Java核心类库深度剖析:掌握JDK常用类库的5大技巧
发布时间: 2024-09-30 09:57:26 阅读量: 35 订阅数: 31 

JDK7底层C++源码及hotspot虚拟机源码

# 1. Java核心类库概述
Java核心类库是Java开发者在日常开发中不可或缺的工具包,它包含了丰富的数据结构、异常处理、集合框架、输入输出流以及并发工具等,是构建Java应用程序的基础。在本章中,我们将先对Java核心类库做一个全景式的概览,为接下来深入分析具体类和接口打下坚实的基础。
## 1.1 Java核心类库的重要性
Java核心类库的设计目的是为了简化开发者的编码工作,提供一套全面的、经过精心设计的、可复用的组件集合。它覆盖了从基础的字符串处理到复杂的并发编程,从简单的日志记录到复杂的网络通信等领域。掌握核心类库不仅可以提升开发效率,还可以优化程序性能,确保代码的可维护性和可扩展性。
## 1.2 类库的组织结构
Java核心类库按照功能划分成多个包(package),包括但不限于`java.lang`、`java.util`、`java.io`、`***`和`java并发包java.util.concurrent`等。每个包内又包含了一系列的类和接口,这些类和接口通过层次化的方式组织,使得开发者能够根据需要快速定位到相应的功能模块。
接下来的章节我们将从Collection框架开始,深入探讨Java核心类库中的几个关键部分,以实例和代码为基础,揭示类库背后的原理与最佳实践。
# 2. 深入理解Collection框架
### 2.1 Collection接口与实现类
Collection 是 Java 集合框架中最基本的接口之一,它代表一组对象。了解其不同实现类的特性,对于编写高效、清晰的代码至关重要。
#### 2.1.1 List, Set, Queue三大接口特性
List、Set 和 Queue 是 Collection 框架中三个主要的子接口,它们分别代表有序集合、唯一集合和先进先出队列。
- **List**:List 是一个有序集合,可以包含重复的元素。它按照插入顺序来保存元素,允许通过索引访问各个元素。常见的 List 实现类有 ArrayList 和 LinkedList。
- **Set**:Set 是一个不允许包含重复元素的集合。Set 集合不允许有重复的值,它通常用于去重操作。HashSet 和 TreeSet 是常用的 Set 实现类。
- **Queue**:Queue 是一个接口,它表示一个队列数据结构,允许在队列的头部添加元素,在尾部删除元素。LinkedList 实现了 Queue 接口,使得它同时具备了 List 和 Queue 的特性。
接下来,我们会探讨如何在 ArrayList 和 LinkedList 之间做出选择,以及 HashSet 和 TreeSet 的内部机制。
### 2.1.2 ArrayList与LinkedList的区别和选择
ArrayList 和 LinkedList 是 List 接口的两个典型实现类,它们在性能和使用场景上有着明显的区别。
- **ArrayList**:
- **基于动态数组实现**,能够随机访问元素。
- **插入和删除操作相对慢**,因为可能涉及到数组元素的移动。
- **适合索引访问频繁**的场景,例如构建索引数据结构。
- **LinkedList**:
- **基于双向链表实现**,不需要数组的动态扩展。
- **适合快速插入和删除操作**,因为不需要移动其他元素。
- **遍历时性能稍逊于 ArrayList**,因为没有索引可以直接访问。
- **适合实现栈、队列**等数据结构。
在选择 ArrayList 或 LinkedList 时,考虑访问模式很重要。如果你需要频繁地访问列表中的元素,并且插入和删除操作不是主要关注点,那么 ArrayList 是更好的选择。而如果你需要一个能够快速进行插入和删除操作的数据结构,特别是这些操作发生在列表的中间位置时,LinkedList 则更合适。
### 2.1.3 HashSet与TreeSet的内部机制
HashSet 和 TreeSet 都实现了 Set 接口,但它们在内部机制上有着根本的不同。
- **HashSet**:
- **基于 HashMap 实现**,其内部维护了一个 HashMap 的实例。
- **插入效率较高**,因为它是基于哈希表实现的。
- **元素的存储顺序与插入顺序可能不同**,因为哈希表不保证顺序。
- **允许 null 值**。
- **TreeSet**:
- **基于 TreeMap 实现**,但不直接使用 Map 接口,而是使用 SortedSet 接口。
- **元素按照自然排序或者构造时提供的 Comparator 排序**。
- **查找操作效率较高**,因为它是基于红黑树实现的。
- **不允许 null 值**。
选择 HashSet 还是 TreeSet 取决于你的应用是否需要排序。如果你需要对元素进行排序操作,或者是按照某种规则(比如自然排序)来访问元素,TreeSet 将提供更好的性能。如果你仅仅需要一个快速的、无序的集合,那么使用 HashSet 将是更合适的选择。
在下面的章节中,我们将深入了解 Map 接口与实现类的不同特性,包括常见的 HashMap、HashTable、TreeMap、ConcurrentHashMap,以及 WeakHashMap 和 LinkedHashMap 的详解。
# 3. Java I/O流深入分析
## 3.1 字节流与字符流的区别
Java I/O流分为字节流和字符流,它们在处理I/O操作时扮演了重要的角色。字节流主要处理二进制数据,而字符流则处理字符数据。理解这两者的区别对于选择合适的I/O流以满足特定需求至关重要。
### 3.1.1 InputStream/OutputStream类体系结构
`InputStream`是所有字节输入流的父类,而`OutputStream`是所有字节输出流的父类。这两个类及其子类构成了字节流的主要框架。
#### InputStream类结构
`InputStream`的主要职责是从源头读取数据,比如文件、网络连接等。它提供了一系列方法来读取字节数据,如`read()`, `read(byte[] b)`, `skip(long n)`, `available()`, `close()`等。
#### OutputStream类结构
与`InputStream`相对应的输出流是`OutputStream`,它的主要职责是将数据写入目的地,它提供的方法包括`write(int b)`, `write(byte[] b)`, `flush()`, `close()`等。
### 3.1.2 Reader/Writer类体系结构
`Reader`和`Writer`分别是字符输入流和字符输出流的抽象基类。它们支持Unicode编码,从而可以处理文本文件。
#### Reader类结构
`Reader`提供了一系列读取字符的方法,如`read()`, `read(char[] cbuf)`, `ready()`, `close()`等。其子类包括`FileReader`, `BufferedReader`等,用于提供不同场景下的字符读取功能。
#### Writer类结构
`Writer`用于将字符数据写入输出流。它提供如`write(char[] cbuf)`, `write(int c)`, `write(String str)`, `flush()`, `close()`等方法。其子类例如`FileWriter`, `BufferedWriter`等,它们扩展了写入功能。
## 3.2 缓冲流和转换流
在Java I/O中,为了提高I/O操作效率,引入了缓冲流。此外,转换流可以在字节流和字符流之间进行转换,处理混合编码的数据。
### 3.2.1 BufferedInputStream/BufferedOutputStream的作用
`BufferedInputStream`和`BufferedOutputStream`提供内部缓冲区,可以减少实际的物理I/O次数,从而提升程序性能。
#### BufferedInputStream
`BufferedInputStream`通过内部缓冲区减少对外部资源的访问次数,提供更高效的字节流读取。
```java
FileInputStream in = new FileInputStream("test.txt");
BufferedInputStream bin = new BufferedInputStream(in);
int data = bin.read();
```
以上代码展示了如何使用`BufferedInputStream`来包装一个`FileInputStream`实例,以提高读取效率。
#### BufferedOutputStream
`BufferedOutputStream`则是在字节流的输出过程中,先将数据存储在内部缓冲区,然后批量写入到目标目的地。
```java
FileOutputStream out = new FileOutputStream("test.txt");
BufferedOutputStream bout = new BufferedOutputStream(out);
bout.write(data);
bout.flush();
```
### 3.2.2 InputStreamReader/OutputStreamWriter转换机制
`InputStreamReader`将字节流转换为字符流,它利用指定的字符集将字节解码为字符。相反,`OutputStreamWriter`则将字符流转换为字节流,它利用指定的字符集将字符编码为字节。
#### InputStreamReader
`InputStreamReader`在读取字节流时会将字节转换成字符,通过构造函数可以指定字符集。
```java
FileInputStream fis = new FileInputStream("test.txt");
InputStreamReader isr = new InputStreamReader(fis, "UTF-8");
int ch;
while ((ch = isr.read()) != -1) {
// 处理读取到的字符
}
isr.close();
```
#### OutputStreamWriter
当需要将字符数据写入到字节流时,`OutputStreamWriter`可以完成这个任务。它内部使用字符集将字符编码成字节。
```java
FileOutputStream fos = new FileOutputStream("test.txt");
OutputStreamWriter osw = new OutputStreamWriter(fos, "UTF-8");
osw.write("Hello, World!");
osw.close();
```
## 3.3 高级I/O技术
### 3.3.1 文件操作与NIO
Java NIO (New IO)是Java提供的一套新的I/O API,用于替代标准的Java I/O API。NIO支持面向缓冲区的、基于通道的I/O操作。
#### 文件操作的NIO实现
NIO中通过`Path`和`Paths`类表示文件路径,并通过`Files`类提供了一系列静态方法用于文件操作。例如,使用`Files.delete(Path path)`删除文件。
```java
Path path = Paths.get("test.txt");
if (Files.exists(path)) {
Files.delete(path);
}
```
### 3.3.2 序列化与反序列化
Java提供了对象序列化机制,可以将对象状态保存在持久化设备中,或者在网络上传输。相对应的反序列化是从存储设备读取或者接受网络传输的数据,还原成Java对象。
#### 序列化过程
序列化通常通过实现`Serializable`接口来完成,然后使用`ObjectOutputStream`将对象实例写入到输出流。
```java
FileOutputStream fos = new FileOutputStream("object.data");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(new Object());
oos.close();
```
#### 反序列化过程
反序列化使用`ObjectInputStream`,它可以读取`ObjectOutputStream`写出的数据,并将数据重建为对象。
```java
FileInputStream fis = new FileInputStream("object.data");
ObjectInputStream ois = new ObjectInputStream(fis);
Object obj = ois.readObject();
ois.close();
```
### 3.3.3 输入输出流异常处理策略
在进行I/O操作时,合理处理异常是非常关键的。Java I/O类都继承自`IOException`,因此需要妥善处理这些异常,以避免程序崩溃或数据丢失。
#### 异常处理策略
异常处理可以使用try-catch块来捕获和处理,也可以使用try-with-resources语句自动关闭资源。以下是使用try-catch块处理异常的示例。
```java
try {
FileInputStream fis = new FileInputStream("test.txt");
// 处理文件数据
} catch (FileNotFoundException e) {
System.err.println("文件未找到");
} catch (IOException e) {
System.err.println("I/O错误");
} finally {
// 关闭资源,无论是否出现异常
}
```
以上代码块展示了如何捕获文件I/O操作中可能出现的异常,并在`finally`块中确保资源被正确关闭。在Java 7及以上版本,推荐使用try-with-resources简化资源管理,无需显式调用`close()`方法。
```java
try (FileInputStream fis = new FileInputStream("test.txt")) {
// 处理文件数据
} catch (FileNotFoundException e) {
System.err.println("文件未找到");
} catch (IOException e) {
System.err.println("I/O错误");
}
```
通过合理的异常处理,可以提高程序的健壮性和用户体验。
# 4. Java并发编程类库探究
## 4.1 线程的创建与管理
### 4.1.1 线程的生命周期与状态
在Java中,一个线程从创建到消亡,其状态会经历多个阶段。这包括:新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)、等待(Waiting)、计时等待(Timed Waiting)和终止(Terminated)。
一个新建的线程一旦调用start方法开始执行,它就进入就绪状态,此时它在就绪队列等待调度。当线程获得CPU时间片后,便进入运行状态。当线程调用sleep、wait等方法,或者因为I/O操作进入阻塞状态,它便暂时失去所占用的CPU资源,并重新进入就绪状态等待CPU调度。
如果线程执行完成或出现异常,其生命周期就到了终止状态。终止状态的线程不能再被重新启动或复用。
### 4.1.2 创建线程的多种方式
在Java中,创建线程主要有两种方式:继承Thread类或实现Runnable接口。
继承Thread类是最直接的方法,可以定义一个Thread的子类并重写run方法。示例如下:
```java
class MyThread extends Thread {
public void run() {
// 线程执行的代码
}
}
// 使用
MyThread myThread = new MyThread();
myThread.start();
```
实现Runnable接口更为灵活。这是因为Java不支持多重继承,通过实现Runnable接口,我们可以让类继承其他类的同时,实现多线程功能。示例如下:
```java
class MyRunnable implements Runnable {
public void run() {
// 线程执行的代码
}
}
// 使用
Thread thread = new Thread(new MyRunnable());
thread.start();
```
此外,Java 8 引入了lambda表达式,使创建线程变得更加简洁:
```java
Runnable task = () -> {
// 任务代码
};
Thread thread = new Thread(task);
thread.start();
```
### 4.1.3 线程优先级
线程优先级是操作系统的一个属性,它指明了一个线程相对于其它线程的重要性。在Java中,每个线程都有一个优先级,范围是1到10,默认是5。
```java
Thread thread = new Thread(new MyRunnable());
thread.setPriority(Thread.MAX_PRIORITY); // 设置最高优先级
thread.start();
```
需要注意的是,高优先级的线程并不意味着一定会先运行,这取决于操作系统的线程调度策略。
## 4.2 同步机制详解
### 4.2.1 synchronized关键字和锁机制
`synchronized`关键字是Java提供的最基本的线程同步机制,它可以作用于方法或代码块,确保同一时刻只有一个线程可以执行被`synchronized`保护的代码段,从而避免数据不一致问题。
```java
public class Counter {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
}
```
在这个例子中,`increment`和`getCount`方法都被`synchronized`修饰,保证了对`count`变量的访问互斥。
### 4.2.2 volatile关键字的作用和原理
`volatile`关键字是Java提供的一种轻量级同步机制。它确保被`volatile`修饰的变量对所有线程总是可见的,保证了不同线程对这个变量进行操作时的可见性。
```java
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
if (uniqueInstance == null) {
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
```
在这个单例模式的实现中,`uniqueInstance`被`volatile`修饰,确保不同线程获得的实例是一致的。
### 4.2.3 Lock接口及其实现类的使用
`Lock`接口提供了比`synchronized`更加广泛的锁定操作。`ReentrantLock`是`Lock`接口的一个具体实现,它支持非阻塞地获取锁,以及锁的尝试获取和超时获取等特性。
```java
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class Counter {
private final Lock lock = new ReentrantLock();
private int count = 0;
public void increment() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
}
```
在使用`Lock`时,通常会配合`try/finally`结构确保锁的释放,避免发生死锁。
## 4.3 高级并发工具类
### 4.3.1 线程池的配置与使用
线程池是一种基于池化技术管理线程的机制。通过预先创建一定数量的线程,并控制这些线程的生命周期,线程池能够有效管理线程资源,提升程序的性能。
```java
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolExample {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(4);
executor.execute(() -> {
System.out.println("Executing task in Thread: " + Thread.currentThread().getName());
});
// 关闭线程池,不再接受新任务,但会执行完已排队的任务
executor.shutdown();
}
}
```
### 4.3.2 Future, Callable与ExecutorService
`Future`表示异步计算的结果。通过`ExecutorService`提交`Callable`任务后,它会返回一个`Future`对象,我们可以用这个对象来查询异步计算的状态或获取计算结果。
```java
import java.util.concurrent.*;
public class FutureExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executor = Executors.newSingleThreadExecutor();
Future<Integer> future = executor.submit(() -> {
// 模拟长时间任务
TimeUnit.SECONDS.sleep(2);
return 123;
});
// 等待任务完成并获取结果
Integer result = future.get();
System.out.println("Result: " + result);
executor.shutdown();
}
}
```
### 4.3.3 锁相关类:ReentrantLock, Condition, ReadWriteLock
`ReentrantLock`可以认为是`synchronized`的一种替代方式。`Condition`提供了条件变量的功能,它和锁配合使用,可以实现线程间的协作和等待/通知机制。`ReadWriteLock`允许多个读操作同时进行,但在写操作时,其他读或写操作被阻塞,从而提高了读操作的并发性。
```java
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReadWriteLock;
public class LockExample {
private final Lock lock = new ReentrantLock();
private final Condition condition = lock.newCondition();
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
// 实现复杂的线程协作逻辑...
}
```
锁相关的类提供了灵活的线程同步机制,使开发者可以更精细地控制多线程之间的交互。
至此,我们完成了对Java并发编程类库的探究,深入理解了线程的创建与管理,同步机制和高级并发工具类的使用。这些知识对于编写高效且安全的多线程Java程序至关重要。
# 5. Java常用工具类的实践应用
## 5.1 Java时间日期API
Java 8 引入了一个全新的日期时间API,解决了之前Joda Time库流行之前,Java日期时间处理的诸多问题。
### 5.1.1 Java 8之前的时间处理问题
在Java 8之前,我们主要依赖于`java.util.Date`和`java.util.Calendar`,但是它们有诸多不便之处:
- **易变性(Mutability)**:`Date`类和`Calendar`类都是可变的,这意味着你必须创建一个对象的副本,否则并发修改可能会导致意外的副作用。
- **线程不安全(Thread-safety)**:由于可变性,`Date`和`Calendar`也不是线程安全的。开发者需要负责同步,否则在多线程环境下可能会引发数据不一致问题。
- **API设计不合理**:旧的API不够直观,例如日期和时间的操作比较繁琐,不够灵活。
### 5.1.2 Java 8新的日期时间框架
Java 8引入了全新的日期时间API,位于`java.time`包中。新的API特点包括:
- **不可变性(Immutability)**:所有的日期时间类都是不可变的,例如`LocalDate`, `LocalTime`, `LocalDateTime`, `ZonedDateTime`等。
- **线程安全(Thread-safety)**:由于不可变性,新的日期时间类天然线程安全。
- **清晰的API设计**:新的API更加清晰和直观,提供了更加灵活的日期和时间操作。
### 5.1.3 时间日期API的国际化处理
`java.time`包还考虑到了国际化问题,可以轻松处理多种时区和日历系统:
- `ZonedDateTime`类可以处理不同时区的时间,`ZoneId`类表示时区。
- `Locale`类可以用于处理不同国家的日历系统。
代码示例:
```java
import java.time.LocalDate;
import java.time.ZoneId;
import java.time.ZonedDateTime;
import java.util.Locale;
public class DateTimeExample {
public static void main(String[] args) {
// 获取当前日期
LocalDate today = LocalDate.now();
System.out.println("Today's date: " + today);
// 指定时区获取当前时间
ZonedDateTime nowInNewYork = ZonedDateTime.now(ZoneId.of("America/New_York"));
System.out.println("Current date and time in New York: " + nowInNewYork);
// 国际化处理示例,使用不同的日历系统
System.out.println("Chinese New Year: " + LocalDate.now(Locale.CHINA));
}
}
```
## 5.2 Java正则表达式与Pattern类
正则表达式是用于匹配字符串中字符组合的模式,在文本处理中非常有用。
### 5.2.1 正则表达式的构成与用途
正则表达式包括普通字符(例如字母a到z)和特殊字符(称为"元字符")。它们可以组合以形成搜索模式,用途包括但不限于数据验证、文本搜索、替换及字符串分割。
### 5.2.2 Pattern类的编译和匹配方法
`Pattern`类是`java.util.regex`包中用于编译正则表达式的类,提供了编译和匹配的方法:
- `compile(String regex)`:编译给定的正则表达式。
- `matcher(CharSequence input)`:创建一个`Matcher`对象。
- `split(CharSequence input)`:根据匹配到的正则表达式将输入的字符串分割成多个子字符串。
代码示例:
```java
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class RegexExample {
public static void main(String[] args) {
// 编译正则表达式
Pattern pattern = ***pile("w3schools");
// 测试字符串
String testString = "***!";
// 创建Matcher对象
Matcher matcher = pattern.matcher(testString);
// 输出匹配结果
while (matcher.find()) {
System.out.println("Found value: " + matcher.group());
}
}
}
```
### 5.2.3 Matcher类的高级应用
`Matcher`类提供了许多用于高级文本搜索的方法,例如:
- `find()`:查找下一个匹配项。
- `group()`:返回最近一次匹配的字符串。
- `replaceAll(String replacement)`:替换匹配到的所有内容。
- `start()`和`end()`:返回匹配子字符串在原字符串中的起始和结束位置。
## 5.3 Java加密与安全类库
Java提供了全面的加密和安全类库,用于保证数据的安全性。
### 5.3.1 加密基础:算法与密钥管理
- **加密算法**:分为对称加密(例如AES)和非对称加密(例如RSA)。
- **密钥管理**:使用`KeyGenerator`生成密钥,`KeyStore`存储密钥。
### 5.3.2 消息摘要和数字签名的应用
- **消息摘要**:使用`MessageDigest`类生成数据的哈希值,如MD5, SHA系列。
- **数字签名**:结合公钥和私钥,使用`Signature`类验证数据的完整性和来源。
### 5.3.3 对称加密和非对称加密技术对比
对称加密速度快,但密钥分发复杂;非对称加密解决了密钥分发问题,但速度慢。两者通常结合使用,形成混合加密系统。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析了 Java 开发中必不可少的 JDK 自带类库,涵盖了基础类、集合框架、并发编程、反射机制、国际化管理、日志系统、正则表达式处理、流式 API 和监控类库等多个方面。通过对源码的解读和应用案例的分析,专栏旨在帮助开发者全面掌握这些类库的使用技巧,提升 Java 编程能力。从基础知识到高级应用,本专栏提供了全面的指南,助力开发者充分利用 JDK 类库的强大功能,打造高效、可靠的 Java 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PCM测试进阶必读:深度剖析写入放大和功耗分析的实战策略
# 摘要
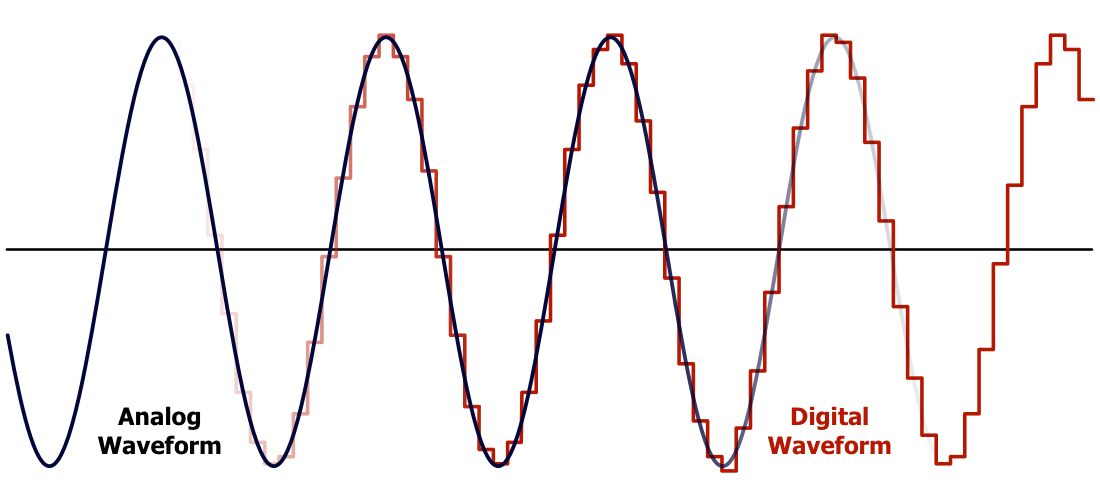
相变存储(PCM)技术作为一种前沿的非易失性存储解决方案,近年来受到广泛关注。本文全面概述了PCM存储技术,并深入分析了其写入放大现象,探讨了影响写入放大的关键因素以及对应的优化策略。此外,文章着重研究了PCM的功耗特性,提出了多种节能技术,并通过实际案例分析评估了这些技术的有效性。在综合测试方法方面,本文提出了系统的测试框架和策略,并针对测试结果给出了优化建议。最后,文章通过进阶案例研究,探索了PCM在特定应用场景中的表现,并探讨了
网络负载均衡与压力测试全解:NetIQ Chariot 5.4应用专家指南
# 摘要
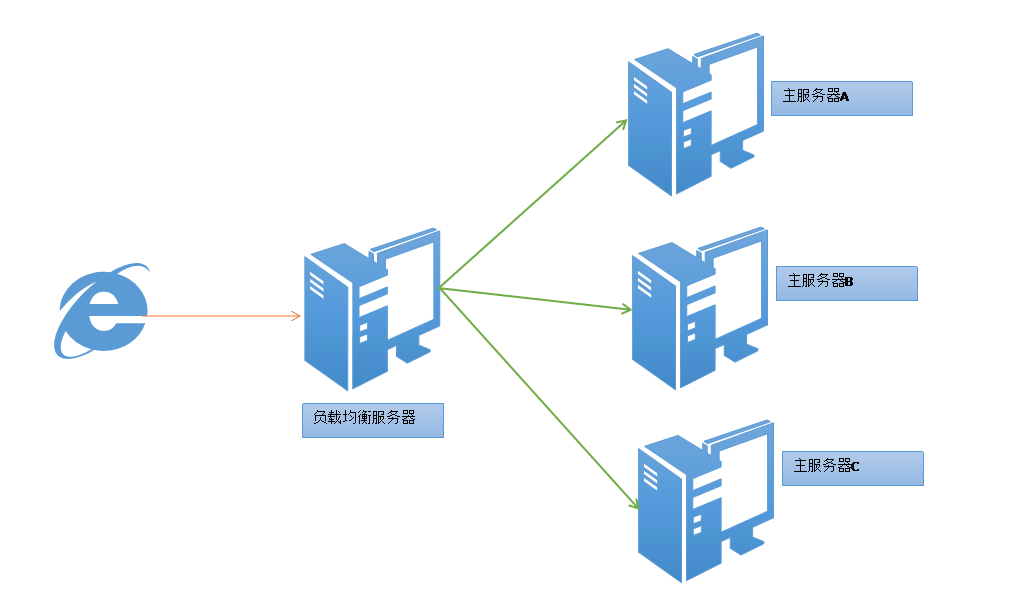
本文详细介绍了网络负载均衡的基础知识和NetIQ Chariot 5.4的部署与配置方法。通过对NetIQ Chariot工具的安装、初始化设置、测试场景构建、执行监控以及结果分析的深入讨论,展示了如何有效地进行性能和压力测试。此外,本文还探讨了网络负载均衡的高级应用,包括不同负载均衡策略、多协议支持下的性能测试,以及网络优化与故障排除技巧。通过案例分析,本文为网络管理员和技术人员提供了一套完整的网络性能提升和问
ETA6884移动电源效率大揭秘:充电与放电速率的效率分析

# 摘要
移动电源作为便携式电子设备的能源,其效率对用户体验至关重要。本文系统地概述了移动电源效率的概念,并分析了充电与放电速率的理论基础。通过对理论影响因素的深入探讨以及测量技术的介绍,本文进一步评估了ETA6884移动电源在实际应用中的效率表现,并基于案例研究提出了优化充电技术和改
深入浅出:收音机测试进阶指南与优化实战

# 摘要
本论文详细探讨了收音机测试的基础知识、进阶理论与实践,以及自动化测试流程和工具的应用。文章首先介绍了收音机的工作原理和测试指标,然后深入分析了手动测试与自动测试的差异、测试设备的使用和数据分析方法。在进阶应用部分,文中探讨了频率和信号测试、音质评价以及收音机功能测试的标准和方法。通过案例分析,本文还讨论了测试中常见的问题、解决策略以及自动化测试的优势和实施。最后,文章展望了收音机测试技术的未来发展趋势,包括新技术的应用和智能化测试的前
微波毫米波集成电路制造与封装:揭秘先进工艺
# 摘要
本文综述了微波毫米波集成电路的基础知识、先进制造技术和封装技术。首先介绍了微波毫米波集成电路的基本概念和制造技术的理论基础,然后详细分析了各种先进制造工艺及其在质量控制中的作用。接着,本文探讨了集成电路封装技术的创新应用和测试评估方法。在应用案例分析章节,本文讨论了微波毫米波集成电路在通信、感测与成像系统中的应用,并展望了物联网和人工智能对集成电路设计的新要求。最后,文章对行业的未来展望进
Z变换新手入门指南:第三版习题与应用技巧大揭秘

# 摘要
Z变换是数字信号处理中的核心工具,它将离散时间信号从时域转换到复频域,为分析和设计线性时不变系统提供强有力的数学手段。本文首先介绍了Z变换的基
Passthru函数的高级用法:PHP与Linux系统直接交互指南

# 摘要
本文详细探讨了PHP中Passthru函数的使用场景、工作原理及其进阶应用技巧。首先介绍了Passthru函数的基本概念和在基础交
【Sentaurus仿真调优秘籍】:参数优化的6个关键步骤

# 摘要
本文系统地探讨了Sentaurus仿真技术的基础知识、参数优化的理论基础以及实际操作技巧。首先介绍了Sentaurus仿真参数设置的基础,随后分析了优化过程中涉及的目标、原则、搜索算法、模型简化
【技术文档编写艺术】:提升技术信息传达效率的12个秘诀

# 摘要
本文旨在探讨技术文档编写的全过程,从重要性与目的出发,深入到结构设计、内容撰写技巧,以及用户测试与反馈的循环。文章强调,一个结构合理、内容丰富、易于理解的技术文档对于产品的成功至关重要。通过合理设计文档框架,逻辑性布局内容,以及应用视觉辅助元素,可以显著提升文档的可读性和可用性。此外,撰写技术文档时的语言准确性、规范化流程和读者意识的培养也是不可或缺的要
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )