SLF4J高级使用技巧:动态调整日志级别与MDC深度应用
发布时间: 2024-10-20 16:36:24 阅读量: 69 订阅数: 28 
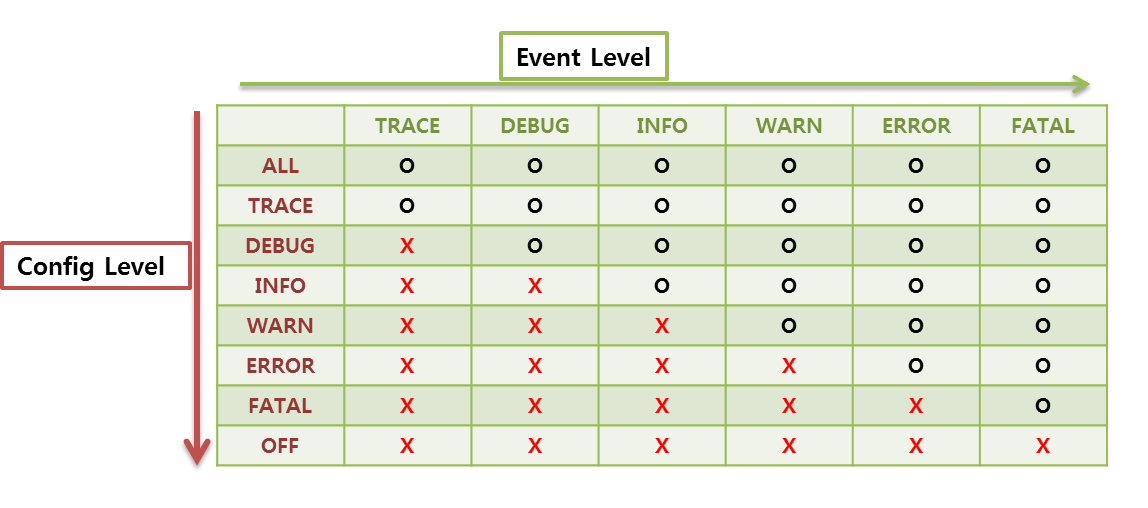
# 1. SLF4J概述与基本配置
## 1.1 SLF4J简介
SLF4J(Simple Logging Facade for Java)是一个用于Java的日志框架抽象层,它提供了统一的日志API,可以与各种日志系统如Log4j, Logback等进行对接。开发者可以使用SLF4J作为日志记录的前端,而具体的日志实现则可以动态添加。这种设计使得日志系统可以在不修改现有代码的情况下进行更换或更新。
## 1.2 SLF4J与Java日志体系
在Java中,日志是一个重要的功能,它帮助开发者记录系统运行时的状态信息。SLF4J是众多日志框架中的一种,它并不直接记录日志,而是作为一个门面模式来屏蔽具体日志实现的细节。通过使用SLF4J,开发者可以在不同的日志实现之间进行切换而无需更改代码逻辑,提高了代码的可维护性和可扩展性。
## 1.3 SLF4J基本配置
要开始使用SLF4J,首先需要在项目中引入SLF4J的jar包,并选择一个具体的日志框架实现。例如,使用Logback作为SLF4J的后端,需要添加Logback的依赖到项目中。然后在项目的`src/main/resources`目录下创建一个名为`logback.xml`的配置文件,用于配置日志的输出格式、日志级别、输出目的地等。下面是一个基本的`logback.xml`配置示例:
```xml
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="STDOUT" />
</root>
</configuration>
```
这个配置文件中定义了一个控制台输出的appender,并指定了日志的输出格式和级别。通过这种配置方式,可以轻松地控制日志的输出内容和级别,有助于开发和调试过程中的日志记录。
# 2. 动态调整日志级别
## 2.1 日志级别的重要性与作用
### 2.1.1 理解日志级别和其对性能的影响
在任何日志系统中,日志级别是控制日志输出的重要机制。它允许开发者控制信息的详细程度,并且可以根据运行时的需要动态地调整。SLF4J作为一个抽象层,它提供了多样的实现,例如logback和log4j,而这些实现都支持日志级别的动态调整。
日志级别从高到低通常包括:ERROR, WARN, INFO, DEBUG, TRACE。选择合适的日志级别是至关重要的,因为它影响性能及问题诊断的能力。
- **性能影响:** 过高的日志级别将导致记录过多的细节,这不仅会消耗大量的存储空间,也可能降低应用程序的性能,因为I/O操作是昂贵的。
- **问题诊断:** 过低的日志级别可能会丢失关键的错误信息,使开发者难以追踪问题。
选择正确的日志级别可以使开发人员、运维人员和故障排查人员在问题出现时能够快速获取必要的信息,而在生产环境中又不会影响性能。
### 2.1.2 使用SLF4J调整日志级别的基本方法
使用SLF4J结合logback等实现时,日志级别可以通过配置文件动态设置。例如,在logback.xml中可以这样设置:
```xml
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="STDOUT" />
</root>
</configuration>
```
在上述配置中,根日志级别被设置为INFO,意味着只会记录INFO级别以上的日志信息。如果需要动态调整,可以通过编程方式改变某个logger的日志级别,如下代码片段所示:
```java
Logger logger = LoggerFactory.getLogger("com.example.MyClass");
logger.error("This is an error message");
```
在应用运行时,根据需要可以使用logger的`setLevel`方法更改日志级别:
```java
((ch.qos.logback.classic.Logger) logger).setLevel(Level.WARN);
```
这会将`com.example.MyClass`的记录级别从INFO调整到WARN。在实际项目中,通常会利用外部配置文件或系统参数来调整日志级别,以减少重新部署或重启应用的需要。
## 2.2 实现日志级别的动态调整
### 2.2.1 利用Java的反射机制动态调整日志级别
Java的反射机制允许程序在运行时动态地访问和修改类的属性。SLF4J的日志记录器接口是设计为可以被动态替换的,这可以用来实现运行时调整日志级别。
首先,需要获取当前日志记录器的实例:
```java
Logger logger = LoggerFactory.getLogger("com.example.MyClass");
```
然后,利用反射获取这个logger实例的`org.slf4j.impl.StaticLoggerBinder`类的`loggerContext`对象:
```java
Field field = logger.getClass().getDeclaredField("loggerContext");
field.setAccessible(true);
LoggerContext loggerContext = (LoggerContext) field.get(logger);
```
现在,可以使用`LoggerContext`来获取特定logger,并设置新的日志级别:
```java
Logger loggerToChange = loggerContext.getLogger("com.example.MyClass");
loggerToChange.setLevel(Level.WARN);
```
通过这种方式,可以在不中断应用程序运行的情况下,动态地调整日志级别。这种技术在调试或监控中非常有用,但要注意不要在生产环境中过度使用反射,因为它可能引起性能问题,并且增加系统的复杂性。
### 2.2.2 结合Spring框架实现配置驱动的日志级别调整
当使用Spring框架时,可以通过属性文件来调整日志级别。Spring Boot可以自动配置日志系统,并根据外部配置文件(如application.properties或application.yml)动态调整日志级别。
例如,在`application.properties`中可以这样设置:
```
***.example.MyClass=WARN
```
这样的配置可以在Spring Boot应用程序启动时读取并应用。如果需要在应用运行时修改日志级别,可以使用Spring的`LoggingSystem`接口:
```java
import org.springframework.boot.logging.LogLevel;
import org.springframework.boot.logging.LoggingSystem;
import org.springframework.core.env.Environment;
@Autowired
private Environment environment;
public void changeLogLevel(String loggerName, LogLevel logLevel) {
LoggingSystem.get(LoggingSystem.class.getClassLoader())
.setLogLevel(loggerName, logLevel);
}
```
在这个例子中,`LoggingSystem`由Spring提供,允许在应用运行时修改logger的级别。`LogLevel`是一个枚举,代表不同的日志级别。
结合Spring框架实现日志级别的动态调整,为日志管理提供了极大的灵活性。它可以支持更加细致的日志级别控制,有利于快速定位和解决生产环境的问题。
## 2.3 高级场景下的日志级别管理
### 2.3.1 在分布式系统中同步日志级别
在微服务架构或分布式系统中,不同服务可能由不同的团队管理,它们可能运行在不同的实例和节点上。在这种情况下,统一日志级别变得复杂。SLF4J通过与logback配合,可以实现日志级别的远程同步。
使用logback的JMX功能,可以在管理控制台远程管理日志级别。或者,可以自定义一个服务,通过API调用的方式统一管理所有服务的日志级别。这样的服务可以与配置中心(例如Spring Cloud Config)集成,实现日志级别的动态推送。
### 2.3.2 使用SLF4J API进行日志级别的程序化控制
SLF4J提供的API允许程序化控制日志级别。这是非常有用的,尤其是在需要根据特定条件调整日志行为的场景中。
例如,可以根据应用运行环境动态设置日志级别:
```java
import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.Logger;
import org.slf4j.LoggerFactory;
public class DynamicLevelControl {
public void adjustLogLevel(String loggerName, Level level) {
Logger logger = (Logger) LoggerFactory.getLogger(loggerName);
logger.setLevel(level);
}
}
```
在这个例子中,`DynamicLevelControl`类的`adjustLogLevel`方法允许根据传入的参数设置特定logger的日志级别。这样,你可以根据应用的运行环境(如开发、测试、生产)或者根据业务需求来动态调整日志级别。
程序化控制日志级别可以让日志系统更加灵活,但它需要谨慎使用。错误配置日志级别可能导致记录过多或过少的信息,这会对系统性能和故障排查造成影响。
# 3. MDC深入应用
## 3.1 MDC的核心概念和使用场景
### 3.1.1 MDC的工作原理与数据传递机制
MDC(Mapped Diagnostic Context)是SLF4J中的一个高级特性,它允许开发者在日志上下文中插入诊断信息。这种机制对于追踪请求在多线程环境中的执行路径尤其有用。它的工作原理涉及到一种特殊的日志上下文,该上下文可以存储键值对信息,这些信息可以在日志记录时作为上下文变量使用。
具体来说,当一个请求到达服务端时,系统可以为该请求生成一个唯一的跟踪ID(例如UUID),然后将这个ID作为键,与一个值(例如用户的会话标识)一起存入MDC。之后,每当应用程序记录一条日志时,MDC中的信息会被自动添加到日志消息中。这使得开发者可以通过查看日志信息来追溯请求的完整流转路径。
### 3.1.2 MDC在不同场景下的使用案例
MDC在众多场景中都非常有用,比如在一个Web服务器中,我们可能需要区分不同用户的请求,或者在一个分布式系统中,我们可能需要追踪服务之间的调用链路。
以一个电商平台为例,在处理用户的支付请求时,可以通过在MDC中存储用户ID和订单ID来帮助我们追踪整个支付过程中的所有日志。如果支付过程中发生了异常,我们可以迅速定位是哪个用户的订单出了问题,并且查看相关日志以分析问题原因。
```java
MDC.put("userId", "user1234");
MDC.put("orderId", "order5678");
***("开始处理支付请求");
// 业务逻辑处理代码
MDC.remove("userId");
MDC.remove("orderId");
```
## 3.2 MDC的高级配置技巧
### 3.2.1 自定义MDC上下文初始化与清理
在一些复杂的场景下,我们可能需要对MDC进行更细致的控制,比如在请求开始时自动初始化MDC中的信息,在请求结束时清理这些信息。这时可以通过实现一个过滤器或拦截器来进行自定义。
例如,使用Spring MVC的拦截器来自动管理MDC:
```java
public class MdcInterceptor implements HandlerInterceptor {
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
MDC.clear();
}
@Override
public void afterConcurrentHandlingStarted(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 可以在这里初始化MDC,例如从请求头中获取跟踪ID
String traceId = request.getHeader("X-Trace-Id");
if (traceId != null) {
MDC.put("traceId", traceId);
}
}
}
```
### 3.2.2 利用MDC进行跨线程日志追踪与调试
在多线程的应用程序中,线程之间的上下文信息传递可能会变得复杂。MDC提供了一种便捷的方式来管理这些跨线程的日志信息。线程在启动时可以从父线程继承MDC中的信息,并且在任务执行完毕后清除这些信息,以避免信息污染。
下面展示了如何在Java的`ExecutorService`中管理MDC信息:
```java
ExecutorService executorService = Executors.newFixedThreadPool(10);
executorService.submit(() -> {
String traceId = MDC.get("traceId");
try {
// 执行任务
} finally {
MDC.remove("traceId");
}
});
```
## 3.3 结合SLF4J扩展MDC的功能
### 3.3.1 结合SLF4J的MDC与异步日志记录
异步日志记录是一种提高日志记录性能的方法,它允许日志操作在后台线程中执行,从而减少对业务代码的延迟影响。结合SLF4J使用MDC,我们可以在异步记录日志时仍然保持正确的上下文信息。
这里有一个简单的示例,演示了如何结合SLF4J和Logback来实现MDC的异步日志记录:
```java
import org.slf4j.MDC;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
final class MyAsyncAppender extends AsyncAppender {
private final Logger log = LoggerFactory.getLogger(MyAsyncAppender.class);
@Override
public void doAppend(LoggingEvent event) {
event.getNDC(); // 在这里可以通过getMDC方法获取MDC内容
event.setMDCPropertyMap(MDC.getCopyOfContextMap());
super.doAppend(event);
}
}
```
### 3.3.2 在高并发环境下利用MDC进行性能优化
在高并发环境下,正确地使用MDC可以大大降低日志系统对整体系统性能的影响。通过在MDC中传递关键信息(如请求ID、用户ID等),可以减少对数据库或其他外部服务的查询次数,因为这些信息可以在日志记录时直接从MDC中获取。
此外,在高并发环境下,要特别注意MDC的清理工作,避免内存泄露。正确的清理机制可以保证不会因为MDC的使用导致内存消耗过快。例如:
```java
try {
// 业务逻辑代码
} finally {
MDC.clear(); // 清理MDC信息,防止内存泄露
}
```
通过这些高级配置技巧,结合SLF4J的MDC可以实现更高效的日志记录,同时保持系统的高性能和稳定性。
# 4. SLF4J与其他日志框架的整合
在日志管理的实践中,不同的项目和组织可能会选择不同的日志框架。SLF4J(Simple Logging Facade for Java)作为一个日志门面,提供了与多种日志框架的整合能力,从而让使用者能够无缝切换底层日志实现。本章将深入探讨SLF4J如何与常见的日志框架进行整合,以及整合时的注意事项和最佳实践。
## 4.1 SLF4J与Logback的整合
Logback是SLF4J官方推荐的日志实现之一,两者在设计上有着紧密的联系。我们将讨论Logback如何作为SLF4J后端进行日志记录,以及从Log4j迁移到Logback的策略。
### 4.1.1 Logback作为SLF4J后端的日志记录实现
Logback是一个强大且高度可配置的记录系统。它被设计为SLF4J的一个默认实现,因此两者整合起来相当直接。
```xml
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
<scope>runtime</scope>
</dependency>
```
在上述依赖被添加到项目中之后,通过SLF4J提供的简单日志接口,就可以使用Logback作为日志记录后端了。这种整合方式使得开发者无需修改太多代码,只需要更换依赖即可完成迁移。
### 4.1.2 从Log4j迁移到Logback的最佳实践
当需要从Log4j迁移到Logback时,应考虑到Logback提供了更快的日志处理速度和更灵活的配置能力。最佳实践包括:
- **备份和比较配置文件:** Logback和Log4j在配置文件上有相似之处,但还是有所不同。备份原配置文件并逐项比较修改是最稳妥的方式。
- **替换依赖:** 移除Log4j的依赖并添加Logback依赖。
- **检查第三方库:** 某些第三方库可能还保留着对Log4j的依赖,需要检查并替换掉这些依赖。
## 4.2 SLF4J与Log4j2的整合
Log4j2是Log4j的下一代产品,它提供了更丰富的功能和性能优势。SLF4J与Log4j2的整合及其优势将是本小节的重点。
### 4.2.1 Log4j2对SLF4J的支持和配置
Log4j2通过SLF4J桥接模块来实现与SLF4J的整合。配置Log4j2作为SLF4J的实现,需要添加以下依赖:
```xml
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.13.3</version>
</dependency>
```
通过这个桥接模块,Log4j2允许开发者继续使用SLF4J的API,同时利用Log4j2的扩展性和性能优势。
### 4.2.2 评估Log4j2与SLF4J组合的优势
Log4j2与SLF4J组合的亮点在于:
- **性能:** Log4j2是专为性能优化而设计的,其在多线程环境下的表现尤为突出。
- **配置灵活性:** Log4j2提供了更丰富的配置选项和更细粒度的控制能力。
- **模块化和扩展性:** Log4j2的插件架构允许更多的扩展和自定义,极大地增强了其在不同场景下的适应性。
## 4.3 SLF4J与其他日志框架的兼容性
有时项目可能因为各种原因需要整合非Logback和Log4j2的日志框架。SLF4J提供了与其他日志框架的桥接功能,使得整合变得更加灵活。
### 4.3.1 SLF4J桥接其他日志框架的方法
SLF4J桥接模块允许开发者将SLF4J与其他日志框架进行整合。例如,如果要整合Jul(Java Util Logging),则需要添加如下依赖:
```xml
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jul-to-slf4j</artifactId>
<version>1.7.30</version>
</dependency>
```
一旦桥接依赖被添加,Jul的日志调用就会被转换为SLF4J API的调用,从而可以通过SLF4J的门面访问底层日志实现。
### 4.3.2 对比不同日志框架整合SLF4J的性能影响
整合SLF4J与其他日志框架时,开发者应考虑到性能影响。不同的日志框架之间在性能和功能上都存在差异,例如:
- **性能开销:** 通过SLF4J桥接的额外一层可能会引入一些性能开销。
- **功能限制:** 使用桥接时,某些特定于底层日志框架的功能可能无法使用。
- **配置复杂性:** 配置可能更加复杂,因为需要同时考虑SLF4J和底层框架的配置要求。
整合SLF4J与不同日志框架是一个灵活且强大的选择,但必须基于对项目需求和日志框架特性的充分理解。
接下来,我们将继续深入探讨如何对SLF4J进行性能优化,以及如何在不同领域应用SLF4J以达到最佳实践。
# 5. SLF4J的性能优化与最佳实践
## 5.1 SLF4J性能监控与调优
### 5.1.1 分析SLF4J日志记录的性能瓶颈
在探讨SLF4J日志记录性能瓶颈之前,我们需要理解SLF4J本身并不执行日志记录的实际工作,它只是作为日志门面(Logging Facade),将日志事件转发到实际的后端日志系统。因此,性能瓶颈通常与所使用的具体后端日志系统有关。
要分析SLF4J日志记录的性能瓶颈,我们可以通过以下步骤进行:
1. **基准测试**:在没有日志记录的情况下,运行系统以获得基准性能数据。然后逐步增加日志记录的级别和数量,观察对性能的影响。
2. **监控工具**:使用如VisualVM, JProfiler, Flight Recorder等工具监控JVM性能,特别是垃圾收集器的行为,以及线程的状态和CPU的使用情况。
3. **日志系统分析**:对于使用的后端日志系统,分析其内部结构,如缓冲机制、同步写入和异步处理的能力。
代码分析示例:
```java
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class PerformanceBottleneckAnalysis {
private static final Logger logger = LoggerFactory.getLogger(PerformanceBottleneckAnalysis.class);
public void performOperations(int numberOfOperations) {
for (int i = 0; i < numberOfOperations; i++) {
logger.debug("Operation performed: {}", i);
}
}
}
```
在上述代码中,如果大量记录debug级别日志,而实际后端日志系统配置为异步写入,可能不会立即发现性能瓶颈。但如果同步写入,或者使用的后端系统不适合当前负载(例如,磁盘I/O成为瓶颈),性能瓶颈就会显现出来。
### 5.1.2 优化SLF4J配置以提高性能
为了提高SLF4J的性能,以下是一些常见的优化建议:
1. **异步日志记录**:配置异步日志记录可以提高性能,尤其是在高并发环境下。异步记录可以减少对主线程的影响,避免I/O阻塞。
2. **优化日志级别**:仅启用必要的日志级别,关闭不必要的级别(如debug, trace),减少日志系统的负载。
3. **日志轮转**:设置合适的日志轮转策略,避免单个日志文件过大,影响读写性能。
4. **MDC优化**:如果使用MDC(Mapped Diagnostic Context),确保上下文初始化和清理得当,避免内存泄漏。
5. **合理配置编码器**:对于使用Logback或Log4j2等后端框架,合理配置编码器可以减少序列化和反序列化的开销。
代码块示例:
```xml
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<queueSize>256</queueSize> <!-- 控制队列大小 -->
<discardingThreshold>0</discardingThreshold> <!-- 控制丢弃阈值 -->
<appender-ref ref="FILE" />
</appender>
```
在上述配置中,`AsyncAppender` 可以异步地将日志事件传递到其他appenders,这对于高并发应用来说是非常有用的。
## 5.2 SLF4J的高级特性和插件
### 5.2.1 探索SLF4J的高级特性:Marker和参数化日志
SLF4J的高级特性中,Marker提供了在日志消息中添加额外上下文的能力,而参数化日志(也称为可审计日志)则可以提高性能,特别是当该日志级别关闭时。
使用Marker的代码示例:
```java
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.Marker;
import org.slf4j.MarkerFactory;
public class MarkerUsage {
private static final Logger logger = LoggerFactory.getLogger(MarkerUsage.class);
private static final Marker SQL_MARKER = MarkerFactory.getMarker("SQL");
public void performDatabaseOperation() {
***(SQL_MARKER, "Executing database query {}", "SELECT * FROM users");
}
}
```
在该代码中,我们使用Marker来标识特定的日志消息类别,如数据库操作日志。在日志配置文件中,我们可以针对不同的Marker进行不同的处理。
参数化日志使用代码示例:
```java
logger.debug("User with id {} logged in", userId);
```
上述参数化日志使用了占位符,避免了不必要的字符串拼接操作,当日志级别为DEBUG且不需要输出参数值时,其性能会优于使用`+`操作符拼接字符串的记录方式。
### 5.2.2 了解和应用SLF4J社区开发的插件
SLF4J社区为日志记录提供了许多有用的插件,如`slf4j-ext`提供的`TimberLoggerFactory`和`JULLoggerFactory`,这些插件为开发者提供了额外的日志处理能力。
使用插件的一个常见案例是将SLF4J绑定到Java Util Logging (JUL):
```java
import org.slf4j.bridge.SLF4JBridgeHandler;
import java.util.logging.Level;
import java.util.logging.Logger;
public class JULtoSLF4J {
static {
SLF4JBridgeHandler.removeHandlersForRootLogger();
SLF4JBridgeHandler.install();
}
public static void main(String[] args) {
Logger julLogger = Logger.getLogger("com.example");
julLogger.setLevel(Level.FINE);
org.slf4j.Logger slf4jLogger = org.slf4j.LoggerFactory.getLogger("com.example");
slf4jLogger.debug("This is a debug message");
}
}
```
在该代码中,我们使用`SLF4JBridgeHandler`将Java Util Logging 日志转发到SLF4J,使得可以在一个应用程序中同时使用多种日志框架。
## 5.3 SLF4J最佳实践案例分析
### 5.3.1 大型项目中SLF4J的实践应用
在大型项目中,SLF4J不仅用于记录日志,还经常用于追踪分布式系统中的调用链。应用SLF4J最佳实践可以提高开发效率,减少系统维护的复杂性。
一个关键实践是使用统一的日志格式和标准化的命名约定,这有助于日志分析工具更加有效地解析和分类日志事件。另一个实践是合理使用Marker和MDC来附加额外的上下文信息,这对于后续的问题排查和性能分析非常有价值。
### 5.3.2 分析和学习业界知名项目中的SLF4J应用
业界有许多知名项目,如Spring Boot、Dropwizard和Apache Kafka等,它们在内部广泛使用SLF4J来记录日志。通过分析这些项目,我们可以了解如何在实际应用中合理配置和优化SLF4J。
以Spring Boot为例,它默认使用SLF4J结合Logback作为日志系统。Spring Boot通过`application.properties`或`application.yml`配置文件,提供了灵活的日志配置选项,如日志级别、日志格式、日志文件位置等。
```yaml
logging:
level:
org:
springframework:
web: INFO
***
***
```
通过阅读源码和文档,我们可以学习到如何通过SLF4J配置实现更加精细化的日志管理,这将对我们的项目产生积极影响。
通过以上内容,我们介绍了SLF4J的性能优化与最佳实践,分析了性能瓶颈并提供了配置优化的建议。同时,我们还探索了SLF4J的高级特性,并通过真实案例学习如何在项目中应用这些知识,提高日志系统的整体性能和可维护性。
# 6. SLF4J在不同领域应用的深度剖析
## 6.1 SLF4J在微服务架构中的角色
在微服务架构中,SLF4J扮演着至关重要的角色。由于微服务架构的组件数量巨大且相互独立,因此高效且准确的日志记录和管理显得尤为重要。SLF4J作为日志抽象层,支持开发者在不同服务中灵活选择和更换具体的日志实现框架,同时保持了代码的整洁和一致性。
### 6.1.1 SLF4J在Spring Cloud微服务中的应用
Spring Cloud是微服务架构中的一大利器,它为服务之间的通信、服务发现、配置管理等方面提供了丰富的工具和模式。SLF4J在Spring Cloud中的应用主要体现在服务日志的记录和管理上。以Spring Cloud Netflix Eureka为例,服务注册与发现组件会大量产生日志信息,SLF4J可以帮助开发人员对这些信息进行统一格式化和管理。
```java
// SLF4J使用示例
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class EurekaService {
private static final Logger LOGGER = LoggerFactory.getLogger(EurekaService.class);
public void registerService() {
***("Registering service with Eureka server");
// ... service registration logic ...
}
}
```
在此代码示例中,通过LoggerFactory获取Logger实例,然后可以在任何需要的地方记录日志。这种模式不仅统一了日志的输出格式,也便于后续根据日志级别进行过滤和管理。
### 6.1.2 利用SLF4J实现服务追踪和故障排查
在微服务架构中,服务之间依赖和调用关系复杂,因此服务追踪和故障排查成为一项挑战。SLF4J可以与Zipkin、Sleuth等服务追踪框架结合使用,为开发者提供更加丰富的日志信息。例如,通过在服务调用链中插入追踪ID,可以轻松追踪请求的完整路径,从而进行故障诊断和性能优化。
```java
// 利用SLF4J与Sleuth结合的追踪示例
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.cloud.sleuth.Span;
import org.springframework.cloud.sleuth.Tracer;
public class ServiceTracingExample {
private static final Logger LOGGER = LoggerFactory.getLogger(ServiceTracingExample.class);
private final Tracer tracer;
public ServiceTracingExample(Tracer tracer) {
this.tracer = tracer;
}
public void executeService() {
Span newSpan = tracer.createSpan("executeService");
***("Tracing service execution with Sleuth");
// ... service execution logic ...
tracer.close(newSpan);
}
}
```
此代码通过Sleuth的`Tracer`类创建了一个追踪span,然后在服务执行的关键点记录日志。这样,在分布式系统中就可以轻松追踪每个服务的调用链,极大地提高了调试和维护的效率。
## 6.2 SLF4J在企业级应用中的实践
企业级应用通常需要处理大量数据,维持高并发请求,并且要求极高的稳定性和可靠性。SLF4J在这些场景下能够帮助企业实现灵活、高效的日志管理。
### 6.2.1 集成SLF4J到企业级应用的技术路线
集成SLF4J到企业级应用时,首先需要考虑的是日志框架的选择。通常企业级应用会采用Logback或Log4j2作为后端实现,因为这两者都提供了丰富的配置选项和性能优化手段。在SLF4J的引导下,可以轻松地将日志框架与应用集成,而无需在业务代码中直接依赖具体的日志框架。
```xml
<!-- pom.xml中添加依赖 -->
<dependencies>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<!-- 其他依赖... -->
</dependencies>
```
通过这种方式,企业级应用可以灵活地切换和升级不同的日志框架,以满足不断变化的业务需求。
### 6.2.2 SLF4J在分布式事务和高并发场景下的应用
在处理分布式事务和高并发场景时,日志的准确性和性能尤其重要。SLF4J提供了强大的日志记录功能,可以让开发人员精确地记录事务的开始和结束、关键步骤的执行时间、甚至是事务失败的原因。这对于提高系统的稳定性和监控系统的性能至关重要。
```java
// 日志记录示例
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class DistributedTransactionExample {
private static final Logger LOGGER = LoggerFactory.getLogger(DistributedTransactionExample.class);
public void startTransaction() {
// 开始事务的记录
***("Starting distributed transaction");
// ... 事务逻辑 ...
***("Distributed transaction completed successfully");
}
}
```
## 6.3 SLF4J与其他技术结合的新趋势
随着技术的发展,SLF4J不断与新技术结合,以适应日志管理和分析的新需求。
### 6.3.1 结合Docker容器化SLF4J日志管理
容器化技术的发展使得应用的部署变得更加轻量和灵活。在Docker容器化的环境中,SLF4J可以与容器的日志驱动相结合,例如使用journald、syslog或者直接输出到标准输出(stdout),以便于日志的集中管理和分析。
```yaml
# docker-compose.yml 配置示例
version: '3'
services:
application:
image: your-image
logging:
driver: "journald"
options:
tag: "my-service"
```
通过这种方式,SLF4J记录的日志会通过容器的日志驱动发送到宿主机的journald中,之后可以利用journald强大的搜索和过滤功能进行日志的查询和分析。
### 6.3.2 SLF4J与大数据技术的日志整合策略
在大数据领域,日志数据常常是分析的重要来源。通过将SLF4J与Apache Kafka、HDFS等大数据技术结合,可以实现对日志数据的实时收集和持久化存储。这不仅提高了日志数据的处理能力,也为大数据分析提供了更多的数据源。
```java
// Kafka Producer 示例,将日志发送到Kafka
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class KafkaLogProducerExample {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaLogProducerExample.class);
public static void main(String[] args) {
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("log-topic", "log message");
producer.send(record);
}
}
```
这个简单的示例展示了如何将日志信息通过Kafka发送到一个指定的主题中。这使得日志数据可以被进一步地处理和分析,例如通过流处理技术实时分析日志信息,从而实现故障预测、用户行为分析等功能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《Java SLF4J(简单日志门面)》深入探讨了 SLF4J 日志框架,提供了一系列技巧和指南,帮助开发人员优化 Java 项目中的日志记录。从初学者指南到高级使用技巧,专栏涵盖了 SLF4J 的各个方面,包括集成、性能优化、可扩展性、从其他框架迁移、与其他框架的互操作性、高并发系统中的挑战、企业级应用中的应用、日志策略制定、云原生环境中的应用、日志过滤和格式化等。通过深入分析 SLF4J 源代码、提供实战案例和最佳实践,专栏旨在帮助开发人员充分利用 SLF4J,构建高效、准确且可扩展的日志系统。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
决策树在金融风险评估中的高效应用:机器学习的未来趋势
# 1. 决策树算法概述与金融风险评估
## 决策树算法概述
决策树是一种被广泛应用于分类和回归任务的预测模型。它通过一系列规则对数据进行分割,以达到最终的预测目标。算法结构上类似流程图,从根节点开始,通过每个内部节点的测试,分支到不
预测模型中的填充策略对比
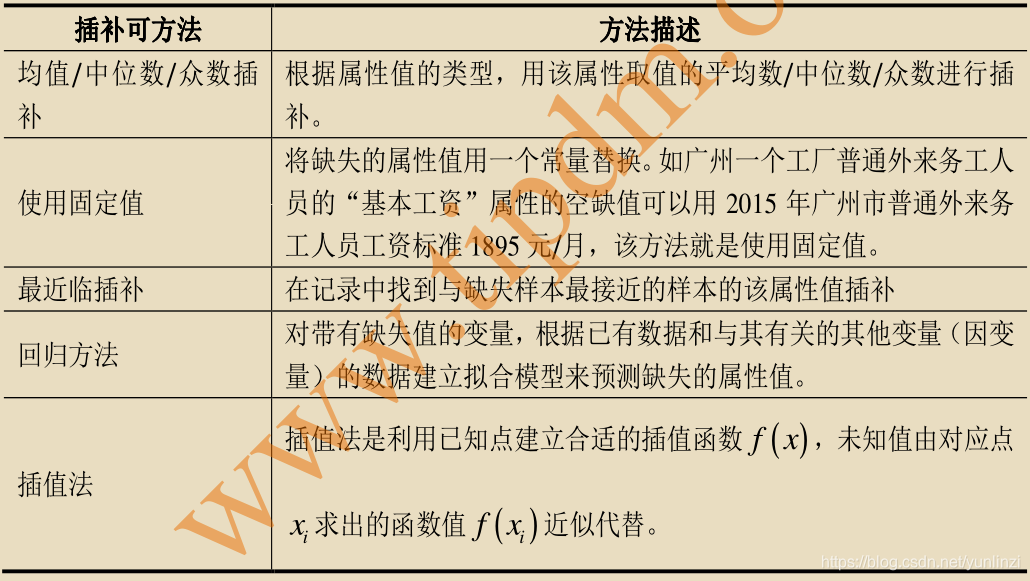
# 1. 预测模型填充策略概述
## 简介
在数据分析和时间序列预测中,缺失数据是一个常见问题,这可能是由于各种原因造成的,例如技术故障、数据收集过程中的疏漏或隐私保护等原因。这些缺失值如果
【超参数调优与数据集划分】:深入探讨两者的关联性及优化方法

# 1. 超参数调优与数据集划分概述
在机器学习和数据科学的项目中,超参数调优和数据集划分是两个至关重要的步骤,它们直接影响模型的性能和可靠性。本章将为您概述这两个概念,为后续深入讨论打下基础。
## 1.1 超参数与模型性能
超参数是机器学习模型训练之前设置的参数,它们控制学习过程并影响最终模型的结构。选择合适的超参数对于模型能否准确捕捉到数据中的模式至关重要。一个不
数据增强实战:从理论到实践的10大案例分析

# 1. 数据增强简介与核心概念
数据增强(Data Augmentation)是机器学习和深度学习领域中,提升模型泛化能力、减少过拟合现象的一种常用技术。它通过创建数据的变形、变化或者合成版本来增加训练数据集的多样性和数量。数据增强不仅提高了模型对新样本的适应能力,还能让模型学习到更加稳定和鲁棒的特征表示。
## 数据增强的核心概念
数据增强的过程本质上是对已有数据进行某种形式的转换,而不改变其底层的分
【案例分析】:金融领域中类别变量编码的挑战与解决方案

# 1. 类别变量编码基础
在数据科学和机器学习领域,类别变量编码是将非数值型数据转换为数值型数据的过程,这一步骤对于后续的数据分析和模型建立至关重要。类别变量编码使得模型能够理解和处理原本仅以文字或标签形式存在的数据。
## 1.1 编码的重要性
类别变量编码是数据分析中的基础步骤之一。它能够将诸如性别、城市、颜色等类别信息转换为模型能够识别和处理的数值形式。例如,性别中的“男”和“女
【聚类算法优化】:特征缩放的深度影响解析
# 1. 聚类算法的理论基础
聚类算法是数据分析和机器学习中的一种基础技术,它通过将数据点分配到多个簇中,以便相同簇内的数据点相似度高,而不同簇之间的数据点相似度低。聚类是无监督学习的一个典型例子,因为在聚类任务中,数据点没有预先标注的类别标签。聚类算法的种类繁多,包括K-means、层次聚类、DBSCAN、谱聚类等。
聚类算法的性能很大程度上取决于数据的特征。特征即是数据的属性或
市场营销的未来:随机森林助力客户细分与需求精准预测

# 1. 市场营销的演变与未来趋势
市场营销作为推动产品和服务销售的关键驱动力,其演变历程与技术进步紧密相连。从早期的单向传播,到互联网时代的双向互动,再到如今的个性化和智能化营销,市场营销的每一次革新都伴随着工具、平台和算法的进化。
## 1.1 市场营销的历史沿
梯度下降在线性回归中的应用:优化算法详解与实践指南

# 1. 线性回归基础概念和数学原理
## 1.1 线性回归的定义和应用场景
线性回归是统计学中研究变量之间关系的常用方法。它假设两个或多个变
防止SVM过拟合:模型选择与交叉验证的最佳实践
# 1. 支持向量机(SVM)基础
支持向量机(SVM)是机器学习中的一种强大的监督学习模型,广泛应用于分类和回归问题。SVM的核心思想是找到一个最优的超平面,它能够最
自然语言处理新视界:逻辑回归在文本分类中的应用实战

# 1. 逻辑回归与文本分类基础
## 1.1 逻辑回归简介
逻辑回归是一种广泛应用于分类问题的统计模型,它在二分类问题中表现尤为突出。尽管名为回归,但逻辑回归实际上是一种分类算法,尤其适合处理涉及概率预测的场景。
## 1.2 文本分类的挑战
文本分类涉及将文本数据分配到一个或多个类别中。这个过程通常包括预处理步骤,如分词、去除停用词,以及特征提取,如使用词袋模型或TF-IDF方法
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )