高级数据分析:SparkSQL中的统计与聚合函数
发布时间: 2023-12-19 08:28:52 阅读量: 36 订阅数: 38 
# 第一章:SparkSQL简介
## 1.1 SparkSQL概述
## 1.2 SparkSQL的特点
## 1.3 SparkSQL与传统SQL的区别
### 第二章:SparkSQL中的数据统计
数据统计在数据分析中是非常重要的环节,通过对数据的统计可以更好地理解数据的特征和分布,为后续的决策和分析提供有效的支持。在SparkSQL中,我们可以使用各种数据统计函数来实现对数据的灵活统计分析,从而更好地理解数据的内在规律。
#### 2.1 数据统计的概念
数据统计是指对数据中的各种指标进行计算和分析,以便得出数据的规律和特征。数据统计可以包括对数据的总体描述、分布情况、集中趋势、离散程度等多个方面的分析。
#### 2.2 SparkSQL中的数据统计函数介绍
在SparkSQL中,提供了丰富的数据统计函数,包括但不限于count、sum、avg、max、min等常用的统计函数,通过这些函数可以方便地实现对数据的统计分析。
```python
# Python示例代码
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
# 初始化SparkSession
spark = SparkSession.builder.appName("data_statistic").getOrCreate()
# 读取数据源
data = spark.read.csv("data.csv", header=True, inferSchema=True)
# 对数据进行统计分析
data.select(count("id").alias("total_count"),
sum("amount").alias("total_amount"),
avg("amount").alias("average_amount"),
max("amount").alias("max_amount"),
min("amount").alias("min_amount")).show()
```
#### 2.3 实例演示:使用SparkSQL进行数据统计分析
接下来,我们通过一个实例演示来展示如何使用SparkSQL进行数据统计分析。假设我们有一份销售数据,包括订单编号、商品编号和销售金额等字段,我们将使用SparkSQL对该数据进行统计分析,得出总订单数、总销售额、平均销售额、最大销售额和最小销售额。
首先,我们通过SparkSQL读取数据,并使用数据统计函数进行分析:
```python
# Python示例代码
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
# 初始化SparkSession
spark = SparkSession.builder.appName("data_statistic").getOrCreate()
# 读取数据源
data = spark.read.csv("sales_data.csv", header=True, inferSchema=True)
# 对数据进行统计分析
data.select(count("order_id").alias("total_orders"),
sum("amount").alias("total_amount"),
avg("amount").alias("average_amount"),
max("amount").alias("max_amount"),
min("amount").alias("min_amount")).show()
```
### 第三章:SparkSQL中的数据聚合
#### 3.1 数据聚合的概念
在数据处理中,数据聚合是指将多条数据记录合并为少数几条,以便更好地理解数据、发现规律和提取信息。SparkSQL提供了丰富的聚合函数,可以对数据进行各种聚合操作,如求和、计数、平均值等。
#### 3.2 SparkSQL中的聚合函数详解
SparkSQL中的聚合函数包括但不限于:`sum`、`count`、`avg`、`max`、`min`等,这些函数可以在SQL语句或DataFrame的操作中灵活应用,实现对数据的快

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在介绍SparkSQL在ETL中的应用。文章从SparkSQL的简介与基本概念入手,详细解析了利用SparkSQL进行数据加载与保存的方法。接着深入探讨了DataFrame操作,以及如何使用SparkSQL进行数据清洗与转换。专栏进一步讲解了SparkSQL中的查询优化与窗口函数的有效应用。此外,还探讨了SparkSQL中的join操作与性能优化,并介绍了在金融领域中应用SparkSQL的实例。专栏还介绍了如何使用SparkSQL进行数据挖掘与机器学习,并探讨了数据结构化与模式推断的方法。最后,专栏分享了关于性能优化、数据可视化、统计与聚合函数的高级技巧,并介绍了如何部署与运维SparkSQL实时数据分析平台。此外,该专栏还提供了持久化与缓存优化、数据安全与隐私保护的最佳实践。通过本专栏的学习,读者可以全面了解SparkSQL在ETL中的应用,从而提升数据处理与分析的能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
93K缓存策略详解:内存管理与优化,提升性能的秘诀

# 摘要
93K缓存策略作为一种内存管理技术,对提升系统性能具有重要作用。本文首先介绍了93K缓存策略的基础知识和应用原理,阐述了缓存的作用、定义和内存层级结构。随后,文章聚焦于优化93K缓存策略以提升系统性能的实践,包括评估和监控93K缓存效果的工具和方法,以及不同环境下93K缓存的应用案例。最后,本文展望了93K缓存
Masm32与Windows API交互实战:打造个性化的图形界面
# 摘要
本文旨在介绍基于Masm32和Windows API的程序开发,从基础概念到环境搭建,再到程序设计与用户界面定制,最后通过综合案例分析展示了从理论到实践的完整开发过程。文章首先对Masm32环境进行安装和配置,并详细解释了Masm编译器及其他开发工具的使用方法。接着,介绍了Windows API的基础知识,包括API的分类、作用以及调用机制,并对关键的API函数进行了基础讲解。在图形用户界面(GUI)的实现章节中,本文深入
数学模型大揭秘:探索作物种植结构优化的深层原理
# 摘要
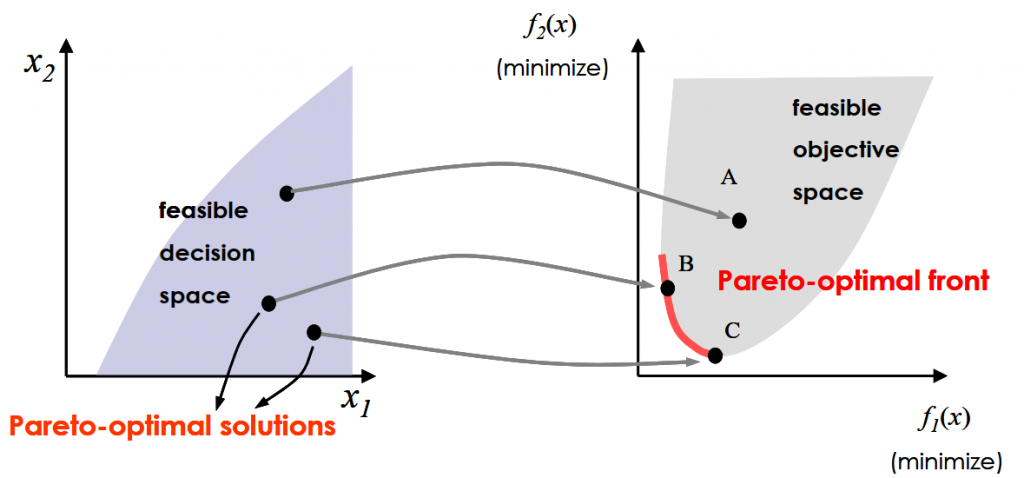
本文系统地探讨了作物种植结构优化的概念、理论基础以及优化算法的应用。首先,概述了作物种植结构优化的重要性及其数学模型的分类。接着,详细分析了作物生长模型的数学描述,包括生长速率与环境因素的关系,以及光合作用与生物量积累模型。本文还介绍了优化算法,包括传统算法和智能优化算法,以及它们在作物种植结构优化中的比较与选择。实践案例分析部分通过具体案例展示了如何建立优化模型,求解并分析结果。
S7-1200 1500 SCL指令性能优化:提升程序效率的5大策略

# 摘要
本论文深入探讨了S7-1200/1500系列PLC的SCL编程语言在性能优化方面的应用。首先概述了SCL指令性能优化的重要性,随后分析了影响SCL编程性能的基础因素,包括编程习惯、数据结构选择以及硬件配置的作用。接着,文章详细介绍了针对SCL代码的优化策略,如代码重构、内存管理和访问优化,以及数据结构和并行处理的结构优化。
泛微E9流程自定义功能扩展:满足企业特定需求

# 摘要
本文深入探讨了泛微E9平台的流程自定义功能及其重要性,重点阐述了流程自定义的理论基础、实践操作、功能扩展案例以及未来的发展展望。通过对流程自定义的概念、组件、设计与建模、配置与优化等方面的分析,本文揭示了流程自定义在提高企业工作效率、满足特定行业需求和促进流程自动化方面的重要作用。同时,本文提供了丰富的实践案例,演示了如何在泛微E9平台上配置流程、开发自定义节点、集成外部系统,
KST Ethernet KRL 22中文版:硬件安装全攻略,避免这些常见陷阱

# 摘要
本文详细介绍了KST Ethernet KRL 22中文版硬件的安装和配置流程,涵盖了从硬件概述到系统验证的每一个步骤。文章首先提供了硬件的详细概述,接着深入探讨了安装前的准备工作,包括系统检查、必需工具和配件的准备,以及
约束理论与实践:转化理论知识为实际应用
# 摘要
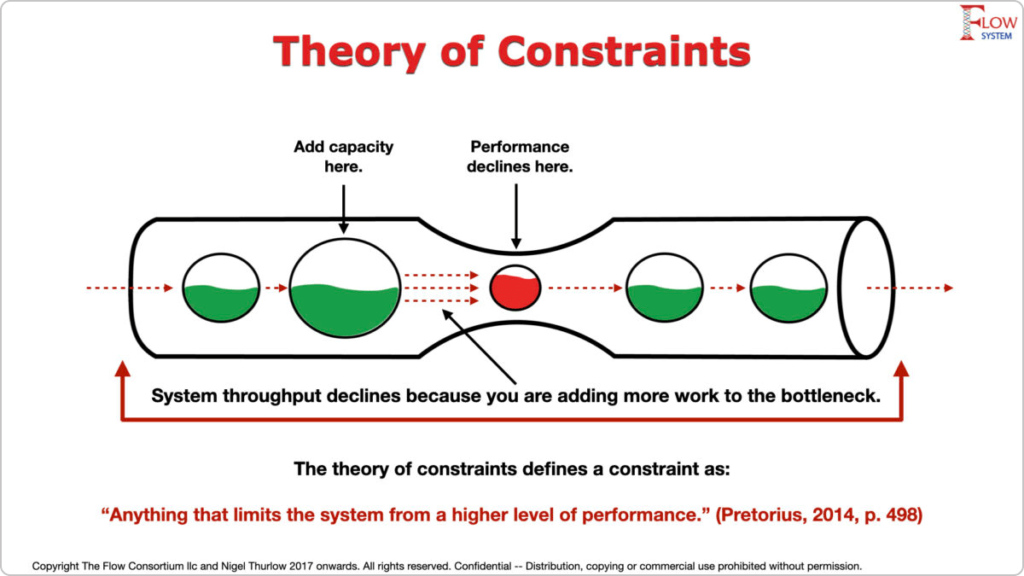
约束理论是一种系统性的管理原则,旨在通过识别和利用系统中的限制因素来提高生产效率和管理决策。本文全面概述了约束理论的基本概念、理论基础和模型构建方法。通过深入分析理论与实践的转化策略,探讨了约束理论在不同行业,如制造业和服务行业中应用的案例,揭示了其在实际操作中的有效性和潜在问题。最后,文章探讨了约束理论的优化与创新,以及其未来的发展趋势,旨在为理论研究和实际应用提供更广阔的
FANUC-0i-MC参数与伺服系统深度互动分析:实现最佳协同效果
# 摘要
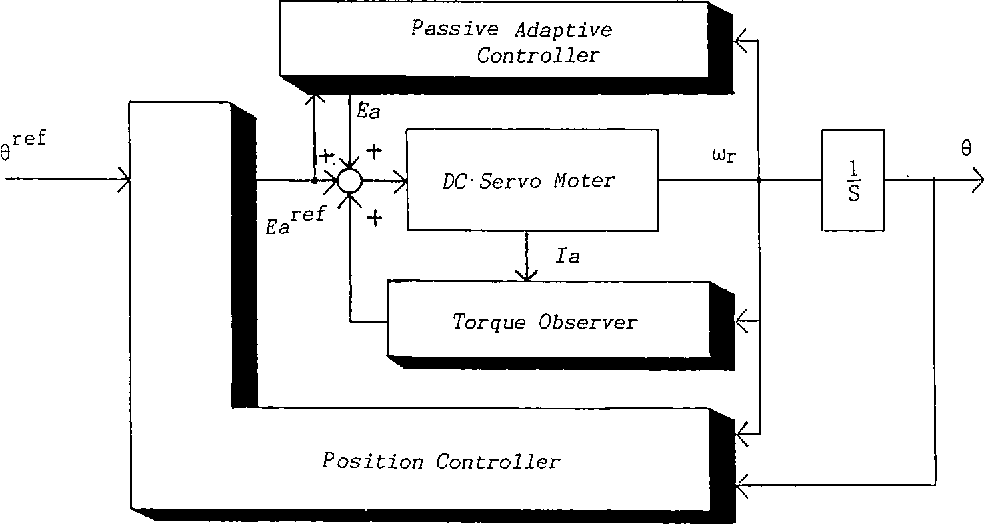
本文深入探讨了FANUC 0i-MC数控系统的参数配置及其在伺服系统中的应用。首先介绍了FANUC 0i-MC参数的基本概念和理论基础,阐述了参数如何影响伺服控制和机床的整体性能。随后,文章详述了伺服系统的结构、功能及调试方法,包括参数设定和故障诊断。在第三章中,重点分析了如何通过参数优化提升伺服性能,并讨论了伺服系统与机械结构的匹配问题。最后,本文着重于故障预防和维护策略,提
ABAP流水号安全性分析:避免重复与欺诈的策略
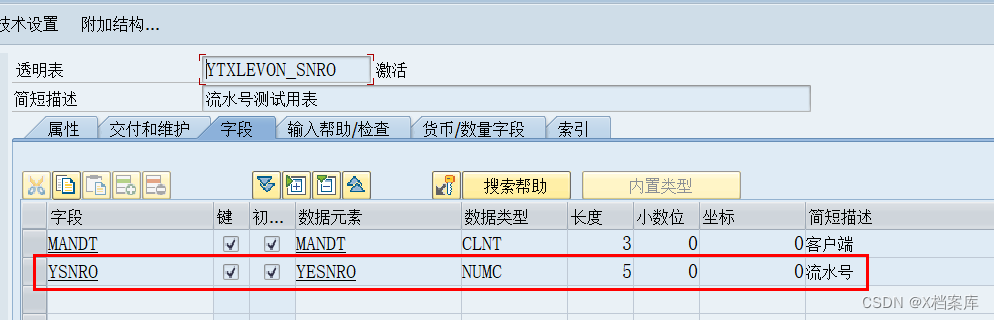
# 摘要
本文全面探讨了ABAP流水号的概述、生成机制、安全性实践技巧以及在ABAP环境下的安全性增强。通过分析流水号生成的基本原理与方法,本文强调了哈希与加密技术在保障流水号安全中的重要性,并详述了安全性考量因素及性能影响。同时,文中提供了避免重复流水号设计的策略、防范欺诈的流水号策略以及流水号安全的监控与分析方法。针对ABAP环境,本文论述了流水号生成的特殊性、集成安全机制的实现,以及安全问题的ABAP代
Windows服务器加密秘籍:避免陷阱,确保TLS 1.2的顺利部署
# 摘要
本文提供了在Windows服务器上配置TLS 1.2的全面指南,涵盖了从基本概念到实际部署和管理的各个方面。首先,文章介绍了TLS协议的基础知识和其在加密通信中的作用。其次,详细阐述了TLS版本的演进、加密过程以及重要的安全实践,这
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )