【多GPU训练实战】:PyTorch图像识别并行计算的高效应用
发布时间: 2024-12-11 23:04:59 阅读量: 9 订阅数: 15 

实现SAR回波的BAQ压缩功能

# 1. 多GPU训练的基础知识
## 1.1 多GPU训练的必要性
随着深度学习模型复杂度的增加,单GPU训练已经不能满足大规模数据集和复杂模型的训练需求。多GPU训练能够并行处理数据和模型的计算任务,显著缩短训练时间,提升模型开发效率。此外,利用多GPU可以实现更大规模的模型训练,增强模型的表现力。
## 1.2 GPU与CPU的计算差异
GPU与CPU在设计之初就有着不同的目标,CPU擅长处理复杂的控制逻辑,而GPU则设计来处理并行数据计算任务。由于深度学习中大量存在重复的矩阵运算,GPU天然适合这类计算密集型任务。利用多GPU进行训练,可以将数据和模型分片并行计算,进而实现更高效的训练过程。
## 1.3 多GPU训练的挑战
尽管多GPU训练提供了强大的计算能力,但同时也带来了新的挑战。包括但不限于数据一致性问题、显存限制、网络通信开销以及代码复杂度增加等。接下来的章节将探讨如何在PyTorch框架中解决这些问题,并通过实例演示多GPU训练的具体实现方式。
```markdown
# 这是一级章节,紧接着我们进入二级章节
## 1.1 多GPU训练的必要性
这是二级章节的内容,将对多GPU训练的必要性进行说明。
## 1.2 GPU与CPU的计算差异
这一节将探讨GPU与CPU在处理深度学习任务中的差异。
## 1.3 多GPU训练的挑战
面对多GPU训练带来的挑战,我们需要了解并做好准备。
```
# 2. PyTorch中的并行计算原理
## 2.1 PyTorch并行计算概述
### 2.1.1 并行计算的重要性
在处理大规模深度学习任务时,单GPU的速度往往成为瓶颈。并行计算的引入可以显著提升数据处理和模型训练的速度,从而在更短的时间内得到结果。对于复杂模型而言,多GPU并行能够将模型分散到各个设备上,从而降低内存占用,提升模型的复杂度和处理能力。
在PyTorch中,数据并行(Data Parallelism)是一种常见的并行策略,通过将输入数据分散到多个GPU上,并且在每个GPU上复制模型,实现训练加速。同时,模型并行(Model Parallelism)则适用于模型过大无法完全放入单个GPU的情况,把模型的不同部分分散到不同的GPU上。
### 2.1.2 PyTorch的并行计算架构
PyTorch提供了多个API和工具来支持并行计算。以数据并行为例,PyTorch通过`torch.nn.DataParallel`模块使得开发者能够在多GPU环境中方便地进行模型训练。此外,PyTorch还提供了分布式数据并行(Distributed Data Parallel, DDP),它允许在多个节点上运行,并且能有效地处理大规模的模型训练。
为了更好地理解这些概念,可以查看以下的代码示例:
```python
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
# 创建一个简单的模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.conv = nn.Conv2d(1, 1, kernel_size=3)
self.fc = nn.Linear(10, 10)
def forward(self, x):
x = self.conv(x)
x = self.fc(x)
return x
# 实例化模型
model = SimpleModel()
# 使用DataParallel进行模型包装实现数据并行
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# 将模型转移到可用的GPU上
model = nn.DataParallel(model)
model.cuda()
# 模型并行的实现相对复杂,需要手动分配不同模块到不同的GPU
# 通常不是推荐的做法,除非模型极大,无法在单GPU上处理
```
在上述代码中,`SimpleModel`定义了一个简单的神经网络模型。如果系统中有多个GPU,我们通过`nn.DataParallel`对模型进行包装,并将模型转移到GPU上进行训练。
## 2.2 数据并行模型的构建
### 2.2.1 单GPU到多GPU数据流动
在单GPU的训练过程中,数据与模型在同一个GPU上进行交互。当引入多GPU后,数据需要被分配到各个GPU上。在PyTorch中,这一过程通过数据加载器(DataLoader)和数据并行模块(DataParallel)来实现。
首先,我们需要设置一个合适的数据加载器来遍历数据集,并将数据加载到内存中。然后,通过数据并行模块,数据会被均匀地分配到多个GPU上,每个GPU都会执行一次前向传播和反向传播操作,梯度更新会在所有GPU间同步。
以下是单GPU数据流动到多GPU数据流动的代码示例:
```python
# 单GPU数据流动
single_gpu_loader = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True)
for data, target in single_gpu_loader:
output = model(data)
loss = loss_fn(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 多GPU数据流动
data_loader = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True)
for data, target in data_loader:
data = data.cuda() # 将数据移动到第一个可用的GPU
output = model(data)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
```
### 2.2.2 数据并行的模型封装
在PyTorch中,要实现数据并行,通常需要将模型包裹在`nn.DataParallel`中。这样做会自动处理输入数据的分配和输出数据的收集,同时也会进行梯度的同步处理。对于开发者而言,只需要关注模型逻辑的实现,而无需关心并行的具体细节。
一个典型的封装方式如下:
```python
# 包装模型以实现数据并行
model = nn.DataParallel(model, device_ids=[0, 1, 2, 3]) # device_ids定义了哪些GPU将参与计算
model = model.cuda() # 将模型移动到第一个GPU
```
在上述代码中,`device_ids`参数指定了参与计算的GPU的ID,而`model.cuda()`则用于将模型移动到指定的GPU上。
## 2.3 模型并行与混合并行策略
### 2.3.1 模型并行的基本概念
模型并行主要适用于模型很大,无法全部装入单个GPU的情况。在模型并行中,模型的不同部分会被分散到不同的GPU上。这通常意味着需要自定义数据流动和梯度更新的逻辑,因为不同GPU间的模型部分需要相互通信。
模型并行通常复杂度较高,且对算法设计有较高的要求,因此一般情况下,除非模型特别庞大,通常优先考虑数据并行。
### 2.3.2 混合并行的方法与优势
混合并行是指数据并行和模型并行相结合的方法,该方法可以同时解决数据量过大和模型过大两个问题。例如,可以将模型的不同层放在不同的GPU上,同时将数据复制到每个GPU上进行并行处理。
混合并行的优势在于它可以充分利用GPU资源,提高处理大规模模型和数据的能力。然而,混合并行的编程复杂度较高,需要仔细设计数据流和通信模式,以减少网络通信的开销。
以下展示了如何在PyTorch中实现模型并行和混合并行的代码示例:
```python
# 模型并行示例
class ModelParallel(nn.Module):
def __init__(self):
super(ModelParallel, self).__init__()
self.module1 = ... # 第一个GPU上的模块
self.module2 = ... # 第二个GPU上的模块
def forward(self, x):
x = self.module1(x.cuda(0))
x = self.module2(x.cuda(1))
return x
# 混合并行示例
class DataAndModelParallel(nn.Module):
def __init__(self):
super(DataAndModelParallel, self).__init__()
self.module = nn.Sequential(
nn.DataParallel(MyModel1(), device_ids=[0, 1]),
nn.DataParallel(MyModel2(), device_ids=[2, 3])
)
def forward(self, x):
return self.module(x.cuda())
```
在`ModelParallel`类中,模型的不同部分被放在不同的GPU上;而在`DataAndModelParallel`类中,则是组合使用了数据并行和模型并行策略。需要注意的是,实际应用中,你需要根据模型的结构和数据的大小来灵活设计并行策略。
到此为止,我们已经介绍了PyTorch中并行计算的概述,包括数据并行和模型并行的基本概念以及构建方法。在下一章节中,我们将深入到多GPU训练的实践技巧中,探讨环境配置、代码实现、性能调优和故障排查等实际操作问题。
# 3. 多GPU训练的实践技巧
在多GPU训练的实践中,环境搭建与配置、代码实现以及性能调优与故障排查是三个关键环节。本章将深入探讨这些环节的详细步骤和技巧,以及在实际操作中需要注意的事项。
## 3.1 环境搭建与配置
### 3.1.1 硬件环境要求
在搭建多GPU训练环境之前,首先需要具备合适的硬件支持。多GPU训练要求至少有两个或更多的NVIDIA GPU卡,这些GPU卡需要具备足够的显存来满足模型训练的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面涵盖了使用 PyTorch 进行图像识别的各个方面,从基础知识到高级技巧。它提供了分步指南,介绍如何使用迁移学习提高图像识别精度,并深入探讨了自定义数据集、训练策略和数据加载器优化等主题。此外,该专栏还介绍了 GPU 加速、多 GPU 训练和深度学习硬件加速等技术,以提高训练速度和模型性能。对于希望使用 PyTorch 进行图像识别的初学者和经验丰富的从业者来说,本专栏都是宝贵的资源。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MPS-MP2315芯片性能参数揭秘:深度分析与应用技巧
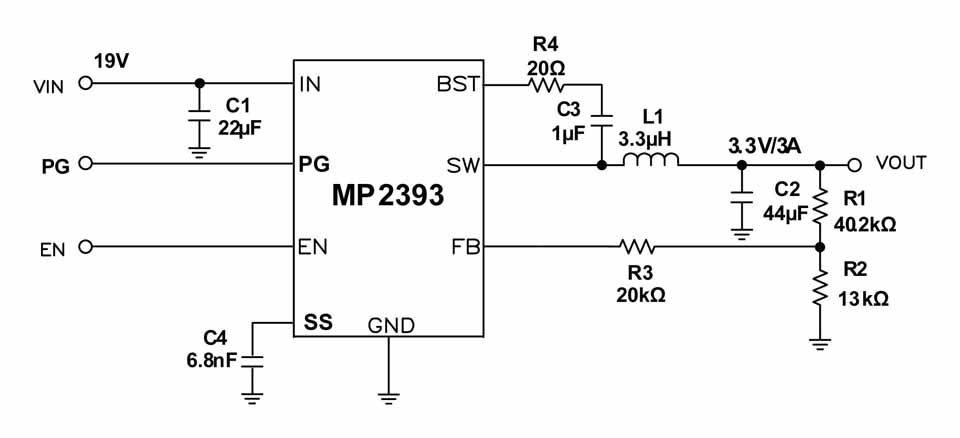
参考资源链接:[MP2315高效能3A同步降压转换器技术规格](https://wenku.csdn.net/doc/87z1cfu6qv?spm=1055.2635.3001.10343)
# 1. MPS-MP2315芯片概述
MPS-MP2315是一颗由MicroProcessor Solutions(MPS)公司设计的高性能微处理器芯片,它不仅具备强大的数据处理能力,还具有高效的电源
解析网络RTK性能的秘密:RTCM 3.3协议的影响力分析
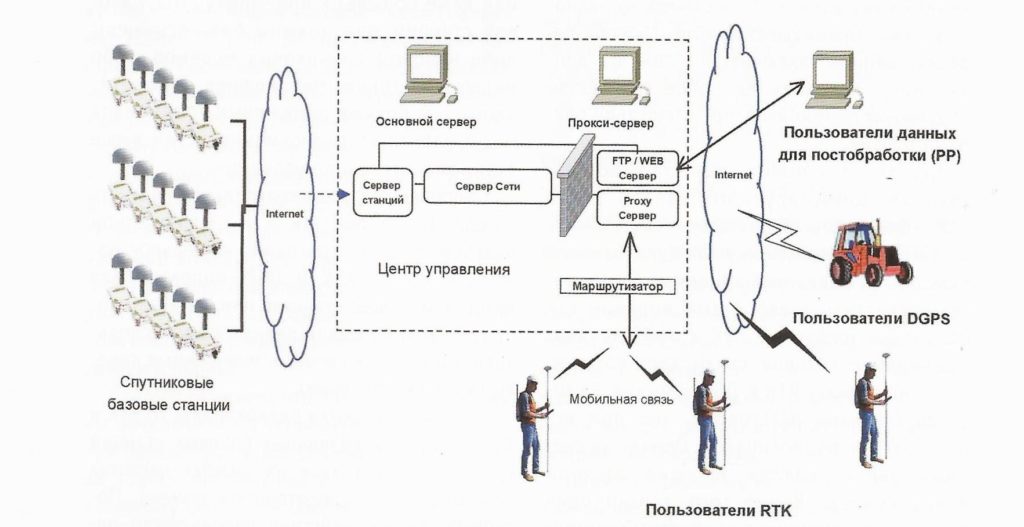
参考资源链接:[RTCM 3.3协议详解:全球卫星导航系统差分服务最新标准](https://wenku.csdn.net/doc/7mrszjnfag?spm=1055.2635.3001.10343)
# 1. RTCM 3.3协议简介
RTCM(Radio Technical Commission for Maritime Services)3.3协议是
北航2020预推免笔试题实战演练:3个代码效率优化杀手锏
参考资源链接:[北航2020自动化预推免硕士笔试真题解析](https://wenku.csdn.net/doc/6401ac50cce7214c316eb65c?spm=1055.2635.3001.10343)
# 1. 代码效率优化概述
软件开发中,代码效率优化是提高程序性能、降低资源消耗的关键环节。它不仅涉及算法和数据结构的选择,还包括编译器优化、系统级调优等多个方面。在现代编程实践中,理解和应用代码效率优化的概念,可以显著提升软件质量,延长产品生命周期,并在竞争激烈的市场中占据优势。
代码效率优化的目的是为了让程序在执行时占用更少的计算资源,如CPU时间、内存使用、磁盘I/O等,
【硬件抽象层(HAL)完全手册】:深度解读PCIe 5.40a版本中的关键概念

参考资源链接:[2019 Synopsys PCIe Endpoint Databook v5.40a:设计指南与版权须知](https://wenku.csdn.net/
S32DS编译器配置秘籍:从零开始的{8

参考资源链接:[S32DS编译器官方指南:快速入门与项目设置](https://wenku.csdn.net/doc/6401abd2cce7214c316e9a18?spm=1055.2635.3001.10343)
# 1. S32DS编译器概述与安装
## 1.1 S32DS编译器简介
S32DS(S32 Design Studio)是一款专为NXP的S32微控制器系列设计的集成开发环境(IDE)。它整合了处理器专家系统、图形化
【MATLAB App Designer精通之路】:从零基础到高级应用开发,提升你的开发效率
参考资源链接:[MATLAB App Designer 全方位教程:GUI设计与硬件集成](https://wenku.csdn.net/doc/6412b76abe7fbd1778d4a38a?spm=1055.2635.3001.10343)
# 1. MATLAB App Designer简介与安装
MATLAB App Designer是一个强大的工具,用于创建交互式的MATLAB应用程序。它是MATLAB的集成开发环境(IDE)中的一部分,提供了一套可视化界面设计和编程的组件,使得开发自定义的应用程序成为可能。本章将介绍App Designer的基本概念,以及如何进行安装和配置,为
【ROST软件升级解析】:新特性与改进点全览

参考资源链接:[ROST内容挖掘系统V6用户手册:功能详解与操作指南](https://wenku.csdn.net/doc/5c20fd2fpo?spm=1055.2635.3001.10343)
# 1.
【毫米波技术革命】:掌握mmWave Studio,入门到精通全攻略
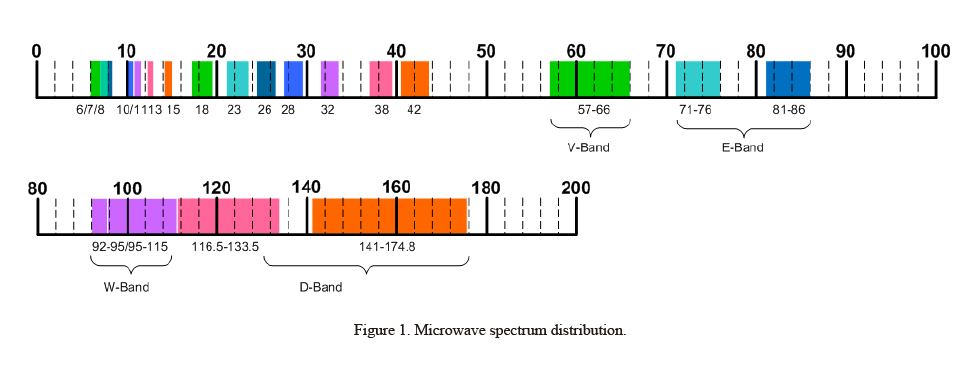
参考资源链接:[TI mmWave Studio用户指南:安装与功能详解](https://wenku.csdn.net/doc/3moqmq4ho0?spm=1055.2635.3001.10343)
# 1. 毫米波
架构愿景构建速成课:TOGAF 9.2中文版第二章的权威解读与案例分析
参考资源链接:[TOGAF9.2中文版(第二章).pdf](https://wenku.csdn.net/doc/6401acb5cce7214c316ecd6d?spm=1055.2635.3001.10343)
# 1. TOGAF 9.2架构愿景概述
在企业架构的世界里,架构愿景为组织提供
【Python量化交易高级教程】:时间序列分析,打造盈利策略

参考资源链接:[Python量化交易实战:从入门到精通](https://wenku.csdn.net/doc/7rp5f8e8m
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )