【爬虫中的分布式存储】:Redis与MongoDB优化数据存储的策略


分布式爬虫处理Redis里的数据操作步骤
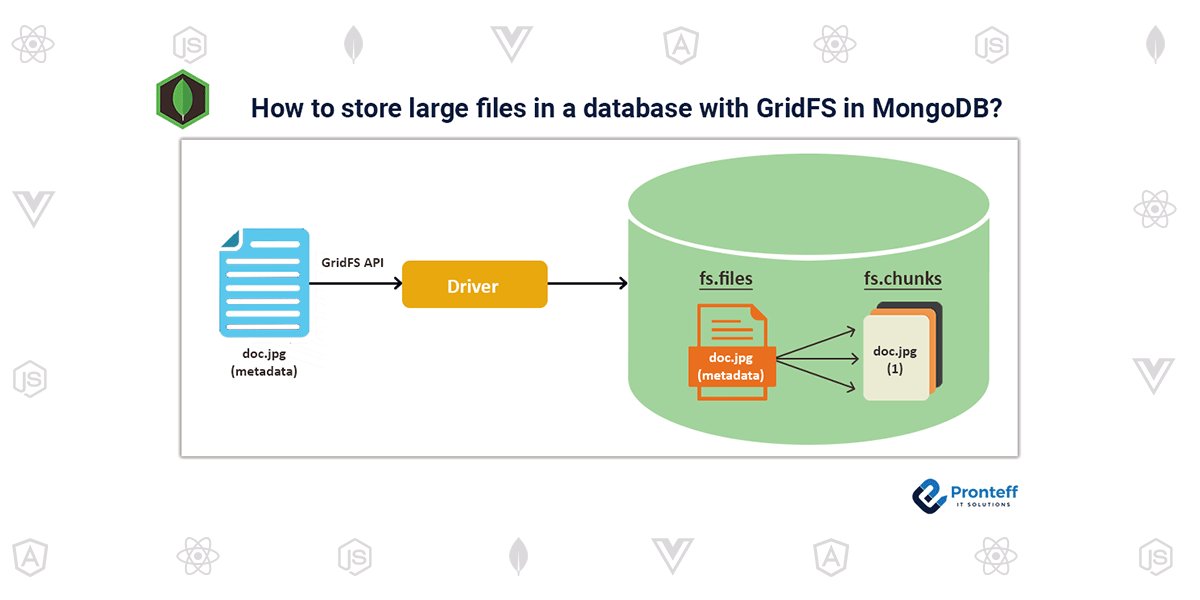
1. 爬虫数据存储的挑战
在当今互联网信息爆炸的时代,爬虫技术成为了获取大量数据的有效工具。但随之而来的数据存储问题也日益凸显。存储爬虫数据面临的挑战主要包括数据量巨大、存储介质选择困难、数据更新频繁以及高可用性和扩展性的需求。传统的存储方案很难满足这些需求,因此,如何高效、稳定地存储和管理爬虫数据,成为了IT行业中的一个技术热点。
数据规模与存储介质
爬虫应用往往会生成海量的数据。这些数据不仅量大,而且增长速度极快,这对于存储介质提出了极高的要求。对于海量数据,传统的关系型数据库可能在性能和成本上都无法满足需求。因此,我们可能需要考虑使用NoSQL数据库,例如Redis和MongoDB,它们提供了更好的水平扩展性和更灵活的数据模型。
数据更新与一致性问题
爬虫数据通常需要频繁更新,这就要求存储系统能够快速响应数据的变化。同时,数据的一致性和完整性也是不可忽视的问题。在分布式存储环境中,如何确保数据在多个节点间保持一致,是设计存储解决方案时必须要考虑的问题。
高可用性与扩展性
随着业务量的增加,爬虫系统可能需要在短时间内处理更多的请求,这就要求存储系统能够提供高可用性和良好的扩展性。分布式存储系统由于其天然的冗余性和容错性,成为了优先考虑的解决方案。
针对这些挑战,本文后续章节将分别探讨Redis和MongoDB的优化策略,分布式存储的实践技巧,以及未来技术的发展趋势与展望,旨在为爬虫数据存储提供全方位的解决方案。
2. Redis优化策略
Redis是一个开源的高性能key-value数据库,广泛应用于各种互联网业务中,包括爬虫数据存储。考虑到Redis的高效读写性能和丰富的数据结构,优化Redis对于提升爬虫系统的性能至关重要。
2.1 Redis的基本概念与应用
2.1.1 Redis数据结构基础
Redis支持五种基本数据结构:字符串(String)、哈希(Hash)、列表(List)、集合(Set)和有序集合(Sorted Set)。每种数据结构都有自己独特的用例和优化策略。
字符串(String)是最基本的数据类型,可以包含任何数据,比如jpg图片或者序列化的对象。字符串主要通过 SET 和 GET 命令操作。
哈希(Hash)是一个由字段(field)和值(value)组成的数据结构,特别适合存储对象。HSET 和 HGET 命令用于操作哈希。
列表(List)由多个字符串元素组成,按照插入顺序排序。LPUSH 和 LRANGE 可以用于添加和获取列表元素。
集合(Set)是字符串的无序集合,不允许重复元素。通过 SADD 和 SMEMBERS 可以添加和获取集合成员。
有序集合(Sorted Set)类似于集合,但是每个元素都关联一个浮点数值(分数)。通过 ZADD 和 ZRANGE 可以添加和获取有序集合元素。
2.1.2 Redis在爬虫中的应用实例
在爬虫应用中,我们可以利用Redis的高性能读写特点,快速存储和查询URL队列。例如,爬虫可以使用List结构存储待爬取的URL,使用LPUSH添加URL,使用BRPOP命令阻塞式地获取URL,然后进行页面抓取。
- # 示例:使用Redis的List存储和处理URL队列
- import redis
- # 连接到Redis
- r = redis.Redis(host='localhost', port=6379, db=0)
- # 添加URL到队列
- r.lpush('url_queue', '***')
- # 获取并弹出队列中的URL
- url = r.brpop('url_queue', 0)
在这个例子中,lpush 方法将一个URL添加到名为 url_queue 的列表头部。brpop 方法用于阻塞式地从列表尾部弹出一个URL,0 表示无限等待直到有元素可弹出。这样的设计可以有效管理URL队列,同时提高爬取效率。
2.2 Redis的性能优化
2.2.1 数据持久化策略
Redis提供了两种数据持久化方式:RDB(Redis Database)和AOF(Append Only File)。RDB通过创建数据集的快照来存储数据,适合备份和灾难恢复。AOF则是记录所有对Redis数据库的写操作,适用于需要数据完整性的场景。
为了提高持久化效率,可以考虑将Redis和持久化文件放在不同硬盘,或者通过调整自动保存规则(save 配置项),以减少磁盘写操作的频率。
2.2.2 内存管理和优化技巧
内存管理对于Redis性能至关重要。Redis默认使用所有可用内存,并且使用LRU算法来移除过期的键。合理的内存分配和键的过期策略能够提升Redis性能。
通过 CONFIG SET maxmemory 可以设置Redis使用的最大内存。另外,可以使用 CONFIG SET maxmemory-policy 来设置内存淘汰策略,例如 allkeys-lru 会移除最近最少使用的键。
2.2.3 集群部署与横向扩展
当单机Redis无法满足大规模数据和访问量需求时,可以考虑使用Redis集群。Redis集群通过分片将数据分布在不同的节点上,并提供高可用性和水平扩展能力。
集群部署需要考虑节点间的数据一致性和故障转移。Redis集群使用一致性哈希算法来分配键到不同的节点,并且提供了主从复制和哨兵系统来实现故障转移。
如上面的mermaid流程图所示,数据在主节点进行写操作,并且从节点复制数据。当主节点发生故障时,从节点可以进行故障转移成为新的主节点,以保证服务的连续性。
2.3 Redis的安全性和稳定性
2.3.1 访问控制和认证
Redis默认没有开启认证,可以使用 requirepass 配置项设置密码,对客户端连接进行认证。
- CONFIG SET requirepass "your_password"
配置

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SQL查询优化技巧:专家解读减少资源消耗的7个实用策略
【预防与故障排除】:MapGIS点属性编辑问题的全面应对方案
【技术革新】:三维元胞自动机在林火蔓延模拟中的新应用
【流程审计攻略】:APQC框架下的高效流程管理关键
【数字取证高手】:CTF中的Forensics案例 - 线索追踪与分析实践
【MT8880芯片数据手册:硬件规格解读全攻略】
零极点分析进阶指南:提升IDL编程效率的黄金法则
【iOS & Android应用下载新策略】:优化H5唤起与安装流程的秘诀
【设计模式的终极指南】:心算大师游戏架构的秘密武器
【屏幕亮度调整】:正确护眼的打开方式


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )










