MLIR中的中间表示(IR)优化技术
发布时间: 2024-02-22 04:18:31 阅读量: 91 订阅数: 47 
# 1. MLIR简介
## 1.1 MLIR概述
MLIR(Multi-Language Intermediate Representation)是一种多语言中间表示,旨在解决不同编程语言和硬件架构之间的交互问题。它由谷歌开发,被设计为可扩展、灵活且面向未来的编译器基础设施。
## 1.2 MLIR的应用领域
MLIR的设计使其适用于各种应用领域,包括但不限于机器学习框架、图形编程、领域特定语言(DSLs)、GPU加速计算,等等。
## 1.3 MLIR与传统IR的对比
相较于传统的中间表示(IR),MLIR具有更高的灵活性和扩展性。它支持多种语言和硬件,同时能够有效地进行优化和转换。该特性使得MLIR在当今复杂的编译场景中具有更大的优势和适用性。
# 2. 中间表示(IR)在编译器中的作用
### 2.1 IR的定义和作用
中间表示(IR)是编译器中的一种数据结构,用于在不同阶段传递和优化程序代码。它承担着连接前端和后端的桥梁作用,可以帮助编译器在不同的优化阶段对程序进行分析和改进。
### 2.2 IR在编译器优化中的地位
在编译器优化中,IR起着至关重要的作用。它提供了一个抽象的、中立的视角,使得编译器能够在不同的优化阶段对程序进行操作,而无需考虑特定的编程语言。
### 2.3 中间表示的选择对优化的影响
不同的中间表示对编译器优化有着不同的影响。一些高级的IR可能更接近源代码,使得编译器可以利用更多的语义信息进行优化;而一些低级的IR可能更贴近机器代码,使得编译器可以更直接地进行机器指令级别的优化。因此,选择合适的IR形式对于编译器优化至关重要。
# 3. MLIR中的中间表示(IR)
在MLIR中,中间表示(IR)扮演着至关重要的角色,它是连接不同语言前端和优化后端的桥梁。MLIR的IR设计理念致力于提供一个灵活而高效的表示形式,以满足不同编程语言和优化需求的复杂性。
#### 3.1 MLIR IR的特点和设计理念
MLIR的IR设计具有以下几个显著特点:
- 多层级结构:MLIR的IR被设计为多层级结构,每个层级都有不同的抽象级别和表示能力,从而更好地适配不同的编程语言和优化场景。
- 弹性扩展:MLIR的IR支持灵活的扩展,用户可以定义新的操作和数据结构,以满足特定的需求,而不需要改变整体设计。
- 高度优化:MLIR的IR能够表达丰富的程序语义,从而为后续的编译优化提供更多的信息和可能性。
#### 3.2 MLIR IR的层级结构
MLIR的IR结构可以分为以下几个层级:
- **高层抽象表示**:包括Module、Function等级别的抽象表示,更接近源代码的语义结构。
- **中间层表示**:包括Control Flow Graph(CFG)、SSA形式等中间表示,用于进行高级优化和分析。
- **低层次表示**:包括LLVM IR、SPIR-V等底层表示,用于生成目标代码。
#### 3.3 不同层级的IR在编译优化中的作用
不同层级的IR在编译优化中起着不同的作用:
- **高层抽象表示**:提供了对程序语义的高级理解,可以进行高级优化,如函数内联、死代码消除等。
- **中间层表示**:用于进行更细粒度的优化,如循环优化、数据流分析等。
- **低层次表示**:包含了与具体硬件相关的细节信息,可以进行针对性的底层优化,如寄存器分配、指令调度等。
通过多层级的IR设计,MLIR能够有效地结合不同级别的优化手段,实现对复杂程序的全面优化。
# 4. MLIR中的中间表示(IR)优化技术
在MLIR中,中间表示(IR)的优化技术是非常重要的,它可以帮助编译器生成更高效的目标代码。下面将介绍MLIR中的一些常见的IR优化技术。
### 4.1 基本块优化
在MLIR中,基本块是一组按顺序执行的指令集合,而基本块优化技术则旨在对基本块内的指令进行精细化的优化,以提高代码的执行效率。这包括常见的指令删除、无用代码消除、常量传播等优化手段。下面是一个简单的基本块优化示例:
```python
# 示例代码
def optimize_basic_block(basic_block):
# 删除无用指令
for instr in basic_block:
if is_unused(instr):
remove_instruction(instr)
# 常量传播优化
propagate_constants(basic_block)
```
在示例中,我们展示了如何对一个基本块进行优化,通过删除无用指令和进行常量传播,来提高基本块的执行效率。
### 4.2 数据流分析与优化
数据流分析是指对程序中数据流动进行分析,以便发现代码中的优化机会,包括数据依赖关系、可达性分析、活跃变量分析等。在MLIR中,数据流分析与优化是编译器优化中的重要手段,可以帮助发现潜在的性能瓶颈并进行针对性的优化。
```java
// 示例代码
public void performDataFlowAnalysis(Function function) {
DataFlowAnalyzer analyzer = new DataFlowAnalyzer(function);
analyzer.analyzeDataFlow();
// 进行优化操作
analyzer.applyOptimizations();
}
```
上述示例展示了如何在一个函数中进行数据流分析,并根据分析结果进行优化操作。
### 4.3 循环优化技术
循环是程序中常见的结构,循环的优化对于提高程序性能非常重要。在MLIR中,循环优化技术可以通过展开循环、向量化、循环并行化等手段来优化循环结构,以提高程序的并行性和效率。
```go
// 示例代码
func applyLoopOptimizations(loop Loop) {
unrollLoop(loop) // 循环展开
vectorizeLoop(loop) // 向量化循环
parallelizeLoop(loop) // 并行化循环
}
```
上述示例展示了如何对一个循环应用优化技术,包括循环展开、向量化和并行化操作。
通过以上示例,我们可以看到在MLIR中,针对中间表示(IR)的优化技术包括基本块优化、数据流分析与优化以及循环优化技术,这些技术可以帮助编译器生成更高效的目标代码,从而提高程序的性能。
# 5. MLIR中的IR优化工具与框架
在MLIR中,IR优化是编译器优化的一个核心环节,而IR优化工具与框架则是支撑这一环节的重要组成部分。下面我们将详细探讨MLIR中的IR优化工具与框架的相关内容。
### 5.1 利用现有工具进行IR优化
在MLIR中,可以利用许多已有的工具来进行IR优化,比如常见的数据流分析工具、常量折叠工具等。通过整合这些工具,可以提高编译器优化的效率和准确性,进而改善代码的性能和可读性。
以下是一个简单的示例,展示如何使用现有的数据流分析工具在MLIR中进行IR优化:
```python
# 导入MLIR库中的数据流分析工具
from mlir.optimization import DataFlowAnalysis
# 创建一个MLIR模块
module = Module()
# 对该模块进行数据流分析
dataflow_analysis = DataFlowAnalysis(module)
dataflow_analysis.run()
# 打印数据流分析的结果
dataflow_analysis.print_results()
```
在上述代码中,我们通过导入MLIR库中的数据流分析工具,对一个MLIR模块进行了数据流分析,并打印了分析结果。
### 5.2 MLIR提供的IR优化工具
除了利用现有工具外,MLIR本身也提供了许多IR优化工具,这些工具基于MLIR的特性和设计理念,能够更好地与MLIR的中间表示进行交互和优化。
MLIR提供了丰富的IR优化工具,如常量传播优化、死代码消除、循环展开等。这些工具可以帮助开发者更好地优化和改进他们的代码。
下面是一个简单的示例,展示如何在MLIR中使用常量传播优化工具:
```python
# 导入MLIR库中的常量传播优化工具
from mlir.optimization import ConstantPropagation
# 创建一个MLIR函数
func = Function()
# 对该函数进行常量传播优化
const_propagation = ConstantPropagation(func)
const_propagation.run()
# 输出优化后的函数
print(func)
```
在上述代码中,我们通过导入MLIR库中的常量传播优化工具,对一个MLIR函数进行常量传播优化,并输出优化后的函数。
### 5.3 IR优化框架的设计和实现
为了更好地支持IR优化工具的开发和整合,MLIR提供了IR优化框架。这个框架包括了优化工具的注册、调度和执行等功能,使得开发者可以方便地编写和管理自定义的IR优化工具。
通过IR优化框架,开发者可以更加灵活地实现各种类型的优化,加快编译器优化的迭代速度,提高代码的质量和性能。
```python
# 伪代码示例:IR优化框架的设计和实现
class IROptimizationFramework:
def __init__(self):
self.optimization_passes = []
def register_optimization_pass(self, pass):
self.optimization_passes.append(pass)
def run_optimizations(self, module):
for pass in self.optimization_passes:
pass.run(module)
```
上述伪代码展示了一个简单的IR优化框架的设计和实现,通过注册和执行优化 passes,可以对一个IR模块进行一系列的优化操作。
总的来说,MLIR提供了丰富的IR优化工具与框架,帮助开发者优化他们的代码并提高编译器的性能和效率。
# 6. 未来发展与展望
MLIR作为一个全新的IR优化框架,正在逐渐展现出其强大的潜力和应用价值。在未来,我们可以期待MLIR在IR优化领域取得更大的突破,并为整个编译器技术的发展带来新的活力。
#### 6.1 MLIR在IR优化领域的前景
随着MLIR的不断发展和完善,可以预见其在IR优化领域将发挥越来越重要的作用。MLIR的灵活性和可扩展性使得它可以适用于各种不同的编程语言和领域,为IR优化提供更广阔的空间。未来,MLIR有望成为各类编译器领域的事实标准,为编译器技术的发展提供强有力的支持。
#### 6.2 面向未来的发展方向
在未来的发展中,可以预见MLIR将会不断扩展其应用范围,涉及越来越多的编程语言和编译器领域。同时,MLIR有望进一步完善其优化技术,提高编译器的性能和效率。另外,随着人工智能和机器学习领域的发展,MLIR可能会在这些领域发挥更加重要的作用,为AI应用提供更好的编译器支持。
#### 6.3 MLIR为IR优化技术带来的影响
MLIR的出现为IR优化技术带来了全新的思路和方法。其丰富的中间表示层级结构和灵活的优化工具使得IR优化变得更加高效和可控。通过整合不同层级的IR和优化技术,可以实现更加细粒度和有效的编译器优化,从而提升程序的性能和质量。MLIR的影响将不仅仅局限于IR优化领域,还将推动编译器技术的发展,为软件开发提供更加强大的工具和支持。
未来,随着MLIR的不断完善和发展,相信它将在IR优化领域展现出更加耀眼的光芒,为整个编译器技术的发展带来新的契机和挑战。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
MLIR编译基础设施专栏深入探讨了现代编译器中关键的MLIR(多层次中间表示语言)技术。专栏内容包括MLIR中的Dialects与Operations定义,解析了MLIR中的Module、Region与Block详解,深入探讨了MLIR中的中间表示(IR)优化技术,并介绍了MLIR中的Pass管理器及Pass设计原则。此外,专栏涵盖了MLIR中的代码生成技术,静态单走定义(SSA)形式介绍,模块化设计与扩展性分析,以及数据依赖分析与优化。同时,还探讨了MLIR中的缓存优化与压缩技术,并行化与并发编程实现,以及多核与GPU加速应用。最后,专栏还引入了MLIR中的异构计算与协处理器利用。通过本专栏,读者将获得全面了解MLIR编译基础设施的知识,以及应用这些知识进行高效编译的方法和技巧。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电流互感模块尺寸与安装:最佳实践与空间考量
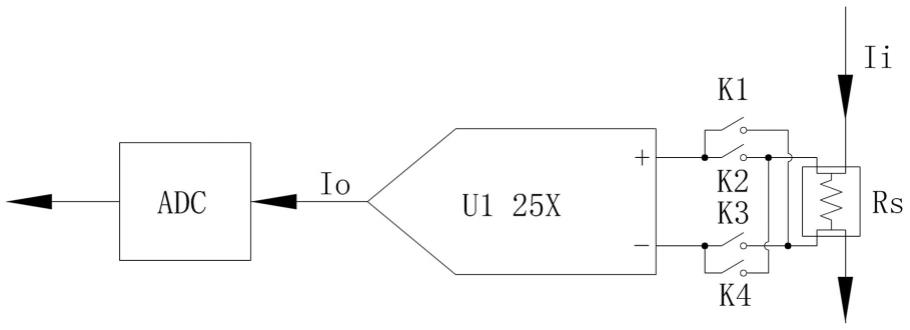
参考资源链接:[ZMCT103B/C型电流互感器使用指南:体积小巧,精度高](https://wenku.csdn.net/doc/647065ca543f844488e465a1?spm=1055.2635.3001.10343)
# 1. 电流互感模块概述与分类
电流互感模块,作为电力系统中不可或缺的一部分,负责将高电流转换为安全的低电流信号,以便于监测和控制电力设备。互感模块的分类主要基于其设计原理和应用场景,其中包括传统的电磁式互感器和现代的电子式互感器
MPE720软件交互设计:用户界面定制与数据库数据整合策略

参考资源链接:[MPE720Ver.7软件操作与系统集成指南](https://wenku.csdn.net/doc/6412b4a0be7fbd1778d403e8?spm=1055.2635.3001.10343)
# 1. MPE720软件概述与交互设计基础
## MPE720软件概述
MPE720软件是一
【电力电子装置】:PSCAD在电力电子仿真中的应用

参考资源链接:[PSCAD简明使用指南:从基础到高级操作](https://wenku.csdn.net/doc/64ae169d2d07955edb6aa14e?spm=1055.2635.3001.10343)
# 1. PSCAD简介及其在电力系统中的作用
## 1.1 PSCAD的基本概念
PSCAD(Power System Computer Aided Design)是一款专注于电力系统仿真软件,它利用图形化界面允许工程师
【调试技巧大公开】:Chrome 109,高效定位问题的秘诀

参考资源链接:[谷歌浏览器Chrome 109.0.5414.120 x64版发布](https://wenku.csdn.net/doc/5f4a
【接口适配突破】:GD32到STM32迁移中的I2C与SPI接口挑战

参考资源链接:[GD32与STM32兼容性对比及移植指南](https://wenku.csdn.net/doc/6401ad18cce7214c316ee469?spm=1055.2635.3001.10343)
# 1. 接口适配与微控制器迁移概述
在当今快速发展的信
【跨文化写作之道】:撰写面向国际读者的IEEE论文技巧
参考资源链接:[使用Microsoft Word撰写IEEE论文的官方模板](https://wenku.csdn.net/doc/6412b587be7fbd1778d437a6?spm=1055.2635.3001.10343)
# 1. 跨文化写作的重要性
在全球化的今天,跨文化写作已经成为IT专业领域内不可或缺的一部分。随着技术的不断发展和国际合作的日益频繁,IT专业人士需要通过写作向不同文化背景的读者传达信息、分享知识与研究成
CPCL打印脚本维护更新:系统稳定性关键操作
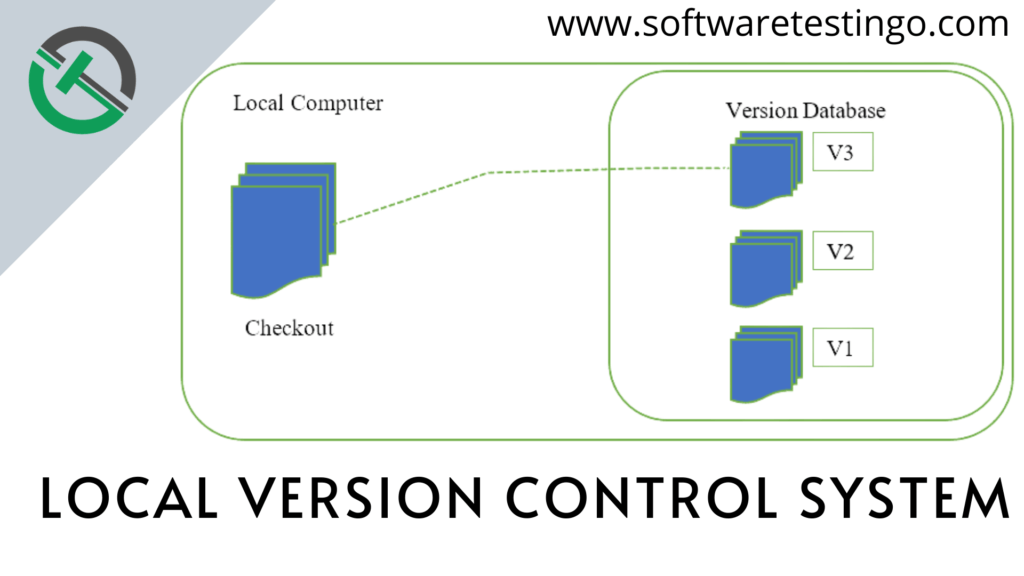
参考资源链接:[CPCL指令手册:便携式标签打印机编程宝典](https://wenku.csdn.net/doc/6401abbfcce7214c316e95a8?spm=1055.2635.3001.10343)
# 1. CPCL打印脚本概述
## 1.1 CPCL打印脚本简介
CPCL(Common Printing Comma
Simulink在控制系统中的应用:5步骤探索控制系统的建模与仿真
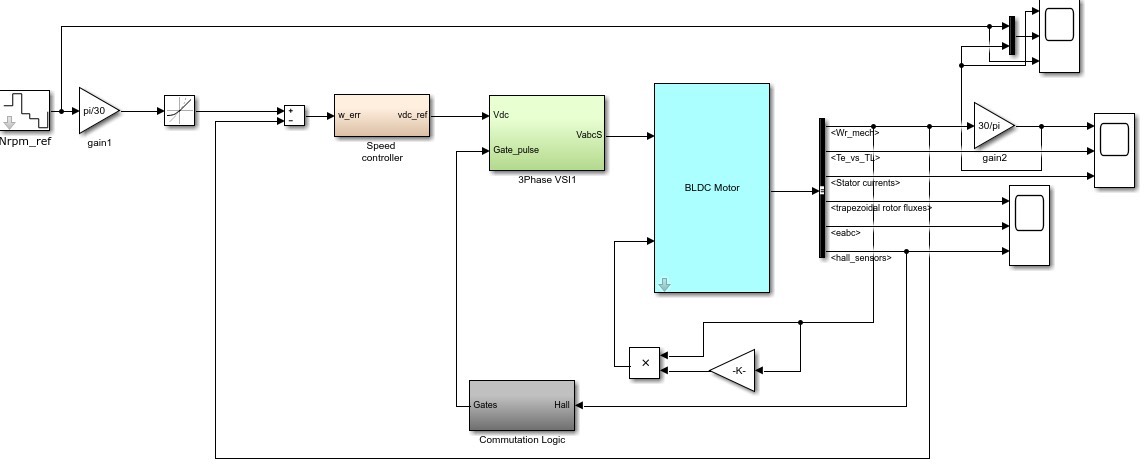
参考资源链接:[simulink模块库中文.pdf](https://wenku.csdn.net/doc/6412b488be7fbd1778d3feaf?spm=1055.2635.3001.10343)
# 1. Simulink概述与控制系统基础
## 1.1 Simulink简介
Simulink 是 MathWorks 公司推出的基于 MATLAB
ISO-2859-1抽样表解读:中文版必备知识与实际案例
参考资源链接:[ISO2859-1标准解读:属性检验与AQL抽样规则](https://wenku.csdn.net/doc/2v0ix307mq?spm=1055.2635.3001.10343)
# 1. ISO-2859-1抽样表概述
ISO-2859-1抽样表是国际标准化组织发布的一种统计抽样标准,广泛应用于制造业和供应链管理中的质量控制过程。该标准为确保产品和过程质量提供了可信赖的抽样计划和操作指南。ISO-2859-1抽样表的目的在于通过少量样本的检验来做出关于整体质量的判断,从而优化检验资源的分配,减少不必要的全量检验。下一章节将探讨这一抽样计划的理论基础,为读者深入理解ISO
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )