【编译原理问答集】:权威解答常见编译问题
发布时间: 2024-12-16 03:03:23 阅读量: 6 订阅数: 12 

毕业设计-线性规划模型Python代码.rar

参考资源链接:[《编译原理》清华版课后习题答案详解](https://wenku.csdn.net/doc/4r3oyj2zqg?spm=1055.2635.3001.10343)
# 1. 编译原理基础概念
编译原理是研究如何将一种语言(源语言)转换为另一种语言(目标语言)的学科。编译器,作为编译原理的核心工具,承担着将高级编程语言代码转化为机器能理解的低级代码的任务。本章将从基础概念出发,引导读者了解编译器的主要组成部分及其工作流程。我们将从编译器的基本概念和作用讲起,逐步深入到编译过程中各个阶段的功能和作用,最终达到一个全面而深入的理解。
编译器的基本功能可以分为五大阶段:
1. 词法分析(Lexical Analysis)
2. 语法分析(Syntax Analysis)
3. 语义分析(Semantic Analysis)
4. 中间代码生成(Intermediate Code Generation)
5. 代码优化与生成(Code Optimization & Generation)
每个阶段都有其独特的任务和挑战。在词法分析阶段,编译器将源代码分解为一系列的记号(tokens)。接下来的语法分析阶段则会基于这些记号构建出一个语法结构,通常表示为一棵语法树。语义分析阶段,编译器检查代码的含义,确保语句在逻辑上是合理的。中间代码生成阶段将高级抽象的代码转换为一种中间形式,既方便进行优化,也便于后续转换为目标机器代码。最后,在代码优化和目标代码生成阶段,编译器将中间代码转换成优化的目标代码,并准备将这些代码用于具体的硬件平台。
整个编译过程需要编译器设计者具有深入的理论知识和实践经验。随着现代编程语言和计算平台的不断发展,编译原理这门学科持续面临着新的挑战和机遇。本章将为读者打下坚实的基础,以便更好地理解后续各章节中所涉及的更复杂的技术和概念。
# 2. ```
# 第二章:编译过程中的词法分析技术
词法分析是编译过程中的初步阶段,负责将源代码文本转换为一组更易于后续处理的符号(tokens),这些符号对应于程序中的常量、变量名、运算符和关键字等。构建一个高效的词法分析器(lexical analyzer 或 lexer)对于编译器的性能至关重要。本章节将深入探讨词法分析的构建方法、优化策略以及测试与调试技巧。
## 2.1 词法分析器的构建
### 2.1.1 正则表达式和有限自动机(FA)
在构建词法分析器时,正则表达式用于定义语言中各个词法单元(tokens)的模式,而有限自动机(FA)则作为一种数学模型,用于执行匹配正则表达式的算法。FA可以是确定性的(DFA)或非确定性的(NFA),它们在实现词法分析器时都扮演着核心角色。
- **正则表达式**是词法分析中的基础,它以简洁的方式表达了复杂的模式匹配规则。例如,可以使用正则表达式来匹配标识符、数字和运算符等。
- **确定性有限自动机(DFA)**是一种有限自动机,对于给定的输入符号,其状态转移是确定的。DFA可以由正则表达式直接转换而来,其转换过程是编译原理中的一个重要概念,常常在理论研究和词法分析器生成工具中使用。
### 2.1.2 工具Lex/Yacc在词法分析中的应用
在实际开发中,工程师通常不直接从正则表达式到有限自动机构建词法分析器,而是借助于成熟的工具如Lex和Yacc。这些工具极大地简化了词法分析器的构建过程。
- **Lex**是一个词法分析器生成器,它可以读入包含正则表达式的规则文件,并输出C语言源代码,这些代码实现了一个词法分析器。
- **Yacc**用于生成语法分析器,它与Lex常被一起使用。Yacc从语法规则文件中生成用于语法分析的代码。词法分析器和语法分析器通常紧密配合,一起构成编译器前端。
## 2.2 词法分析器的优化
### 2.2.1 最小化有限自动机
有限自动机(尤其是DFA)的大小直接影响到词法分析器的效率。一个简化的、最小化的FA可以减少状态数和转移次数,从而加快分析速度。
- **最小化FA**的过程涉及将DFA中的冗余状态合并,得到一个最小化的状态集合。这个过程可以减少内存的使用,提高运行效率。
- 对于大型的词法分析器,手动最小化FA是一项繁琐的任务。一般的做法是使用工具自动生成最小化的FA,例如通过Lex工具生成的词法分析器已经是相对优化过的。
### 2.2.2 词法分析器的测试和调试技巧
编译器的开发和维护中,词法分析器的测试和调试工作不容忽视。正确的测试可以确保词法分析器准确无误地处理各种情况,包括边界条件和异常输入。
- **白盒测试**关注于词法分析器内部的逻辑,确保每个状态转移和规则匹配都按照预期工作。
- **黑盒测试**则侧重于词法分析器的外部行为,测试不同的输入组合是否能够产生正确的token序列。
- 在调试过程中,输出详细的错误信息和诊断信息对于问题定位至关重要。这包括了报告未识别的字符、意外的token和状态转换错误等。
代码示例展示了一个简单的词法分析器的生成过程,使用了Lex工具:
```lex
%{
#include <stdio.h>
%}
[0-9]+ { printf("NUMBER: %s\n", yytext); }
[a-zA-Z]+ { printf("IDENTIFIER: %s\n", yytext); }
"+"|"-"|"*"|"|"|"("|" ")" { printf("OPERATOR: %s\n", yytext); }
\n { /* Ignore */ }
. { printf("UNKNOWN: %s\n", yytext); }
int main(int argc, char **argv) {
yylex();
return 0;
}
```
上述示例中定义了基本的词法规则,包括对数字、标识符、运算符和未知字符的匹配规则。此Lex代码会生成一个C源文件,其中包含一个词法分析器。每次读取输入文本中的token时,`yylex()`函数会被调用。
参数`yytext`是当前匹配到的token字符串,它在词法规则中被引用,用以输出识别到的token信息。
```c
void yylex(void) {
...
while (c != '\0') {
switch (c) {
...
case '0' ... '9':
BEGIN(INITIAL);
yylval.sval = strdup(yytext);
return NUMBER;
...
}
...
}
...
}
```
此函数部分展示了Lex如何根据输入字符`c`识别token,并执行相应的动作。例如,当读入的字符为数字时,会将状态切换到`INITIAL`,创建一个临时的字符串存储当前识别的数字序列,并返回一个`NUMBER`类型的token。
在Lex的词法分析器生成之后,通常需要与Yacc生成的语法分析器结合使用,共同完成编译器的前端工作。
```
# 3. 语法分析与语法树的生成
## 3.1 上下文无关文法(CFG)和语法树
### 3.1.1 CFG的定义和特性
上下文无关文法(Context-Free Grammar, CFG)是形式语言理论中的一个基本概念,它用于描述编程语言和自然语言的语法结构。CFG由一系列的产生式(production rules)构成,每个产生式描述了一种非终结符如何展开成其他符号(终结符或非终结符)的组合。一个CFG由四个部分组成:
1. **终结符集合**:构成语言的最小单位,如在编程语言中通常是关键字、操作符和标识符。
2. **非终结符集合**:也称为变量,是用于构建语言的中间结构的符号。
3. **开始符号**:一个特殊的非终结符,是整个语法的入口点。
4. **产生式规则**:定义了非终结符如何展开成终结符或其他非终结符序列的规则。
CFG的特点包括:
- **无上下文依赖**:产生式规则的应用不依赖于非终结符周围的符号,这使得CFG在编译过程中易于处理。
- **递归性质**:CFG常常包含递归规则,允许产生式规则嵌套使用,这对于表达自然语言和编程语言的嵌套结构非常有用。
在编译器设计中,CFG是构建语法分析器和生成语法树的基础。语法分析器使用CFG来识别源代码中符合语言规范的结构,并构建出一棵描述程序语法结构的树,即语法树。
### 3.1.2 语法树的构建方法和应用
语法树是源代码的抽象表示,它以树状结构展示了程序的语法成分及其层次关系。构建语法树的过程通常分为两个步骤:
1. **分析输入**:首先,语法分析器读取输入的源代码,并根据CFG产生式规则进行分析。
2. **构造树结构**:分析过程中,每当一个产生式规则被匹配成功时,就在树中创建相应的节点,并将其子节点与父节点连接。
语法树的应用非常广泛,包括但不限于:
- **代码优化**:通过语法树,编译器可以更方便地进行各种代码优化,如常量折叠、死代码消除等。
- **代码生成**:在目标代码生成阶段,编译器将根据语法树生成中间代码或机器代码。
- **代码插桩与分析**:在静态分析和测试工具中,语法树用于插桩(插入额外的代码)和程序分析。
### 3.1.3 代码块:构建语法树的伪代码
下面的伪代码展示了构建语法树的基本逻辑:
```plaintext
function constructSyntaxTree(tokens):
symbolStack = new Stack()
tree = new SyntaxTreeNode("Start") // 创建根节点
for token in tokens:
if token is non-terminal:
s
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《编译原理》清华版课后答案专栏是一本全面的编译原理学习指南,涵盖了从理论基础到实际应用的方方面面。专栏内容丰富,包括构建高效抽象语法树、优化中间表示和代码生成、实现语义分析、处理编译器错误、诊断和修复编译错误、模块化编译器构建、提升编译效率、从理论到实践的编译器项目开发、不同语言编译过程的深入探索、自定义编程语言编译器、权威解答常见编译问题、代码质量保证的关键技术探讨、即时编译技术的核心原理与应用、为各平台生成代码的高级技术、防止代码注入与执行的有效策略、编译时与运行时内存优化的艺术等主题。该专栏旨在帮助读者深入理解编译原理,掌握编译器设计和实现的最佳实践,并为实际编译器开发提供宝贵的指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实验参数设定指南】:在Design-Expert中精确定义响应变量与因素

# 摘要
本论文全面介绍Design-Expert软件及其在实验设计中的应用。第一章为软件介绍与概览,提供对软件功能和操作界面的初步了解。随后,第二章详细阐述实验设计的基础知识,包括响应变量与实验因素的理论、实验设计的类型与统计原理。第三章和第四章着重于在Design-Expert中如何定义响应变量和设定实验因素,包括变量类型、优化目标及数据管
【USB供电机制详解】:掌握电源与地线针脚的关键细节
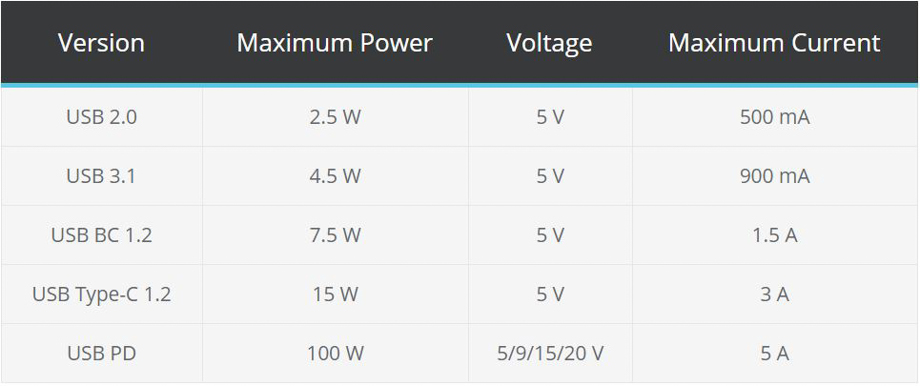
# 摘要
本文系统介绍了USB供电机制的理论基础与设计实践,深入探讨了USB电源针脚及地线针脚的电气特性,并分析了供电与地线在移动设备、PC及其周边设备中的应用。文中详细阐述了USB标准的演变、电源针脚的工作原理、供电电路设计、地线的连接与布局,以及热设计功率和电流限制等关键因素。此外,本文还探讨了USB供电
FANUC数控机床参数调整:避免误区的正确操作流程
# 摘要
FANUC数控机床参数调整是确保机床高效、精确运行的重要手段。本文首先概述了FANUC数控机床参数调整的基本概念和重要性。接着,详细解析了参数的类型、结构、分类及作用域,为深入理解参数调整奠定了基础。第三章探讨了参数调整的理论依据、原则和方法,并指出实践中的常见误区及其成因。第四章则重点介绍具体的参数调整操作流程和进阶技巧,以及在此过程中可能遇到的故障诊断与解决策略。通过对成功与失败案例的分析,本文第五章展示了参数调整的实际效果及重要性。最后,第六章展望了参数调整技术的未来发展和行业应用趋势,强调了技术创新与标准化在提升行业参数调整水平方面的作用。
# 关键字
数控机床;参数调整;
hw-server性能优化:服务器运行效率提升10倍的技巧
# 摘要
随着信息技术的迅猛发展,服务器性能优化成为提升计算效率和用户体验的关键。本文首先概述了服务器性能优化的重要性和基本概念。随后,文章深入探讨了影响服务器性能的关键指标,如响应时间、吞吐量以及CPU、内存和磁盘I/O的性能指标。在此基础上,本文详细介绍了性能瓶颈的诊断技
SMC真空负压表选型专家指南:不同场景下的精准选择

# 摘要
本文系统地介绍了SMC真空负压表的选型基础知识、技术参数解析以及在不同行业中的应用案例。文章首先阐述了SMC真空负压表的基本测量原理和主要技术指标,并指出选型时的常见误区。通过分析半导体制造、化工行业以及真空包装行业的应用实例,展示了真空负压表在实际应用中的选型策略和技巧。最后,文章详细介绍了真空负压表的维护与故障排除方法,强调了日常维护的重要性,以及通过预防性维护和操作人员培训提升设备使用寿命的必要性。本文为技术人
BELLHOP性能优化实战:5大技巧让你的应用性能飞跃

# 摘要
BELLHOP性能优化是一门涵盖基础理论与实战技巧的综合领域,旨在通过科学的方法和工具提升软件系统的运行效率。本文首先概述了BELLHOP性能优化的基础知识,随后详细探讨了性能分析的理论框架及高效工具的应用。在实战技巧方面,文章从代码优化、系统配置以及数据存储访问三个方面提供了深入的优化策略。此外,还介绍了负载均衡与扩展技术,以及在微服务架构下如何进行性能优化。高级技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )