Darknet YOLO图像检测:部署与集成,让算法落地实战
发布时间: 2024-08-18 03:50:23 阅读量: 37 订阅数: 22 
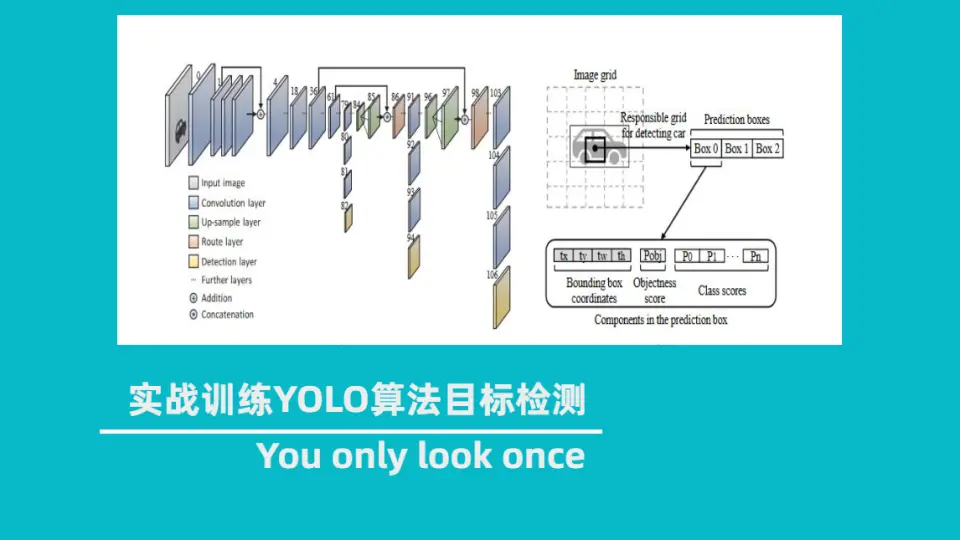
# 1. Darknet YOLO图像检测概述**
Darknet YOLO(You Only Look Once)是一种实时目标检测算法,以其速度和准确性而闻名。它基于卷积神经网络(CNN),将图像处理为单个神经网络,一次性预测所有边界框和类别概率。与传统的目标检测算法相比,YOLO速度更快,因为它不需要生成候选区域或执行多个推理步骤。
YOLO算法有几个关键特性:
- **单次评估:**YOLO将图像划分为网格,并为每个网格单元预测多个边界框和类别概率。
- **端到端训练:**YOLO使用单个神经网络训练,无需预处理或后处理步骤。
- **实时处理:**YOLO可以实时处理图像,使其适用于视频流和实时应用程序。
# 2. Darknet YOLO部署与环境搭建
### 2.1 Darknet框架安装与配置
#### 依赖库安装
Darknet框架基于C语言开发,需要安装以下依赖库:
- OpenCV
- CUDA(可选,用于GPU加速)
- CUDNN(可选,用于GPU加速)
在Ubuntu系统中,可以通过以下命令安装这些依赖库:
```bash
sudo apt-get install libopencv-dev
sudo apt-get install nvidia-cuda-toolkit
sudo apt-get install libcudnn7-dev
```
#### Darknet编译与安装
下载Darknet源代码:
```bash
git clone https://github.com/AlexeyAB/darknet
```
进入Darknet目录并编译:
```bash
cd darknet
make
```
### 2.2 YOLO模型下载与导入
#### 模型下载
预训练的YOLO模型可以从Darknet官方网站下载:
```bash
wget https://pjreddie.com/media/files/yolov3.weights
```
#### 模型导入
将下载的模型文件复制到Darknet目录下的`cfg`文件夹中:
```bash
cp yolov3.weights cfg/yolov3.weights
```
### 2.3 硬件加速与优化
#### GPU加速
如果安装了CUDA和CUDNN,可以通过修改`Makefile`文件启用GPU加速:
```
GPU=1
CUDNN=1
```
#### 参数优化
Darknet提供了一些参数用于优化YOLO模型的性能:
| 参数 | 说明 | 默认值 |
|---|---|---|
| batch | 训练批次大小 | 64 |
| subdivisions | 每个批次划分的子批次数量 | 16 |
| max_batches | 训练的最大批次数量 | 50000 |
| learning_rate | 学习率 | 0.001 |
| momentum | 动量 | 0.9 |
| decay | 权重衰减 | 0.0005 |
这些参数可以在`cfg/yolov3.cfg`文件中进行调整。
#### 代码示例
以下代码展示了如何加载预训练的YOLO模型并进行图像检测:
```python
import darknet
# 加载模型
net = darknet.load_net("cfg/yolov3.cfg", "yolov3.weights", 0)
meta = darknet.load_meta("cfg/coco.data")
# 加载图像
image = darknet.load_image("image.jpg")
# 进行检测
detections = darknet.detect_image(net, meta, image)
# 打印检测结果
for detection in detections:
print(f"Class: {detection[0]}")
print(f"Confidence: {detection[1]}")
print(f"Bounding box: {detection[2]}")
```
**逻辑分析:**
* `load_net()`函数加载预训练的YOLO模型和权重。
* `load_meta()`函数加载类名和标签信息。
* `load_image()`函数将图像加载到Darknet数据结构中。
* `detect_image()`函数执行图像检测并返回检测结果。
* 检测结果包含类名、置信度和边界框信息。
# 3. Darknet YOLO图像检测实践**
### 3.1 图像预处理与增强
图像预处理是图像检测任务中的关键步骤,它可以有效地提高模型的检测精度和速度。Darknet YOLO支持多种图像预处理技术,包括:
- **图像缩放和裁剪:**将图像缩放或裁剪到特定大小,以适应模型的输入尺寸。
- **颜色空间转换:**将图像从RGB转换为其他颜色空间,如HSV或YCbCr,以增强某些特征。
- **归一化:**将图像像素值归一化到[0, 1]范围内,以减轻光照变化的影响。
- **数据增强:**通过随机翻转、旋转、缩放和裁剪图像,增加训练数据的多样性。
**代码块:**
```python
import cv2
import numpy as np
def preprocess_i
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Darknet YOLO 图像检测:从零到英雄》专栏是目标检测算法的全面指南,涵盖了从基础知识到高级应用的各个方面。它提供了分步教程,从构建训练数据集到疑难杂症排除,以及算法比较和嵌入式部署。专栏还深入探讨了图像预处理、目标跟踪、视频流实时检测、自动驾驶、医学图像分析、安全监控、零售、农业、制造和教育等领域的应用。此外,它还讨论了与 TensorFlow 和 PyTorch 的集成,以实现算法互通。通过这个专栏,读者可以掌握 Darknet YOLO 图像检测算法,并将其应用于广泛的现实世界场景。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
JY01A直流无刷IC全攻略:深入理解与高效应用

# 摘要
本文详细介绍了JY01A直流无刷IC的设计、功能和应用。文章首先概述了直流无刷电机的工作原理及其关键参数,随后探讨了JY01A IC的功能特点以及与电机集成的应用。在实践操作方面,本文讲解了JY01A IC的硬件连接、编程控制,并通过具体
数据备份与恢复:中控BS架构考勤系统的策略与实施指南

# 摘要
在数字化时代,数据备份与恢复已成为保障企业信息系统稳定运行的重要组成部分。本文从理论基础和实践操作两个方面对中控BS架构考勤系统的数据备份与恢复进行深入探讨。文中首先阐述了数据备份的必要性及其对业务连续性的影响,进而详细介绍了不同备份类型的选择和备份周期的制定。随后,文章深入解析了数据恢复的原理与流程,并通过具体案例分析展示了恢复技术的实际应用。接着,本文探讨
【TongWeb7负载均衡秘笈】:确保请求高效分发的策略与实施
.webp)
# 摘要
本文从基础概念出发,对负载均衡进行了全面的分析和阐述。首先介绍了负载均衡的基本原理,然后详细探讨了不同的负载均衡策略及其算法,包括轮询、加权轮询、最少连接、加权最少连接、响应时间和动态调度算法。接着,文章着重解析了TongWeb7负载均衡技术的架构、安装配置、高级特性和应用案例。在实施案例部分,分析了高并发Web服务和云服务环境下负载
【Delphi性能调优】:加速进度条响应速度的10项策略分析

# 摘要
本论文首先概述了信号定位技术的基本概念和重要性,随后深入分析了三角测量和指纹定位两种主要技术的工作原理、实际应用以及各自的优势与不足。通过对三角测量定位模型的解析,我们了解到其理论基础、精度影响因素以及算法优化策略。指纹定位技术部分,则侧重于其理论框架、实际操作方法和应用场
【PID调试实战】:现场调校专家教你如何做到精准控制

# 摘要
PID控制作为一种历史悠久的控制理论,一直广泛应用于工业自动化领域中。本文从基础理论讲起,详细分析了PID参数的理论分析与选择、调试实践技巧,并探讨了PID控制在多变量、模糊逻辑以及网络化和智能化方面的高级应用。通过案例分析,文章展示了PID控制在实际工业环境中的应用效果以及特殊环境下参数调整的策略。文章最后展望了PID控制技术的发展方
网络同步新境界:掌握G.7044标准中的ODU flex同步技术

# 摘要
本文详细探讨了G.7044标准与ODU flex同步技术,首先介绍了该标准的技术原理,包括时钟同步的基础知识、G.7044标准框架及其起源与应用背景,以及ODU flex技术
字符串插入操作实战:insert函数的编写与优化

# 摘要
字符串插入操作是编程中常见且基础的任务,其效率直接影响程序的性能和可维护性。本文系统地探讨了字符串插入操作的理论基础、insert函数的编写原理、使用实践以及性能优化。首先,概述了insert函数的基本结构、关键算法和代码实现。接着,分析了在不同编程语言中insert函数的应用实践,并通过性能测试揭示了各种实现的差异。此外,本文还探讨了性能优化策略,包括内存使用和CPU效率提升,并介绍了高级数据结
环形菜单的兼容性处理

# 摘要
环形菜单作为一种用户界面元素,为软件和网页设计提供了新的交互体验。本文首先介绍了环形菜单的基本知识和设计理念,重点探讨了其通过HTML、CSS和JavaScript技术实现的方法和原理。然后,针对浏览器兼容性问题,提出了有效的解决方案,并讨论了如何通过测试和优化提升环形菜单的性能和用户体验。本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )