使用Python编写简单的HTTP服务器
发布时间: 2023-12-19 13:33:19 阅读量: 57 订阅数: 47 

简单的HTTP服务器
# 1. 理解HTTP协议
HTTP(HyperText Transfer Protocol)是一种用于传输超文本数据(例如HTML)的应用层协议。它是Web的基础,使用客户端-服务器模型作为工作方式。
## 1.1 什么是HTTP协议
HTTP协议是一种用于传输超文本数据的协议,它是建立在TCP/IP协议之上的。通过HTTP,客户端可以向服务器请求各种资源,例如文档和多媒体文件。HTTP是无状态的,意味着每个请求都是独立的,服务器不会记得之前的请求。
## 1.2 HTTP协议的基本工作原理
HTTP协议的基本工作原理是,客户端向服务器发送一个HTTP请求,请求中包含请求的方法(如GET、POST)、请求的URL、HTTP协议版本、可选的请求头以及可选的请求体。服务器接收到请求后,会根据请求的内容进行处理,并生成一个HTTP响应返回给客户端。
## 1.3 HTTP请求和响应的结构
### HTTP请求的结构
一个标准的HTTP请求由请求行、请求头部、空行和请求数据四个部分组成,其中请求行必不可少,其他三个部分都是可选的。
```http
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0
Accept-Language: en-us
```
### HTTP响应的结构
一个标准的HTTP响应由状态行、响应头部、空行和响应正文四个部分组成。在HTTP/1.1之前的协议版本中并不会有响应头部,只有状态行和响应正文。
```http
HTTP/1.1 200 OK
Date: Sun, 18 Oct 2012 10:36:20 GMT
Server: Apache/2.2.14 (Win32)
Last-Modified: Sat, 20 Nov 2004 07:16:26 GMT
ETag: "10000000565a5-2c-3e94b66c2e680"
Accept-Ranges: bytes
Content-Length: 44
Connection: close
Content-Type: text/html
<html>
<head>
<title>Title</title>
</head>
<body>
<h1>Hello, World!</h1>
</body>
</html>
```
以上是HTTP协议的基本介绍和结构解析。接下来,我们将深入探讨如何使用Python编写简单的HTTP服务器。
# 2. Python HTTP服务器基础
2.1 Python中的HTTP服务器模块
Python中有多个可用于创建HTTP服务器的模块,其中最常用的是`http.server`模块。该模块提供了一个简单易用的HTTP服务器类,能够处理来自客户端的HTTP请求并发送HTTP响应。
2.2 创建简单的HTTP服务器
使用`http.server`模块创建一个简单的HTTP服务器非常简单。下面是一个使用Python编写的简单的HTTP服务器示例代码:
```python
from http.server import HTTPServer, BaseHTTPRequestHandler
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write(b"Hello, World!")
def run():
server_address = ('', 8000)
httpd = HTTPServer(server_address, SimpleHTTPRequestHandler)
print('Starting server...')
httpd.serve_forever()
if __name__ == '__main__':
run()
```
在上述代码中,我们首先导入了`HTTPServer`和`BaseHTTPRequestHandler`类。然后定义了一个名为`SimpleHTTPRequestHandler`的子类,该子类继承自`BaseHTTPRequestHandler`,用于处理HTTP请求。在`do_GET`方法中,我们发送了一个HTTP响应,其中包含了状态码为200(表示请求成功)和响应内容为"Hello, World!"的头部信息。然后我们定义了一个`run`函数,用于创建并启动HTTP服务器,并在端口8000上监听。最后,在`if __name__ == '__main__'`的条件下,我们调用`run`函数启动服务器。
2.3 运行和测试HTTP服务器
要运行上述的HTTP服务器,只需要在命令行中执行脚本文件即可。执行完毕后,你可以打开浏览器,并输入`http://localhost:8000`来测试HTTP服务器。你将会看到浏览器显示"Hello, World!"的信息,这就说明你的HTTP服务器已经成功运行并发送了HTTP响应。
总结:
在本章中,我们介绍了Python中处理HTTP请求和发送HTTP响应的基本知识。我们学习了使用`http.server`模块创建简单的HTTP服务器,并编写了一个简单的示例代码来实现这一目标。此外,我们还学习了如何运行和测试HTTP服务器。下一章中,我们将学习如何解析HTTP请求的内容。
# 3. 处理HTTP请求
在开发一个HTTP服务器时,处理HTTP请求是至关重要的。本章将介绍如何解析HTTP请求,并处理其中的GET请求和POST请求。
## 3.1 解析HTTP请求
在处理HTTP请求之前,首先需要解析HTTP请求。HTTP请求由请求行、请求头和请求体三部分组成。请求行包含请求方法、URL和HTTP协议版本等信息;请求头包含与请求相关的各种参数和设置;请求体则包含请求的具体内容,如表单数据或上传的文件等。
下面是一个HTTP请求的例子:
```http
GET /hello HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
```
要解析这个HTTP请求,可以使用Python的`http.server.BaseHTTPRequestHandler`类的`parse_request()`方法。下面是一个示例代码:
```python
from http.server import BaseHTTPRequestHandler
def parse_http_request(request):
handler = BaseHTTPRequestHandler()
handler.raw_requestline = request.encode()
handler.parse_request()
return handler
request = """GET /hello HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"""
parsed_request = parse_http_request(request)
print("Method:", parsed_request.command)
print("URL:", parsed_request.path)
print("Protocol:", parsed_request.request_version)
print("Headers:", parsed_request.headers)
```
运行上面的代码,输出如下:
```
Method: GET
URL: /hello
Protocol: HTTP/1.1
Headers: {'Host': 'example.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'}
```
上述代码通过将HTTP请求传递给`parse_http_request()`函数,解析出了请求的各个部分,并打印出来。
## 3.2 处理GET请求
GET请求是最常见的HTTP请求,通过URL中的查询参数传递数据。对于GET请求的处理,可以简单地根据URL中的查询参数进行逻辑处理,并返回响应。
以下是一个示例代码:
```python
from http.server import BaseHTTPRequestHandler
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
if self.path == "/hello":
self.send_response(200)
self.send_header("Content-type", "text/plain")
self.end_headers()
self.wfile.write(b"Hello, World!")
else:
self.send_response(404)
self.send_header("Content-type", "text/plain")
self.end_headers()
self.wfile.write(b"Not Found")
```
上述代码中的`do_GET()`方法用于处理GET请求。在这个例子中,如果请求的路径是`/hello`,则返回响应状态码200并输出"Hello, World!",否则返回404并输出"Not Found"。
## 3.3 处理POST请求
POST请求常用于提交表单数据或上传文件等操作。处理POST请求需要先解析请求体中的数据,然后根据具体业务逻辑进行处理。
以下是一个示例代码,演示如何处理POST请求:
```python
from http.server import BaseHTTPRequestHandler
from urllib.parse import parse_qs
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
def do_POST(self):
content_length = int(self.headers["Content-Length"])
body = self.rfile.read(content_length)
data = parse_qs(body)
if "name" in data:
name = data["name"][0]
self.send_response(200)
self.send_header("Content-type", "text/plain")
self.end_headers()
self.wfile.write(f"Hello, {name}!".encode())
else:
self.send_response(400)
self.send_header("Content-type", "text/plain")
self.end_headers()
self.wfile.write(b"Bad Request")
```
上述代码中的`do_POST()`方法用于处理POST请求。首先从请求头中获取请求体的长度,然后读取请求体的内容。接着使用`urllib.parse.parse_qs()`函数解析请求体中的数据,并根据具体业务逻辑进行处理。在此示例中,如果请求体中包含名为"name"的字段,则返回响应状态码200和"Hello, {name}!"的字符串,否则返回400和"Bad Request"。
这就是处理HTTP请求的基本示例。通过解析HTTP请求,我们可以根据不同的请求方法和请求内容进行相应的处理和响应。在实际应用中,我们可以根据具体需求进行更加复杂的处理逻辑。
# 4. 构建HTTP响应
在本章中,我们将探讨如何构建和发送HTTP响应。HTTP响应是服务器对客户端请求的回应,它包含了响应头和响应体两部分。我们会学习如何构建响应头、设置响应码,并发送简单的HTTP响应。
#### 4.1 HTTP响应的基本结构
HTTP响应的基本结构如下:
```
HTTP/1.1 200 OK
Content-Type: text/html
<html>
<head>
<title>Sample Page</title>
</head>
<body>
<h1>Hello, World!</h1>
</body>
</html>
```
- 第一行为状态行,包含了协议版本和状态码。
- 之后是一系列的响应头,每个头字段由字段名和字段值组成,以冒号分隔。
- 响应头和响应体之间需要用一个空行进行分隔。
- 响应体即为服务器发送给客户端的实际内容。
#### 4.2 构建并发送简单的HTTP响应
在Python中,我们可以使用内置的`http.server`模块来构建和发送HTTP响应。下面是一个简单的示例代码:
```python
from http.server import BaseHTTPRequestHandler, HTTPServer
class MyHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-Type', 'text/html')
self.end_headers()
response = '''
<html>
<head>
<title>Sample Page</title>
</head>
<body>
<h1>Hello, World!</h1>
</body>
</html>
'''
self.wfile.write(response.encode())
def run(server_class=HTTPServer, handler_class=MyHandler, port=8000):
server_address = ('', port)
httpd = server_class(server_address, handler_class)
print('Starting server on port %d...' % port)
httpd.serve_forever()
run()
```
在上述代码中,我们定义了一个名为`MyHandler`的自定义请求处理类,继承自`BaseHTTPRequestHandler`。其中,`do_GET`方法用于处理GET请求。我们先发送了一个状态码为200的响应头,并设置了`Content-Type`为`text/html`。之后,我们构建了一个简单的HTML响应体。最后,通过`self.wfile.write()`方法将响应体发送到客户端。
通过运行上述代码,我们将启动一个简单的HTTP服务器,并在访问该服务器时返回一个包含"Hello, World!"的HTML页面。
#### 4.3 设置响应头和状态码
除了前面提到的`Content-Type`头字段外,HTTP响应还可以包含其他常用的头字段,如`Content-Length`、`Set-Cookie`等。我们可以通过调用`self.send_header()`方法来设置响应头字段。另外,通过调用`self.send_response()`方法可以设置响应的状态码。
例如,下面的代码演示了如何设置`Content-Length`头字段和状态码为404的响应:
```python
class MyHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(404)
self.send_header('Content-Type', 'text/plain')
self.send_header('Content-Length', '0')
self.end_headers()
```
在这个示例中,我们将状态码设置为404,表示请求的资源未找到。我们还设置了`Content-Type`为`text/plain`,并通过`Content-Length`头字段指定响应体的长度为0。
通过设置不同的响应头字段和状态码,我们可以灵活地构建不同类型的HTTP响应。
在本章中,我们介绍了HTTP响应的基本结构,并通过示例代码演示了如何构建和发送简单的HTTP响应。我们还学习了如何设置响应头和状态码。下一章节中,我们将探讨如何处理静态文件。
# 5. 处理静态文件
在本章中,我们将讨论如何在Python中处理静态文件,并将其发送给客户端。静态文件通常包括HTML、CSS、JavaScript、图片等,它们是服务器上存储的文件,我们需要将它们发送给客户端以供浏览器渲染。
### 5.1 读取和发送静态文件
在处理静态文件时,首先我们需要读取服务器上的静态文件内容,然后将其发送给客户端。Python的`open`函数可以用来读取文件内容,然后我们可以使用HTTP响应将文件内容发送给客户端。在这个过程中,我们需要注意处理可能出现的异常情况,比如文件不存在的情况。
```python
import os
def send_static_file(file_path, client_socket):
try:
with open(file_path, 'rb') as file:
content = file.read()
response_headers = "HTTP/1.1 200 OK\r\n\r\n"
client_socket.send(response_headers.encode('utf-8'))
client_socket.send(content)
except FileNotFoundError:
not_found_response = "HTTP/1.1 404 Not Found\r\n\r\n"
client_socket.send(not_found_response.encode('utf-8'))
client_socket.send(b"File Not Found")
```
### 5.2 处理不同类型的静态文件
不同类型的静态文件可能需要以不同的方式进行处理和发送。比如,文本文件可以直接读取并发送,而图片等二进制文件需要以不同的方式处理。我们可以通过检查文件的扩展名来判断文件的类型,并选择合适的读取和发送方式。
```python
import mimetypes
def send_static_file(file_path, client_socket):
try:
mime_type, _ = mimetypes.guess_type(file_path)
with open(file_path, 'rb') as file:
content = file.read()
response_headers = f"HTTP/1.1 200 OK\r\nContent-Type: {mime_type}\r\n\r\n"
client_socket.send(response_headers.encode('utf-8'))
client_socket.send(content)
except FileNotFoundError:
not_found_response = "HTTP/1.1 404 Not Found\r\n\r\n"
client_socket.send(not_found_response.encode('utf-8'))
client_socket.send(b"File Not Found")
```
### 5.3 缓存控制和内容压缩
在处理静态文件时,缓存控制和内容压缩是非常重要的性能优化手段。通过设置适当的响应头,我们可以让客户端缓存静态文件,减少不必要的网络传输。同时,对于文本文件等通常可以进行内容压缩,以减小传输的数据量,提升网站的加载速度。
```python
import os
import gzip
import mimetypes
def send_static_file(file_path, client_socket, enable_cache=True, enable_compression=True):
try:
mime_type, _ = mimetypes.guess_type(file_path)
with open(file_path, 'rb') as file:
content = file.read()
if enable_compression and mime_type.startswith('text'):
content = gzip.compress(content)
client_socket.send("Content-Encoding: gzip\r\n".encode('utf-8'))
if enable_cache:
client_socket.send("Cache-Control: max-age=3600, public\r\n".encode('utf-8'))
response_headers = f"HTTP/1.1 200 OK\r\nContent-Type: {mime_type}\r\n\r\n"
client_socket.send(response_headers.encode('utf-8'))
client_socket.send(content)
except FileNotFoundError:
not_found_response = "HTTP/1.1 404 Not Found\r\n\r\n"
client_socket.send(not_found_response.encode('utf-8'))
client_socket.send(b"File Not Found")
```
通过以上内容,我们可以更好地理解如何在Python中处理静态文件,包括读取和发送不同类型的静态文件,以及优化性能的相关方法。
# 6. 进阶话题和扩展
在本章中,我们将探讨一些进阶话题和扩展内容,以帮助你更好地理解和使用Python编写简单的HTTP服务器。以下是本章的具体内容:
### 6.1 处理动态请求
在前面的章节中,我们已经学习了如何处理静态文件的请求。现在,我们将进一步学习如何处理动态请求。动态请求是指服务器根据请求的参数和数据生成响应内容,而不是直接返回静态文件。
在Python中,我们可以使用CGI(通用网关接口)来处理动态请求。CGI是一种用于Web服务器和脚本语言之间进行通信的标准。它可以让我们的HTTP服务器调用其他编程语言编写的脚本,并将脚本的输出作为HTTP响应返回给客户端。
在本节中,我们将使用Python的CGI模块来处理动态请求。首先,我们需要配置服务器以支持CGI。我们可以通过在服务器配置文件中启用CGI模块来完成。
以下是一个简单的Python HTTP服务器配置文件示例:
```python
from http.server import HTTPServer, CGIHTTPRequestHandler
server_address = ("", 8000)
httpd = HTTPServer(server_address, CGIHTTPRequestHandler)
httpd.serve_forever()
```
在上面的示例中,我们使用了`http.server`模块中的`CGIHTTPRequestHandler`来处理CGI请求,并将其与`HTTPServer`一起使用来创建服务器。
接下来,我们需要创建一个简单的CGI脚本来处理动态请求。下面是一个示例CGI脚本的代码:
```python
#!/usr/bin/env python
print("Content-type: text/html")
print()
print("<html>")
print("<head>")
print("<title>CGI Example</title>")
print("</head>")
print("<body>")
print("<h1>Hello, CGI!</h1>")
print("</body>")
print("</html>")
```
在上面的示例中,我们使用Python的print函数来输出CGI脚本的响应内容。CGI脚本的输出应该符合HTTP响应的格式要求。
要启动服务器并测试动态请求,您可以运行以下命令:
```
python -m http.server --cgi 8000
```
然后,您可以在浏览器中访问`http://localhost:8000/cgi-bin/example.py`来查看CGI脚本的输出。
### 6.2 使用框架简化HTTP服务器开发
在前面的章节中,我们展示了如何使用Python编写简单的HTTP服务器。然而,如果您需要处理更复杂的逻辑和请求,手动编写服务器可能会变得复杂和繁琐。
幸运的是,Python中有许多成熟的框架可以帮助简化HTTP服务器的开发过程。这些框架提供了丰富的功能和工具,可以帮助您处理请求、路由、响应等。
以下是一些流行的Python HTTP框架:
- Flask:一个轻量级的框架,提供了简单易用的API和扩展性。
- Django:一个全功能的Web框架,适用于构建复杂的Web应用程序。
- Bottle:一个简单而快速的Web框架,适用于小型项目和API开发。
- Tornado:一个高性能的Web框架和异步网络库,适用于高并发的应用程序。
使用这些框架,您可以更轻松地编写可靠和高效的HTTP服务器。每个框架都有自己的优势和特点,您可以根据项目的需求选择合适的框架。
### 6.3 安全性和性能优化的考虑
在开发和部署HTTP服务器时,安全性和性能优化是非常重要的考虑因素。以下是一些常见的安全性和性能优化措施:
- 使用HTTPS:为了提高数据传输的安全性,您应该考虑使用HTTPS来加密通过网络传输的数据。
- 输入验证和过滤:在处理用户输入时,始终进行验证和过滤,以防止恶意输入和攻击。
- 安全配置:确保正确配置服务器和应用程序,包括设置合适的访问权限、防火墙和安全策略。
- 缓存控制:使用适当的HTTP标头设置缓存,以减少服务器负载和提高性能。
- 压缩内容:使用Gzip等方法压缩传输的内容,减少数据传输量和网络带宽占用。
通过合理的安全性和性能优化措施,您可以提高HTTP服务器的安全性、性能和可靠性。
希望本章的内容能够帮助您进一步扩展和优化Python的HTTP服务器!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在深入讲解Python网络编程(socket)相关知识,内容涵盖了入门指南、TCP/IP协议在Python中的应用、Socket编程基础、UDP套接字编程等多个方面。通过专栏,读者将学习如何建立简单的网络连接、创建多线程网络服务器、进行高级网络设置、进行异常处理和错误调试等实用技能。此外,专栏还介绍了I_O多路复用、TCP服务器构建、网络聊天应用程序实现、网络安全基础、无阻塞网络编程、大数据传输处理等多个实践案例。同时,专栏也探讨了TCP和UDP的应用场景及选择、简单的HTTP服务器编写、简单的网络代理创建以及远程过程调用实现等高级主题。通过本专栏的学习,读者将能全面掌握Python网络编程(socket)的知识和技能,为其在实际项目中的应用奠定坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
扇形菜单设计原理

# 摘要
扇形菜单作为一种创新的界面设计,通过特定的布局和交互方式,提升了用户在不同平台上的导航效率和体验。本文系统地探讨了扇形菜单的设计原理、理论基础以及实际的设计技巧,涵盖了菜单的定义、设计理念、设计要素以及理论应用。通过分析不同应用案例,如移动应用、网页设计和桌面软件,本文展示了扇形菜单设计的实际效果,并对设计过程中的常见问题提出了改进策略。最后,文章展望了扇形菜单设计的未来趋势,包括新技术的应用和设计理念的创新。
# 关键字
扇形菜
传感器在自动化控制系统中的应用:选对一个,提升整个系统性能
# 摘要
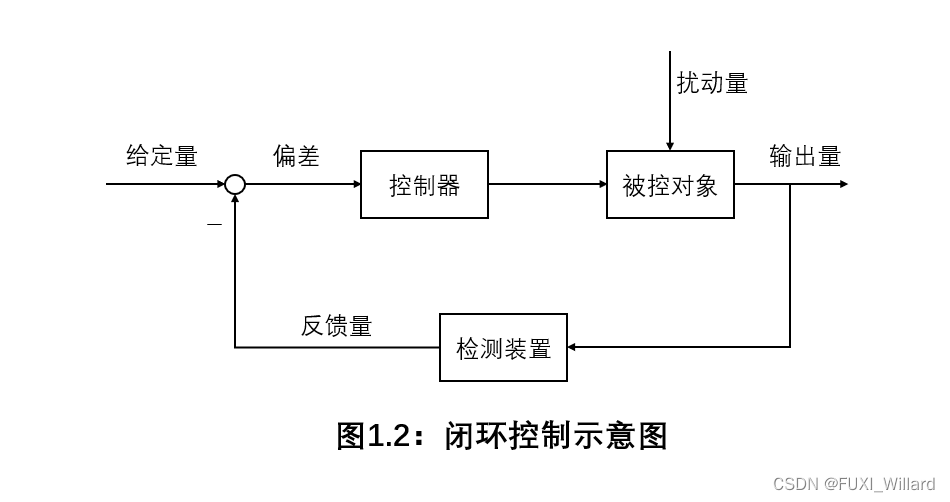
传感器在自动化控制系统中发挥着至关重要的作用,作为数据获取的核心部件,其选型和集成直接影响系统的性能和可靠性。本文首先介绍了传感器的基本分类、工作原理及其在自动化控制系统中的作用。随后,深入探讨了传感器的性能参数和数据接口标准,为传感器在控制系统中的正确集成提供了理论基础。在此基础上,本文进一步分析了传感器在工业生产线、环境监测和交通运输等特定场景中的应用实践,以及如何进行
CORDIC算法并行化:Xilinx FPGA数字信号处理速度倍增秘籍

# 摘要
本文综述了CORDIC算法的并行化过程及其在FPGA平台上的实现。首先介绍了CORDIC算法的理论基础和并行计算的相关知识,然后详细探讨了Xilinx FPGA平台的特点及其对CORDIC算法硬件优化的支持。在此基础上,文章具体阐述了CORDIC算法
C++ Builder调试秘技:提升开发效率的十项关键技巧
# 摘要
本文详细介绍了C++ Builder中的调试技术,涵盖了从基础知识到高级应用的广泛领域。文章首先探讨了高效调试的准备工作和过程中的技巧,如断点设置、动态调试和内存泄漏检测。随后,重点讨论了C++ Builder调试工具的高级应用,包括集成开发环境(IDE)的使用、自定义调试器及第三方工具的集成。文章还通过具体案例分析了复杂bug的调试、
MBI5253.pdf高级特性:优化技巧与实战演练的终极指南
# 摘要
MBI5253.pdf作为研究对象,本文首先概述了其高级特性,接着深入探讨了其理论基础和技术原理,包括核心技术的工作机制、优势及应用环境,文件格式与编码原理。进一步地,本文对MBI5253.pdf的三个核心高级特性进行了详细分析:高效的数据处理、增强的安全机制,以及跨平台兼容性,重点阐述了各种优化技巧和实施策略。通过实战演练案
【Delphi开发者必修课】:掌握ListView百分比进度条的10大实现技巧

# 摘要
本文详细介绍了ListView百分比进度条的实现与应用。首先概述了ListView进度条的基本概念,接着深入探讨了其理论基础和技术细节,包括控件结构、数学模型、同步更新机制以及如何通过编程实现动态更新。第三章
先锋SC-LX59家庭影院系统入门指南
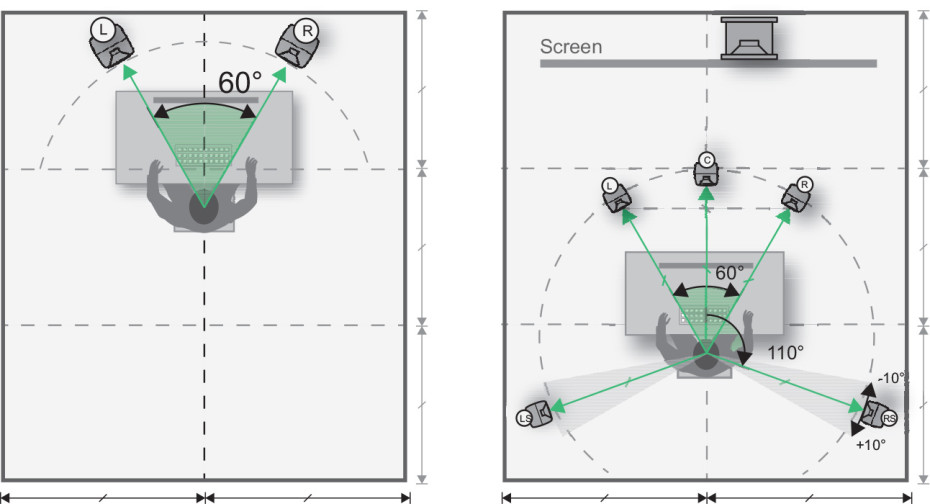
# 摘要
本文全面介绍了先锋SC-LX59家庭影院系统,从基础设置与连接到高级功能解析,再到操作、维护及升级扩展。系统概述章节为读者提供了整体架构的认识,详细阐述了家庭影院各组件的功能与兼容性,以及初始设置中的硬件连接方法。在高级功能解析部分,重点介绍了高清音频格式和解码器的区别应用,以及个
【PID控制器终极指南】:揭秘比例-积分-微分控制的10个核心要点

# 摘要
PID控制器作为工业自动化领域中不可或缺的控制工具,具有结构简单、可靠性高的特点,并广泛应用于各种控制系统。本文从PID控制器的概念、作用、历史发展讲起,详细介绍了比例(P)、积分(I)和微分(D)控制的理论基础与应用,并探讨了PID
【内存技术大揭秘】:JESD209-5B对现代计算的革命性影响
# 摘要
本文详细探讨了JESD209-5B标准的概述、内存技术的演进、其在不同领域的应用,以及实现该标准所面临的挑战和解决方案。通过分析内存技术的历史发展,本文阐述了JESD209-5B提出的背景和核心特性,包括数据传输速率的提升、能效比和成本效益的优化以及接口和封装的创新。文中还探讨了JESD209-5B在消费电子、数据中心、云计算和AI加速等领域的实
【install4j资源管理精要】:优化安装包资源占用的黄金法则

# 摘要
install4j是一款强大的多平台安装打包工具,其资源管理能力对于创建高效和兼容性良好的安装程序至关重要。本文详细解析了install4j安装包的结构,并探讨了压缩、依赖管理以及优化技术。通过对安装包结构的深入理解,本文提供了一系列资源文件优化的实践策略,包括压缩与转码、动态加载及自定义资源处理流程。同时
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )