模型选择与优化:综合评估方法的实操指南
发布时间: 2024-11-24 20:49:21 阅读量: 33 订阅数: 37 

ATT-CK-CN:ATT&CK实操

# 1. 模型选择与优化的重要性
## 概述
在构建机器学习模型时,模型选择与优化是至关重要的步骤。一个良好的模型选择不仅能够提高预测的准确性,而且还能提升模型的泛化能力,确保其在未见数据上的表现稳定。优化过程则涉及到调整模型参数,改进算法,以获得最佳性能。
## 模型选择的作用
选择正确的模型结构是解决特定问题的前提。根据数据的特性、问题的类型(分类、回归等),以及模型的复杂度和解释能力,模型选择将决定后续优化步骤的基础。例如,决策树简单直观,适合处理分类问题,而神经网络则可能在复杂的模式识别任务中表现出色。
## 优化的目的
模型优化的目的是调整模型参数和结构,以减少过拟合和欠拟合的风险,提高模型对新数据的适应能力。通过优化,可以使得模型更加稳定、鲁棒,并且在不同数据集上都能维持较好的表现。常见的优化技术包括参数调整、特征选择和集成学习等。
在接下来的章节中,我们将更深入地探讨模型评估的基本理论、过拟合与欠拟合的问题,以及交叉验证等关键概念,这些都是进行有效模型选择与优化的基础。
# 2. 模型评估的基本理论
## 2.1 评估指标的分类与选择
### 2.1.1 准确度与精确度
在模型评估中,准确度(Accuracy)和精确度(Precision)是两个基础而关键的概念。准确度是指模型正确预测的样本数与总样本数的比例。即,一个模型准确度高表示它对于多数样本作出了正确的预测。精确度则指在所有被模型预测为正类的样本中,真正为正类的样本所占的比例。
下面是一个简单的例子来说明这两个概念:
假设在一个二分类问题中,我们有100个样本,其中80个为正类,20个为负类。一个模型预测了85个正类,其中有75个是真正的正类,10个负类被错误地预测为正类。
- 准确度 = (真正类样本数 + 真正负样本数) / 总样本数 = (75 + 5) / 100 = 80%
- 精确度 = 真正正类样本数 / 预测正类样本数 = 75 / 85 ≈ 88.24%
准确度和精确度虽然都衡量了模型预测的性能,但它们的侧重点不同。准确度关注整体预测的正确性,而精确度更侧重于预测为正的样本中有多少是真正的正类。
### 2.1.2 召回率与F1分数
召回率(Recall)或称为真阳性率(True Positive Rate),是指模型正确识别出的正类样本数占所有实际正类样本数的比例。它衡量的是模型对于正类的“覆盖率”。
- 召回率 = 真正正类样本数 / 所有实际正类样本数 = 75 / 80 = 93.75%
召回率高表明模型倾向于预测正类,这在一些应用中非常关键,比如疾病筛查,我们不希望遗漏任何一个潜在的病例。
F1分数是准确度和召回率的调和平均数,它是评估模型性能的另一个重要指标,特别是当类别分布不均衡时。
F1分数 = 2 * (精确度 * 召回率) / (精确度 + 召回率) ≈ 90.91%
### 2.1.3 AUC-ROC曲线分析
AUC-ROC曲线是评估分类模型性能的一个重要工具,AUC(Area Under Curve)表示在ROC曲线下方的面积,ROC(Receiver Operating Characteristic)曲线是以假正率(FPR)为横轴,以召回率(TPR)为纵轴绘制的曲线图。
- FPR(False Positive Rate)= 假正例数 / 所有负例数
曲线越接近左上角,模型的性能越好,AUC值为1时表示模型完美无缺,AUC值为0.5时表示模型预测能力与随机猜测无异。
## 2.2 模型的过拟合与欠拟合
### 2.2.1 过拟合的概念与原因
过拟合(Overfitting)是指模型在训练数据上表现很好,但在新的、未见过的数据上表现不佳的现象。换言之,模型变得过于复杂,不仅学习到了数据中的规律,还学习到了数据中的噪声。导致过拟合的主要原因通常与以下因素相关:
- 模型过于复杂:使用了过多的参数或者模型结构过于复杂。
- 训练数据不足:样本量不足以涵盖所有可能出现的情况。
- 噪声数据:训练数据包含大量噪声或异常值。
### 2.2.2 欠拟合的识别与解决
与过拟合相反,欠拟合(Underfitting)是指模型无法捕捉数据的真实特征,即使在训练数据上表现也不理想。欠拟合的识别相对简单,主要表现在模型在训练数据和测试数据上的性能都不好。
解决欠拟合的办法通常包括:
- 增加模型复杂度:选择更为复杂的模型或增加模型参数。
- 使用更多的特征:引入更多相关特征以捕捉数据的真实结构。
- 延长模型训练时间:让模型有更充分的时间去学习数据的特征。
### 2.2.3 正则化技术应用
为了防止过拟合,经常采用正则化技术,其基本思想是为损失函数添加一个额外的惩罚项,这样可以控制模型的复杂度,促进模型学习更为简洁的特征表示。
常见的正则化方法包括:
- L1正则化:增加L1范数作为惩罚项,可导致模型参数稀疏化。
- L2正则化:增加L2范数作为惩罚项,倾向于使模型参数变得更小且接近于零但不完全为零。
下面是一个使用L2正则化对线性回归模型进行优化的简单示例:
```python
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
# 生成模拟数据集
X, y = make_regression(n_samples=100, n_features=20, noise=0.1, random_state=42)
# 应用Ridge回归(L2正则化)
ridge = Ridge(alpha=0.1)
ridge.fit(X, y)
# 打印模型参数
print(ridge.coef_)
print(ridge.intercept_)
```
参数`alpha`是正则化项的强度参数。随着`alpha`的增大,模型的正则化项影响增大,模型的复杂度会降低,从而降低过拟合的风险。在上述代码中,`Ridge`类是线性回归模型的L2正则化版本。通过调整`alpha`参数,我们可以控制模型复杂度和防止过拟合。
## 2.3 交叉验证方法
### 2.3.1 K折交叉验证的原理与实现
K折交叉验证(K-Fold Cross-Validation)是一种常用的模型评估方法,它通过将数据集划分为K个子集,然后用其中K-1个子集进行模型训练,剩下的一个子集进行验证。重复这一过程K次,每次选取不同的子集作为验证集,最终模型性能的评估是基于K次验证结果的平均。
K折交叉验证的优点在于能够更充分地利用有限的数据集,提高模型评估的可靠性。
下面是一个K折交叉验证的Python代码示例:
```python
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载iris数据集
iris = load_iris()
X, y = iris.data, iris.target
# 设置K折交叉验证的参数
kf = KFold(n_splits=5)
# 用于存储每一轮的准确率
scores = []
# 进行交叉验证
for train_index, test_index in kf.split(X):
# 根据索引分割数据集
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 初始化逻辑回归模型并训练
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
# 进行预测并计算准确率
predictions = model.predict(X_test)
score = accuracy_score(y_test, predictions)
scores.append(score)
# 输出平均准确率
print("Average accuracy: ", sum(scores)/len(scores))
```
在这个例子中,我们使用了5折交叉验证来评估逻辑回归在iris数据集上的准确率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《机器学习-超参数》专栏深入探讨了机器学习超参数优化这一关键主题。从基础概念到高级技术,该专栏涵盖了广泛的主题,包括:
* 超参数优化速成指南
* 贝叶斯优化在超参数优化中的应用
* 常见超参数优化错误及解决策略
* 学习率优化案例研究
* Optuna和Hyperopt等自动化超参数调优工具的使用教程
* 提升卷积神经网络性能的超参数优化策略
* 交叉验证在超参数优化中的作用
* 微调艺术和超参数优化深度解析
* 超参数优化实验设计全攻略
* 强化学习在超参数优化中的应用
该专栏旨在为机器学习从业者提供全面且实用的指南,帮助他们优化机器学习模型的性能,提高模型的准确性和效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MAX9295_MAX9296 GMSL2–MIPI–CSI–2 故障排除】:常见问题快速诊断与解决指南
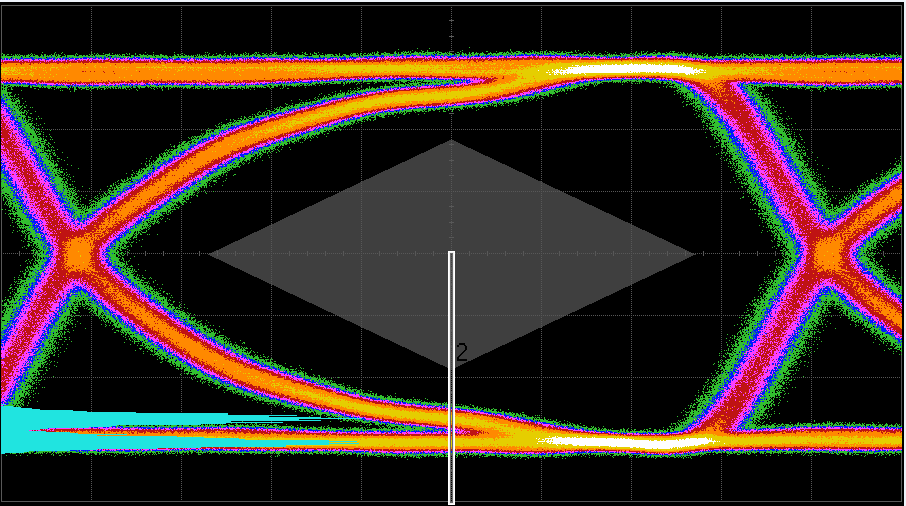
# 摘要
本文介绍了MAX9295_MAX9296 GMSL2–MIPI–CSI–2的特性,并对其故障诊断理论基础进行了深入探讨。章节详细阐述了GMSL2–MIPI–CSI–2的基本工作原理,分析了连接故障、数据传输错误和信号完整性问题的原因,并讨论了使用现代工具和技术进行故障排查的方法。此外,本文提供了基于实践的故障解决策略,包括硬件和软件故障处理,
ICGC数据库数据管理简化指南:导入导出最佳实践
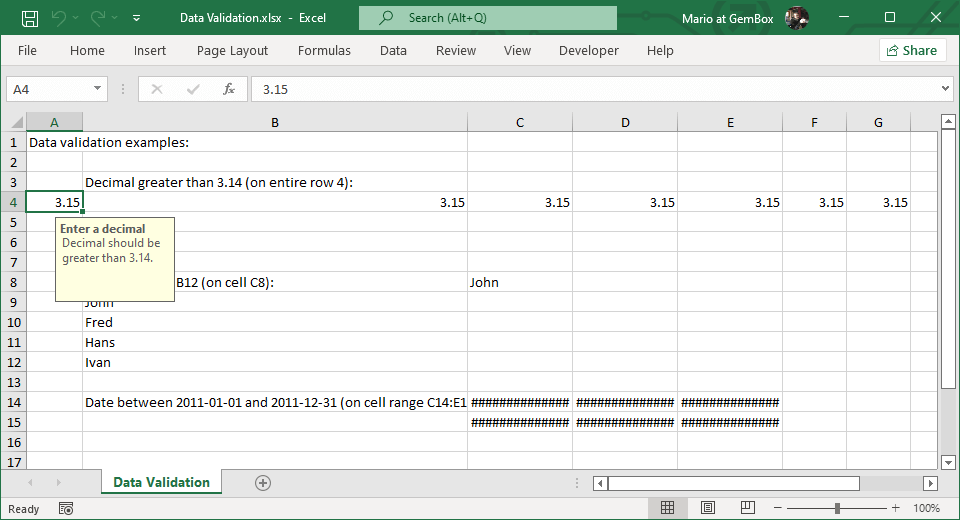
# 摘要
本文全面介绍了ICGC数据库的导入与导出策略、数据管理和维护方法,以及自动化管理工具的最佳实践。首先概述了ICGC数据库的基本概念和重要性。接着深入探讨了数据导入前的准备工作,包括数据格式转换、校验清洗,及技巧如批量导入和实时更新机制。通过案例分析,本文还讨论了成功导入的范例和解决常见问题的方法。在数据导出方面,文章详述了准备工作、导出技巧以及导出过程中的常见问
掌握C++队列:一步到位解决舞伴配对问题

# 摘要
本论文首先介绍了队列的基础知识及其在C++中的实现。接着,深入分析了队列的先进先出原理、操作方法和时间复杂度。文章进一步探讨了队列在C++标准库中的高级应用,如算法实现和多线程中的应用。此外,本文还提供了一个具体的队列解决方案——舞伴配对问题,并对其设计、实现和优化进行了详细讨论。最后,通过一个编程挑战案例,展
铁路售票系统用例图:需求验证与场景模拟的专业方法
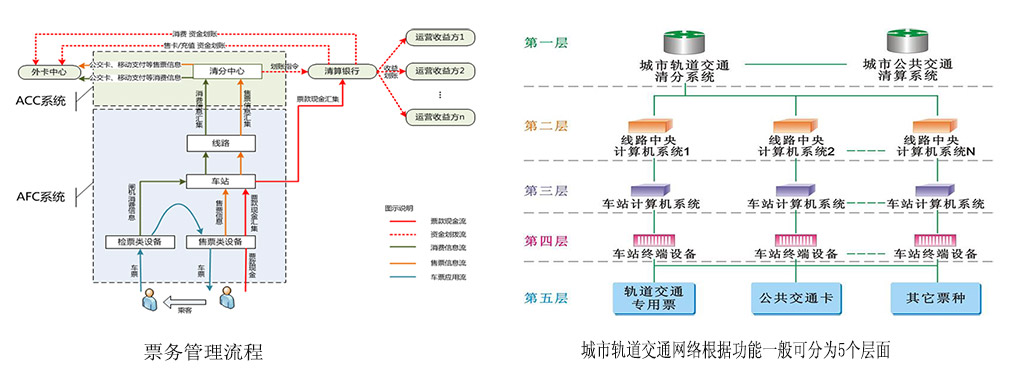
# 摘要
铁路售票系统的用例图作为需求工程的重要工具,对于系统设计和实现具有指导意义。本文从用例图的基础理论出发,详细阐述了用例图的定义、组成、设计原则以及与需求工程的关系。通过分析铁路售票系统的实例,本文探讨了用例图在需求分析、绘制优化和场景模拟中的具体应用。此外,本文还指出了用例图在当前实施中的挑战,并对其在敏捷开发和集成新技术方面的未来发展趋势进行了展望。
# 关键字
铁路售票系统;用例图;需求工程;场景模拟;功能设计;
【Focas2接口全攻略】:13个实用技巧助你成为数据交换大师

# 摘要
Focas2接口是工业自动化领域的重要通信协议,本文旨在提供对Focas2接口全面的概述和技术解析。首先介绍了Focas2接口的发展历程和关键特性,接着详细探讨了其数据交换机制,包括数据封装、协议细节以及TCP/IP在网络通信中的作用。进一步深入解析了报文结构
【数字电路设计的加速器】:三态RS锁存器CD4043高级应用技巧大公开
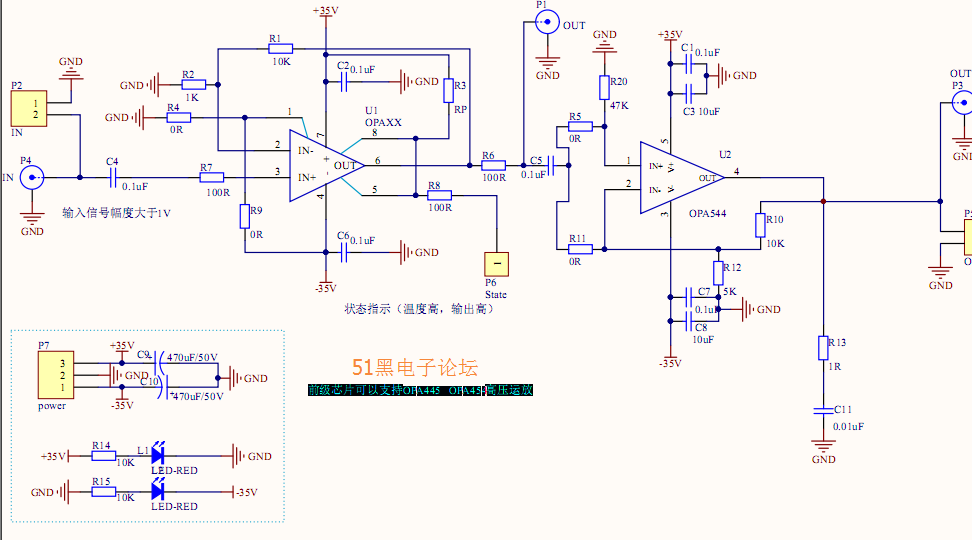
# 摘要
本文深入探讨了数字电路中三态RS锁存器的基础概念及其工作原理,特别关注CD4043这一广泛应用的型号。文章首先介绍了CD4043的基本特性和信号处理机制,然后详细分析了其在数字电路设计中的应用场景和电路设计技巧。随后,探讨了CD4043的高级编程与配置技巧,包括如何通过编程控制三态逻辑、集成测试与故障排除以及优化设计与安全注意事项。最后,文章通过实际项目应用案例,展望了CD40
【编译原理的计算视角】:计算理论导引第五章对编译器设计的深远影响
# 摘要
本文全面介绍编译器的设计与实现过程,从编译器概述与计算理论基础讲起,逐步深入到词法分析、语法分析、语义分析、优化与代码生成等关键阶段。文章详细探讨了有限自动机在词法分析中的应用、上下文无关文法在语法分析中的重要性,以及类型系统的原理和语义分析中的实现策略。此外,文中也分析了中间表示(IR)的作用、常见的编译时和运行时代码优化技术,以及代码生成过程中的关键步骤。最后,本文展望了编译器前沿技术,包括并行编译
SD卡性能飙升秘诀:掌握物理层规范4.0的关键技巧
# 摘要
随着存储技术的快速发展,SD卡作为一种便携式存储介质,在消费电子和工业领域中得到了广泛应用。本文对SD卡技术进行了全面概述,并详细介绍了SD卡物理层规范4.0的关键特性和性能提升的技术要点。通过分析SD卡的物理接口、基本操作以及新规范所带来的改进,探讨了提升SD卡性能的实践技巧,如高速模式优化、电源管理和读写优化策略。本文还提供了性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )