utils库中的日志记录工具:有效监控应用状态
发布时间: 2024-10-11 01:08:30 阅读量: 114 订阅数: 45 

utils:保存log日志到存储设备
# 1. 日志记录工具的重要性与基本原理
在现代IT运维和开发实践中,日志记录工具是不可或缺的组成部分。它们负责记录应用程序运行过程中的关键信息,帮助开发者和运维人员诊断问题、追踪软件执行流程和分析系统性能瓶颈。一个优秀的日志系统能够提供可靠的信息源,以支持数据驱动的决策制定。
日志记录的原理是将程序运行时的详细信息输出到文件、数据库或控制台等存储介质中。基本的日志记录通常包括时间戳、日志级别、消息内容以及相关的上下文信息,如线程ID或用户标识。这些信息有助于快速定位问题,并允许后期的审查和分析。
基础原理部分,我们将探索日志系统的工作流程、重要性和最佳实践。以下是日志记录流程的简要概述:
1. **日志生成**:程序运行时,会触发日志事件,通过调用日志接口记录相关信息。
2. **日志格式化**:将日志信息转换成预定义的格式,包括时间戳、日志级别和消息内容。
3. **日志输出**:日志记录工具将格式化后的日志输出到预设的目标,如文件或控制台。
4. **日志存储**:日志信息被持久化存储,以便进行长期分析和问题排查。
掌握这些原理之后,IT从业者可以更有效地实施和优化日志管理策略,为系统的稳定运行和性能优化提供有力支持。在后续章节中,我们将深入探讨如何使用utils库日志工具来实现高效的日志记录,并展示具体的配置和实践操作。
# 2. utils库日志工具的基础使用
日志记录是开发过程中不可或缺的一部分,它帮助开发者监控、调试以及维护应用程序。utils库作为一个功能强大的日志工具包,提供了简单易用的日志记录功能。本章节将深入探讨utils库日志工具的基础使用方法,包括日志级别与输出格式的配置、日志的配置和初始化以及具体的日志记录实践操作。
## 2.1 日志级别与输出格式
### 2.1.1 理解日志级别
日志级别为日志消息定义了重要性。在utils库中,日志级别从高到低包括:ERROR、WARN、INFO、DEBUG 和 TRACE。不同级别的日志消息表示了消息的重要性以及处理紧急程度的差异。
- ERROR:表示错误发生,导致应用程序的某些功能异常。
- WARN:警告级别,表示可能出现问题,但不影响程序运行。
- INFO:提供一般性的运行信息,帮助了解程序运行状态。
- DEBUG:用于开发调试,记录调试信息,便于开发者排查问题。
- TRACE:记录更详细的执行流程信息。
在实际开发中,通常会根据开发和运行阶段的不同需求,设置不同的日志级别,以便于更高效地获取关键信息。
### 2.1.2 格式化日志输出
格式化输出可以更好地组织日志内容,提高信息的可读性。utils库的日志输出支持多种参数化方式,如时间戳、日志级别、消息内容等。格式化表达式如下:
```plaintext
%{level} %{message}
```
在这里,`%{level}`代表日志级别,`%{message}`代表日志消息。您还可以添加其他参数,例如线程名、时间戳等,以满足日志输出的特定需求。
```java
// Java 示例代码:格式化日志输出
Logger logger = Logger.getLogger("MyClass");
logger.log(***, "This is an info level log message.");
```
在上述代码中,我们创建了一个Logger实例并使用info级别输出了一条日志。通过这样的配置,日志消息会被输出为带有时间戳和日志级别的格式化文本。
## 2.2 配置和初始化utils库日志
### 2.2.1 日志配置文件解析
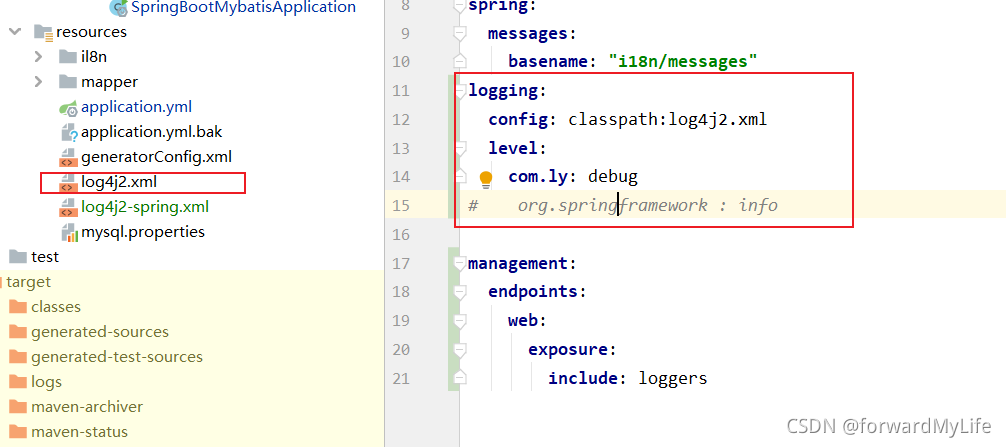
在utils库中,日志的配置信息通常存储在一个配置文件中,例如log4j2.xml。配置文件中详细定义了日志的级别、输出格式、输出目标等信息。
```xml
<!-- log4j2.xml 示例配置片段 -->
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
```
上述配置文件定义了一个控制台输出器,使用PatternLayout来指定日志输出的格式,并将根logger的级别设置为info。
### 2.2.2 日志初始化流程
utils库通常提供API进行日志初始化。以下是一个初始化日志系统的示例:
```java
// Java 示例代码:初始化日志系统
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.core.LoggerContext;
public class Main {
public static void main(String[] args) {
System.setProperty("log4j.configurationFile", "path/to/your/log4j2.xml");
LoggerContext context = (LoggerContext) LogManager.getContext(false);
context.reconfigure();
}
}
```
在这段代码中,我们设置了log4j的配置文件路径,并通过`reconfigure`方法重新加载了配置。这将使得日志系统根据配置文件中的设置进行初始化。
## 2.3 日志记录实践
### 2.3.1 简单日志记录示例
```java
// Java 示例代码:简单日志记录
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class LogExample {
private static final Logger logger = LogManager.getLogger(LogExample.class);
public void logSomething() {
***("This is an INFO log message.");
logger.debug("This is a DEBUG log message.");
logger.error("This is an ERROR log message.");
}
}
```
通过上述代码,我们演示了如何在代码中使用日志记录API记录不同级别的日志信息。在实际应用中,你可以在函数或方法中添加相应级别的日志记录点,以便于跟踪程序执行流程和问题排查。
### 2.3.2 错误处理与异常日志记录
记录错误和异常信息是日志记录非常重要的方面。utils库提供了记录异常堆栈信息的功能,帮助开发者快速定位问题根源。
```java
try {
// 可能会抛出异常的代码
} catch (Exception e) {
logger.error("An exception occurred:", e);
}
```
在这个示例中,如果在try块中捕获到异常,它将被记录在日志中,包括异常类型和堆栈跟踪。这为开发者提供了调试程序时所需的详细异常信息。
以上所述便是utils库日志工具的基础使用方法。通过本章内容,我们了解了日志级别与格式化的配置、日志的初始化过程,以及如何在代码中进行日志记录。这些基础知识为更高级的日志功能应用打下了坚实的基础。接下来,我们将探索utils库日志工具的高级特性,进一步提升日志记录的能力和效率。
# 3. utils库日志工具的高级特性
## 3.1 日志轮转与压缩
### 3.1.1 日志文件的自动轮转
随着系统运行时间的增加,日志文件会不断增长,如果不定期处理,最终将消耗大量磁盘空间,并影响日志检索效率。为了有效地管理日志文件的大小和数量,utils库提供了日志文件自动轮转的功能。自动轮转允许开发者设置日志文件达到一定大小后,自动切割并开始新文件的记录。这在很多情况下可以显著提升日志的可管理性,并减少对磁盘空间的需求。
通常,日志轮转的配置参数包括轮转的大小限制、轮转的时间间隔和轮转后的保留策略。以下是一个轮转配置的示例:
```json
"rotation": {
"max_bytes": 1024 * 1024 * 100, // 单个日志文件最大字节数,这里设置为100MB
"backup_count": 3, // 保留备份日志文件数量
"interval": "midnight", // 轮转时间,这里设置为每天午夜
"compression": true /
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**专栏简介:**
本专栏深入探索 Python utils 库,这是一款功能强大的实用工具库,旨在简化和增强 Python 开发。从基础到高级应用,专栏涵盖了 utils 库的各个方面,包括:
* 编写可复用的代码片段的最佳实践
* 自定义工具函数以提高开发效率
* 理解 utils 库的设计哲学
* 处理文件和目录的常用技巧
* 数据结构处理的高级技术
* 并发编程工具,如线程和进程管理
* 日期和时间模块,用于时间处理
* 测试工具,用于编写可维护的单元测试
* 数据分析中的应用,简化数据处理
* 科学计算中的应用,简化复杂公式的实现
* XML 和 HTML 解析工具,用于提取和处理网页数据
* 日志记录工具,用于监控应用状态
* 文件压缩和解压缩功能,用于高效的数据存储和传输
* 文本处理工具,用于字符串操作
* 序列化工具,用于对象持久化
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
空间统计学新手必看:Geoda与Moran'I指数的绝配应用
# 摘要
本论文深入探讨了空间统计学在地理数据分析中的应用,特别是运用Geoda软件进行空间数据分析的入门指导和Moran'I指数的理论与实践操作。通过详细阐述Geoda界面布局、数据操作、空间权重矩阵构建以及Moran'I指数的计算和应用,本文旨在为读者提供一个系统的学习路径和实操指南。此外,本文还探讨了如何利用Moran'I指数进行有效的空间数据分析和可视化,包括城市热岛效应的空间分析案例研究。最终,论文展望了空间统计学的未来
【Python数据处理秘籍】:专家教你如何高效清洗和预处理数据

# 摘要
随着数据科学的快速发展,Python作为一门强大的编程语言,在数据处理领域显示出了其独特的便捷性和高效性。本文首先概述了Python在数据处理中的应用,随后深入探讨了数据清洗的理论基础和实践,包括数据质量问题的认识、数据清洗的目标与策略,以及缺失值、异常值和噪声数据的处理方法。接着,文章介绍了Pandas和NumPy等常用Python数据处理库,并具体演示了这些库在实际数
【多物理场仿真:BH曲线的新角色】:探索其在多物理场中的应用
# 摘要
本文系统介绍了多物理场仿真的理论基础,并深入探讨了BH曲线的定义、特性及其在多种材料中的表现。文章详细阐述了BH曲线的数学模型、测量技术以及在电磁场和热力学仿真中的应用。通过对BH曲线在电机、变压器和磁性存储器设计中的应用实例分析,本文揭示了其在工程实践中的重要性。最后,文章展望了BH曲线研究的未来方向,包括多物理场仿真中BH曲线的局限性
【CAM350 Gerber文件导入秘籍】:彻底告别文件不兼容问题
# 摘要
本文全面介绍了CAM350软件中Gerber文件的导入、校验、编辑和集成过程。首先概述了CAM350与Gerber文件导入的基本概念和软件环境设置,随后深入探讨了Gerber文件格式的结构、扩展格式以及版本差异。文章详细阐述了在CAM350中导入Gerber文件的步骤,包括前期
【秒杀时间转换难题】:掌握INT、S5Time、Time转换的终极技巧
# 摘要
时间表示与转换在软件开发、系统工程和日志分析等多个领域中起着至关重要的作用。本文系统地梳理了时间表示的概念框架,深入探讨了INT、S5Time和Time数据类型及其转换方法。通过分析这些数据类型的基本知识、特点、以及它们在不同应用场景中的表现,本文揭示了时间转换在跨系统时间同步、日志分析等实际问题中的应用,并提供了优化时间转换效率的策略和最
【传感器网络搭建实战】:51单片机协同多个MLX90614的挑战

# 摘要
本论文首先介绍了传感器网络的基础知识以及MLX90614红外温度传感器的特点。接着,详细分析了51单片机与MLX90614之间的通信原理,包括51单片机的工作原理、编程环境的搭建,以及传感器的数据输出格式和I2C通信协议。在传感器网络的搭建与编程章节中,探讨了网络架构设计、硬件连接、控制程序编写以及软件实现和调试技巧。进一步
Python 3.9新特性深度解析:2023年必知的编程更新
# 摘要
随着编程语言的不断进化,Python 3.9作为最新版本,引入了多项新特性和改进,旨在提升编程效率和代码的可读性。本文首先概述了Python 3.
金蝶K3凭证接口安全机制详解:保障数据传输安全无忧
# 摘要
金蝶K3凭证接口作为企业资源规划系统中数据交换的关键组件,其安全性能直接影响到整个系统的数据安全和业务连续性。本文系统阐述了金蝶K3凭证接口的安全理论基础,包括安全需求分析、加密技术原理及其在金蝶K3中的应用。通过实战配置和安全验证的实践介绍,本文进一步阐释了接口安全配置的步骤、用户身份验证和审计日志的实施方法。案例分析突出了在安全加固中的具体威胁识别和解决策略,以及安全优化对业务性能的影响。最后
【C++ Builder 6.0 多线程编程】:性能提升的黄金法则
# 摘要
随着计算机技术的进步,多线程编程已成为软件开发中的重要组成部分,尤其是在提高应用程序性能和响应能力方面。C++ Builder 6.0作为开发工具,提供了丰富的多线程编程支持。本文首先概述了多线程编程的基础知识以及C++ Builder 6.0的相关特性,然后深入探讨了该环境下线程的创建、管理、同步机制和异常处理。接着,文章提供了多线程实战技巧,包括数据共享
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )