HBase数据库在大数据存储与管理中的应用
发布时间: 2024-02-29 09:14:30 阅读量: 35 订阅数: 39 

基于HBase的大数据存储的应用场景分析
# 1. 介绍
## 1.1 什么是HBase数据库
Apache HBase是一个开源的、分布式的、面向列的NoSQL数据库管理系统,它构建在Apache Hadoop之上,提供了对大型数据集的随机、实时的读/写访问能力。HBase具有高可靠性、高性能和高可伸缩性的特点,适用于需要快速、大规模数据存储和实时查询的场景。
## 1.2 HBase与传统关系型数据库的区别
HBase采用分布式存储、无模式和水平扩展的设计理念,与传统的关系型数据库相比,在处理PB级数据时具有更好的性能和可扩展性。传统关系型数据库使用固定模式和行存储,不适合大规模非结构化数据的存储和查询。
## 1.3 HBase在大数据存储与管理中的重要性
在大数据存储与管理中,HBase扮演着重要角色。其横向扩展能力、高性能读写操作以及数据一致性与容错性等特点,使其成为处理实时、海量数据的理想选择。通过HBase,用户可以快速、高效地存储、管理和查询海量数据,满足数据密集型应用的需求。
# 2. HBase数据库架构
HBase作为一个高可靠、高性能、面向列存储的分布式数据库,其架构设计是支撑其稳定运行的关键。接下来,我们将对HBase数据库的架构进行详细的介绍。
### 2.1 HBase的基本架构概述
HBase数据库的基本架构由三个关键部分组成:客户端访问、HMaster、RegionServer。其中,客户端通过ZooKeeper定位HMaster,并直接与HMaster通信,HMaster负责HBase表的管理及RegionServer的负载均衡等工作。每个RegionServer负责存储若干个Region,而Region又被划分为若干个Store,每个Store包含一个MemStore和若干个StoreFile。该架构设计使得HBase能够实现高可用、横向扩展等特性。
### 2.2 Region、Region Server、HMaster等组件解析
- **Region:** 表在HBase中的数据存储是通过Region来完成的,每个Region对应一个Store,一个表可以拥有多个Region。Region根据Row Key的字典序进行划分,保证了数据存储的负载均衡。
- **Region Server:** 它是HBase的核心组件,负责管理一系列的Region,处理读写请求并维护Region的负载均衡。Region Server将数据存储在HDFS上,通过HFile文件进行存储和管理。
- **HMaster:** 负责管理Region的分布和负载均衡,处理Region的分裂和合并等操作,同时接收客户端的DDL请求并进行相应的处理。
### 2.3 HBase数据模型与存储方式
HBase的数据模型是基于Google的Bigtable论文设计而成的,采用了稀疏的、多维的、按时间戳顺序排序的Map数据模型。其中,表由多个Column Family组成,每个Column Family由多个Qualifier和Value组成。数据以Row Key为索引,Row Key按字典序排序,保证了数据在物理存储上的邻近性,从而提高了数据的访问效率。
以上是对HBase数据库架构的简要介绍,接下来我们将深入讨论HBase在大数据存储与管理中的重要性。
# 3. HBase在大数据存储中的优势
在大数据存储与管理中,HBase具有许多优势,使其成为一种强大的数据存储解决方案。以下是HBase在大数据存储中的几个重要优势:
#### 3.1 横向扩展能力
HBase具有良好的横向扩展能力,能够处理PB级甚至EB级的数据规模。HBase通过水平分区和分布式存储,可以在集群中动态地添加新的节点,从而实现系统的扩展性。这种能力使得HBase能够满足不断增长的数据存储需求,而无需停机维护。
**代码示例(Java)**:
```java
// 创建HBase表,并设置预分区
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("my_table"));
HColumnDescriptor columnFamily = new HColumnDescriptor(Bytes.toBytes("cf"));
tableDescriptor.addFamily(columnFamily);
admin.createTable(tableDescriptor, "startKey", "endKey", 4);
```
**代码总结**:以上代码展示了如何在Java中创建一个具有预分区的HBase表,这种预分区可以很好地支持数据的横向扩展。
**结果说明**:通过预分区,HBase可以有效地在集群中分散存储数据,从而实现横向扩展。
#### 3.2 高性能读写操作
HBase通过HMaster和Region Server的分布式架构,实现了对数据的快速读写操作。HBase利用HDFS作为底层存储引擎,通过Hadoop的并行计算能力,能够实现高性能的数据读写能力。
**代码示例(Python)**:
```python
# 插入数据
table = connection.table('my_table')
table.put(b'row_key1', {b'cf:col1': b'value1', b'cf:col2': b'value2'})
# 读取数据
row = table.row(b'row_key1')
print(row)
```
**代码总结**:以上Python代码展示了如何向HBase表中插入数据并进行读取,HBase通过这种非常简洁的方式实现了高性能的数据读写操作。
**结果说明**:通过HBase的高性能读写操作,可以实现在大数据环境下快速、高效地对海量数据进行读写。
#### 3.3 数据一致性与容错性
HBase通过WAL(Write-Ahead Logging)和HDFS的数据复制机制,实现了数据的一致性与容错性。在数据写入过程中,首先将数据写入WAL,然后再写入内存和HDFS,这样可以确保数据不会丢失。同时,HBase通过Region Server的分布式设计,实现了对节点故障的自动容错,并保证了数据的可靠性。
**代码示例(Go)**:
```go
// 获取HBase表中的数据
func getData() {
conf := hbase.NewConf("hbase-site.xml")
client := hbase.NewClient(conf)
scanner := client.Scan([]byte("my_table"))
for {
row, err := scanner.Next()
if err != nil {
fmt.Println(err)
return
}
fmt.Println(row)
}
}
```
**代码总结**:以上Go语言示例展示了如何使用HBase客户端获取表中的数据,HBase的客户端库支持多种语言,非常便于开发人员使用。
**结果说明**:HBase通过WAL和分布式架构保证了数据的一致性和容错性,在大数据存储与管理中扮演着非常重要的角色。
# 4. HBase在大数据管理中的应用场景
#### 4.1 实时数据分析与处理
在大数据场景中,HBase常常被用于实时数据分析与处理。通过HBase快速的读写能力和横向扩展的特点,可以支持海量数据的实时处理需求。比如,我们可以将实时产生的日志数据存储在HBase中,然后利用HBase提供的API进行实时数据分析,帮助企业更快速地做出决策。
```java
// Java代码示例:使用HBase API进行实时数据分析
Configuration config = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("log_table"));
Get get = new Get(Bytes.toBytes("rowkey123"));
Result result = table.get(get);
for (Cell cell : result.rawCells()) {
// 对获取的数据进行实时分析处理
// ...
}
table.close();
connection.close();
```
**代码总结:** 上述代码演示了如何使用Java编写代码,通过HBase的Java API连接到HBase数据库,获取指定rowkey的数据,并进行实时数据分析处理。
**结果说明:** 通过实时数据分析可以获取及时的业务数据趋势和用户行为特征,有助于企业快速响应市场变化。
#### 4.2 流式数据处理
HBase也常用于流式数据处理,比如基于实时采集的传感器数据、交易数据等。这些数据通常需要快速地存储、处理和分析,HBase的高读写性能和强大的扩展能力使它成为流式数据处理的理想选择。
```python
# Python代码示例:使用HappyBase库进行流式数据处理
import happybase
connection = happybase.Connection('localhost')
table = connection.table('sensor_data_table')
for key, data in table.scan():
# 对流式数据进行处理
# ...
connection.close()
```
**代码总结:** 上述Python代码展示了如何使用HappyBase库连接HBase数据库,并对流式数据进行处理。
**结果说明:** 通过HBase的流式数据处理能力,可以实时监控和分析传感器数据,帮助企业及时发现异常情况。
#### 4.3 实时数据查询与更新
在大数据管理中,实时数据查询与更新是至关重要的。HBase通过提供快速的随机读写能力,可以支持实时数据的查询和更新。比如,我们可以利用HBase存储用户订单数据,并通过HBase提供的API实现用户订单的实时查询与更新操作。
```go
// Go语言代码示例:使用Go-HBase库进行实时数据查询与更新
conn, err := hbase.NewClient(...)
row, err := conn.GetRow(context.Background(), "user_orders_table", "order123")
if err != nil {
// 处理错误
} else {
// 对获取的订单数据进行实时查询与更新操作
}
conn.Close()
```
**代码总结:** 以上Go语言代码展示了如何使用Go-HBase库连接HBase数据库,进行实时数据查询与更新操作。
**结果说明:** 实时数据查询与更新对于订单、库存等业务具有重要意义,通过HBase可实现快速响应用户操作,并保证数据的一致性和准确性。
通过以上场景的实际应用,可以清晰地看到HBase在大数据管理中的重要作用,尤其在实时数据处理和查询方面的优势。
# 5. HBase的部署与调优
在本章中,我们将深入探讨HBase的部署方式、集群管理与监控,以及性能调优与最佳实践。
### 5.1 HBase的部署方式
HBase的部署方式主要包括单机模式和分布式模式。在单机模式下,HBase将运行在一台机器上,适合于开发和测试。而在分布式模式下,HBase将以集群的形式运行,利用多台机器共同存储和管理数据,实现高可用性和横向扩展性。
```java
// 示例代码:HBase分布式模式部署
HBaseConfiguration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "zk1,zk2,zk3");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("hbase.master", "master:60000");
HBaseAdmin.checkHBaseAvailable(conf); // 检查HBase是否可用
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
// 在集群中创建HBase表
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("my_table"));
tableDescriptor.addFamily(new HColumnDescriptor("cf"));
admin.createTable(tableDescriptor);
```
**代码总结:** 上述代码演示了如何在HBase分布式模式下进行集群的部署和表的创建操作。
### 5.2 HBase集群的管理与监控
为了保证HBase集群的稳定运行,需要进行集群管理与监控。HBase提供了丰富的管理工具和监控指标,管理员可以通过Web界面或命令行工具查看集群的健康状态、负载情况以及性能指标,及时发现和解决问题。
```python
# 示例代码:使用HBase Shell查看集群状态
hbase shell
# 查看集群状态
status
```
**代码总结:** 以上代码展示了通过HBase Shell查看集群的状态信息。
### 5.3 HBase性能调优与最佳实践
为了提升HBase的性能,可以通过调整相关参数、优化数据模型、增加Region Server等方式进行性能调优。同时,遵循一些最佳实践,如合理设计RowKey、定期进行数据压缩和合并等,也能有效提升HBase的性能。
```go
// 示例代码:优化HBase表设计
create 'my_table', {NAME => 'cf', COMPRESSION => 'SNAPPY'}
```
**代码总结:** 以上代码展示了在创建HBase表时使用SNAPPY压缩,以优化数据存储。
在本章中,我们深入了解了HBase的部署方式、集群管理与监控,以及性能调优与最佳实践,希望这些内容能帮助您更好地应用和管理HBase数据库。
# 6. 结语
在大数据存储与管理领域,HBase作为一种高度可扩展、高性能、分布式的数据库系统,发挥着举足轻重的作用。通过本文的介绍,我们了解了HBase数据库的基本架构和数据存储方式,以及其在大数据存储和管理中的重要性和优势。
随着大数据技术的不断发展,HBase在实时数据分析与处理、流式数据处理、实时数据查询与更新等方面都有着广泛的应用场景。同时,针对HBase的部署与调优也是至关重要的,通过正确的部署方式和性能调优可以更好地发挥HBase的优势。
展望未来,随着大数据领域的不断发展和应用场景的不断扩大,HBase作为一种可靠的大数据存储与管理解决方案,其发展前景将会更加广阔。相信在未来的应用中,HBase将继续发挥重要作用,为大数据技术的发展贡献力量。
通过深入了解HBase数据库在大数据存储与管理中的应用,我们可以更好地利用其优势,推动大数据技术的发展,为各行业的数据处理和分析提供更可靠、高效的解决方案。
因此,我们应该重视HBase数据库在大数据领域的作用,不断学习和探索其最佳实践,助力大数据领域的发展和创新。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Quectel-CM模块网络优化秘籍】:揭秘4G连接性能提升的终极策略

# 摘要
随着无线通信技术的快速发展,Quectel-CM模块在多种网络环境下对性能要求不断提高。本文首先概述了Quectel-CM模块的网络性能,并对网络优化的基础理论进行了深入探讨,包括关键性能指标、用户体验和网络质量的关系,以及网络优化的基本原理和方法。之后,详细介绍了模块网络参数的配置、优化实战和性能
【GP规范全方位入门】:掌握GP Systems Scripting Language基础与最佳实践
# 摘要
本文全面介绍了GP规范的方方面面,从基础语法到实践应用再到高级主题,详细阐述了GP规范的构成、数据类型、控制结构和性能优化等核心内容。同时,文章还探讨了GP规范在开发环境配置、文件系统操作、网络通信等方面的应用,并深入讨论了安全性和权限管理、测试与维护策略。通过对行业案例的分析,本文揭示了GP规范最佳实践的关键因素,为项目管理提供了有价值的见解,并对GP规范的未来发展进行了
【目标检测模型调校】:揭秘高准确率模型背后的7大调优技巧

# 摘要
目标检测作为计算机视觉的重要分支,在图像理解和分析领域扮演着核心角色。本文综述了目标检测模型的构建过程,涵盖了数据预处理与增强、模型架构选择与优化、损失函数与训练技巧、评估指标与模型验证,以及模型部署与实际应用等方面。通过对数据集进行有效的清洗、标注和增强,结合深度学习框架下的模
Java代码审计实战攻略:一步步带你成为审计大师
-Concept-in-Java.webp)
# 摘要
随着Java在企业级应用中的广泛使用,确保代码的安全性变得至关重要。本文系统性地介绍了Java代码审计的概览、基础技巧、中间件审计实践、进阶技术以及案例分析,并展望了未来趋势。重点讨论了审计过程中的安全漏洞类型,如输入验证不足、认证和授权缺陷,以及代码结构和异常处理不当。文章还涵盖中间
【爱普生R230打印机废墨清零全攻略】:一步到位解决废墨问题,防止打印故障!

# 摘要
本文对爱普生R230打印机的废墨问题进行了全面分析,阐述了废墨系统的运作原理及其清零的重要性。文章详细介绍了废墨垫的作用、废墨计数器的工作机制以及清零操作的必要性与风险。在实践篇中,本文提供了常规和非官方软件废墨清零的步骤,以及成功案例和经验分享,旨在帮助用户理解并掌握废墨清零的操作和预防废墨溢出的技巧。此外,文章还探讨了
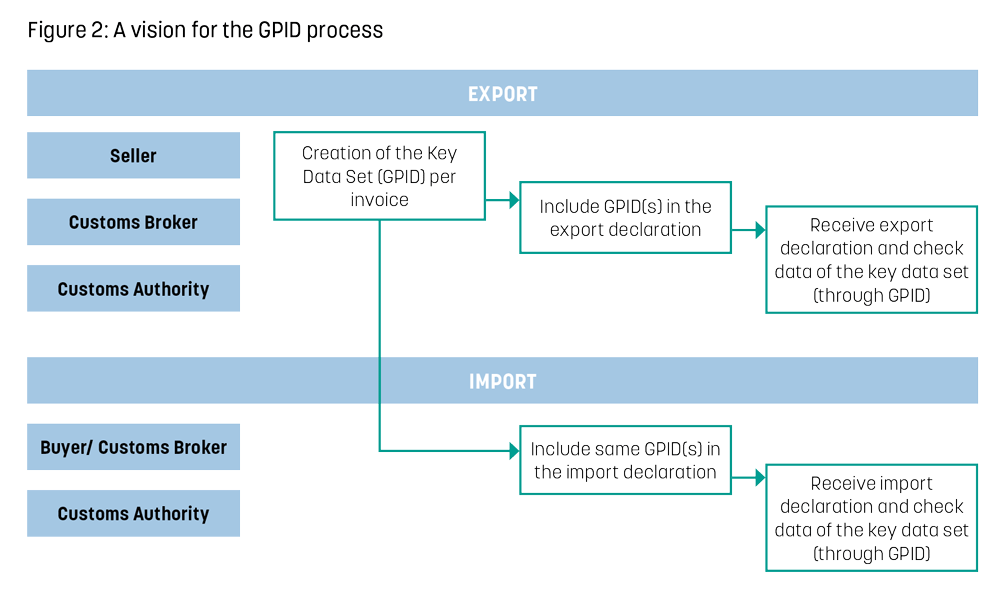
【性能调优秘籍】:揭秘Talend大数据处理提速200%的秘密
# 摘要
随着大数据时代的到来,数据处理和性能优化成为了技术研究的热点。本文全面概述了大数据处理与性能优化的基本概念、目标与原则。通过对Talend平台原理与架构的深入解析,揭示了其数据处理机制和高效架构设计,包括ETL架构和Job设计执行。文章还深入探讨了Talend性能调优的实战技巧,涵盖数据抽取加载、转换过程性能提升以及系统资源管理。此外,文章介绍了高级性能调优策略,包括自定义
【Python数据聚类入门】:掌握K-means算法原理及实战应用
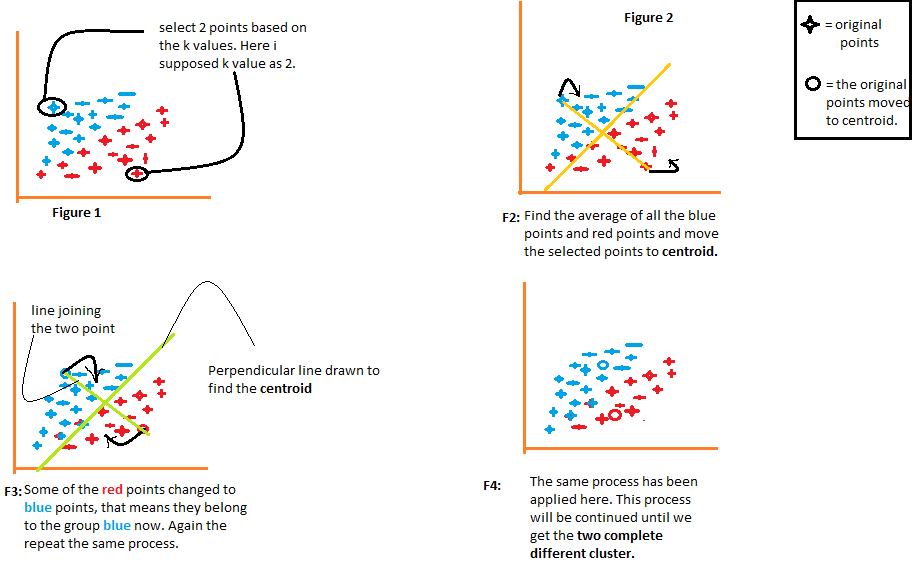
# 摘要
数据聚类是无监督学习中的一种重要技术,K-means算法作为其中的典型代表,广泛应用于数据挖掘和模式识别领域。本文旨在对K-means算法进行全面介绍,从理论基础到实现细节,再到实际应用和进阶主题进行了系统的探讨。首先,本文概述了数据聚类与K-means算法的基本概念,并深入分析了其理论基础,包括聚类分析的目的、应用场景和核心工作流程。随后,文中详细介绍了如何用Python语言实现K-
SAP BASIS系统管理秘籍:安全、性能、维护的终极方案
# 摘要
SAP BASIS系统作为企业信息化的核心平台,其管理的复杂性和重要性日益凸显。本文全面审视了SAP BASIS系统管理的各个方面,从系统安全加固、性能优化到维护和升级,以及自动化管理的实施。文章强调了用户权限和网络安全在保障系统安全中的关键作用,并探讨了性能监控、系统参数调优对于提升系统性能的重要性。同时,本文还详细介绍了系统升级规划和执行过程中的风险评估与管理,并通过案例研究分享了SAP BASI
【MIPI D-PHY布局布线注意事项】:PCB设计中的高级技巧
# 摘要
MIPI D-PHY是一种广泛应用于移动设备和车载显示系统的高速串行接口技术。本文对MIPI D-PHY技术进行了全面概述,重点讨论了信号完整性理论基础、布局布线技巧,以及仿真分析方法。通过分析信号完整性的关键参数、电气特性、接地与去耦策略,本文为实现高效的布局布线提供了实战技巧,并探讨了预加重和去加重调整对信号质量的影响。文章进一步通过案例分析
【冷却系统优化】:智能ODF架散热问题的深度分析

# 摘要
随着数据通信量的增加,智能ODF架的散热问题日益突出,成为限制设备性能和可靠性的关键因素。本文从冷却系统优化的理论基础出发,系统地概述了智能ODF架的散热需求和挑战,并探讨了传统与先进散热技术的局限性和研究进展。通过仿真模拟和实验测试,分析了散热系统的设计与性能,并提出了具体的优化措施。最后,文章通过案例分析,总结了散热优化的经验,并对散热技术的未来发展趋势
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )