高效处理大规模文本数据的词频计算方法
发布时间: 2024-02-22 08:37:16 阅读量: 42 订阅数: 36 
# 1. 简介
## 1.1 词频计算的重要性
在文本数据处理中,词频计算是一项至关重要的任务。它可以帮助我们了解文本中出现频率较高的词语,从而进行文本分类、情感分析以及关键词提取等应用。词频计算的准确性和效率直接影响着后续数据处理的质量和速度。
## 1.2 面临的挑战
处理大规模文本数据时,词频计算面临着数据量大、计算复杂度高的挑战。传统的串行计算方式往往无法满足大规模数据的处理需求,需要寻找高效并行计算方法。
## 1.3 目标与意义
本文旨在探讨高效处理大规模文本数据的词频计算方法,以提高数据处理的效率和准确性。通过研究和应用更高效的计算方法,可以加快文本数据处理的速度,提升计算的准确性,进而更好地支持各种文本数据应用场景的需求。
# 2. 数据预处理
数据预处理在文本数据处理中起着至关重要的作用。它包括了文本数据清洗、分词处理和停用词过滤等步骤,这些步骤的质量将直接影响后续词频计算的准确性和效率。
### 2.1 文本数据清洗
在进行词频计算之前,通常需要对文本数据进行清洗,去除一些无关信息,如HTML标签、特殊符号、URL链接等。文本清洗的过程能够提升后续分词和词频计算的效果,避免噪音数据对结果造成干扰。
```python
def clean_text(text):
# 去除HTML标签
clean_text = re.sub('<[^>]*>', '', text)
# 去除特殊符号
clean_text = re.sub('[^a-zA-Z]', ' ', clean_text)
return clean_text
```
上述示例代码展示了一个简单的文本数据清洗函数,利用正则表达式去除HTML标签和特殊符号。
### 2.2 分词处理
分词是将文本拆分成一个个独立的词语或词组的过程,是词频计算的基础。常见的分词方法有基于规则的分词、基于统计的分词和基于深度学习的分词等。
```java
public List<String> tokenizeText(String text) {
List<String> tokens = new ArrayList<>();
BreakIterator breakIterator = BreakIterator.getWordInstance();
breakIterator.setText(text);
int start = breakIterator.first();
int end = breakIterator.next();
while (end != BreakIterator.DONE) {
String token = text.substring(start, end).trim();
if (!token.isEmpty()) {
tokens.add(token);
}
start = end;
end = breakIterator.next();
}
return tokens;
}
```
以上Java示例代码演示了利用BreakIterator进行基本的英文分词处理。
### 2.3 停用词过滤
停用词是指在文本分析过程中需过滤掉的一些常见词语,如“的”、“是”、“在”等,这些词语在词频计算时往往没有太大的实际意义。因此,在词频计算前需要对文本进行停用词过滤处理。
```go
func filterStopWords(tokens []string) []string {
stopWords := map[string]struct{}{
"is": {}, "the": {}, "and": {}, // 定义停
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将深入探讨文本挖掘中的词频-逆文档频率(TF-IDF)算法,从基础概念到实际应用进行详细解析。首先,通过《理解文本挖掘中的词频统计》和《探索文本处理中的词频计算技术》,读者将对词频统计有全面的认识。紧接着,文章《如何利用Python进行文本词频分析》将带领读者通过实际案例掌握Python在文本词频分析中的应用。对于TF-IDF算法,《初探逆文档频率在信息检索中的应用》、《深入掌握TF-IDF算法原理与实现》和《使用NLP技术优化词频-逆文档频率算法》将从多个角度进行解读与实践。此外,还涵盖了大规模文本数据处理、文本分类、搜索引擎应用以及信息检索结果优化等多个方面,让读者在阅读完整专栏后可以全面掌握词频-逆文档频率算法及其在文本挖掘领域的广泛应用。
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据清洗艺术】:R语言density函数在数据清洗中的神奇功效

# 1. 数据清洗的必要性与R语言概述
## 数据清洗的必要性
在数据分析和挖掘的过程中,数据清洗是一个不可或缺的环节。原始数据往往包含错误、重复、缺失值等问题,这些问题如果不加以处理,将严重影响分析结果的准确性和可靠性。数据清洗正是为了纠正这些问题,提高数据质量,从而为后续的数据分析和模型构建打下坚实的基础。
## R语言概述
R语言是一种用于统计分析
R语言数据分析高级教程:从新手到aov的深入应用指南
# 1. R语言基础知识回顾
## 1.1 R语言简介
R语言是一种开源编程语言和软件环境,特别为统计计算和图形表示而设计。自1997年由Ross Ihaka和Robert Gentleman开发以来,R已经成为数据科学领域广受欢迎的工具。它支持各种统计技术,包括线性与非线性建模、经典统计测试、时间序列分析、分类、聚类等,并且提供了强大的图形能力。
## 1.2 安装与配置R环境
要开始使用R语言,首先需要在计算机上安装R环境。用户可以访问官方网站
【R语言t.test实战演练】:从数据导入到结果解读,全步骤解析

# 1. R语言t.test基础介绍
统计学是数据分析的核心部分,而t检验是其重要组成部分,广泛应用于科学研究和工业质量控制中。在R语言中,t检验不仅易用而且功能强大,可以帮助我们判断两组数据是否存在显著差异,或者某组数据是否显著不同于预设值。本章将为你介绍R语言中t.test函数的基本概念和用法,以便你能快速上手并理解其在实际工作中的应用价值。
## 1.1 R语言t.test函数概述
R语言t.test函数是一个
prop.test函数揭秘:R语言中的比例检验,专家级指南
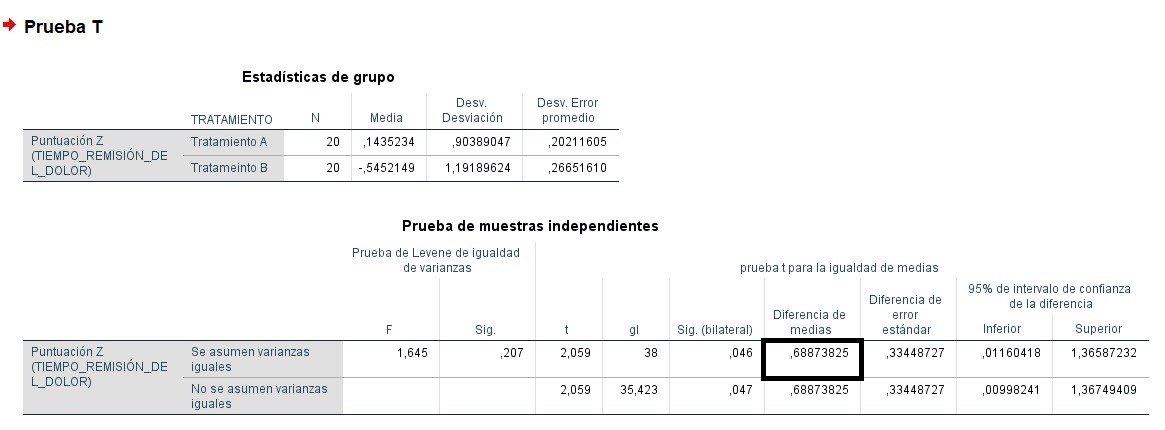
# 1. prop.test函数基础介绍
## 1.1 prop.test函数的概述
`prop.test`是R语言中的一个内置函数,主要用于执行比例检验,即检验一个或两个样本的比例是否等于某个特定值(单比例检验)或检验两个样本的比例是否存在显著差异(双比例检验)。它是统计分析中非常实用的一个工具,特别是在涉及比例或概率的假设检验问题中
【保险行业extRemes案例】:极端值理论的商业应用,解读行业运用案例
# 1. 极端值理论概述
极端值理论是统计学的一个重要分支,专注于分析和预测在数据集中出现的极端情况,如自然灾害、金融市场崩溃或保险索赔中的异常高额索赔。这一理论有助于企业和机构理解和量化极端事件带来的风险,并设计出更有效的应对策略。
## 1.1 极端值理论的定义与重要性
极端值理论提供了一组统计工具,
R语言数据包个性化定制:满足复杂数据分析需求的秘诀

# 1. R语言简介及其在数据分析中的作用
## 1.1 R语言的历史和特点
R语言诞生于1993年,由新西兰奥克兰大学的Ross Ihaka和Robert Gentleman开发,其灵感来自S语言,是一种用于统计分析、图形表示和报告的编程语言和软件环境。R语言的特点是开源、功能强大、灵活多变,它支持各种类型的数据结
【R语言时间序列预测大师】:利用evdbayes包制胜未来

# 1. R语言与时间序列分析基础
在数据分析的广阔天地中,时间序列分析是一个重要的分支,尤其是在经济学、金融学和气象学等领域中占据
【R语言统计推断】:ismev包在假设检验中的高级应用技巧

# 1. R语言与统计推断基础
## 1.1 R语言简介
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。由于其强大的数据处理能力、灵活的图形系统以及开源性质,R语言被广泛应用于学术研究、数据分析和机器学习等领域。
## 1.2 统计推断基础
统计推断是统计学中根据样本数据推断总体特征的过程。它包括参数估计和假设检验两大主要分支。参数估计涉及对总体参数(如均值、方差等)的点估计或区间估计。而
【R语言极值事件预测】:评估和预测极端事件的影响,evd包的全面指南

# 1. R语言极值事件预测概览
R语言,作为一门功能强大的统计分析语言,在极值事件预测领域展现出了其独特的魅力。极值事件,即那些在统计学上出现概率极低,但影响巨大的事件,是许多行业风险评估的核心。本章节,我们将对R语言在极值事件预测中的应用进行一个全面的概览。
首先,我们将探究极值事
【R语言编程实践手册】:evir包解决实际问题的有效策略

# 1. R语言与evir包概述
在现代数据分析领域,R语言作为一种高级统计和图形编程语言,广泛应用于各类数据挖掘和科学计算场景中。本章节旨在为读者提供R语言及其生态中一个专门用于极端值分析的包——evir——的基础知识。我们从R语言的简介开始,逐步深入到evir包的核心功能,并展望它在统计分析中的重要地位和应用潜力。
首先,我们将探讨R语言作为一种开源工具的优势,以及它如何在金融
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )