C#锁机制陷阱揭秘:程序员如何避免多线程常见错误
发布时间: 2024-10-21 13:29:18 阅读量: 27 订阅数: 24 
# 1. C#中锁机制的概念和必要性
## 1.1 什么是锁机制
在C#中,锁机制是管理多线程访问共享资源的一种同步机制。它通过确保一次只有一个线程可以进入临界区(一个被锁保护的代码段),从而避免多个线程对同一资源的并发访问问题,防止资源竞争和数据不一致。
## 1.2 锁机制的必要性
在多线程编程中,多个线程常常需要访问和操作共享资源,这可能引起竞态条件(race condition),即线程运行的顺序会影响程序的最终结果。锁机制的引入正是为了解决这种问题。例如,如果没有适当的同步机制,银行账户余额的更新可能会因为并发的存取操作而出现错误。锁机制确保每次只有一个线程能够修改数据,从而维护了数据的一致性和完整性。
## 1.3 锁的类型和应用场景
C#提供了不同类型的锁,例如`Monitor`、`Mutex`、`Semaphore`、`ReaderWriterLock`等,每种锁都有其特定的使用场景。开发者需要根据实际需求选择合适的锁类型。例如,`Monitor`适用于单个资源的访问控制,而`Semaphore`适合限制对资源池的并发访问数量。选择合适的锁,可以在保证线程安全的同时,最大程度上减少性能开销和避免死锁的可能性。
# 2. 深入理解C#中的锁机制类型
## 2.1 互斥锁(Mutex)和信号量(Semaphore)
### 2.1.1 互斥锁的工作原理和使用场景
互斥锁(Mutex)是一种用于控制多个线程对共享资源进行排他性访问的同步机制。它的主要作用是保证在同一时刻,只有一个线程可以访问该资源。互斥锁通常用于保护临界区,防止数据竞争和不一致性。
在C#中,互斥锁的实现依赖于`System.Threading.Mutex`类。互斥锁有一个与之相关联的信号量,初始状态为0。当一个线程获得互斥锁时,该信号量增加,使得其他线程无法进入临界区。当该线程释放互斥锁时,信号量减少,允许其他线程访问临界区。
互斥锁的使用场景广泛,比如:
- 保护共享资源的访问,确保同一时刻只有一个线程对其进行读写操作。
- 防止多个线程同时执行一个只允许单次执行的代码块,例如初始化代码。
- 在类的实例之间同步访问,确保在多线程环境下的线程安全。
### 2.1.2 信号量的工作原理和使用场景
信号量(Semaphore)是一种控制多个线程访问有限数量资源的同步对象。它维护一组虚拟的许可(信号量计数器),其值表示可用资源的数量。信号量允许线程请求资源,当信号量计数器大于零时,请求将被授权,否则请求的线程将被阻塞直到信号量计数器大于零。
在C#中,信号量通过`System.Threading.Semaphore`类实现。一个典型的使用场景是限制对某些资源的访问数量,比如数据库连接池中的连接数量限制。
信号量的主要用途包括:
- 控制对一组资源的访问,限制对资源的最大并发访问数。
- 实现线程的同步,比如在生产者-消费者模型中控制生产速度和消费速度。
- 在并发编程中限制对某个特定代码段的并发执行数。
### 2.1.3 互斥锁与信号量的对比
尽管互斥锁和信号量都可以实现线程间的同步,但它们之间存在一些关键性的区别:
- **资源数量**:互斥锁只允许一个线程访问资源,而信号量允许一定数量的线程访问资源。
- **用途**:互斥锁常用于资源的排他性访问,而信号量常用于限制资源的访问数量。
- **性能开销**:互斥锁在每次获取和释放时只涉及一个许可,而信号量可能涉及多个许可的获取和释放,因此信号量在高并发场景下的性能可能受到影响。
## 2.2 读写锁(ReaderWriterLock)和自旋锁(SpinLock)
### 2.2.1 读写锁的工作原理和使用策略
读写锁(ReaderWriterLock)是一种支持多读单写的锁机制。当没有写线程正在访问资源时,允许多个读线程同时访问资源;当有写线程在访问资源时,则阻塞所有其他读写线程,保证了写操作的独占性。
在C#中,`System.Threading.ReaderWriterLockSlim`类提供了一个高效、轻量级的读写锁实现。它提供三种锁定模式:读锁定、升级锁定(读转换为写)、写锁定。读锁定通常以“无等待”方式获得,而写锁定可能会导致读线程的阻塞。
读写锁适用于以下场景:
- 当读操作远多于写操作时,读写锁可以提高系统的并发性能。
- 资源经常被读取,但偶尔需要更新时。
- 应用于多线程环境中的缓存,比如缓存经常被读取的数据。
### 2.2.2 自旋锁的工作原理和性能考虑
自旋锁(SpinLock)是一种低级的同步机制,它依赖于忙等待(busy-waiting)。当锁不可用时,线程会重复检查锁的状态,直到锁被释放。自旋锁适用于短时间持有锁的场景,因为长时间的自旋会导致处理器资源的浪费。
在C#中,`System.Threading.SpinLock`类实现了自旋锁的功能。与传统锁不同的是,自旋锁不涉及上下文切换,因此在锁很快被释放的情况下,自旋锁可以提供较低的延迟。但如果锁被长时间占用,自旋锁可能会导致处理器资源的高消耗。
自旋锁的主要使用场景包括:
- 锁定时间极短的操作。
- 在性能敏感的应用中,特别是在多核处理器上。
- 在中断处理程序或上下文切换开销很大的环境中。
### 2.2.3 读写锁与自旋锁的对比
- **适用场景**:读写锁适合读操作频繁且读操作时间较长的场景,而自旋锁适合锁定时间极短的场景。
- **性能开销**:读写锁在切换读写模式时可能会有一定的开销,自旋锁则在锁被长时间占用时会导致处理器资源浪费。
- **使用复杂度**:读写锁的使用相对复杂,需要管理不同的锁定模式,而自旋锁的使用相对简单,但需要谨慎考虑其适用场景。
## 2.3 常见的锁机制陷阱分析
### 2.3.1 死锁的成因和预防
死锁是指两个或多个线程在执行过程中,因争夺资源而造成的一种僵局,即每个线程都在等待其他线程释放资源。死锁的发生通常需要满足四个条件:互斥条件、请求与保持条件、不可剥夺条件和循环等待条件。
为预防死锁,可以采取以下措施:
- 避免循环等待:确保每个线程按照特定顺序访问资源。
- 避免持有和等待:要求线程在开始执行前获取所有需要的资源。
- 使用超时机制:给锁请求设置超时,当无法获取锁时,线程可以释放已持有的资源。
- 死锁检测与恢复:系统周期性地检测死锁,并通过某种策略强制恢复,例如终止线程或释放资源。
### 2.3.2 锁粒度不当导致的性能问题
锁粒度是指锁保护的范围大小。锁粒度过大,会导致过多的线程竞争同一把锁,增加线程阻塞的时间和频率,降低并发性能;锁粒度过小,则可能引入额外的复杂性和维护难度,同时可能会引发死锁。
为了平衡锁粒度,可以采取以下策略:
- 使用细粒度锁:对数据的访问进行划分,使锁保护的数据尽可能少。
- 使用读写锁:区分读操作和写操作,允许读操作并发执行,而写操作独占锁。
- 锁分离:根据数据的访问特点,将数据和锁分离,如Java中的ConcurrentHashMap。
以上是第二章的内容概述,详细内容将基于上述结构和要求展开。
# 3. C#锁机制的最佳实践
## 3.1 锁的正确选择和使用
### 3.1.1 如何根据需求选择合适的锁类型
在多线程编程中,正确选择锁的类型对系统性能有着重要的影响。C#提供了多种锁机制,包括互斥锁(Mutex)、信号量(Semaphore)、读写锁(ReaderWriterLock)和自旋锁(SpinLock)等。选择合适的锁类型需要考虑以下几个方面:
1. **锁的粒度**:细粒度的锁可以减少线程间的竞争,提高并发度,但也可能导致更高的管理开销。粗粒度的锁管理简单,但可能会导致不必要的线程阻塞。
2. **锁定时间**:锁的持有时间应尽可能短。长时间持有锁会导致资源竞争加剧,影响性能。如果锁定时间不可预见或很长,可能需要考虑其他并发控制方法,如锁分离、锁分解等技术。
3. **读写比例**:如果共享资源的读操作远远多于写操作,使用读写锁可以大幅度提高并发性能。读写锁允许多个读操作同时进行,而写操作需要独占访问。
4. **优先级反转问题**:在某些情况下,高优先级的线程可能因为等待低优先级线程释放锁而被阻塞。对于这种情况,可以使用优先级继

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析了 C# 中的锁机制,为高级并发编程提供了全面指导。从 Monitor 类到 ReaderWriterLockSlim,再到死锁预防和性能优化,专栏涵盖了锁机制的各个方面。通过 20 年的经验分享,作者揭示了锁机制的陷阱和最佳实践,帮助程序员避免常见错误并优化多线程代码。此外,专栏还探讨了锁机制在分布式系统中的应用,为构建可扩展和高并发的应用程序提供了宝贵的见解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
支持向量机在语音识别中的应用:挑战与机遇并存的研究前沿

# 1. 支持向量机(SVM)基础
支持向量机(SVM)是一种广泛用于分类和回归分析的监督学习算法,尤其在解决非线性问题上表现出色。SVM通过寻找最优超平面将不同类别的数据有效分开,其核心在于最大化不同类别之间的间隔(即“间隔最大化”)。这种策略不仅减少了模型的泛化误差,还提高了模型对未知数据的预测能力。SVM的另一个重要概念是核函数,通过核函数可以将低维空间线性不可分的数据映射到高维空间,使得原本难以处理的问题变得易于
从GANs到CGANs:条件生成对抗网络的原理与应用全面解析
.jpg)
# 1. 生成对抗网络(GANs)基础
生成对抗网络(GANs)是深度学习领域中的一项突破性技术,由Ian Goodfellow在2014年提出。它由两个模型组成:生成器(Generator)和判别器(Discriminator),通过相互竞争来提升性能。生成器负责创造出逼真的数据样本,判别器则尝试区分真实数据和生成的数据。
## 1.1 GANs的工作原理
神经网络硬件加速秘技:GPU与TPU的最佳实践与优化

# 1. 神经网络硬件加速概述
## 1.1 硬件加速背景
随着深度学习技术的快速发展,神经网络模型变得越来越复杂,计算需求显著增长。传统的通用CPU已经难以满足大规模神经网络的计算需求,这促使了
细粒度图像分类挑战:CNN的最新研究动态与实践案例

# 1. 细粒度图像分类的概念与重要性
随着深度学习技术的快速发展,细粒度图像分类在计算机视觉领域扮演着越来越重要的角色。细粒度图像分类,是指对具有细微差异的图像进行准确分类的技术。这类问题在现实世界中无处不在,比如对不同种类的鸟、植物、车辆等进行识别。这种技术的应用不仅提升了图像处理的精度,也为生物多样性
市场营销的未来:随机森林助力客户细分与需求精准预测

# 1. 市场营销的演变与未来趋势
市场营销作为推动产品和服务销售的关键驱动力,其演变历程与技术进步紧密相连。从早期的单向传播,到互联网时代的双向互动,再到如今的个性化和智能化营销,市场营销的每一次革新都伴随着工具、平台和算法的进化。
## 1.1 市场营销的历史沿
【AdaBoost深度解析】:5个案例揭示分类问题中的最佳实践
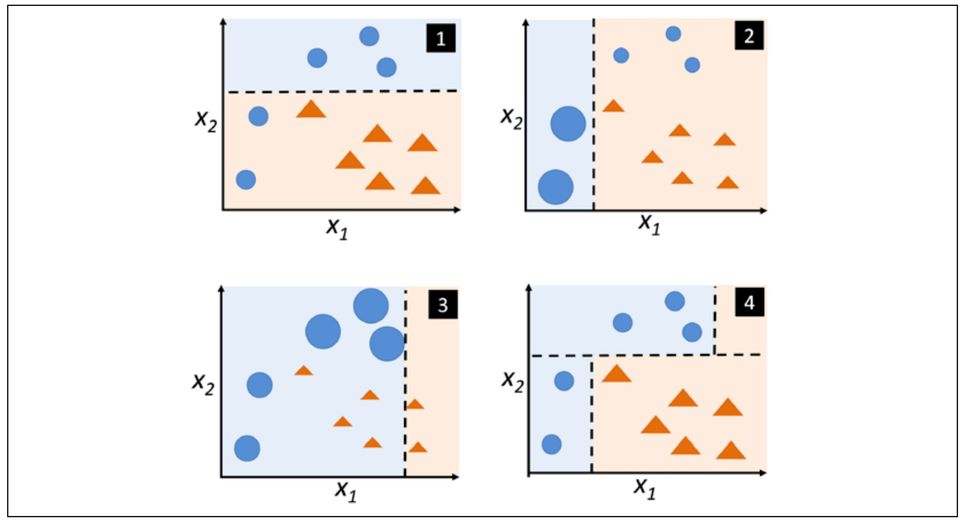
# 1. AdaBoost算法概述
AdaBoost(Adaptive Boosting)算法作为提升学习(Boosting)领域的重要里程碑,已经在各种机器学习任务中显示出其强大的分类能力。提升学习的核心思想是将多个弱学习器组合起来构建一个强学习器,通过这种集成学习的方式,使得最终的学习器能够达到较高的预测精度。在众多提升算法中,AdaBoost以其独特的自适应更新机制,成为最受欢迎和
RNN可视化工具:揭秘内部工作机制的全新视角

# 1. RNN可视化工具简介
在本章中,我们将初步探索循环神经网络(RNN)可视化工具的核心概念以及它们在机器学习领域中的重要性。可视化工具通过将复杂的数据和算法流程转化为直观的图表或动画,使得研究者和开发者能够更容易理解模型内部的工作机制,从而对模型进行调整、优化以及故障排除。
## 1.1 RNN可视化的目的和重要性
可视化作为数据科学中的一种强
XGBoost时间序列分析:预测模型构建与案例剖析
# 1. 时间序列分析与预测模型概述
在当今数据驱动的世界中,时间序列分析成为了一个重要领域,它通过分析数据点随时间变化的模式来预测未来的趋势。时间序列预测模型作为其中的核心部分,因其在市场预测、需求计划和风险管理等领域的广泛应用而显得尤为重要。本章将简单介绍时间序列分析与预测模型的基础知识,包括其定义、重要性及基本工作流程,为读者理解后续章节内容打下坚实基础。
# 2. XGB
K-近邻算法多标签分类:专家解析难点与解决策略!

# 1. K-近邻算法概述
K-近邻算法(K-Nearest Neighbors, KNN)是一种基本的分类与回归方法。本章将介绍KNN算法的基本概念、工作原理以及它在机器学习领域中的应用。
## 1.1 算法原理
KNN算法的核心思想非常简单。在分类问题中,它根据最近的K个邻居的数据类别来进行判断,即“多数投票原则”。在回归问题中,则通过计算K个邻居的平均
LSTM在语音识别中的应用突破:创新与技术趋势

# 1. LSTM技术概述
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN),它能够学习长期依赖信息。不同于标准的RNN结构,LSTM引入了复杂的“门”结构来控制信息的流动,这允许网络有效地“记住”和“遗忘”信息,解决了传统RNN面临的长期依赖问题。
## 1
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )