BCH码与其他纠错码的比较分析:谁更胜一筹?
发布时间: 2024-12-15 17:16:34 阅读量: 1 订阅数: 4 

BHC.rar_BCH信道_BCH纠错码_bch_bch纠错_纠错码
参考资源链接:[BCH码编解码原理详解:线性循环码构造与多项式表示](https://wenku.csdn.net/doc/832aeg621s?spm=1055.2635.3001.10343)
# 1. 纠错码基础介绍
纠错码是一类特殊的编码技术,它能够在通信过程中检测和修正由于各种干扰导致的数据错误。在数字通信和数据存储领域,纠错码是保障信息完整性和可靠性的重要工具。纠错码的种类繁多,包括汉明码、里德-所罗门码、卷积码以及本章重点介绍的BCH码等。这些码各有其特点,比如汉明码适合检测并纠正单比特错误,而BCH码能够处理多比特错误,尤其在码长较短时表现优异。
纠错码的基本工作原理是通过添加额外的校验位,使得接收端能够在不重新传输数据的情况下,发现并修正一定的错误位。这种编码过程是在发送方完成的,而接收方通过特定的解码算法来识别和修正错误。在实际应用中,纠错码技术的选择需要综合考虑错误模式、纠错能力、编码与解码的复杂度及效率等因素。因此,深入理解不同纠错码的工作原理及其特性,对于正确选择和使用纠错码至关重要。
# 2. BCH码的理论基础与构造方法
### 2.1 纠错码的种类和特点
#### 2.1.1 纠错码的基本概念
纠错码是一种数据通信和存储系统中用来提高数据传输和存储的可靠性技术。它通过对原始数据进行编码,在数据中加入冗余信息,使得在传输或存储过程中即使部分数据遭到破坏或丢失,接收方也可以利用这些冗余信息重构出原始数据。这一过程相当于在数据中引入了错误检测和纠正的机制,极大地增强了信息传输的鲁棒性。
在数字化通信和数据处理中,错误的发生可能是由于各种原因,比如电磁干扰、电路故障、存储介质的缺陷等。纠错码的出现,有效地解决了这些问题,保证了信息的正确传输和稳定存储。
#### 2.1.2 主要纠错码类型对比
主要的纠错码可以分为线性纠错码和非线性纠错码两大类。线性纠错码中包括了海明码、Reed-Solomon码、BCH码等,其结构简单,易于编码和解码。而非线性纠错码如卷积码、LDPC码等则在某些方面表现出比线性码更优的性能,尤其是在错误纠正能力方面。
在这些纠错码中,BCH码以其良好的纠错能力和较强的错误分布容忍性,在数字通信和数据存储领域得到广泛应用。接下来,我们将深入探讨BCH码的理论基础和构造方法,了解其如何在各种应用中发挥其独特的优势。
### 2.2 BCH码的数学原理
#### 2.2.1 有限域的定义与性质
有限域(也称为伽罗瓦域,Galois Field)是BCH码的基础。有限域是一种只有有限个元素的数学结构,通常用GF(q)表示,其中q是域的元素个数。有限域的一个关键特性是每个非零元素都有乘法逆元。
对于BCH码来说,最常用的是二元有限域GF(2^m),其中m是正整数。在GF(2^m)中,元素可以通过m维的二进制向量表示,域中的加法对应于向量的模2加法,而乘法则是通过一个不可约多项式来定义的。
#### 2.2.2 BCH码的构造算法
BCH码是基于循环码的构造方法,通过选择一个特定的生成多项式来编码信息。具体的构造步骤如下:
1. 确定码的最小距离d,这决定了码的纠错能力。
2. 选择一个能够生成满足最小距离要求的生成多项式G(x),该多项式具有d-1个连续的零点。
3. 编码过程就是将信息多项式I(x)乘以生成多项式G(x)得到码字多项式C(x)。
4. 解码过程包括接收码字、计算伴随式、错误位置多项式的确定以及错误的纠正。
这种构造方法允许在有限域上进行高效率的算法实现,这也使得BCH码在实际中应用变得可行。
### 2.3 BCH码的编码与解码过程
#### 2.3.1 BCH码的编码原理
BCH码的编码原理基于循环码的框架。首先定义一个生成多项式G(x),它能够生成一个给定的最小距离d的码。编码时,将信息向量与生成多项式的乘积得到码字多项式C(x)。这个过程可以用数学公式表示为:
\[C(x) = I(x) \times G(x)\]
其中,\(I(x)\)表示信息多项式,\(G(x)\)表示生成多项式,\(C(x)\)表示编码后的码字多项式。
在BCH码的构造中,生成多项式\(G(x)\)必须满足特定的根的性质,即它在有限域上的根必须是码字最小距离d的倍数。
#### 2.3.2 BCH码的解码策略
BCH码的解码过程相对复杂,涉及到错误检测与纠正算法。通常,解码步骤如下:
1. 接收码字,并通过伴随式计算来检测是否存在错误。
2. 利用接收码字和已知的生成多项式来确定错误位置多项式。
3. 根据错误位置多项式计算错误位置和错误值。
4. 对于每个检测到的错误,通过在相应的位置上加上错误值来纠正错误。
由于BCH码的解码需要复杂的代数运算,对于长码字的BCH码来说,解码计算量可能非常大。然而,正是这种高效的纠错能力,使得BCH码成为许多通信和存储系统不可或缺的一部分。
通过了解BCH码的理论基础和构造方法,我们可以更好地把握其在实际应用中的表现和潜在优化方向。接下来,在第三章中,我们将深入探讨BCH码与其他纠错码的性能对比。
# 3. BCH码与其他纠错码的性能对比
## 3.1 BCH码与其他线性纠错码的比较
### 3.1.1 纠错能力分析
BCH码(Bose-Chaudhuri-Hocquenghem codes)是广泛应用于数字通信和数据存储系统中的一种强大的纠错码。BCH码属于线性纠错码的一种,其独特的特点在于能够在码字中纠正多个错误,而且具有很高的纠错性能。与其他线性纠错码相比,如汉明码(Hamming Code)和里德-所罗门码(Reed-Solomon Code),BCH码在相同码长的情况下通常能提供更好的纠错能力。
汉明码是一种能够检测并纠正单个错误的线性码。它的编码效率较高,但是只能处理单个错误。相比之下,BCH码能够在更长的码长中纠正多个错误。这意味着在一些需要更高可靠性的应用场合中,BCH码具有明显的优势。比如,BCH码能够纠正三个或更多的错误,而普通的汉明码只能纠正一个错误。
此外,BCH码可以通过增加码长和校验位的方式扩展其纠错能力。然而,随着纠错能力的提升,编码和解码的计算复杂度也会随之增加。因此,在设计BCH码时需要权衡纠错能力与计算效率之间的关系。
### 3.1.2 编码和解码复杂性对比
在编码复杂性方面,BCH码比汉明码等其他线性纠错码更为复杂。BCH码的编码过程涉及到生成多项式的构造和多项式运算,这

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【IT6801FN深度解析】:一文掌握手册中的20个核心技术要点

参考资源链接:[IT6801FN 数据手册:MHL2.1/HDMI1.4 接收器技术规格](https://wenku.csdn.net/doc
【电机控制实践】:DCS系统中电机启停原理图深度解读
参考资源链接:[DCS系统电机启停原理图.pdf](https://wenku.csdn.net/doc/646330c45928463033bd8df4?spm=1055.2635.3001.10343)
# 1. DCS系统概述与电机控制基础
## 1.1 DCS系统简介
分布式控制系统(DCS)是一种集成了数据采集、监控、控制和信息管理功
Win7_Win8系统Prolific USB-to-Serial适配器故障快速诊断与修复大全:专家级指南

参考资源链接:[Win7/Win8系统解决Prolific USB-to-Serial Comm Port驱动问题](https://wenku.csdn.net/doc/4zdddhvupp?spm=1055.2635.3001.10343)
# 1. Prolific USB-to-Serial适配器故障概述
在当今数字化时代,Prolific USB-to-Seria
iSecure Center 日志管理技巧:追踪与分析的高效方法
参考资源链接:[海康iSecure Center运行管理手册:部署、监控与维护详解](https://wenku.csdn.net/doc/2ibbrt393x?spm=1055.2635.3001.10343)
# 1. 日志管理的重要性和基础
## 1.1 日志管理的重要性
日志记录了系统运行的详细轨迹,对于故障诊断、性能监控、安全审计和
SSD1309性能优化指南

参考资源链接:[SSD1309: 128x64 OLED驱动控制器技术数据](https://wenku.csdn.net/doc/6412b6efbe7fbd1778d48805?spm=1055.2635.3001.10343)
# 1. SSD1309显示技术简介
SSD1309是一款广泛应用于小型显示设备中的单色OLED驱动芯片,由上海世强先进科技有限公司生产。它支持多种分辨率、拥有灵活的接口配置,并且通过I2C或S
Rational Rose顺序图性能优化:10分钟掌握最佳实践
参考资源链接:[Rational Rose顺序图建模详细教程:创建、修改与删除](https://wenku.csdn.net/doc/6412b4d0be7fbd1778d40ea9?spm=1055.2635.3001.10343)
# 1. Rational Rose顺序图简介与性能问题
## 1.1 Rational Rose工具的介绍
Rational Rose是IBM推出
无线快充技术革新:IP5328与无线充电的完美融合
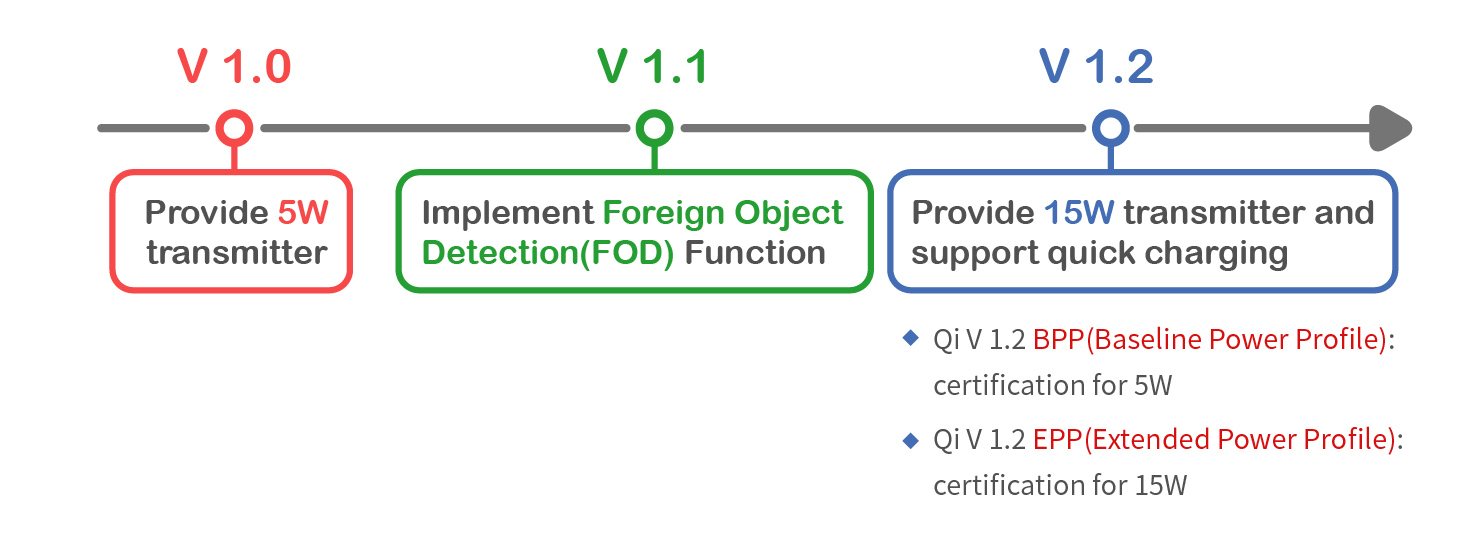
参考资源链接:[IP5328移动电源SOC:全能快充协议集成,支持PD3.0](https://wenku.csdn.net/doc/16d8bvpj05?spm=1055.2635.3001.10343)
# 1. 无线快充技术概述
无线快充技术的兴起,改变了人们为电子设备充电的习惯,使得充电变得更加便捷和高效。这种技
【AI引擎高级功能开发】:Prompt指令扩展的实践与策略
参考资源链接:[掌握ChatGPT Prompt艺术:全场景写作指南](https://wenku.csdn.net/doc/2b23iz0of6?spm=1055.2635.3001.10343)
# 1. AI引擎与Prompt指令概述
在当前的IT和人工智能领域,AI引擎与Prompt指令已经成为提升自然语言处理能力的重要工具。AI引擎作为核心的技术驱动,其功能的发挥往往依赖于高效、准确的Prompt指令。通过使用这些指令,AI引擎能够更好地理解和执行用户的查询、请求和任务,从而展现出强大的功能和灵活性。
AI引擎与Prompt指令的结合,不仅加速了人工智能的普及,也推动了智能技术在
【汇川H5U Modbus TCP性能提升】:高级技巧与优化策略
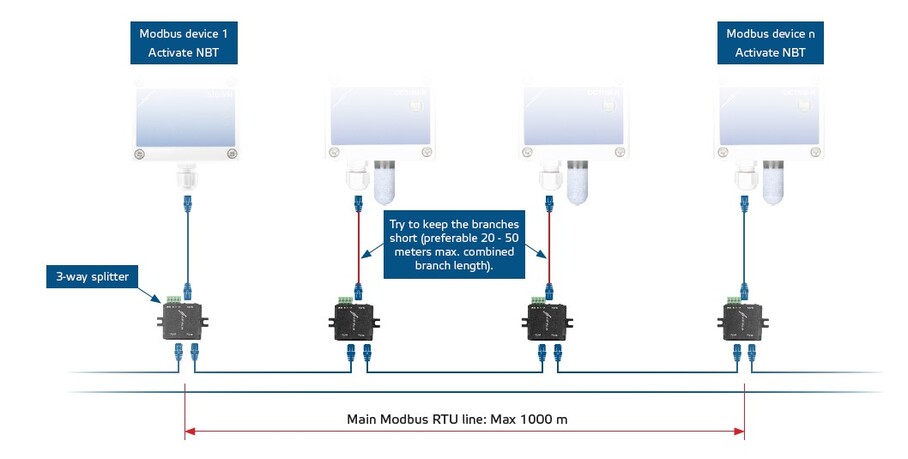
参考资源链接:[汇川H5U系列控制器Modbus通讯协议详解](https://wenku.csdn.net/doc/4bnw6asnhs?spm=1055.2635.3001.10343)
# 1. Modbus TCP协议概述
Modbus TCP协议作为工业通信领域广泛采纳的开放式标准,它在自动化控制和监视系统中扮演着至关重要的角色。本章首先将简要回顾Mod
【TFT-OLED速度革命】:提升响应速度的驱动电路改进策略

参考资源链接:[TFT-OLED像素单元与驱动电路:新型显示技术的关键](https://wenku.csdn.net/doc/645e54535
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )