技巧
# 摘要
本文详细介绍了C++ Builder中的调试技术,涵盖了从基础知识到高级应用的广泛领域。文章首先探讨了高效调试的准备工作和过程中的技巧,如断点设置、动态调试和内存泄漏检测。随后,重点讨论了C++ Builder调试工具的高级应用,包括集成开发环境(IDE)的使用、自定义调试器及第三方工具的集成。文章还通过具体案例分析了复杂bug的调试、
MBI5253.pdf高级特性:优化技巧与实战演练的终极指南
# 摘要
MBI5253.pdf作为研究对象,本文首先概述了其高级特性,接着深入探讨了其理论基础和技术原理,包括核心技术的工作机制、优势及应用环境,文件格式与编码原理。进一步地,本文对MBI5253.pdf的三个核心高级特性进行了详细分析:高效的数据处理、增强的安全机制,以及跨平台兼容性,重点阐述了各种优化技巧和实施策略。通过实战演练案
【Delphi开发者必修课】:掌握ListView百分比进度条的10大实现技巧

# 摘要
本文详细介绍了ListView百分比进度条的实现与应用。首先概述了ListView进度条的基本概念,接着深入探讨了其理论基础和技术细节,包括控件结构、数学模型、同步更新机制以及如何通过编程实现动态更新。第三章
先锋SC-LX59家庭影院系统入门指南
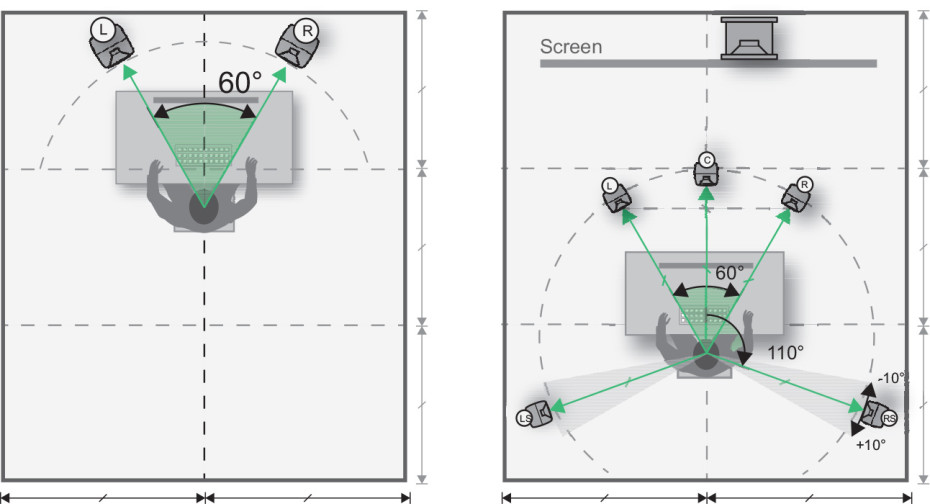
# 摘要
本文全面介绍了先锋SC-LX59家庭影院系统,从基础设置与连接到高级功能解析,再到操作、维护及升级扩展。系统概述章节为读者提供了整体架构的认识,详细阐述了家庭影院各组件的功能与兼容性,以及初始设置中的硬件连接方法。在高级功能解析部分,重点介绍了高清音频格式和解码器的区别应用,以及个
【PID控制器终极指南】:揭秘比例-积分-微分控制的10个核心要点

# 摘要
PID控制器作为工业自动化领域中不可或缺的控制工具,具有结构简单、可靠性高的特点,并广泛应用于各种控制系统。本文从PID控制器的概念、作用、历史发展讲起,详细介绍了比例(P)、积分(I)和微分(D)控制的理论基础与应用,并探讨了PID
【内存技术大揭秘】:JESD209-5B对现代计算的革命性影响
# 摘要
本文详细探讨了JESD209-5B标准的概述、内存技术的演进、其在不同领域的应用,以及实现该标准所面临的挑战和解决方案。通过分析内存技术的历史发展,本文阐述了JESD209-5B提出的背景和核心特性,包括数据传输速率的提升、能效比和成本效益的优化以及接口和封装的创新。文中还探讨了JESD209-5B在消费电子、数据中心、云计算和AI加速等领域的实
【install4j资源管理精要】:优化安装包资源占用的黄金法则

# 摘要
install4j是一款强大的多平台安装打包工具,其资源管理能力对于创建高效和兼容性良好的安装程序至关重要。本文详细解析了install4j安装包的结构,并探讨了压缩、依赖管理以及优化技术。通过对安装包结构的深入理解,本文提供了一系列资源文件优化的实践策略,包括压缩与转码、动态加载及自定义资源处理流程。同时
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )