【gdata库的最佳实践】:分享高效使用gdata库的经验与技巧
发布时间: 2024-10-14 15:57:53 阅读量: 39 订阅数: 33 

无需编写任何代码即可创建应用程序:Deepseek-R1 和 RooCode AI 编码代理.pdf
# 1. gdata库概述
## gdata库简介
gdata库是一个用于处理Google数据API的Python库,它支持与Google多个服务(如Google Calendar、Google Spreadsheets等)进行交互。它提供了一种简单的方式来读取和写入Google数据,而不需要直接处理底层的HTTP请求和XML解析。gdata库通过抽象出简单的API,使得开发者能够轻松地集成Google服务到自己的应用中。
## gdata库的应用场景
gdata库广泛应用于需要与Google服务进行集成的应用程序开发中。例如,开发者可能需要在自己的应用程序中访问用户的Google日历数据以实现同步功能,或者需要上传和管理Google表格数据。此外,gdata库也适用于自动化脚本,如数据备份、报表生成等场景,其中需要与Google服务交互并处理大量数据。通过gdata库,开发者可以更加专注于业务逻辑的实现,而不是底层的数据通信细节。
# 2. gdata库的安装与配置
2.1 安装gdata库
gdata库是一个强大的库,用于处理和操作各种数据格式,尤其擅长于XML和JSON数据。为了充分利用gdata库的功能,我们需要先进行安装和配置。本章节将详细介绍如何通过pip安装gdata库,以及从源代码编译安装gdata库的方法。
### 2.1.1 通过pip安装gdata
pip是Python的包管理工具,它可以帮助我们方便快捷地安装所需的Python包。以下是通过pip安装gdata库的步骤:
1. 打开命令行工具,输入以下命令以确保pip工具是最新版本:
```bash
python -m pip install --upgrade pip
```
2. 使用pip安装gdata库:
```bash
pip install gdata
```
这个过程会从Python的包索引中下载gdata库及其依赖,并自动安装到您的系统中。
### 2.1.2 从源代码编译安装gdata
如果您希望从源代码安装gdata库,或者需要安装特定版本的gdata,那么可以从GitHub上克隆gdata库的源代码并自行编译安装。以下是详细步骤:
1. 访问gdata库的GitHub仓库,下载源代码压缩包或使用git命令克隆仓库:
```bash
git clone ***
```
2. 进入克隆的仓库目录:
```bash
cd go-gdata
```
3. 安装编译所需的依赖:
```bash
pip install -r requirements.txt
```
4. 构建并安装gdata库:
```bash
python setup.py build
python setup.py install
```
这个过程将编译gdata库,并在您的系统中安装编译后的库文件。
### 2.2 配置gdata库
为了使用gdata库,我们还需要进行一些配置,包括API密钥的配置、服务账户的设置以及环境变量的使用。
### 2.2.1 配置API密钥
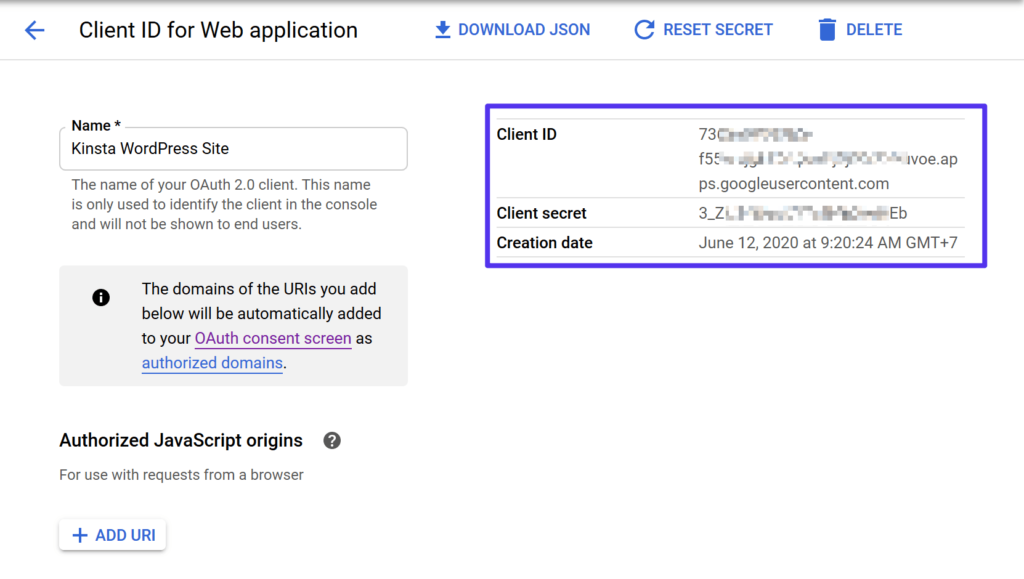
一些数据服务需要通过API密钥来进行身份验证。您可以访问相应的服务提供商网站注册API密钥。以下是配置API密钥的一般步骤:
1. 注册并获取API密钥。
2. 将API密钥添加到您的代码中:
```python
import gdata.gauth
gauth = gdata.gauth.GoogleAuth()
gauth.service_account_file = '/path/to/service-account-file.json'
gauth.client_id = 'your-client-id'
gauth.client_secret = 'your-client-secret'
```
### 2.2.2 设置服务账户
服务账户是一种特殊类型的Google账户,用于服务器到服务器的应用程序身份验证。以下是设置服务账户的步骤:
1. 在Google Cloud Platform上创建一个服务账户。
2. 下载服务账户的密钥文件。
3. 配置服务账户信息到gdata库中,如上节所示。
### 2.2.3 环境变量的使用
为了更好地管理API密钥和配置信息,我们可以使用环境变量。这样可以避免在代码中硬编码敏感信息。以下是如何设置环境变量的步骤:
1. 在您的操作系统中设置环境变量,例如在Unix-like系统中:
```bash
export SERVICE_ACCOUNT_JSON=/path/to/service-account-file.json
```
2. 在Python代码中读取环境变量:
```python
import os
gauth = gdata.gauth.GoogleAuth()
gauth.service_account_file = os.environ.get('SERVICE_ACCOUNT_JSON')
```
通过以上步骤,我们完成了gdata库的安装与配置。在下一章节中,我们将深入探讨gdata库的核心功能与使用方法。
# 3. gdata库的核心功能与使用
在本章节中,我们将深入探讨gdata库的核心功能,包括数据检索、数据处理与转换以及高级交互操作。通过这些功能的详细介绍和示例代码,读者将能够掌握如何在项目中高效地使用gdata库。
## 3.1 数据检索功能
### 3.1.1 基本的XML数据检索
gdata库提供了强大的XML数据检索功能。开发者可以通过简单的API调用来查询和检索XML格式的数据。以下是一个基本的XML数据检索示例:
```python
from gdata.client import Client
# 创建一个客户端实例
client = Client('***')
# 设置API密钥
client.authorization = 'Bearer YOUR_API_KEY'
# 发起数据检索请求
feed = client.GetFeed(url='***')
for entry in feed.entry:
print(entry.title.text)
```
#### 代码逻辑解读分析
1. 首先,我们导入`gdata.client`模块中的`Client`类。
2. 创建一个`Client`实例,并指定API的基本URL。
3. 设置API密钥,这通常是一个由API提供者发放的令牌,用于验证请求。
4. 通过`GetFeed`方法发起一个数据检索请求,获取特定URL的数据。
5. 遍历返回的feed中的每个条目,并打印出标题。
### 3.1.2 高级查询技巧
在实际应用中,我们可能需要执行更复杂的查询。gdata库支持XPath和GData查询语言来实现高级查询。以下是一个使用XPath进行高级查询的示例:
```python
from gdata.client import Client
from gdata.gd import atom
# 创建一个客户端实例
client = Client('***')
# 设置API密钥
client.authorization = 'Bearer YOUR_API_KEY'
# 构建XPath查询
query = atom.Query(client.root feed=atom.Feed(url='***'))
query.SelectField(atom.Field('title'))
query.AddConstraint(atom.Constraint(atom.Property('updated'), operator=***parator.GT, value='2020-01-01T00:00:00Z'))
# 发起高级查询请求
entries = client.GetQuery(query)
for entry in entries.entry:
print(entry.title.text)
```
#### 参数说明
- `atom.Query`:用于构建XPath查询的对象。
- `client.root`:表示客户端根目录。
- `atom.Feed`:表示要查询的feed对象。
- `atom.Field`:指定要返回的字段。
- `atom.Constraint`:设置查询条件。
- `atom.Property`:指定要查询的属性。
- `***parator`:比较操作符,如大于、小于等。
#### 代码逻辑解读分析
1. 创建一个`Client`实例,并设置API密钥。
2. 使用`atom.Query`构建一个XPath查询对象。
3. 设置查询的feed URL。
4. 通过`SelectField`方法选择要返回的字段。
5. 通过`AddConstraint`方法添加一个查询条件,这里设置为更新时间大于指定的日期。
6. 发起高级查询请求,获取符合条件的条目。
7. 遍历并打印每个条目的标题。
## 3.2 数据处理与转换
### 3.2.1 数据解析方法
gdata库提供了多种数据解析方法,使开发者能够轻松地处理和转换XML数据。以下是一个使用`Entry`类进行数据解析

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python gdata 库学习专栏!本专栏旨在全面介绍 gdata 库,帮助您轻松操作 Google Data API。从入门指南到高级技巧,从实战案例到常见问题解析,我们为您提供了丰富的资源,让您逐步掌握 gdata 库的方方面面。此外,我们还探讨了性能优化、安全指南、版本升级、多线程和异步编程等高级主题。无论您是初学者还是经验丰富的开发者,本专栏都能为您提供有价值的见解,帮助您高效地使用 gdata 库处理 Google 数据。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
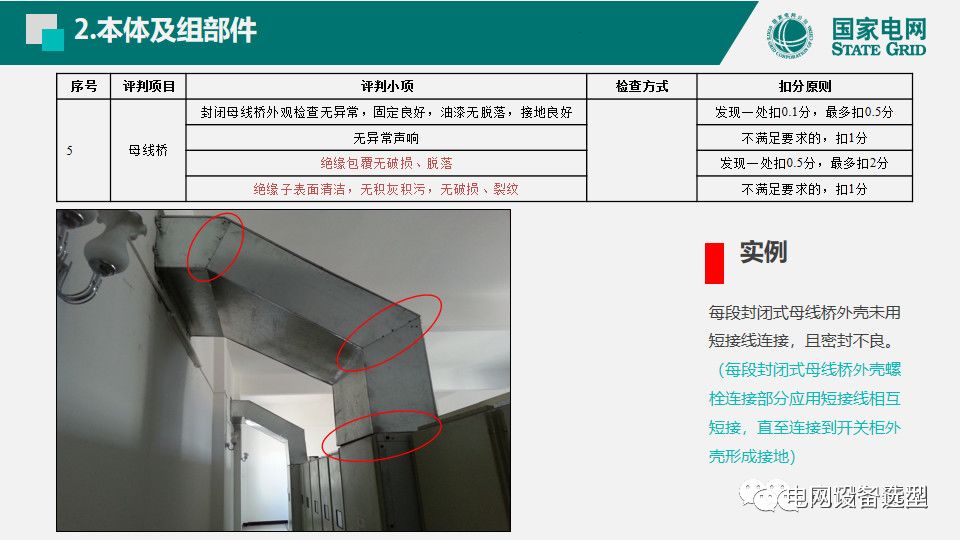
配电柜技术更新:从规范角度解析新趋势
# 摘要
配电柜技术作为电力系统的重要组成部分,一直随着技术进步而不断进化。本文首先概述了配电柜技术的发展历程,接着详细探讨了新规范下的设计原则及其对安全性、可靠性和可维护性的影响。文章深入分析了配电柜技术更新的原理、实践案例以及面临的挑战。并进一步展望了数字化配电柜技术、环保型配电柜技术和超前设计在配电柜领域的应用前景。最后,本文评估了配电柜技术更新对制造业、施工安装业和维护行业的广泛影响,并讨论了国家政策导向及配电柜技术
WCDMA无线接口技术深研:信号调制与编码机制实战攻略

# 摘要
本文对WCDMA无线通信技术进行了全面的概述和深入分析,从调制技术到编码机制,再到信号调制解调的实践应用,涵盖了WCDMA技术的关键组成部分和优化策略。首先介绍了WCDMA无线通信的基础概念,并深入探讨了
硬盘故障快速诊断:HDDScan工具的实战应用

# 摘要
硬盘故障诊断和数据恢复是计算机维护的重要方面。本文首先介绍硬盘故障诊断的基础知识,然后深入探讨HDDScan工具的功能、安装与配置。通过实战章节,本文演示如何使用HDDScan进行快速和深度硬盘检测,包括健康状态检测、SMART属性解读和磁盘错误修复。接着,文章详细阐述数据恢复原理、限制以及备份策略和实践。在故障修复与性能调优部分,探讨了硬盘故障识别、修复方法和性能检测与优化技巧。最后,通过高
揭秘软件工程的法律与伦理基石:合规与道德决策的终极指南
# 摘要
软件工程领域的快速发展伴随着法律与伦理问题的日益凸显。本文首先概述了软件工程中法律与伦理的概念,并探讨了在软件开发生命周期中实施合规性管理的实践方法,包括法律风险的识别、评估以及合规策略的制定。随后,本文讨论了软件工程中的伦理决策框架和原则,提供了面对伦理困境时的决策指导,并强调了增强伦理意识的重要性。文章还分析了软件工程法律与伦理的交叉点,例如隐私保护、数据安全、知识产
最小拍控制系统的故障诊断与预防措施

# 摘要
最小拍控制系统是一种工业控制策略,以其快速稳定性和简单性著称。本文首先介绍了最小拍控制系统的概念与原理,然后深入探讨了故障诊断的理论基础,包括硬件和软件故障的分类、诊断技术、实时监控和数据分析。接着,文章着重讲解了最小拍控制系统在不同阶段的故障预防策略,包括系统设计、实施和运维阶段。此外,本文还详述了故障修复与维护的流程,从故障快速定位到系统恢复与性能优化。最后,通过案例研究与经验分享
稳定扩散模型终极指南:WebUI使用与优化全解析(含安装指南及高级技巧)
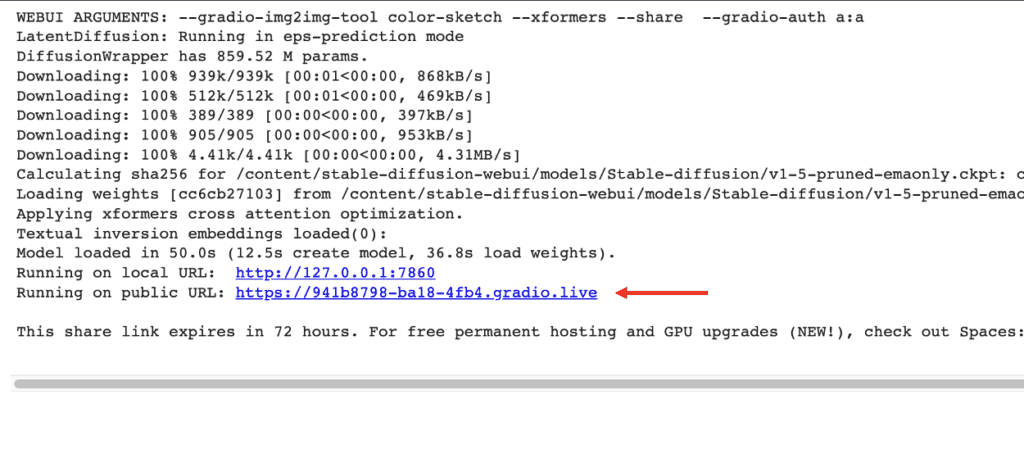
# 摘要
本文系统介绍了WebUI的安装、基础配置、使用实践、性能优化以及未来展望,旨在为用户提供全面的使用指导和最佳实践。文章首先介绍了稳定扩散模型的基本概念,随后详细阐述了WebUI的安装过程、界面布局、功能设置以及模型操作和管理。为了提高用户效率,文中还包含了WebUI性能优化、安全性配置和高级定制化设置的策略。最后,本文探讨了WebUI社区的
CST软件在喇叭天线设计中的最佳实践指南

# 摘要
CST软件在天线设计中扮演着至关重要的角色,尤其在喇叭天线的建模与仿真方面具有显著优势。本文首先概述了CST软件的功能及其在天线设计中的应用,随后深入探讨了喇叭天线的基本理论、设计原理、性能参数和设计流程。文章详细介绍了使用CST软件进行喇叭天线建模的步骤,包括参数化建模和仿真设置,并对仿真结果进行了分析解读。此外,本文提供了设计喇叭天
信号与系统基础精讲:单位脉冲响应在系统识别中的关键应用
# 摘要
信号与系统的研究是电子工程和通讯领域的基础,单位脉冲响应作为系统分析的关键工具,在理论和实践中都占有重要地位。本文从单位脉冲信号的基本概念出发,深入探讨了其在时域和频域的特性,以及线性时不变系统(LTI)响应的特点。通过对系统响应分类和单位脉冲响应角色的分析,阐述了其在系统描述和分析中的重要性。随后,文章转向系统识别方法论,探索了单位脉冲响应
【点胶机故障诊断必修课】:手持版快速故障排除技巧

# 摘要
点胶机作为精密的自动化设备,在生产中扮演着至关重要的角色。本文首先介绍了点胶机故障诊断的基础知识,随后深入探讨了硬件故障的分析与排除方法,包括关键硬件组件的识别、诊断步骤以及实际案例分析。接着,文章转而讨论了软件故障排除的技巧,重点在于理解点胶软件架构、排除策略以及实际故障案例的剖析。此外,点胶机的操作规范、维护要点以及故障预防和持续改进措施也被详细阐述。最后,针对手持版点胶机的特殊故障诊断进行了探讨,并提出了现场故障处理的实战经
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )