实现简单的HTTP请求处理与响应
发布时间: 2023-12-18 14:20:51 阅读量: 48 订阅数: 23 

一个Http请求处理工具
## 1. 介绍HTTP协议
### 1.1 HTTP协议概述
HTTP(HyperText Transfer Protocol)是一种基于客户端-服务器模型的协议,用于在Web上进行数据交互。它是一种无状态的协议,即每个请求和响应之间没有持久的连接。HTTP协议使用TCP作为传输层的协议,通过在应用层和传输层之间进行通信来传输数据。
HTTP协议的作用是允许客户端向服务器请求数据,并且服务器可以向客户端发送响应数据。客户端发送HTTP请求到服务器的URL进行通信,并通过HTTP协议来传输和接收数据。
### 1.2 请求报文与响应报文结构
HTTP请求报文由请求行、请求头部和请求主体三部分组成。请求行包括请求方法、URL和协议版本。请求头部包含了一些用于描述请求的信息,比如用户代理、Cookie等。请求主体中包含了实际要发送给服务器的数据。
下面是一个示例的HTTP请求报文:
```http
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36
Accept-Language: en-US,en;q=0.9
```
HTTP响应报文由状态行、响应头部和响应主体三部分组成。状态行包括协议版本、状态码和状态消息。响应头部包含了一些用于描述响应的信息,比如日期、服务器、Content-Type等。响应主体中包含了服务器返回的实际数据。
下面是一个示例的HTTP响应报文:
```http
HTTP/1.1 200 OK
Date: Wed, 30 Dec 2020 10:30:00 GMT
Server: Apache/2.4.18 (Ubuntu)
Content-Type: text/html; charset=UTF-8
Content-Length: 2345
<!DOCTYPE html>
<html>
<head>
<title>Welcome to Example.com</title>
</head>
<body>
<h1>Hello, World!</h1>
</body>
</html>
```
## 2. HTTP请求处理
在HTTP协议中,客户端向服务器发送请求,服务器则根据请求进行相应处理并返回响应。本章节将详细介绍HTTP请求的处理流程以及相关细节。
### 2.1 HTTP请求方法
HTTP定义了多种请求方法,用于表示对资源的不同操作类型。常用的请求方法包括:
- GET:获取资源
- POST:提交数据,创建资源
- PUT:更新资源
- DELETE:删除资源
- HEAD:获取资源的元数据,不返回主体
- OPTIONS:获取服务器支持的请求方法
- PATCH:对资源进行局部更新
- TRACE:追踪请求的传输路径
以下是基于Python的示例代码,演示了如何使用`http.client`模块发送GET和POST请求:
```python
import http.client
# 发送GET请求
conn = http.client.HTTPSConnection("www.example.com")
conn.request("GET", "/")
response = conn.getresponse()
print(response.status, response.reason)
data = response.read()
print(data.decode())
# 发送POST请求
conn = http.client.HTTPSConnection("www.example.com")
headers = {"Content-Type": "application/x-www-form-urlencoded"}
conn.request("POST", "/", "param1=value1¶m2=value2", headers)
response = conn.getresponse()
print(response.status, response.reason)
data = response.read()
print(data.decode())
```
代码总结:
- 通过`http.client.HTTPSConnection`创建HTTP连接
- 使用`.request`方法发送请求,参数包括请求方法、路径、请求体和请求头部(POST请求需要指定`Content-Type`)
- 通过`.getresponse`获取服务器响应
- 可以通过`.status`和`.reason`获取响应的状态码和状态消息
- 通过`.read`读取响应主体数据
结果说明:
- 响应状态码和状态消息可用于判断请求是否成功
- 使用`.decode()`将响应数据从字节流转换为字符串
### 2.2 URL解析与路径匹配
在HTTP请求中,URL用于标识资源的位置。对于服务器端来说,需要解析URL并根据路径决定如何处理请求。
以下是基于Python的示例代码,演示了如何使用`urllib.parse`模块解析URL和`http.server`模块匹配路径:
```python
from urllib.parse import urlparse
from http.server import BaseHTTPRequestHandler
def handle_path(path):
if path == "/":
return "Hello, World!"
elif path == "/about":
return "About Us"
else:
return "404 Not Found"
url = "http://www.example.com/about"
parsed_url = urlparse(url)
path = parsed_url.path
response = handle_path(path)
print(response)
```
代码总结:
- 使用`urlparse`函数解析URL,获取路径信息
- 自定义处理函数`handle_path`根据路径返回相应的内容
- 使用`http.server.BaseHTTPRequestHandler`类处理路径匹配,这是一个简化的HTTP服务器示例
- 调用`handle_path`函数传入解析后的路径,获取相应的内容并打印
结果说明:
- 根据解析后的路径进行路径匹配,返回相应的内容
### 2.3 请求头部解析与处理
HTTP请求通常包含头部信息,用于传递请求的元数据。服务器端需要解析请求头部并根据其中的信息进行相应的处理。
以下是基于Python的示例代码,演示了如何使用`http.server`模块解析和处理请求头部:
```python
from http.server import BaseHTTPRequestHandler
class MyHandler(BaseHTTPRequestHandler):
def do_GET(self):
content_type = self.headers.get("Content-Type")
if content_type == "text/plain":
self.send_response(200)
self.send_header("Content-Type", "text/plain")
self.end_headers()
self.wfile.write(b"Hello, World!")
else:
self.send_response(415)
self.send_header("Content-Type", "text/plain")
self.end_headers()
self.wfile.write(b"Unsupported Media Type")
# ... 其他HTTP方法的处理函数 ...
# 启动HTTP服务器
addr = ("", 8000)
httpd = HTTPServer(addr, MyHandler)
httpd.serve_forever()
```
代码总结:
- 自定义一个继承自`http.server.BaseHTTPRequestHandler`的处理类
- 重写对应HTTP方法的处理函数,如`do_GET`处理GET请求
- 使用`self.headers.get`获取请求头部的值
- 使用`self.send_response`、`self.send_header`和`self.end_headers`发送响应头部
- 使用`self.wfile.write`发送响应主体数据
结果说明:
- 根据请求头部的`Content-Type`进行条件判断,返回不同的响应结果
### 3. HTTP响应处理
HTTP响应处理是指服务器接收到客户端发出的HTTP请求后,根据请求的内容进行处理并返回相应的响应。本章将介绍HTTP响应的处理过程及相关概念。
#### 3.1 响应状态码与状态消息
在HTTP响应中,状态码用于表示服务器对请求的处理结果。状态码分为5个分类,分别以不同的首位数字来表示,常见的状态码有:
- 1xx(信息类):表示服务器已经接收到请求,正在处理中;
- 2xx(成功类):表示服务器成功处理请求;
- 3xx(重定向类):表示请求需要进一步的操作以完成;
- 4xx(客户端错误类):表示客户端发出的请求有误;
- 5xx(服务器错误类):表示服务器在处理请求时发生了错误。
状态码与状态消息的对应关系可以在HTTP协议中找到,如200对应"OK",404对应"Not Found"等。
#### 3.2 响应头部的组织与发送
在HTTP响应中,除了状态码和状态消息之外,还包括了一系列的响应头部信息。响应头部信息通过键值对的形式组织,常见的响应头部有:
- Content-Type:指定了响应主体的数据类型;
- Content-Length:指定了响应主体的长度;
- Set-Cookie:设置Cookie值,用于跟踪会话状态等;
- Cache-Control:指定了缓存策略。
服务器在接收到请求后,根据具体情况进行响应头部信息的设置,然后将响应头部信息与响应内容一起发送给客户端。
以下是一个使用Java代码实现的示例,展示了如何设置响应头部信息并发送响应:
```java
import java.io.IOException;
import java.io.OutputStream;
import java.net.Socket;
public class HttpResponseSender {
public static void sendResponse(Socket socket, String content) throws IOException {
String responseBody = content;
String contentType = "text/plain";
int contentLength = responseBody.getBytes().length;
OutputStream outputStream = socket.getOutputStream();
outputStream.write("HTTP/1.1 200 OK\r\n".getBytes());
outputStream.write(("Content-Type: " + contentType + "\r\n").getBytes());
outputStream.write(("Content-Length: " + contentLength + "\r\n").getBytes());
outputStream.write("\r\n".getBytes());
outputStream.write(responseBody.getBytes());
outputStream.flush();
}
}
```
在上述代码中,我们使用`OutputStream`将响应头部信息和响应内容依次写入输出流中,然后通过`flush()`方法将数据发送给客户端。
#### 3.3 响应主体的处理与发送
HTTP响应的主体部分是可选的,根据请求的具体内容和服务器的处理逻辑可能存在或者不存在。如果存在响应主体,服务器需要根据请求的要求生成相应的内容,并将内容发送给客户端。
以下是一个使用Python代码实现的示例,展示了如何处理并发送带有响应主体的HTTP响应:
```python
import socket
def send_response(client_socket, response_body):
response_status = "HTTP/1.1 200 OK\r\n"
response_headers = "Content-Type: text/html\r\n"
response = response_status + response_headers + "\r\n" + response_body
client_socket.sendall(response.encode())
def handle_request(client_socket):
request_data = client_socket.recv(1024).decode()
# 解析请求数据,处理请求逻辑并生成响应主体内容
response_body = "<html><body><h1>Hello, World!</h1></body></html>"
send_response(client_socket, response_body)
client_socket.close()
if __name__ == "__main__":
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(("localhost", 8000))
server_socket.listen(1)
while True:
client_socket, _ = server_socket.accept()
handle_request(client_socket)
```
在上述代码中,我们使用`socket`模块创建一个基本的HTTP服务器,当服务器接收到客户端的请求后,会调用`handle_request()`方法处理请求逻辑,并根据请求逻辑生成响应主体内容。然后使用`send_response()`方法将响应主体发送给客户端。
以上就是HTTP响应处理的主要内容,包括了响应状态码与状态消息的处理,响应头部信息的组织与发送,以及响应主体的处理与发送。在实际应用中,需根据具体需求来设计和实现相应的处理逻辑。
### 4. HTTP连接管理
HTTP连接管理是指在客户端和服务器之间建立、维护和关闭连接的过程,其有效管理可以提高网络通信的效率和性能。
#### 4.1 HTTP持久连接与非持久连接
HTTP/1.0版本默认使用非持久连接,即每次请求都需要建立新的TCP连接,完成请求后立即关闭连接。这种方式会增加连接建立和关闭的开销,降低性能。
HTTP/1.1引入了持久连接,即在单个TCP连接上可以传输多个HTTP请求及响应,减少了连接建立和关闭的次数,提高了性能。
以下是Java代码示例,演示了如何使用HttpURLConnection实现HTTP持久连接:
```java
import java.net.HttpURLConnection;
import java.net.URL;
public class HttpPersistentConnectionExample {
public static void main(String[] args) {
try {
URL url = new URL("http://example.com/api");
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
// 开启持久连接
connection.setRequestProperty("Connection", "keep-alive");
// 发送GET请求
connection.setRequestMethod("GET");
// 读取响应
int responseCode = connection.getResponseCode();
System.out.println("Response Code: " + responseCode);
// 关闭连接
connection.disconnect();
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
代码总结:上述代码通过设置Connection请求头来开启持久连接,发送GET请求后读取响应并关闭连接。
结果说明:运行示例代码后,可以看到输出的响应码,证明持久连接已经建立并成功发送了请求。
#### 4.2 连接池的使用与管理
连接池是一种重用HTTP连接的技术,通过维护一定数量的连接,可以减少连接的创建和销毁开销,提高性能。
以下是Python代码示例,演示了如何使用requests库实现HTTP连接池的管理:
```python
import requests
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
# 创建一个TCP连接池
adapter = HTTPAdapter(max_retries=3, pool_connections=5, pool_maxsize=10, pool_block=True)
session = requests.Session()
session.mount('http://', adapter)
# 发送多个请求
for _ in range(10):
response = session.get("http://example.com/api")
print("Status code: " + str(response.status_code))
```
代码总结:上述代码通过配置HTTPAdapter和Session来管理连接池,实现了多个请求共享和重复使用连接。
结果说明:运行示例代码后,可以看到10次请求的状态码,证明连接池有效地重用了HTTP连接。
#### 4.3 并发请求的处理与优化
在实际场景中,需要处理大量并发的HTTP请求,为了提高性能和效率,可以采取一些优化措施,如多线程、异步请求等。
以下是Go语言代码示例,演示了如何使用goroutine实现并发HTTP请求的处理与优化:
```go
package main
import (
"fmt"
"net/http"
"sync"
)
func main() {
var wg sync.WaitGroup
urls := []string{"http://example.com/api1", "http://example.com/api2", "http://example.com/api3"}
for _, url := range urls {
wg.Add(1)
go func(u string) {
defer wg.Done()
resp, err := http.Get(u)
if err != nil {
fmt.Println("Error:", err)
return
}
defer resp.Body.Close()
fmt.Printf("URL: %s, Status code: %d\n", u, resp.StatusCode)
}(url)
}
wg.Wait()
}
```
代码总结:上述代码使用goroutine并发处理多个HTTP请求,通过WaitGroup等待所有请求完成后再退出。
结果说明:运行示例代码后,可以看到每个请求的状态码和URL,证明成功并发处理了多个HTTP请求。
## 5. 错误处理与异常情况
在HTTP请求过程中,常常会遇到各种错误情况和异常情况,包括客户端请求错误、服务器内部错误等。正确处理这些错误情况对于保障系统的稳定性和安全性至关重要。本章将介绍常见的HTTP错误状态码、异常请求的处理与重试机制,以及如何处理服务器错误并记录日志。
### 常见的HTTP错误状态码
在HTTP协议中,状态码用于指示特定的请求状态。常见的状态码包括:
- 200 OK:请求成功
- 4xx:客户端错误,如 400 Bad Request(请求无效)、401 Unauthorized(未授权)、403 Forbidden(被拒绝访问)、404 Not Found(未找到资源)等
- 5xx:服务器错误,如 500 Internal Server Error(服务器内部错误)、502 Bad Gateway(网关错误)、503 Service Unavailable(服务不可用)等
针对不同的状态码,我们需要采取不同的处理措施,例如进行重试、返回友好的错误信息给用户,或者记录错误日志以便排查问题。
### 异常请求的处理与重试机制
对于有些异常请求,我们可能需要进行重试以确保请求能够成功完成。这种情况下,需要结合自身业务场景和实际需求来设计合理的重试机制,可以根据不同的错误状态码设置不同的重试策略,如指数退避算法等。以下是Python中实现简单重试机制的示例代码:
```python
import requests
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
# 设置重试次数为3次
retry_strategy = Retry(
total=3,
status_forcelist=[500, 502, 503, 504],
method_whitelist=["GET"]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
http = requests.Session()
http.mount("https://", adapter)
http.mount("http://", adapter)
response = http.get('http://example.com/api')
```
上述代码中,我们利用了Python中的 `requests` 库,通过自定义重试策略来处理特定的错误状态码,达到了简单的重试机制。
### 服务器错误的处理与日志记录
当服务器发生错误时,我们需要及时记录错误日志,以便后续排查问题。可以采用日志记录工具或框架,将错误信息按照一定的格式记录到日志文件或日志系统中。以下是Java中使用Log4j2记录错误日志的示例代码:
```java
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class MyClass {
private static final Logger logger = LogManager.getLogger(MyClass.class);
public void doSomething() {
try {
// 执行业务逻辑
} catch (Exception e) {
logger.error("发生错误:", e);
}
}
}
```
通过以上代码,我们利用了Log4j2记录了发生错误时的异常信息,可以及时排查问题并进行处理。
## 6. 安全与认证
在网络通信中,安全和认证是非常重要的问题。HTTP协议提供了几种安全和认证的机制,本章将介绍其中的一些常见技术。
### 6.1 HTTP基本认证与摘要认证
HTTP基本认证和摘要认证是两种常见的身份认证机制。
#### 6.1.1 HTTP基本认证
HTTP基本认证是最简单的一种认证机制。当客户端发送请求时,服务器可以要求客户端提供用户名和密码。客户端需要在请求头部中添加`Authorization`字段来进行认证。该字段的值是由用户名和密码经过Base64编码后得到的。
以下是一个使用HTTP基本认证的示例代码片段(使用Python语言):
```python
import requests
from requests.auth import HTTPBasicAuth
# 发送带有基本认证的请求
response = requests.get('https://api.example.com', auth=HTTPBasicAuth('username', 'password'))
# 打印响应结果
print(response.text)
```
上述代码中,我们使用了`requests`库来发送HTTP请求,并通过`HTTPBasicAuth`类来进行基本认证。
#### 6.1.2 HTTP摘要认证
HTTP摘要认证是一种更安全的认证机制,相对于基本认证更复杂一些。它通过在服务器和客户端之间交换一个"摘要"来进行认证。
以下是一个使用HTTP摘要认证的示例代码片段(使用Java语言):
```java
import org.apache.http.HttpResponse;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
// 创建HttpClient实例
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建HttpGet实例,并设置认证信息
HttpGet httpGet = new HttpGet("https://api.example.com");
UsernamePasswordCredentials credentials = new UsernamePasswordCredentials("username", "password");
httpClient.getCredentialsProvider().setCredentials(AuthScope.ANY, credentials);
// 执行请求并获取响应
HttpResponse response = httpClient.execute(httpGet);
// 打印响应结果
System.out.println(EntityUtils.toString(response.getEntity()));
```
上述代码中,我们使用了Apache HttpClient库来发送HTTP请求,并通过`UsernamePasswordCredentials`类来进行摘要认证。我们需要设置HttpClient的认证信息,并将其应用于HttpGet请求,然后执行请求并获取响应。
### 6.2 HTTPS的使用与配置
HTTP协议是明文传输的,可能被窃听、篡改等攻击。为了保障通信的安全,可以使用HTTPS协议进行加密传输。
在使用HTTPS时,需要配置服务器端的证书以及验证客户端的证书。
以下是一个使用HTTPS协议的示例代码片段(使用Go语言):
```go
package main
import (
"crypto/tls"
"fmt"
"io/ioutil"
"net/http"
)
func main() {
// 创建HttpClient实例,并设置TLS配置
transport := &http.Transport{
TLSClientConfig: &tls.Config{InsecureSkipVerify: true},
}
httpClient := &http.Client{Transport: transport}
// 发送HTTPS请求
resp, err := httpClient.Get("https://api.example.com")
if err != nil {
panic(err)
}
defer resp.Body.Close()
// 读取响应内容
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
panic(err)
}
// 打印响应结果
fmt.Println(string(body))
}
```
上述代码中,我们使用了Go语言的net/http库来发送HTTPS请求。在创建HttpClient实例时,我们通过`Transport`的`TLSClientConfig`字段设置了TLS配置。为了便于测试,我们将`InsecureSkipVerify`字段设置为`true`,以跳过对服务端证书的验证。
### 6.3 CSRF等安全漏洞的防护措施
在Web开发中,存在一些常见的安全漏洞,如跨站请求伪造(CSRF)攻击、跨站脚本(XSS)攻击等。为了防止这些安全漏洞的利用,开发者需要采取相应的防护措施。
比如,对于CSRF攻击,可以使用Token验证来防护。服务端在返回表单页面时生成一个Token,并将其存储在会话中和表单中。当提交表单时,验证Token的有效性,如果不匹配则拒绝请求。
以下是一个使用Token防护CSRF攻击的示例代码片段(使用JavaScript语言):
```javascript
// 生成一个Token,并将其存储在会话中和表单中
function generateToken() {
var token = Math.random().toString(36).substring(2);
sessionStorage.setItem('csrfToken', token);
document.getElementById('csrfToken').value = token;
}
// 提交表单时验证Token的有效性
function submitForm() {
var storedToken = sessionStorage.getItem('csrfToken');
var inputToken = document.getElementById('csrfToken').value;
if (inputToken !== storedToken) {
alert('CSRF token verification failed!');
return false;
}
return true;
}
```
上述代码中,我们在表单页面加载时生成一个Token,并将其存储在会话中和表单中。在提交表单时,通过验证输入的Token和存储的Token是否一致来进行CSRF防护。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《tornado框架开发与应用》专栏全面系统地介绍了如何使用tornado框架构建强大的Python Web应用程序。从初识tornado框架,快速搭建Web应用程序开始,深入探讨了tornado框架中的路由配置、HTTP请求处理与响应、模板引擎渲染网页、用户输入数据处理、用户认证和授权等方面的详细内容。同时,还覆盖了与关系型数据库、异步编程与协程、WebSocket实时通信、RESTful API、消息队列、分布式部署、缓存提升性能、页面静态化、分布式任务调度、日志管理与错误处理、高并发处理与负载均衡等相关的实践技巧和案例。通过本专栏的学习,读者将全面掌握tornado框架的开发与应用,为构建高性能、可靠的Web应用奠定坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
技术手册制作流程:如何打造完美的IT产品手册?
# 摘要
技术手册作为重要的技术沟通工具,在产品交付和使用过程中发挥着不可或缺的作用。本文系统性地探讨了技术手册撰写的重要性和作用,详述了撰写前期准备工作的细节,包括明确编写目的与受众分析、构建内容框架与风格指南、收集整理技术资料等。同时,本文进一步阐述了内容创作与管理的方法,包含文本内容的编写、图表和视觉元素的设计制作,以及版本控制与文档管理策略。在手册编辑与校对方面,本文强调了建立高效流程和标准、校对工作的方法与技巧以及互动反馈与持续改进的重要性。最后,本文分析了技术手册发布的渠道与格式选择、分发策略与用户培训,并对技术手册的未来趋势进行了展望,特别是数字化、智能化的发展以及技术更新对手册
【SQL Server触发器实战课】:自动化操作,效率倍增!

# 摘要
SQL Server触发器是数据库中强大的自动化功能,允许在数据表上的特定数据操作发生时自动执行预定义的SQL语句。本文
高效优化车载诊断流程:ISO15765-3标准的应用指南

# 摘要
本文详细介绍了ISO15765-3标准及其在车载诊断系统中的应用。首先概述了ISO15765-3标准的基本概念,并探讨了车载诊断系统的功能组成和关键技术挑战。接着,本文深入分析了该标准的工作原理,包括数据链路层协议、消息类型、帧结构以及故障诊断通信流程
【Sysmac Studio模板与库】:提升编程效率与NJ指令的高效应用
# 摘要
本文旨在深入介绍Sysmac Studio的开发环境配置、模板和库的应用,以及NJ指令集在高效编程中的实践。首先,我们将概述Sysmac Studio的界面和基础开发环境设置。随后,深入探讨模板的概念、创建、管理和与库的关系,包括模板在自动化项目中的重要性、常见模板类型、版本控制策略及其与库的协作机制。文章继续分析了
【内存管理技术】:缓存一致性与内存层次结构的终极解读
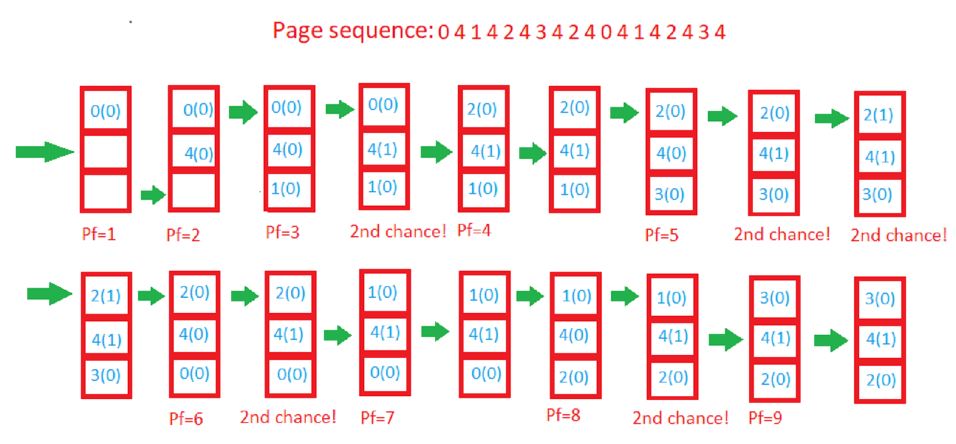
# 摘要
本文对现代计算机系统中内存管理技术进行了全面概述,深入分析了缓存一致性机制及其成因、缓存一致性协议和硬件支持,以及它们对系统性能的影响。随后,本文探讨了内存层次结构与架构设计,包括内存管理策略、页面替换算法和预取技术。文中还提供了内存管理实践案例,分析了大数据环境和实时系统中内存管理的挑战、内存泄漏的诊断技术以及性能调优策略。最后,本文展望了新兴内存技术、软件层面创新和面向未来的内存管理挑战,包括安全性、隐私保护、可持续性和能效问题。
#
【APS系统常见问题解答】:故障速查手册与性能提升指南

# 摘要
本文全面概述了APS系统故障排查、性能优化、故障处理及维护管理的最佳实践。首先,介绍了故障排查的理论依据、工具和案例分析,为系统故障诊断提供了坚实的基础。随后,探讨了性能优化的评估指标、优化策略和监控工具的应用,
SEMI-S2标准实施细节:从理论到实践
# 摘要
本文全面介绍了SEMI-S2标准的理论基础、实践应用以及实施策略,并探讨了相关技术创新。首先概述了SEMI-S2标准的发展历程和核心条款,随后解析了其技术框架、合规要求以及监控与报告机制。接着,文中分析了SEMI-S2标准在半导体制造中的具体应用,并通过案例分析,展示了在工厂环境控制与设备操作维护中的实践效果。此外,本文还提出了实
康耐视扫码枪数据通讯秘籍:三菱PLC响应优化技巧

# 摘要
本文详细探讨了康耐视扫码枪与三菱PLC之间数据通信的基础技术与实践应用,包括通讯协议的选择与配置、数据接口与信号流程分析以及数据包结构的封装和解析。随后,文章针对数据通讯故障的诊断与调试提供了方法,并深入分析了三菱PLC的响应时间优化策略,包括编程响应时间分析、硬件配置改进和系统级优化。通过实践案例分析与应用,提出了系统集成、部署以及维护与升级策略。最后,文章展
【Deli得力DL-888B打印机耗材管理黄金法则】:减少浪费与提升效率的专业策略

# 摘要
Deli得力DL-888B打印机的高效耗材管理对于保障打印品质和降低运营成本至关重要。本文从耗材管理的基础理论入手,详细介绍了打印机耗材的基本分类、特性及生命周期,探讨了如何通过实践实现耗材使用的高效监控。接着,本文提出了减少耗材浪费和提升打印效率的优化策略。在成本控制与采购策略方面,文章讨论了耗材成本的精确计算方法以及如何优化耗材供应链。最后,本
物流效率的秘密武器:圆通视角下的优博讯i6310B_HB版升级效果解析
# 摘要
随着技术的发展,物流效率的提升已成为行业关注的焦点。本文首先介绍了物流效率与技术驱动之间的关系,接着详细阐述了优博讯i6310B_HB版的基础特性和核心功能。文章深入分析了传统物流处理流程中的问题,并探讨了i6310B_HB版升级对物流处理流程带来的变革,包括数据处理效率的提高和操作流程的改进。通过实际案例分析,展示了升级效果,并对未来物流行业的技术趋势及圆通在技术创新中的角色进行了展望,强调了持续改进的重要性。
# 关键字
物流效率;技术驱动;优博讯i6310B_HB;数据处理;操作流程;技术创新
参考资源链接:[圆通工业手机i6310B升级指南及刷机风险提示](https:/
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )