Python日志监控实战指南:构建实时监控系统的必备技巧
发布时间: 2024-10-14 12:05:18 阅读量: 2 订阅数: 4 
# 1. Python日志监控基础
## 1.1 日志监控的重要性
在复杂的IT系统中,日志是不可或缺的一部分。它记录了系统运行的状态、用户的操作行为以及各种事件的详细信息。对于系统维护和故障排查来说,实时有效的日志监控显得尤为重要。通过监控日志,我们可以实时了解系统的运行状况,及时发现潜在的问题,并采取相应的措施。
## 1.2 Python在日志监控中的应用
Python作为一种强大的编程语言,它在日志监控方面有着广泛的应用。Python的简洁语法和强大的标准库使得编写日志监控脚本变得简单高效。此外,Python的第三方库如`logging`和`fluentd`等提供了丰富的接口,方便我们进行日志的采集、处理和传输。
## 1.3 基础知识回顾
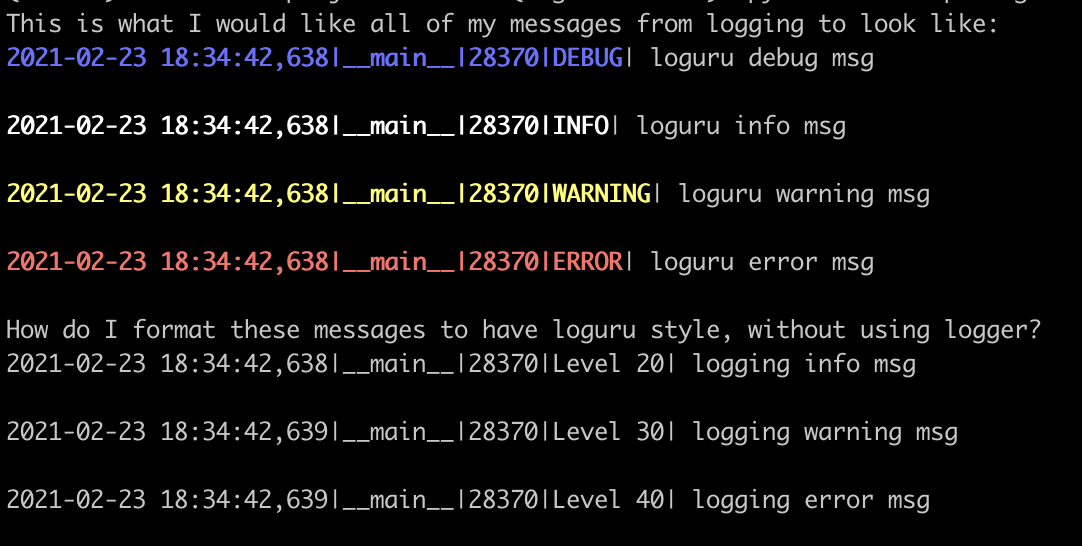
在深入探讨Python日志监控之前,我们需要回顾一些基础知识。首先,了解日志的五要素:时间戳、日志级别、日志消息、日志名称和线程信息。其次,熟悉Python中的`logging`模块的基本使用方法,这将帮助我们构建基础的日志监控系统。
```python
import logging
# 配置日志记录器
logging.basicConfig(level=***, format='%(asctime)s - %(levelname)s - %(message)s')
# 记录一条信息
***('This is a log message.')
```
通过上述代码,我们可以记录一条简单的信息,并将其输出到控制台。这只是Python日志监控的冰山一角,随着文章的深入,我们将学习更多高级功能,如日志文件的读取、日志的远程传输等。
# 2. 日志数据的采集与预处理
在本章节中,我们将深入探讨日志数据的采集与预处理方法。日志数据的采集是日志监控的第一步,它决定了后续分析的质量。预处理则是为了确保日志数据能够被有效地分析和利用。我们将从两种主要的日志采集方法开始,然后讨论预处理技术,包括日志格式化、解析与结构化,以及异常和错误处理。
## 2.1 日志数据的采集方法
### 2.1.1 基于文件的日志采集
基于文件的日志采集是最早也是最常见的日志采集方式。在这种方法中,日志数据以文件的形式存储在服务器上。日志采集工具定期检查这些文件,并将新的日志条目添加到监控系统中。
#### 实现步骤
1. **选择采集工具**:常用的工具包括`logrotate`、`rsync`等。
2. **配置采集策略**:确定哪些文件需要采集,以及采集的频率。
3. **传输日志数据**:使用`scp`、`rsync`或`FTP`等方式将日志文件传输到中央服务器。
#### 示例代码
```bash
# 使用rsync同步日志文件
rsync -avz /var/log/your_application.log user@central_server:/path/to/destination/
```
#### 参数说明
- `-a`:归档模式,保留原有文件权限和属性。
- `-v`:详细模式,显示同步过程。
- `-z`:压缩数据传输。
#### 逻辑分析
上述命令将本地`/var/log/your_application.log`文件同步到远程服务器的指定目录。这种方式适用于日志量不是非常大的情况,因为它依赖于定期轮询,可能会有延迟。
### 2.1.2 基于网络的日志采集
随着分布式系统的发展,基于网络的日志采集方法变得越来越流行。在这种方法中,日志数据通过网络直接发送到中央服务器。
#### 实现步骤
1. **配置日志发送者**:在应用程序或服务器上配置日志输出到网络端口。
2. **设置日志接收者**:在中央服务器上运行日志接收服务,如`syslog-ng`、`fluentd`等。
3. **数据传输**:使用TCP或UDP协议将日志数据发送到接收者。
#### 示例代码
```bash
# 配置fluentd作为日志接收者
<source>
@type forward
port 24224
</source>
<match *.log>
@type file
path /var/log/fluentd/%{index}.log
flush_interval 1s
</match>
```
#### 参数说明
- `@type forward`:指定输入插件类型为`forward`。
- `port`:监听的端口。
- `path`:存储日志文件的路径。
#### 逻辑分析
上述配置设置了`fluentd`作为日志接收者,监听24224端口。所有发送到该端口的日志数据都会被记录到指定的文件中。这种方式的优点是实时性好,能够应对大规模的日志数据。
## 2.2 日志数据的预处理技术
### 2.2.1 日志格式化
日志格式化是将原始日志数据转换成统一格式的过程,便于后续分析和处理。
#### 实现步骤
1. **定义目标格式**:确定日志数据的最终格式,如JSON。
2. **编写格式化脚本**:使用脚本语言(如Python、JavaScript)编写转换逻辑。
3. **应用格式化脚本**:在日志采集或存储阶段应用格式化脚本。
#### 示例代码
```python
import json
# 示例:将单行文本日志格式化为JSON
raw_log = "2023-01-01 12:00:00 error connecting to database"
# 解析日志
log_parts = raw_log.split()
timestamp = log_parts[0]
message = ' '.join(log_parts[2:])
# 转换为JSON格式
formatted_log = {
'timestamp': timestamp,
'message': message
}
print(json.dumps(formatted_log))
```
#### 参数说明
- `split()`:将字符串分割为列表。
- `json.dumps()`:将Python字典转换为JSON格式的字符串。
#### 逻辑分析
上述Python脚本将单行文本日志转换为JSON格式。这只是一个简单的例子,实际应用中可能需要处理更复杂的日志格式和逻辑。
### 2.2.2 日志解析与结构化
日志解析是将日志数据转换为结构化数据的过程,它通常涉及到提取日志中的关键信息,并将其存储到数据库中。
#### 实现步骤
1. **定义结构化模型**:确定存储数据的模型,如数据库表结构。
2. **编写解析逻辑**:使用正则表达式或解析库(如`logstash`、`fluentd`)编写解析逻辑。
3. **应用解析逻辑**:在日志预处理阶段应用解析逻辑。
#### 示例代码
```conf
# logstash配置示例
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:timestamp} %{IPORHOST:hostname} %{WORD:service} %{WORD:severity} %{GREEDYDATA:log_message}" }
}
}
}
```
#### 参数说明
- `filter`:定义过滤器,用于日志解析。
- `grok`:使用正则表达式匹配日志数据。
- `match`:定义匹配规则。
#### 逻辑分析
上述配置使用了`logstash`的`grok`过滤器来解析syslog格式的日志。它将日志文本转换为结构化的字段,如时间戳、主机名、服务、严重性等。
### 2.2.3 异常和错误处理
在日志预处理过程中,需要特别注意异常和错误的处理,以确保监控系统的稳定运行。
#### 实现步骤
1. **定义异常规则**:确定哪些日志条目被认为是异常或错误。
2. **编写异常处理逻辑**:在脚本或配置中添加异常处理逻辑。
3. **记录异常信息**:将异常信息记录到专门的日志文件或发送警报。
#### 示例代码
```python
try:
# 假设这是解析日志的函数
parse_log(raw_log)
except Exception as e:
# 记录异常信息
log_error(e)
```
#### 参数说明
- `try`:尝试执行代码块。
- `except`:捕获异常并执行异常处理代码。
- `log_error(e)`:记录异常信息到日志。
#### 逻辑分析
上述代码示例展示了如何捕获并记录解析日志时发生的异常。在实际应用中,需要根据具体的解析逻辑和环境调整异常处理代码。
通过本章节的介绍,我们了解了日志数据的采集与预处理方法。首先,我们探讨了基于文件和网络的日志采集方法,并通过示例代码和逻辑分析展示了如何实现这些方法。接着,我们深入到日志数据的预处理技术,包括日志格式化、解析与结构化,以及异常和错误处理。通过这些预处理技术,我们可以确保日志数据能够被有效地分析和利用。在下一章中,

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 日志管理专栏!本专栏旨在帮助您深入了解 Python 中强大的 logging 模块,掌握从基本使用到高级技巧的全面知识。我们将深入探讨日志级别、自定义格式、性能优化、日志分析、轮转和归档,以及第三方库的集成。通过一系列循序渐进的文章,您将学习如何有效地管理日志,提取关键信息,保护敏感数据,并利用可视化工具分析日志。无论您是 Python 新手还是经验丰富的开发人员,本专栏都将为您提供全面且实用的指南,帮助您提升日志管理技能,为您的应用程序创建健壮且高效的日志系统。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python Crypt库密钥生成与管理:最佳实践与案例分析

# 1. Python Crypt库简介
Python Crypt库是一个用于加密和解密数据的库,它提供了多种加密算法的实现,包括但不限于AES、DES、RSA、ECC等。本章将介绍Python Crypt库的基本概念和功能,并探讨如何在实际项目中应用它来提高数据安全。
## Crypt库的基本功能
Crypt库为Python开发者提供了一系列的加密工具,使得加密
Django视图与高效分页:在django.views.generic.base中实现高效分页显示的技巧
# 1. Django视图的基础知识
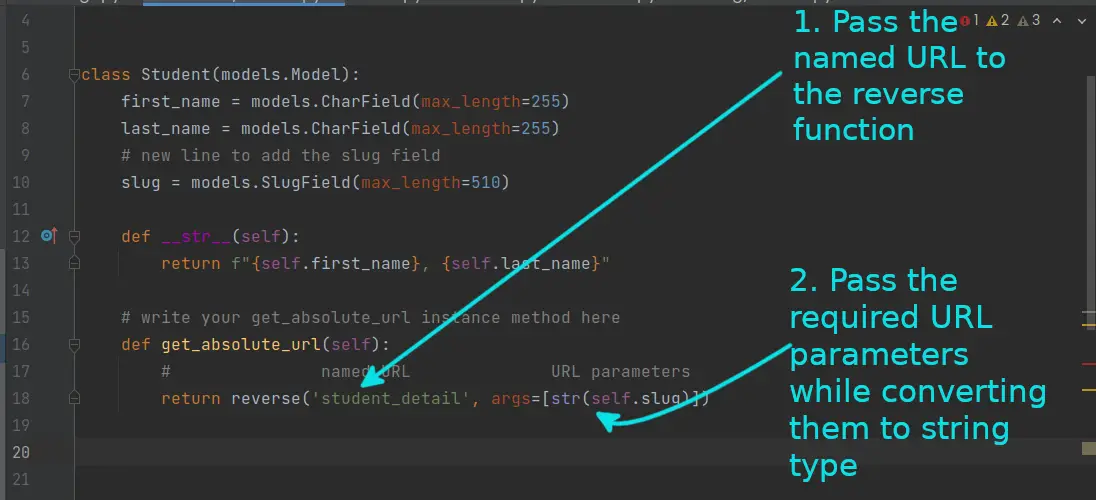
## Django视图的概念
Django视图是MVC架构中控制器角色的实现,负责处理用户的请求并返回响应。在Django中,视图通常是位于`views.py`文件中的Python函数或类。视图接收We
【gdata库的最佳实践】:分享高效使用gdata库的经验与技巧
# 1. gdata库概述
## gdata库简介
gdata库是一个用于处理Google数据API的Python库,它支持与Google多个服务(如Google Calendar、Google Spreadsheets等)进行交互。它提供了一种简单的方式来读取和写入Google数据,而不需要直接处理底层的HTTP请求和XML解析。gdata库通过
【异步视图和控制器】:Python asynchat在Web开发中的实践

# 1. 异步视图和控制器概念解析
在现代Web开发中,异步编程已成为提升性能和响应速度的关键技术之一。异步视图和控制器是实现高效异步Web应用的核心组件。本章将深入探讨这些概念,为读者提供一个坚实的理论基础。
## 异步编程基础
异步编程是一种编程范式,它允许程序在执行过程中,不必等待某个长时间运行的任务完成即
【distutils.sysconfig在虚拟环境中应用】:为虚拟环境定制配置,打造独立的Python环境

# 1. distutils.sysconfig概述
在Python的生态系统中,`distutils.sysconfig`是一个常被忽视但极其重要的模块。它提供了与底层构建系统的交互接口,允许开发者在安装、构建和分发Python模块和包时,能够精确地控制配置细节。本章我们将
Textile文本内容压缩与解压缩:节省空间的6大方法

# 1. Textile文本压缩概述
Textile文本压缩技术是数据处理领域的一项重要技术,它通过减少文本数据中的冗余信息来实现数据大小的缩减。在当今信息爆炸的时代,文本压缩不仅能够提高数据存储和传输的效率,还能在一定程度上节约成本。本文将从Textile文本压缩的基本概念出发,深入探讨其理论基础、实践应用以及优化策略,帮助读者全面理解并有效应用这
SQLAlchemy事务处理指南:ACID原则与异常管理
# 1. SQLAlchemy事务处理概述
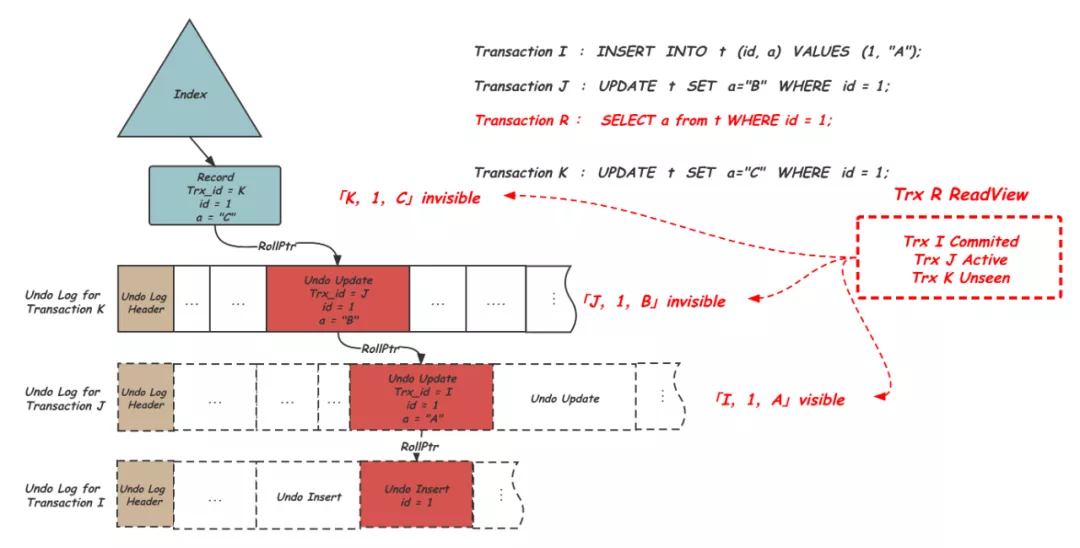
在数据库操作中,事务是确保数据一致性和完整性的重要机制。SQLAlchemy作为Python中强大的ORM工具,其对事务的支持和处理能力是构建健壮应用程序的关键。本文将深入探讨SQLAlchemy中事务处理的各个方面,从ACID原则的基础知识到实际的事务操作,再到异常处理和性能优化的最佳实践。
事务处理在数据库系统中扮演着至关重要的角色,它保证了一系列操作的原子性(Atomicity)
Jinja2.utils代码深度解析:揭秘内置工具类的设计哲学

# 1. Jinja2.utils简介
Jinja2是Python中一个非常流行的模板引擎,它提供了一种简单而强大的方式来生成HTML,XML或其他标记格式的文档。Jinja2.utils是Jinja2库中的一个辅助模块,它包含了一系列实用的函数和类,用于扩展Jinja2的功能和
【Django本地化模型字段扩展】:探索django.contrib.localflavor.us.models的无限可能

# 1. Django本地化模型字段概述
## 本地化字段的基本概念
在Web开发中,本地化(Localization)是指将软件界面和功能适应特定区域或文化的实践。Django作为一个强大的Pyt
Git与Python:版本控制中的高级合并策略揭秘
# 1. Git版本控制基础与Python的交集
Git作为版本控制系统,其重要性在于跟踪和管理代码变更,而对于Python开发者来说,Git不仅是一个代码版本控制工具,更是提高开发效率和协作质量的关键。本章将介绍Git版本控制的基础知识,并探讨其与Python的交集。
## 1.1 版本控制系统的定义
版本控制系统(Version Control
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )