R-Tree索引结构中的搜索算法原理
发布时间: 2024-02-25 16:43:27 阅读量: 37 订阅数: 46 

R树索引的查询研究
# 1. R-Tree索引结构介绍
## 1.1 R-Tree的概念
R-Tree是一种多维索引结构,最初由Antonin Guttman在1984年提出。它被广泛应用于空间数据索引,可以高效地支持范围查询、最近邻查询等操作。
## 1.2 R-Tree的应用领域
R-Tree广泛应用于地理信息系统(GIS)、空间数据库、文档检索等领域。在GIS中,R-Tree可以高效地管理地理空间数据,快速执行空间关系查询。在数据库系统中,R-Tree可以加速空间数据的检索和查询操作。
## 1.3 R-Tree与传统B树索引的对比
相较于传统的B树索引,R-Tree更适用于多维空间数据的索引和查询。它可以有效地减少搜索空间,加速查询速度,并且能够灵活地支持范围查询等复杂查询操作。因此,在空间数据处理领域,R-Tree通常比B树索引具有更好的性能优势。
# 2. R-Tree的数据结构与组织方式
R-Tree是一种多维索引结构,主要用于高效地存储和检索多维空间数据。它是一种树形结构,类似于B树,但是专门设计用来处理多维数据索引。在R-Tree中,每个节点代表一个矩形区域,叶子节点存储实际的数据对象,而非叶子节点存储其子节点的最小外包矩形(Minimum Bounding Rectangle,MBR)以及指向子节点的指针。
### 2.1 R-Tree的节点结构
R-Tree的节点包含以下要素:
- MBR:代表节点所表示的矩形区域。对于非叶子节点来说,MBR是其所有子节点的最小外包矩形;对于叶子节点来说,MBR覆盖所存储的实际数据对象。
- 子节点指针:指向子节点的指针。对于非叶子节点来说,这些指针指向其子节点;对于叶子节点来说,这些指针为空。
### 2.2 R-Tree的分裂策略
当一个节点需要插入新的数据,但空间已满时,需要执行分裂操作。R-Tree的分裂策略主要有两种:
- 线性分裂(Linear Split):将节点的子节点按照一定的策略进行两部分分裂。
- 贪心分裂(Greedy Split):选择合适的节点作为种子,然后将其他节点分配给两个种子节点,直到满足要求。
### 2.3 R-Tree的索引维护方式
R-Tree的索引维护主要包括节点的插入、删除和更新操作。在插入和删除过程中,需要动态地调整R-Tree的结构,保持其平衡和高效性。
以上是R-Tree的数据结构与组织方式的相关内容,接下来我们将详细介绍R-Tree的插入算法原理。
# 3. R-Tree的插入算法原理
R-Tree的插入算法是指向R-Tree索引结构中添加新数据时所采取的算法流程。在R-Tree中,插入算法的主要目标是根据数据对象的空间范围,将其适当地插入到R-Tree的叶子节点中,并确保索引结构的平衡性和高效性。
#### 3.1 R-Tree中的插入流程
R-Tree的插入算法流程一般包括以下步骤:
1. 从R-Tree的根节点开始,递归地选择合适的叶子节点;
2. 在叶子节点的数据条目中选择一个合适的位置,将新数据对象插入其中;
3. 如果插入后导致叶子节点的数据条目超过了最大容量,则触发节点分裂操作;
4. 沿着插入路径更新各级父节点的边界框信息;
5. 如果根节点发生分裂,则生成一个新的根节点

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《R-Tree空间索引结构》专栏深入探讨了R-Tree索引在地理数据可视化和应用场景中的作用,以及与KD-Tree空间索引的比较与分析。文章围绕R-Tree索引的特点与优势展开,阐述了其在地理数据管理与可视化中的重要性和应用前景。同时,通过与KD-Tree索引的比较与应用场景分析,深入探讨了两者在不同领域的适用性和性能对比,为读者提供了全面、深入的视角。本专栏旨在让读者对R-Tree空间索引结构有更深入的理解,同时帮助他们更好地应用于地理数据可视化与管理中,促进地理信息系统领域的发展和创新。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Qt Creator万年历开发秘籍】:C++界面布局与事件处理的终极指南
# 摘要
本文重点讨论了利用Qt Creator与C++开发万年历项目的设计、规划和实现过程。第一章回顾了Qt Creator和C++的基础知识,为项目开发奠定基础。第二章详细介绍了万年历项目的设计理念、目标和技术选型,并阐述了开发环境的搭建方法。第三章深入解析了C++在界面布局方面的应用,包括基础控件的使用、布局管理器的理解以及信号与槽机制的实践。第四章
【领导力重塑】:MBTI揭示不同人格的最佳领导风格

# 摘要
本文综述了MBTI理论在领导力评估和培养中的应用,探讨了不同人格类型与领导风格之间的关系,并分析了MBTI在团队管理和领导力重塑策略中的实际运用。文章首先概述了MBTI理论,随后深入探讨了人格维度与领导力特征的联系,并针对不同的MBTI类型提出了领导力培养方法。通过理论应用章节,本文展示了MBTI测试在识别潜在领导者方面
【代码审查流程优化】:通过VCS提高代码质量的5大步骤

# 摘要
代码审查是确保软件质量的关键环节,它涉及对代码的系统性评估以发现错误、提升设计质量以及促进团队知识共享。本文深入探讨了代码审查的重要性与目标,并详细介绍了版本控制系统(VCS)的基础知识、工具对比、集成方法及其在审查流程中的应用。此外,文中提出了代码审查流程的理论框架
银行架构演进指南:掌握从单体到微服务的转型秘诀

# 摘要
本文回顾了银行系统架构的历史演进,并深入探讨了单体架构和微服务架构的原理、特点及挑战。通过分析单体架构的局限性及实际案例,文章指出其在扩展性、维护和部署方面的难题。随后,文章转向微服务架构的理论基础,包括其定义、关键组件、设计原则,并详细讨论了微服务架构的实践应用,如安全性考量、监控与日志管理。针对微服务架构面临的挑战,文章提出了一系列对策和最佳实践。最后,文章展望了未来银行架构的发展趋势,包括银行业务的创新、新兴技术的应用以及云原生和S
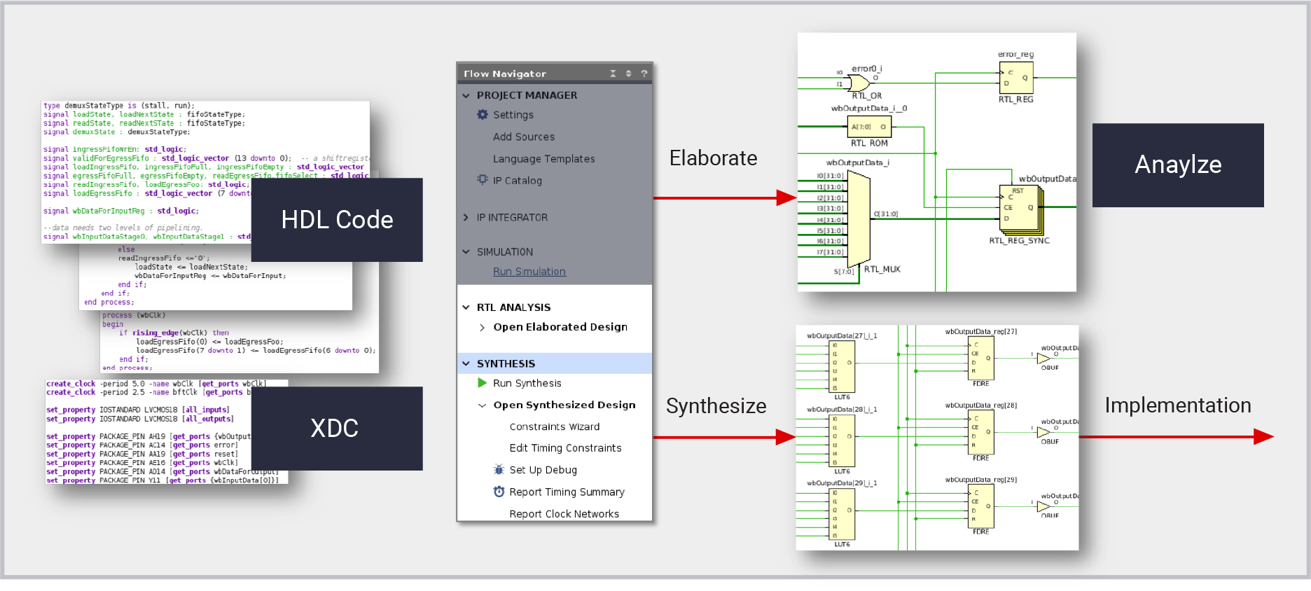
【Vivado与ModelSim协同仿真终极指南】:从新手到专家的10大必学技巧
# 摘要
本文旨在探讨Vivado与ModelSim协同仿真的基础知识与高级应用。首先介绍了Vivado与ModelSim的环境配置、项目管理以及基本使用方法。紧接着,重点讨论了协同仿真中的关键技巧,如设计模块化、测试平台建立和波形分析。第四章进一步探索仿真优化、高级测试技术应用以及多核仿真与并行测试的优势与实践。最后,通过多个实战案
NI-VISA高级技巧:LabVIEW中的多串口数据采集魔法

# 摘要
本文介绍了LabVIEW和NI-VISA在多串口环境下的配置和应用,涵盖串口通信的基础知识、LabVIEW中的数据采集处理技术,以及多串口通信的高级应用。文中详细解析了串口通信协议,阐述了使用NI-VISA工具进行串口配置的过程,包括硬件连接、脚本编写以及高级参数设置。同
【SAP HANA性能巫师】:日期函数调优术,让查询速度飞跃提升

# 摘要
本文旨在全面介绍SAP HANA数据库中日期函数的重要性及其优化策略。首先,文章简要概述了SAP HANA和日期函数的基础知识,强调了日期函数在数据库查询中的核心作用。随后,深入探讨了日期函数的分类和核心功能,以及它们在SQL查询中的实际应用。文章还对日期函数的性能进
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )