自定义你的ForkJoinTask:Java ForkJoinPool扩展框架详解
发布时间: 2024-10-22 08:28:23 阅读量: 1 订阅数: 3 
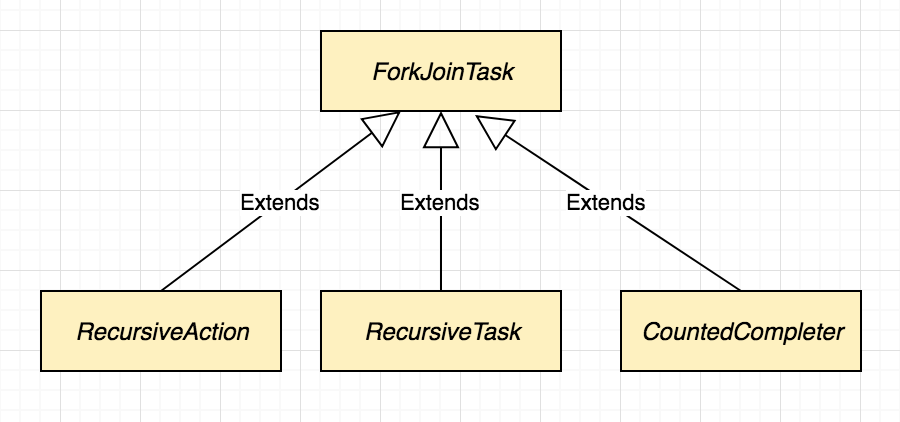
# 1. Java ForkJoinPool框架概述
Java ForkJoinPool框架是Java 7引入的一种特殊线程池,旨在有效利用多核处理器的计算资源。ForkJoinPool利用工作窃取算法,提高处理器的利用率,并处理递归任务分解后的子任务。
工作窃取算法是一种负载平衡技术,它允许空闲的线程从忙碌线程的待处理任务队列中窃取任务执行。这使得所有线程都能够持续工作,避免了闲置和资源浪费。
ForkJoinPool与传统线程池相比,主要的区别在于其对任务的管理方式和并行度的动态调整。它的设计特别适合于可以拆分为更小子任务的计算密集型任务,能够更好地处理因任务分解带来的大量子任务。
```java
// 示例代码:创建ForkJoinPool并执行任务
ForkJoinPool pool = new ForkJoinPool();
pool.execute(new ForkJoinTaskExample());
```
在上述代码中,我们创建了一个`ForkJoinPool`实例,并通过`execute`方法来提交一个实现了`ForkJoinTask`接口的实例。这是使用ForkJoinPool进行任务调度和执行的最简单方式。
通过本章的内容,读者将对ForkJoinPool框架有一个初步的理解,为后续章节中更深入的讨论打下坚实的基础。
# 2. 深入理解ForkJoinPool的工作原理
## 2.1 ForkJoinPool框架的理论基础
### 2.1.1 工作窃取算法的原理与优势
工作窃取算法是一种负载平衡技术,它被ForkJoinPool广泛采用。这种算法允许一个运行中的线程窃取其他线程队列中的任务来执行,目的是为了更高效地利用系统资源,减少线程的空闲时间。工作窃取算法的原理可以概括为以下几个步骤:
1. 每个线程都有一个任务队列,线程优先执行自己队列中的任务。
2. 当一个线程完成自己队列中的所有任务后,它会随机选择另一个线程的队列来窃取任务,窃取过程遵循FIFO原则。
3. 如果一个线程的队列中暂时没有任务可做,这个线程会处于闲置状态,等待其他线程的任务被窃取。
工作窃取算法的优势主要体现在以下几个方面:
- **提高资源利用率**:通过工作窃取,可以确保所有线程尽可能地忙碌,减少CPU空闲时间,提升了整体的计算资源利用率。
- **负载均衡**:即使在任务分配不均的情况下,工作窃取算法也能有效地平衡工作负载,减少因任务分配不均导致的性能瓶颈。
- **动态伸缩**:工作窃取算法对于动态变化的任务量有很好的适应性,能够自适应地调整线程的工作负载。
### 2.1.2 ForkJoinPool与传统线程池的对比
ForkJoinPool是Java并发包中的一个特殊线程池,专为解决可以递归拆分成更小任务的计算密集型任务而设计。与传统的线程池(如ExecutorService和ThreadPoolExecutor)相比,ForkJoinPool在处理具有高度并行性的任务时具有显著优势。
- **任务处理模型**:
- **ForkJoinPool**:使用“分而治之”的策略,任务可以递归地拆分为更小的任务,然后由线程池统一管理和执行。
- **传统线程池**:适合于处理不能分解为更小部分的独立任务,任务通常是并行执行,不会有递归分解的特性。
- **任务调度方式**:
- **ForkJoinPool**:采用工作窃取算法,空闲的线程会主动窃取其他线程的任务队列中的任务,保证了所有线程的高利用率。
- **传统线程池**:通常使用固定的工作队列和调度策略,当某些任务执行时间较长时,其他线程可能会出现空闲,造成资源浪费。
- **性能优化**:
- **ForkJoinPool**:由于支持工作窃取算法和递归任务分解,使得在并行计算时,能够实现更优的性能表现。
- **传统线程池**:性能优化主要依赖于合理配置线程数量和任务队列大小,但缺乏动态调整资源的能力。
接下来,我们将进一步探讨ForkJoinPool的内部实现机制,特别是它的结构组件以及任务如何被分解与合并。
## 2.2 ForkJoinPool的内部实现机制
### 2.2.1 ForkJoinPool的结构和组件
ForkJoinPool的内部结构非常精巧,它主要由以下几个关键组件构成:
- **任务队列**:每个工作线程都拥有一个双端队列(deque),用于存储待执行的任务。
- **工作线程**:ForkJoinPool会维护一个线程池,池中的线程称为ForkJoinWorkerThread,它们专门负责执行ForkJoinPool中的任务。
- **任务**:ForkJoinPool执行的任务需要继承RecursiveTask或RecursiveAction,这些任务被提交给线程池后会根据需要进行拆分。
ForkJoinPool的核心组件如下图所示:
```mermaid
graph TD
ForkJoinPool --> |维护| WorkQueue[工作队列]
ForkJoinPool --> |包含| ForkJoinWorkerThread[工作线程]
ForkJoinPool --> |执行| RecursiveTask[任务]
ForkJoinWorkerThread --> |拥有| WorkQueue
RecursiveTask --> |拆分| ForkJoinTask[可拆分的任务]
```
### 2.2.2 任务的分解与合并过程
ForkJoinPool中的任务分解与合并过程是ForkJoinPool得以高效执行的关键。任务的拆分过程通常是由用户实现的compute()方法来完成的。计算密集型任务通常继承自RecursiveTask,而无返回值的任务则继承自RecursiveAction。
1. **任务提交**:用户将任务提交到ForkJoinPool。
2. **任务执行**:ForkJoinPool中的线程(ForkJoinWorkerThread)开始执行任务。
3. **任务拆分**:
- 当任务足够大时,compute()方法会将任务拆分为更小的子任务。
- 每个子任务继续尝试拆分,直到任务小到可以被直接计算。
4. **任务执行与窃取**:
- 线程会优先执行自己任务队列中的任务。
- 如果线程任务队列为空,它会尝试从其他线程的队列尾部窃取任务。
5. **合并结果**:子任务完成计算后,其结果会被合并回上层任务中。
下面是一个简单的ForkJoinTask的实现代码示例:
```java
public class CountTask extends RecursiveTask<Integer> {
private final int threshold = 10000;
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
boolean canDivide = (end - start) < threshold;
if (canDivide) {
// 任务足够小,直接计算
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 拆分任务
int middle = start + (end - start) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
leftTask.fork(); // 异步执行
rightTask.fork(); // 异步执行
int leftResult = leftTask.join(); // 等待结果
int rightResult = rightTask.join(); // 等待结果
sum = leftResult + rightResult;
}
return sum;
}
}
```
代码逻辑说明:
- 在`compute()`方法中,我们首先判断当前任务的大小是否小于阈值。
- 如果任务足够小,则直接进行计算并返回结果。
- 否则,将任务拆分为两个子任务,并通过`fork()`方法将其异步提交给ForkJoinPool处理。
- 最后,通过`join()`方法等待子任务的完成,并将子任务的结果合并。
在本节中,我们了解了ForkJoinPool的基本结构与组件,以及任务如何通过递归拆分被高效处理。接下来,我们将探讨ForkJoinPool的配置与性能调优,以便让这个框架能更好地服务于不同的并发任务需求。
# 3. 自定义ForkJoinTask开发实践
## 3.1 创建自定义ForkJoinTask类
### 3.1.1 实现compute方法的设计要点
在ForkJoinPool框架中,自定义任务的创建是通过继承`ForkJoinTask`类并实现其`compute`方法来完成的。`compute`方法是ForkJoinTask的核心,它定义了任务的执行逻辑,包括任务如何被分解以及如何合并结果。
自定义`ForkJoinTask`时,首先需要确定任务的粒度。合理的任务划分对于提升线程池的效率至关重要。以下是一些设计`compute`方法时需要考虑的要点:
- **任务分解**:任务应当可以被有效分解为更小的子任务,子任务也应当能够独立完成。
- **递归或迭代**:实现任务分解时,通常采用递归方法来持续细分任务,直到满足某个最小粒度条件。
- **结果合并**:每个子任务的结果需要能够被合并回最终结果。这通常涉及到一些数据结构的合并或整合操作。
- **异常处理**:`compute`方法中应当处理可能的异常情况,以确保任务的健壮性。
- **性能考量**:任务分解与结果合并应当尽

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Go中间件CORS简化攻略:一文搞定跨域请求复杂性
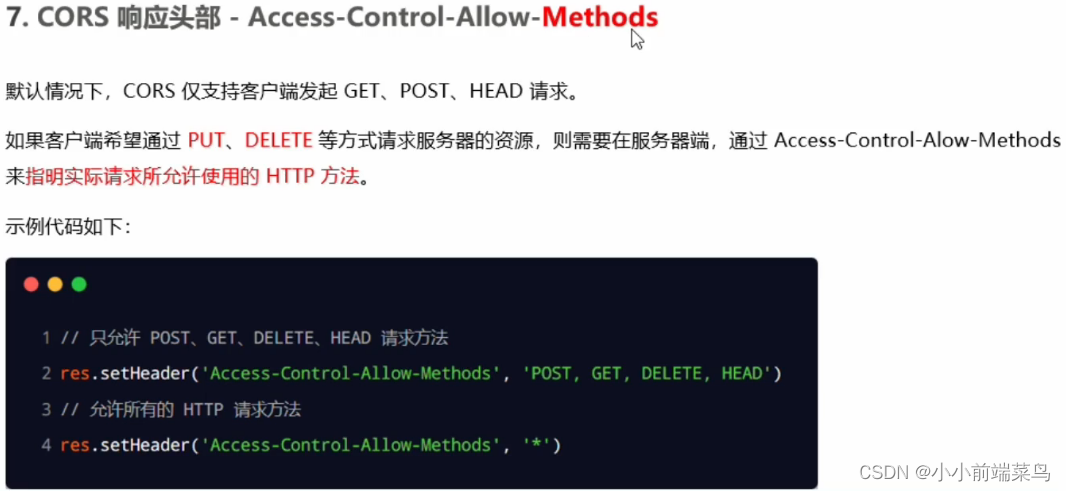
# 1. 跨域资源共享(CORS)概述
跨域资源共享(CORS)是Web开发中一个重要的概念,允许来自不同源的Web页面的资源共享。CORS提供了一种机制,通过在HTTP头中设置特定字段来实现跨域请求的控制。这一机制为开发者提供了灵活性,但同时也引入了安全挑战。本章将为读者提供CORS技术的概览,并阐明其在现代Web应用中的重要性。接下来,我们会深入探讨CORS的工作原理以及如何在实际的开发中运用这一技术
C++14 std::make_unique:智能指针的更好实践与内存管理优化

# 1. C++智能指针与内存管理基础
在现代C++编程中,智能指针已经成为了管理内存的首选方式,特别是当涉及到复杂的对象生命周期管理时。智能指针可以自动释放资源,减少内存泄漏的风险。C++标准库提供了几种类型的智能指针,最著名的包括`std::unique_ptr`, `std::shared_ptr`和`std::weak_ptr`。本章将重点介绍智能指针的基本概念,以及它
Go语言自定义错误类型与测试:编写覆盖错误处理的单元测试
# 1. Go语言错误处理基础
在Go语言中,错误处理是构建健壮应用程序的重要部分。本章将带你了解Go语言错误处理的核心概念,以及如何在日常开发中有效地使用错误。
## 错误处理理念
Go语言鼓励显式的错误处理方式,遵循“不要恐慌”的原则。当函数无法完成其预期工作时,它会返回一个错误值。通过检查这个
C++17模板变量革新:模板编程的未来已来
# 1. C++17模板变量的革新概述
C++17引入了模板变量,这是对C++模板系统的一次重大革新。模板变量的引入,不仅简化了模板编程,还提高了编译时的类型安全性,这为C++的模板世界带来了新的活力。
模板变量是一种在编译时就确定值的变量,它们可以是任意类型,并且可以像普通变量一样使用。与宏定义和枚举类型相比,模板变量提供了更强的类型检查和更好的代码可读性。
在这一章中,我们将首先回顾C++模板的历史和演进,然后详细介绍
【配置管理实用教程】:创建可重用配置模块的黄金法则
# 1. 配置管理的概念和重要性
在现代信息技术领域中,配置管理是保证系统稳定、高效运行的基石之一。它涉及到记录和控制IT资产,如硬件、软件组件、文档以及相关配置,确保在复杂的系统环境中,所有的变更都经过严格的审查和控制。配置管理不仅能够提高系统的可靠性,还能加快故障排查的过程,提高组织对变化的适应能力。随着企业IT基础设施的不断扩张,有效的配置管理已成为推动IT卓越运维的必要条件。接
C#日志记录经验分享:***中的挑战、经验和案例
# 1. C#日志记录的基本概念与必要性
在软件开发的世界里,日志记录是诊断和监控应用运行状况的关键组成部分。本章将带领您了解C#中的日志记录,探讨其重要性并揭示为什么开发者需要重视这一技术。
## 1.1 日志记录的基本概念
日志记录是一个记录软件运行信息的过程,目的是为了后续分析和调试。它记录了应用程序从启动到执行过程中发生的各种事件。C#中,通常会使用各种日志框架来实现这一功能,比如NLog、Log4Net和Serilog等。
## 1.2 日志记录的必要性
日志文件对于问题诊断至关重要。它们能够提供宝贵的洞察力,帮助开发者理解程序在生产环境中的表现。日志记录的必要性体现在以下
【掌握Criteria API动态投影】:灵活选择查询字段的技巧

# 1. Criteria API的基本概念与作用
## 1.1 概念介绍
Criteria API 是 Java Persistence API (JPA) 的一部分,它提供了一种类型安全的查询构造器,允许开发人员以面向对象的方式来编写数据库查询,而不是直接编写 SQL 语句。它的使用有助于保持代码的清晰性、可维护性,并且易于对数据库查询进行单
【Java Spring AOP必备攻略】:掌握面向切面编程,提升代码质量与维护性
# 1. Spring AOP核心概念解读
## 1.1 AOP简介
面向切面编程(Aspect-Oriented Programming,简称AOP),是作为面向对象编程(OOP)的补充而存在的一种编程范式。它主要用来解决系统中分布于不同模块的横切关注点(cross-cutting concerns),比如日志、安全、事务管理等。AOP通过提供一种新的模块化机制,允许开发者定义跨
***模型验证性能优化:掌握提高验证效率的先进方法
# 1. 模型验证性能优化概述
在当今快节奏的IT领域,模型验证性能优化是确保应用和服务质量的关键环节。有效的性能优化不仅能够提升用户体验,还可以大幅度降低运营成本。本章节将概述性能优化的必要性,并为读者提供一个清晰的优化框架。
## 1.1 优化的必要性
优化的必要性不仅仅体现在提升性能,更关乎于资源的有效利用和业务目标的实现。通过对现有流程和系统进行细致的性能分析,我
代码重构与设计模式:同步转异步的CompletableFuture实现技巧
# 1. 代码重构与设计模式基础
在当今快速发展的IT行业中,软件系统的维护和扩展成为一项挑战。通过代码重构,我们可以优化现有代码的结构而不改变其外部行为,为软件的可持续发展打下坚实基础。设计模式,作为软件工程中解决特定问题的模板,为代码重构提供了理论支撑和实践指南。
## 1.1 代码重构的重要性
重构代码是软件开发生命周期中不
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )