揭秘奇异值分解(SVD):自然语言处理中的文本相似度计算与主题提取利器
发布时间: 2024-07-06 18:17:45 阅读量: 144 订阅数: 47 
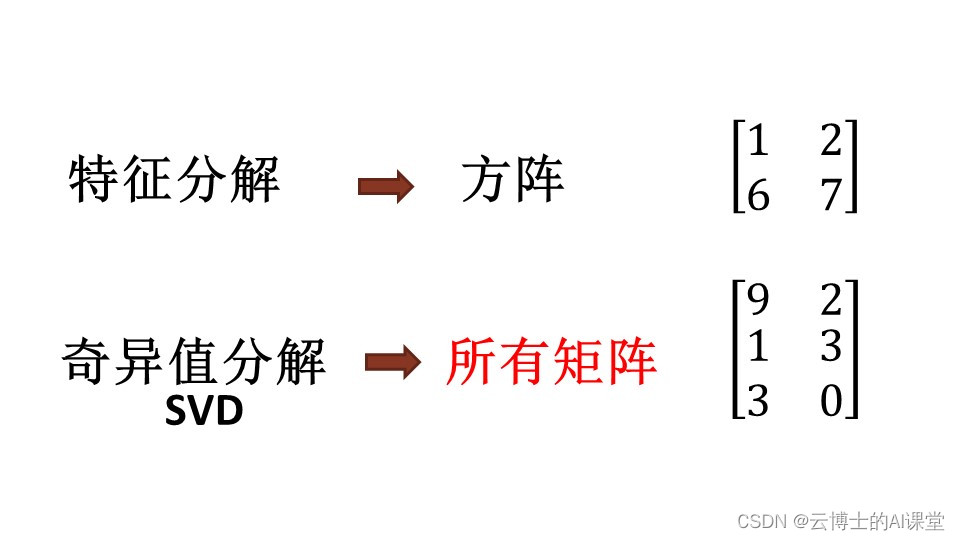
# 1. 奇异值分解(SVD)概述
奇异值分解(SVD)是一种强大的线性代数技术,广泛应用于自然语言处理、数据分析和机器学习等领域。它将一个矩阵分解为三个矩阵的乘积:一个左奇异值矩阵、一个对角奇异值矩阵和一个右奇异值矩阵。
SVD 的核心思想是将一个矩阵表示为一组正交基向量的线性组合。这些基向量称为奇异向量,而奇异值则是这些向量的长度。奇异值对矩阵的秩和条件数等属性提供了重要的见解。
SVD 在文本相似度计算、主题提取和文本分类等自然语言处理任务中发挥着至关重要的作用。它通过将文本表示为向量,并利用奇异值分解来识别相似性和模式,从而提高这些任务的性能。
# 2. SVD的理论基础
### 2.1 线性代数中的SVD
#### 2.1.1 SVD的定义和性质
奇异值分解(SVD)是一种线性代数技术,用于将一个矩阵分解为三个矩阵的乘积:
```
A = UΣV^T
```
其中:
- **A** 是一个 m x n 的实矩阵
- **U** 是一个 m x m 的酉矩阵(即 U^T U = I)
- **Σ** 是一个 m x n 的对角矩阵,对角线上的元素称为奇异值,并且按降序排列
- **V** 是一个 n x n 的酉矩阵(即 V^T V = I)
SVD 的主要性质包括:
- **秩:** A 的秩等于奇异值的非零个数。
- **逆矩阵:** 如果 A 是可逆的,则其逆矩阵可以通过以下方式计算:
```
A^-1 = VΣ^-1U^T
```
- **正交性:** U 和 V 是正交矩阵,这意味着它们的列向量相互正交。
- **奇异值:** 奇异值表示 A 的线性变换的伸缩因子。
#### 2.1.2 SVD的计算方法
SVD 可以通过多种方法计算,包括:
- **Jacobi 方法:** 一种迭代方法,通过一系列旋转将矩阵转换为对角形式。
- **QR 算法:** 一种基于 QR 分解的迭代方法。
- **奇异值分解定理:** 对于任何矩阵 A,都存在一个 SVD 分解。
### 2.2 SVD在文本相似度计算中的应用
SVD 在文本相似度计算中有着广泛的应用,因为文本可以表示为矩阵,并且 SVD 可以揭示文本之间的相似性。
#### 2.2.1 文本向量化
文本向量化是将文本转换为数值向量的过程。可以使用各种方法对文本进行向量化,例如:
- **词袋模型:** 将文本表示为一个向量,其中每个元素表示文本中单词的出现次数。
- **TF-IDF:** 一种加权词袋模型,其中单词的权重由其频率和反文档频率决定。
- **词嵌入:** 将单词表示为低维向量,这些向量捕获单词之间的语义相似性。
#### 2.2.2 基于SVD的文本相似度计算
基于 SVD 的文本相似度计算涉及以下步骤:
1. 将文本向量化,得到一个 m x n 的矩阵 A,其中 m 是文本的数量,n 是向量的大小。
2. 计算 A 的 SVD,得到 U、Σ 和 V。
3. 使用奇异值计算文本之间的相似性。
最常用的相似性度量是余弦相似度,它计算为:
```
相似度 = U^T U_j
```
其中 U_i 和 U_j 是 U 中的第 i 和第 j 行。
# 3.1 基于SVD的文本相似度计算算法
基于SVD的文本相似度计算算法主要有余弦相似度和Jaccard相似度。
#### 3.1.1 余弦相似度
余弦相似度是一种衡量两个向量之间相似性的度量。它计算两个向量的点积与它们各自模长的乘积之比。对于两个文本向量`v1`和`v2`,其余弦相似度定义为:
```python
cosine_similarity = v1.dot(v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
```
余弦相似度取值范围为[-1, 1]。相似度为1表示两个向量完全相同,相似度为-1表示两个向量完全相反,相似度为0表示两个向量正交。
#### 3.1.2 Jaccard相似度
Jaccard相似度是一种衡量两个集合之间相似性的度量。它计算两个集合的交集元素数量与两个集合并集元素数量之比。对于两个文本向量`v1`和`v2`,其Jaccard相似度定义为:
```python
jaccard_similarity = len(set(v1).intersection(set(v2))) / len(set(v1).union(set(v2)))
```
Jaccard相似度取值范围为[0, 1]。相似度为1表示两个集合完全相同,相似度为0表示两个集合没有交集。
### 3.2 基于SVD的文本相似度计算实例
#### 3.2.1 Python实现
```python
import numpy as np
from sklearn.decomposition import TruncatedSVD
# 文本向量化
text1 = "This is a sample text."
text2 = "This is another sample text."
vectorizer = CountVectorizer()
X = vectorizer.fit_transform([text1, text2])
# SVD分解
svd = TruncatedSVD(n_components=2)
U, s, Vh = svd.fit_transform(X)
# 计算文本相似度
cosine_similarity = U[0].dot(U[1]) / (np.linalg.norm(U[0]) * np.linalg.norm(U[1]))
jaccard_similarity = len(set(U[0]).intersection(set(U[1]))) / len(set(U[0]).union(set(U[1])))
print("余弦相似度:", cosine_similarity)
print("Jaccard相似度:", jaccard_similarity)
```
#### 3.2.2 Java实现
```java
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.math3.linear.RealMatrix;
import org.apache.commons.math3.linear.SingularValueDecomposition;
import org.apache.commons.math3.util.FastMath;
// 文本向量化
String text1 = "This is a sample text.";
String text2 = "This is another sample text.";
String[] words = StringUtils.split(text1 + " " + text2);
Vectorizer vectorizer = new Vectorizer(words);
RealMatrix X = vectorizer.transform(new String[]{text1, text2});
// SVD分解
SingularValueDecomposition svd = new SingularValueDecomposition(X);
RealMatrix U = svd.getU();
RealMatrix S = svd.getS();
RealMatrix Vh = svd.getVT();
// 计算文本相似度
double cosineSimilarity = U.getRowVector(0).dotProduct(U.getRowVector(1)) / (U.getRowVector(0).getNorm() * U.getRowVector(1).getNorm());
double jaccardSimilarity = FastMath.min(U.getRowVector(0).getNorm(), U.getRowVector(1).getNorm()) / FastMath.max(U.getRowVector(0).getNorm(), U.getRowVector(1).getNorm());
System.out.println("余弦相似度:" + cosineSimilarity);
System.out.println("Jaccard相似度:" + jaccardSimilarity);
```
# 4. SVD的实践应用:主题提取
### 4.1 基于SVD的主题提取算法
主题提取是一种从文本数据中识别出主要主题或概念的过程。SVD在主题提取中发挥着至关重要的作用,因为它可以将文本数据分解成一系列潜在语义概念,这些概念可以作为主题的代表。
#### 4.1.1 潜在语义分析(LSA)
潜在语义分析(LSA)是一种基于SVD的主题提取算法。它通过以下步骤工作:
1. **文本向量化:**将文本数据转换为一个词频-逆文档频率(TF-IDF)矩阵,其中每个行代表一个文档,每个列代表一个单词。
2. **SVD分解:**对TF-IDF矩阵进行SVD分解,得到三个矩阵:U、Σ和V。
3. **主题提取:**V矩阵的列向量表示潜在语义概念,即主题。
#### 4.1.2 非负矩阵分解(NMF)
非负矩阵分解(NMF)是一种另一种基于SVD的主题提取算法。与LSA不同,NMF将TF-IDF矩阵分解成两个非负矩阵:W和H。
1. **文本向量化:**与LSA相同。
2. **NMF分解:**对TF-IDF矩阵进行NMF分解,得到两个非负矩阵:W和H。
3. **主题提取:**W矩阵的列向量表示主题。
### 4.2 基于SVD的主题提取实例
#### 4.2.1 Gensim实现
Gensim是一个流行的Python库,用于自然语言处理。它提供了基于SVD的主题提取功能。
```python
import gensim
# 加载文本数据
documents = ["文档1", "文档2", "文档3"]
# 创建语料库
corpus = [gensim.corpora.Dictionary(doc).doc2bow(doc) for doc in documents]
# 训练LSA模型
lsa_model = gensim.models.LsiModel(corpus, id2word=dictionary, num_topics=2)
# 获取主题
topics = lsa_model.print_topics()
```
#### 4.2.2 Scikit-learn实现
Scikit-learn是一个流行的Python库,用于机器学习。它也提供了基于SVD的主题提取功能。
```python
from sklearn.decomposition import TruncatedSVD
# 加载文本数据
documents = ["文档1", "文档2", "文档3"]
# 创建向量器
vectorizer = TfidfVectorizer()
# 转换文本数据为TF-IDF矩阵
X = vectorizer.fit_transform(documents)
# 训练SVD模型
svd_model = TruncatedSVD(n_components=2)
# 转换TF-IDF矩阵
X_svd = svd_model.fit_transform(X)
# 获取主题
topics = svd_model.components_
```
# 5. SVD在自然语言处理中的其他应用
### 5.1 文本分类
SVD在文本分类中发挥着重要作用。文本分类的目标是将文本文档分配到预定义的类别中。SVD可以将文本文档表示为低维向量,这些向量可以用来训练分类模型。
#### 5.1.1 基于SVD的文本分类算法
基于SVD的文本分类算法通常遵循以下步骤:
1. **文本向量化:**使用SVD将文本文档转换为低维向量。
2. **特征选择:**选择最能区分不同类别的特征。
3. **分类:**使用分类算法(例如,支持向量机或逻辑回归)将文本向量分配到类别中。
#### 5.1.2 基于SVD的文本分类实例
**Python实现:**
```python
import numpy as np
from sklearn.decomposition import TruncatedSVD
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载文本数据
data = np.loadtxt('text_data.txt', delimiter=',', dtype=str)
labels = data[:, -1]
texts = data[:, :-1]
# 文本向量化
svd = TruncatedSVD(n_components=100)
X = svd.fit_transform(texts)
# 特征选择
selector = SelectKBest(k=1000)
X = selector.fit_transform(X, labels)
# 分类
classifier = LogisticRegression()
classifier.fit(X, labels)
# 测试
X_test, y_test = train_test_split(X, labels, test_size=0.2)
y_pred = classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print('准确率:', accuracy)
```
### 5.2 文本聚类
SVD还可用于文本聚类。文本聚类旨在将文本文档分组到具有相似内容的簇中。SVD可以将文本文档表示为低维向量,这些向量可以用来计算文档之间的相似性。
#### 5.2.1 基于SVD的文本聚类算法
基于SVD的文本聚类算法通常遵循以下步骤:
1. **文本向量化:**使用SVD将文本文档转换为低维向量。
2. **相似性计算:**使用余弦相似度或Jaccard相似度等相似性度量计算文档之间的相似性。
3. **聚类:**使用聚类算法(例如,k-means或层次聚类)将文档聚类到簇中。
#### 5.2.2 基于SVD的文本聚类实例
**Java实现:**
```java
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import org.apache.commons.math3.linear.ArrayRealVector;
import org.apache.commons.math3.linear.RealVector;
import org.apache.commons.math3.ml.clustering.Cluster;
import org.apache.commons.math3.ml.clustering.KMeansPlusPlusClusterer;
public class SvdTextClustering {
public static void main(String[] args) {
// 加载文本数据
List<String> texts = ...
// 文本向量化
Svd svd = new Svd(100);
Map<String, RealVector> vectors = texts.stream()
.collect(Collectors.toMap(text -> text, text -> svd.decompose(text)));
// 相似性计算
double[][] similarities = new double[texts.size()][texts.size()];
for (int i = 0; i < texts.size(); i++) {
for (int j = i + 1; j < texts.size(); j++) {
similarities[i][j] = vectors.get(texts.get(i)).cosine(vectors.get(texts.get(j)));
similarities[j][i] = similarities[i][j];
}
}
// 聚类
KMeansPlusPlusClusterer clusterer = new KMeansPlusPlusClusterer(3);
List<Cluster<RealVector>> clusters = clusterer.cluster(new ArrayRealVector[][] { vectors.values().toArray(new ArrayRealVector[0]) });
// 输出聚类结果
for (Cluster<RealVector> cluster : clusters) {
System.out.println("簇:" + cluster.getPoints().size());
for (RealVector vector : cluster.getPoints()) {
System.out.println(" " + vectors.entrySet().stream()
.filter(entry -> entry.getValue().equals(vector))
.map(Map.Entry::getKey)
.findFirst().get());
}
}
}
}
```
### 5.3 文本摘要
SVD还可以用于文本摘要。文本摘要的目标是生成文本文档的简短、信息丰富的摘要。SVD可以将文本文档表示为低维向量,这些向量可以用来识别文档中最重要的主题。
#### 5.3.1 基于SVD的文本摘要算法
基于SVD的文本摘要算法通常遵循以下步骤:
1. **文本向量化:**使用SVD将文本文档转换为低维向量。
2. **主题识别:**使用潜在语义分析(LSA)或非负矩阵分解(NMF)等算法识别文档中的主题。
3. **摘要生成:**根据识别的主题生成文本摘要。
#### 5.3.2 基于SVD的文本摘要实例
**Python实现:**
```python
import gensim
from gensim import corpora
from gensim.summarization import summarize
# 加载文本数据
text = ...
# 文本向量化
dictionary = corpora.Dictionary([text.split()])
corpus = [dictionary.doc2bow(text.split())]
# 主题识别
lsa = gensim.models.LsiModel(corpus, id2word=dictionary, num_topics=2)
topics = lsa.print_topics()
# 摘要生成
summary = summarize(text, ratio=0.5)
print('摘要:', summary)
```
# 6. SVD的局限性和未来展望
### 6.1 SVD的局限性
尽管SVD在文本相似度计算、主题提取和自然语言处理的其他应用中取得了显著的成功,但它也存在一些局限性:
- **计算成本高:**SVD的计算涉及矩阵分解,这对于大型数据集来说可能是计算密集型的。
- **对噪声敏感:**SVD对文本中的噪声和异常值敏感,这可能会影响其准确性。
- **解释性差:**SVD的输出是奇异值和奇异向量,这些向量可能难以解释,从而限制了其可解释性。
- **维度依赖:**SVD的性能取决于分解的维度,选择合适的维度可能具有挑战性。
### 6.2 SVD的未来展望
尽管存在局限性,SVD在自然语言处理领域仍具有广阔的未来展望:
- **并行化和分布式计算:**随着计算能力的提高,可以探索并行化和分布式计算技术来提高SVD的效率。
- **鲁棒性增强:**研究人员正在探索提高SVD对噪声和异常值的鲁棒性的方法。
- **可解释性增强:**通过开发新的解释技术,可以提高SVD输出的可解释性。
- **新兴应用:**SVD在自然语言处理之外的新兴应用,例如图像处理和语音识别,正在被积极探索。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
奇异值分解(SVD)是一种强大的数学工具,广泛应用于各个领域,包括自然语言处理、推荐系统、图像处理、金融、机器学习、信号处理、数据挖掘、计算机视觉、生物信息学、医学影像、科学计算、工业控制、电气工程、机械工程、土木工程、化学工程、材料科学、环境科学和社会科学。SVD擅长高维数据降维,提取特征,分析数据规律,解决复杂问题。通过揭秘SVD的原理和实战应用,本专栏将帮助读者掌握数据降维核心技术,提升模型性能,优化算法效率,从海量数据中发现隐藏价值,赋能计算机视觉,助力生物医学研究,提升医学影像诊断效率,解决复杂科学问题,保障工业生产安全高效,确保电力系统稳定运行,提升机械设备可靠性,保障建筑安全,提升化工生产效率,推动材料创新,助力环境保护,洞察社会舆情。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PLC系统故障预防攻略:预测性维护减少停机时间的策略

# 摘要
本文深入探讨了PLC系统的故障现状与挑战,并着重分析了预测性维护的理论基础和实施策略。预测性维护作为减少故障发生和提高系统可靠性的关键手段,本文不仅探讨了故障诊断的理论与方法,如故障模式与影响分析(FMEA)、数据驱动的故障诊断技术,以及基于模型的故障预测,还论述了其数据分析技术,包括统计学与机器学习方法、时间序列分析以及数据整合与
【大规模部署的智能语音挑战】:V2.X SDM在大规模部署中的经验与对策

# 摘要
随着智能语音技术的快速发展,它在多个行业得到了广泛应用,同时也面临着众多挑战。本文首先回顾了智能语音技术的兴起背景,随后详细介绍了V2.X SDM平台的架构、核心模块、技术特点、部署策略、性能优化及监控。在此基础上,本文探讨了智能语音技术在银行业和医疗领域的特定应用挑战,重点分析了安全性和复杂场景下的应用需求。文章最后展望了智能语音和V2.X SDM
多模手机伴侣高级功能揭秘:用户手册中的隐藏技巧
# 摘要
多模手机伴侣是一款集创新功能于一身的应用程序,旨在提供全面的连接与通信解决方案,支持多种连接方式和数据同步。该程序不仅提供高级安全特性,包括加密通信和隐私保护,还支持个性化定制,如主题界面和自动化脚本。实践操作指南涵盖了设备连接、文件管理以及扩展功能的使用。用户可利用进阶技巧进行高级数据备份、自定义脚本编写和性能优化。安全与隐私保护章节深入解释了数据保护机制和隐私管理。本文展望
【音频同步与编辑】:为延时作品添加完美音乐与声效的终极技巧
# 摘要
音频同步与编辑是多媒体制作中不可或缺的环节,对于提供高质量的视听体验至关重要。本论文首先介绍了音频同步与编辑的基础知识,然后详细探讨了专业音频编辑软件的选择、配置和操作流程,以及音频格式和质量的设置。接着,深入讲解了音频同步的理论基础、时间码同步方法和时间管理技巧。文章进一步聚焦于音效的添加与编辑、音乐的混合与平衡,以及音频后期处理技术。最后,通过实际项目案例分析,展示了音频同步与编辑在不同项目中的应用,并讨论了项目完成后的质量评估和版权问题。本文旨在为音频技术人员提供系统性的理论知识和实践指南,增强他们对音频同步与编辑的理解和应用能力。
# 关键字
音频同步;音频编辑;软件配置;
飞腾X100+D2000启动阶段电源管理:平衡节能与性能
# 摘要
本文旨在全面探讨飞腾X100+D2000架构的电源管理策略和技术实践。第一章对飞腾X100+D2000架构进行了概述,为读者提供了研究背景。第二章从基础理论出发,详细分析了电源管理的目的、原则、技术分类及标准与规范。第三章深入探讨了在飞腾X100+D2000架构中应用的节能技术,包括硬件与软件层面的节能技术,以及面临的挑战和应对策略。第四章重点介绍了启动阶
【脚本与宏命令增强术】:用脚本和宏命令提升PLC与打印机交互功能(交互功能强化手册)
# 摘要
本文探讨了脚本和宏命令的基础知识、理论基础、高级应用以及在实际案例中的应用。首先概述了脚本与宏命令的基本概念、语言构成及特点,并将其与编译型语言进行了对比。接着深入分析了PLC与打印机交互的脚本实现,包括交互脚本的设计和测试优化。此外,本文还探讨了脚本与宏命令在数据库集成、多设备通信和异常处理方面的高级应用。最后,通过工业
【软件使用说明书的可读性提升】:易理解性测试与改进的全面指南
# 摘要
软件使用说明书作为用户与软件交互的重要桥梁,其重要性不言而喻。然而,如何确保说明书的易理解性和高效传达信息,是一项挑战。本文深入探讨了易理解性测试的理论基础,并提出了提升使用说明书可读性的实践方法。同时,本文也分析了基于用户反馈的迭代优化策略,以及如何进行软件使用说明书的国际化与本地化。通过对成功案例的研究与分析,本文展望了未来软件使用说明书设
【实战技巧揭秘】:WIN10LTSC2021输入法BUG引发的CPU占用过高问题解决全记录

# 摘要
本文对Win10 LTSC 2021版本中出现的输入法BUG进行了详尽的分析与解决策略探讨。首先概述了BUG现象,然后通过系统资源监控工具和故障排除技术,对CPU占用过高问题进行了深入分析,并初步诊断了输入法BUG。在此基础上,本文详细介绍了通过系统更新
【提升R-Studio恢复效率】:RAID 5数据恢复的高级技巧与成功率
# 摘要
RAID 5作为一种广泛应用于数据存储的冗余阵列技术,能够提供较好的数据保护和性能平衡。本文首先概述了RAID 5数据恢复的重要性,随后介绍了RAID 5的基础理论,包括其工作原理、故障类型及数据恢复前的准备工作。接着,文章深入探讨了提升RAID 5数据恢复成功率的高级技巧,涵盖了硬件级别和软件工具的应用,以及文件系统结构和数据一致性检查。通过实际案例分析,
数据挖掘在医疗健康的应用:疾病预测与治疗效果分析(如何通过数据挖掘改善医疗决策)

# 摘要
数据挖掘技术在医疗健康领域中的应用正逐渐展现出其巨大潜力,特别是在疾病预测和治疗效果分析方面。本文探讨了数据挖掘的基础知识及其与医疗健康领域的结合,并详细分析了数据挖掘技术在疾病预测中的实际应用,包括模型构建、预处理、特征选择、验证和优化策略。同时,文章还研究了治疗效果分析的目标、方法和影响因素,并探讨了数据隐私和伦理问题,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )