云原生应用中的Spring AOP:集成与优化策略
发布时间: 2024-10-22 12:06:24 阅读量: 24 订阅数: 39 

Spring Boot 集成 WebSocket(原生注解与Spring封装方式)
# 1. Spring AOP基础概念
## 1.1 AOP简介
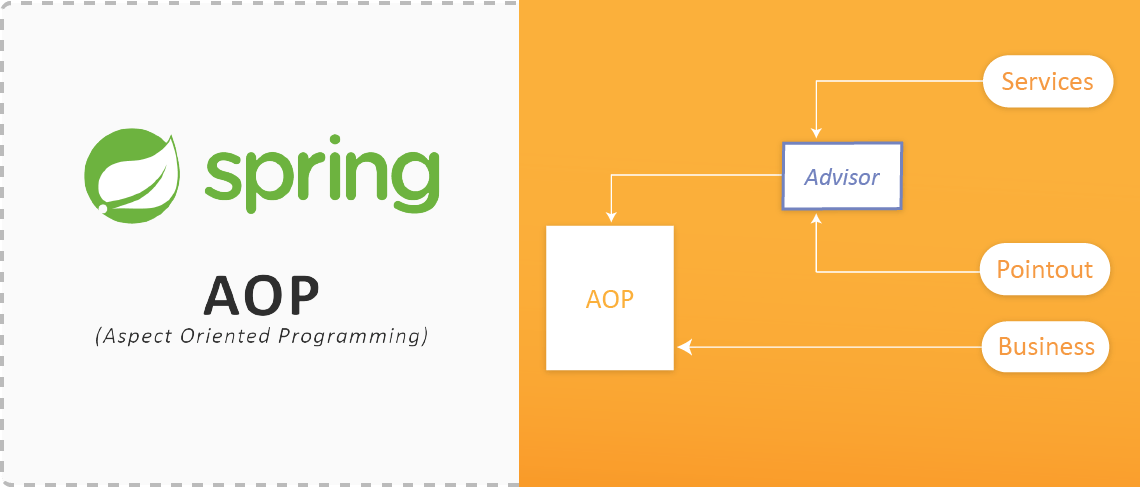
面向切面编程(Aspect-Oriented Programming,AOP)是一种编程范式,旨在将横切关注点(cross-cutting concerns)从业务逻辑中分离出来,以便更加清晰地模块化。横切关注点通常指的是那些跨越多个模块的功能,如日志记录、安全性和事务管理等。
## 1.2 Spring AOP核心组件
Spring AOP使用了几个核心组件来实现面向切面编程,主要包含以下几个:
- **切面(Aspect)**:一个关注点的模块化,这些关注点通常横跨多个对象。
- **连接点(Pointcut)**:在程序执行期间的某个特定点,如方法的执行或异常的处理。
- **通知(Advice)**:在切面的某个特定连接点上执行的动作,例如在方法调用前后执行的代码。
## 1.3 AOP的工作原理
Spring AOP利用动态代理实现切面的编织。具体来说,它通过创建目标对象的代理实例来拦截对目标对象方法的调用,并将通知逻辑应用到这些调用上。代理可以是JDK动态代理(针对接口的实现)或CGLIB代理(针对类的实现)。
通过理解Spring AOP的基础概念,开发者可以开始设计和实现自己的切面,进而提高代码的可维护性和清晰度。
# 2. ```
# 第二章:Spring AOP的集成过程详解
Spring AOP,即面向切面编程,是Spring框架中的一个重要特性。它允许开发者将横切关注点从业务逻辑中分离出来,独立编写代码模块,再通过切面的方式动态地添加到需要处理的对象中。本章节将详细解析Spring AOP的集成过程,包含依赖配置、切面编程以及事务管理等关键步骤。
## 2.1 Spring AOP的依赖配置
要开始使用Spring AOP,首先需要在项目中正确配置相关依赖。Spring Boot极大地简化了这一过程,让我们可以专注于业务逻辑的实现。
### 2.1.1 依赖管理工具的选择与配置
在使用Spring Boot进行项目开发时,通常会用到Maven或Gradle作为项目的构建工具和依赖管理工具。这里以Maven为例,讲解如何配置Spring AOP所需的依赖。
```xml
<dependencies>
<!-- Spring Boot核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- Spring AOP依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<!-- 其他项目所需依赖 -->
</dependencies>
```
以上配置中,`spring-boot-starter-aop` 依赖是集成Spring AOP的核心依赖,而 `spring-boot-starter` 包含了Spring Boot的核心功能,能够帮助我们快速搭建项目结构。
### 2.1.2 Spring Boot与AOP的集成要点
在Spring Boot项目中集成AOP主要依赖于 `@EnableAspectJAutoProxy` 注解。这个注解通常位于Spring Boot的主配置类上,用于启用自动代理,并且通常不需要额外配置。
```java
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.EnableAspectJAutoProxy;
@SpringBootApplication
@EnableAspectJAutoProxy
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}
```
通过在主配置类上使用 `@EnableAspectJAutoProxy`,Spring Boot会自动扫描带有 `@Aspect` 注解的类,并将这些类定义的切面应用到相应的连接点上。
## 2.2 Spring AOP的切面编程
在配置好依赖并启用了自动代理之后,接下来我们将深入理解如何创建和配置切面(Aspect)。
### 2.2.1 切面(Aspect)的创建和配置
切面是AOP中最核心的概念之一,它是一个包含切点(Pointcut)和通知(Advice)的模块。切面的创建非常简单,只需要几个步骤。
```java
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.annotation.After;
import org.aspectj.lang.JoinPoint;
@Aspect
public class LoggingAspect {
// 定义切点,这里配置为某个服务类中的所有方法
@Pointcut("within(com.example.service.*)")
public void serviceLayerPointcut() {}
// 在切点之前执行
@Before("serviceLayerPointcut()")
public void logBefore(JoinPoint joinPoint) {
// 打印方法执行前的日志信息
}
}
```
在上述代码中,`@Aspect` 注解标识了一个类作为切面。`@Pointcut` 注解定义了一个切点,指定为服务层中的所有方法。`@Before` 注解定义了一个前置通知,它会在切点方法执行前被调用。
### 2.2.2 连接点(Pointcut)的定义和使用
连接点是程序执行过程中的某个特定点,例如方法调用或异常抛出等。在Spring AOP中,连接点通常是方法执行的点。要定义一个连接点,可以使用切点表达式来描述。
```java
// 使用AspectJ的切点表达式
@Pointcut("execution(* com.example.service.*.*(..))")
public void serviceLayerPointcut() {}
```
在上面的示例中,我们定义了一个切点,其表达式匹配 `com.example.service` 包下所有类的所有方法。这表示,所有这些方法都将成为连接点,可以被我们的切面进行增强。
### 2.2.3 通知(Advice)的类型和应用场景
通知是切面中定义的方法执行时机的声明。Spring AOP支持多种类型的通知,包括前置通知(Before)、后置通知(After)、返回通知(AfterReturning)、异常通知(AfterThrowing)和环绕通知(Around)。
```java
// 前置通知示例
@Before("serviceLayerPointcut()")
public void logBefore(JoinPoint joinPoint) {
// 在方法执行之前记录日志
}
// 后置通知示例
@After("serviceLayerPointcut()")
public void logAfter(JoinPoint joinPoint) {
// 在方法执行之后记录日志,无论成功或失败
}
// 返回通知示例
@AfterReturning(pointcut = "serviceLayerPointcut()", returning = "result")
public void logAfterReturning(JoinPoint joinPoint, Object result) {
// 当方法成功执行完成后记录返回值
}
// 异常通知示例
@AfterThrowing(pointcut = "serviceLayerPointcut()", throwing = "ex")
public void logAfterThrowing(JoinPoint joinPoint, Throwable ex) {
// 当方法执行过程中抛出异常时记录异常信息
}
// 环绕通知示例
@Around("serviceLayerPointcut()")
public Object logAround(ProceedingJoinPoint joinPoint) throws Throwable {
// 在方法执行前后记录日志,并决定是否继续执行方法
// 执行方法逻辑
}
```
以上代码展示了不同通知类型的使用方式。使用得当的通知类型,可以让切面代码更加清晰,并且根据不同的业务场景灵活地应用切面逻辑。
## 2.3 Spring AOP的事务管理
Spring AOP不仅仅能用于日志记录和监控,它还可以用来管理事务。
### 2.3.1 声明式事务管理的原理
声明式事务管理是通过使用切面来控制事务的开启、提交和回滚等操作。它的优点是代码侵入性小,且配置即可实现。
```java
import org.springframework.transaction.annotation.Transactional;
@Transactional
public void performTransaction() {
// 业务逻辑
}
```
在上述代码中,`@Transactional` 注解就声明了一个事务管理的切面,Spring将通过这个切面来控制声明了该注解的方法的事务行为。
### 2.3.2 事务增强的应用和配置
事务增强通常在 `@Transactional` 注解的帮助下使用,也可以在切面编程中手动定义。
```java
@Aspect
public class TransactionAspect {
@Before("execution(* com.example.service.*.*(..))")
public void beginTransaction(JoinPoint joinPoint) {
// 开启事务
}
@AfterReturning(pointcut = "execution(* com.example.service.*.*(..))", returning = "result")
public void commitTransaction(JoinPoint joinPoint, Object result) {
// 根据方法执行的结果决定是提交事务还是回滚事务
}
}
```
在上面的切面中,我们定义了在服务层方法执行前开启事务,在方法成功执行后提交事务。这样,我们就在切面中管理了事务的生命周期。
以上就是Spring AOP集成过程中的依赖配置、切面编程和事务管理的详解。通过这些步骤,我们可以将Spring AOP应用到实际项目中,实现业务逻辑的分离和集中管理。接下来的章节将继续深入介绍Spring AOP在实践中的应用案例。
```
# 3. Spring AOP实践应用案例
## 3.1 日志记录和审计功能的实现
### 3.1.1 AOP实现日志记录的最佳实践
日志记录是软件开发中不可或缺的一环,它有助于监控应用的运行状态,诊断问题,以及进行安全审计。通过Spring AOP,我们可以轻松地为应用程序中的各种操作添加日志记录功能,而无需侵入核心业务代码。以下是一些实现日志记录的最佳实践:
1. **定义切面(Aspect)**:创建一个专门用于日志记录的切面类,其中包含通知(Advice)方法,例如@AfterReturning、@Before等。
2. **使用注解标注关键方法**:为需要记录日志的方法添加自定义注解,这样可以灵活地控制哪些方法需要日志记录。
3. **使用环绕通知(Around Advice)**:环绕通知可以提供完整的控制,你可以在这个通知中编写日志记录的代码,然后调用目标方法。
4. **日志信息的丰富性**:确保日志包含足够的信息,如方法名、参数、执行时间、返回结果、异常等。
5. **异步日志记录**:为了不阻塞业务流程,可以将日志记录操作放到一个独立的线程中执行。
6. **日志级别和格式**:根据需要调整日志级别和格式,以适应不同的日志管理和分析需求。
7. **统一日志库**:推荐使用如SLF4J这样的抽象层来管理日志库,使得切换不同日志实现更加简单。
下面的代码展示了如何实现一个简单的日志记录切面:
```java
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
***ponent;
@Aspect
@Component
public class LoggingAspect {
private static final Logger log = LoggerFactory.getLogger(LoggingAspect.class);
@Around("@annotation(Loggable)")
public Object logExecutionTime(ProceedingJoinPoint joinPoint) throws Throwable {
long startTime = System.currentTimeMillis();
Object result = joinPoint.proceed();
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Java Spring AOP(面向切面编程),提供了一系列全面且实用的指南,帮助开发者掌握 AOP 的核心概念和最佳实践。从理论基础到源码分析,再到实际应用,本专栏涵盖了 AOP 的各个方面,包括事务管理、日志记录、异常处理、性能优化、切点控制、动态代理、业务逻辑组件、缓存策略、安全框架集成、微服务架构和分布式系统中的应用。通过深入浅出的讲解和丰富的示例,本专栏旨在帮助开发者提升代码质量、提高维护性,并构建更健壮、更高效的应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【XJC-608T-C控制器与Modbus通讯】:掌握关键配置与故障排除技巧(专业版指南)
.jpg)
# 摘要
本文全面介绍了XJC-608T-C控制器与Modbus通讯协议的应用与实践。首先概述了XJC-608T-C控制器及其对Modbus协议的支持,接着深入探讨了Modbus协议的理论基础,包括其发展历史和帧结构。文章详细说明了XJC-608T-C控制器的通信接口配置,以及如何进行Modbus参数的详细设置。第三章通过实践应用,阐述了Modbus RTU和TCP通讯模
掌握Walktour核心原理:测试框架最佳实践速成

# 摘要
本文详细介绍了Walktour测试框架的结构、原理、配置以及高级特性。首先,概述了测试框架的分类,并阐述了Walktour框架的优势。接着,深入解析了核心概念、测试生命周期、流程控制等关键要素。第三章到第五章重点介绍了如何搭建和自定义Walktour测试环境,编写测试用例,实现异常
【水文模拟秘籍】:HydrolabBasic软件深度使用手册(全面提升水利计算效率)

# 摘要
本文全面介绍HydrolabBasic软件,旨在为水文学研究与实践提供指导。文章首先概述了软件的基本功能与特点,随后详细阐述了安装与环境配置的流程,包括系统兼容性检查、安装步骤、环境变量与路径设置,以及针对安装过程中常见问题的解决方案。第三章重点讲述了水文模拟的基础理论、HydrolabBasic的核心算法以及数据处理技巧。第四章探讨了软件的高级功能,如参数敏感
光盘挂载效率优化指南:提升性能的终极秘籍
# 摘要
本文全面探讨了光盘挂载的基础知识、性能瓶颈、优化理论及实践案例,并展望了未来的发展趋势。文章从光盘挂载的技术原理开始,深入分析了影响挂载性能的关键因素,如文件系统层次结构、挂载点配置、读写速度和缓存机制。接着,提出了针对性的优化策略,包括系统参数调优、使用镜像文件以及自动化挂载脚本的应用,旨在提升光盘挂载的性能和效率。通过实际案例研究,验证了优化措施的有效
STM32F407ZGT6硬件剖析:一步到位掌握微控制器的10大硬件特性
# 摘要
本文针对STM32F407ZGT6微控制器进行了全面的概述,重点分析了其核心处理器与存储架构。文章详细阐述了ARM Cortex-M4内核的特性,包括其性能和功耗管理能力。同时,探讨了内部Flash和RAM的配置以及内存保护与访问机制。此外,本文还介绍了STM32F407ZGT6丰富的外设接口与通信功能,包括高速通信接口和模拟/数字外设的集成。电源管理和低功耗
【系统性能优化】:专家揭秘注册表项管理技巧,全面移除Google软件影响

# 摘要
注册表项管理对于维护和优化系统性能至关重要。本文首先介绍了注册表项的基础知识和对系统性能的影响,继而探讨了优化系统性能的具体技巧,包括常规和高级优化方法及其效果评估。文章进一步深入分析了Google软件对注册表的作用,并提出了清理和维护建议。最后,通过综合案例分析,展示了注册表项优化的实际效果,并对注册表项管理的未来趋势进行了展望。本文旨在为读者提供注册表项管理的全面理解,并帮助他们有效提升系统性能。
SAPRO V5.7高级技巧大公开:提升开发效率的10个实用方法

# 摘要
本文全面介绍SAPRO V5.7系统的核心功能与高级配置技巧,旨在提升用户的工作效率和系统性能。首先,对SAPRO V5.7的基础知识进行了概述。随后,深入探讨了高级配置工具的使用方法,包括工具的安装、设置以及高级配置选项的应用。接着,本文聚焦于编程提升策略,分享了编码优化、IDE高级使用以及版本控制的策略。此外,文章详细讨论了系统维护和监控的
线扫相机选型秘籍:海康vs Dalsa,哪个更适合你?
# 摘要
本文对线扫相机技术进行了全面的市场分析和产品比较,特别聚焦于海康威视和Dalsa两个业界领先品牌。首先概述了线扫相机的技术特点和市场分布,接着深入分析了海康威视和Dalsa产品的技术参数、应用案例以及售后服务。文中对两者的核心性能、系统兼容性、易用性及成本效益进行了详尽的对比,并基于不同行业应用需求提出了选型建议。最后,本文对线扫相机技术的未来发展趋势进行了展望,并给出了综合决策建议,旨在帮助技术人员和采购者更好地理解和选择适合的线扫相机产品。
# 关键字
线扫相机;市场分析;技术参数;应用案例;售后服务;成本效益;选型建议;技术进步
参考资源链接:[线扫相机使用与选型指南——海
【Smoothing-surfer绘图性能飞跃】:图形渲染速度优化实战

# 摘要
图形渲染是实现计算机视觉效果的核心技术,其性能直接影响用户体验和应用的互动性。本文第一章介绍了图形渲染的基本概念,为理解后续内容打下基础。第二章探讨了图形渲染性能的理论基础,包括渲染管线的各个阶段和限制性能的因素,以及各种渲染算法的选择与应用。第三章则专注于性能测试与分析,包括测试工具的选择、常见性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )