BurpSuite中的Sequencer的使用与高级技巧
发布时间: 2023-12-21 06:59:26 阅读量: 44 订阅数: 41 
# 第一章:BurpSuite简介与Sequencer概述
1.1 BurpSuite简介
1.2 Sequencer的作用和原理
1.3 Sequencer的功能和优势
## 第二章:Sequencer的基本用法
2.1 设置和启动Sequencer
2.2 理解Sequencer分析的原理和流程
2.3 数据收集和处理
### 第三章:Sequencer的高级技巧
在本章中,我们将深入探讨如何运用Sequencer的高级技巧来优化和定制配置,处理大规模数据以及利用高级统计和分析功能。
#### 3.1 优化和定制Sequencer配置
在使用Sequencer时,通过优化和定制配置可以提高数据分析的效率和准确性。可以通过设置不同的选项和参数来定制Sequencer的行为,比如调整采样率、设置分析的数据长度、选择不同的统计算法等。下面我们以Python语言为例,展示如何使用BurpSuite的API来实现优化和定制Sequencer配置的过程:
```python
from burp import IBurpExtender
from burp import ITab
from burp import IContextMenuFactory
from burp import IContextMenuInvocation
from java.awt import Component
from javax.swing import JMenuItem
# 实现IBurpExtender接口
class BurpExtender(IBurpExtender, ITab, IContextMenuFactory):
def registerExtenderCallbacks(self, callbacks):
self._callbacks = callbacks
self._helpers = callbacks.getHelpers()
callbacks.setExtensionName("Sequencer Customizer")
# ...
# 在菜单中创建"Customize Sequencer"选项
def createMenuItems(self, invocation):
self._invocation = invocation
menu_list = []
menu_list.append(JMenuItem("Customize Sequencer", actionPerformed = self.customizeSequencer))
return menu_list
# 当"Customize Sequencer"选项被点击时执行的操作
def customizeSequencer(self, event):
# 根据菜单操作定制Sequencer配置
sequencer = self._callbacks.createBurpSequencer()
sequencer.setConfigurationOption1(value1)
sequencer.setConfigurationOption2(value2)
# ...
```
以上代码演示了如何创建一个BurpSuite的扩展插件来定制Sequencer的配置,通过创建菜单项并实现菜单点击事件来调整Sequencer的参数。
#### 3.2 处理大规模数据的技巧
在处理大规模数据时,Sequencer可以通过一些技巧来提高分析效率和降低资源消耗。比如可以对数据进行采样处理,设置合理的分析时间窗口,利用多线程并行处理等。接下来,我们通过Java语言来演示如何使用多线程处理大规模数据:
```java
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class SequencerDataProcessor {
public void processDataInParallel(byte[] data) {
// 分割数据
List<byte[]> chunks = splitDataIntoChunks(data);
// 创建固定大小的线程池
ExecutorService executor = Executors.newFixedThreadPool(4);
for (byte[] chunk : chunks) {
executor.submit(() -> {
// 调用Sequencer分析每个数据块
Sequencer.analyzeData(chunk);
});
}
// 关闭线程池
executor.shutdown();
}
private List<byte[]> splitDataIntoChunks(byte[] data) {
// 代码省略,根据需求对数据进行分割
}
}
```
在上面的示例中,我们利用Java的ExecutorService创建了一个固定大小的线程池,然后将数据块分别提交给线程池中的线程来并行处理,从而加快数据分析的速度。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将全面介绍BurpSuite工具在渗透测试和安全评估中的应用技巧和高级功能。从BurpSuite的简介与安装开始,一直到深入探讨代理和拦截器的使用、站点地图与目标、扫描器与漏洞扫描、主动与被动扫描等方面的内容。通过对Proxy History、Repeater、Intruder、Sequencer等工具的使用与高级技巧的讲解,帮助读者掌握BurpSuite的高级功能。此外,还将涉及Decoder和Comparer的应用、Extender的开发与应用、Session Handling与Session Token攻击、Target Analyzer的使用与原理分析等内容。最后,将深入探讨Repeater远程注入、SQL注入攻击、Intruder高级参数与Payload的研究、Extender开发进阶与自定义插件、API定制与高级应用以及数据分析与特定漏洞利用等主题。通过本专栏的学习,读者将全面掌握BurpSuite工具的使用技巧,并能够在实际的渗透测试和安全评估中灵活应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
图像处理中的正则化应用:过拟合预防与泛化能力提升策略

# 1. 图像处理与正则化概念解析
在现代图像处理技术中,正则化作为一种核心的数学工具,对图像的解析、去噪、增强以及分割等操作起着至关重要
大规模深度学习系统:Dropout的实施与优化策略
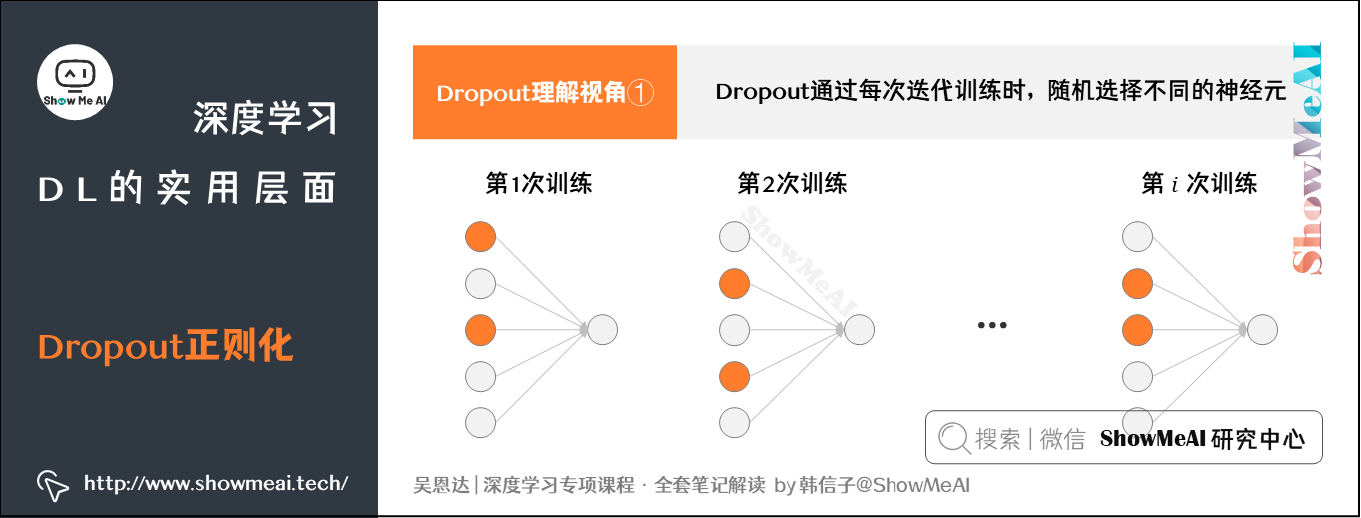
# 1. 深度学习与Dropout概述
在当前的深度学习领域中,Dropout技术以其简单而强大的能力防止神经网络的过拟合而著称。本章旨在为读者提供Dropout技术的初步了解,并概述其在深度学习中的重要性。我们将从两个方面进行探讨:
首先,将介绍深度学习的基本概念,明确其在人工智能中的地位。深度学习是模仿人脑处理信息的机制,通过构建多层的人工神经网络来学习数据的高层次特征,它已
预测建模精准度提升:贝叶斯优化的应用技巧与案例

# 1. 贝叶斯优化概述
贝叶斯优化是一种强大的全局优化策略,用于在黑盒参数空间中寻找最优解。它基于贝叶斯推理,通过建立一个目标函数的代理模型来预测目标函数的性能,并据此选择新的参数配置进行评估。本章将简要介绍贝叶斯优化的基本概念、工作流程以及其在现实世界
推荐系统中的L2正则化:案例与实践深度解析
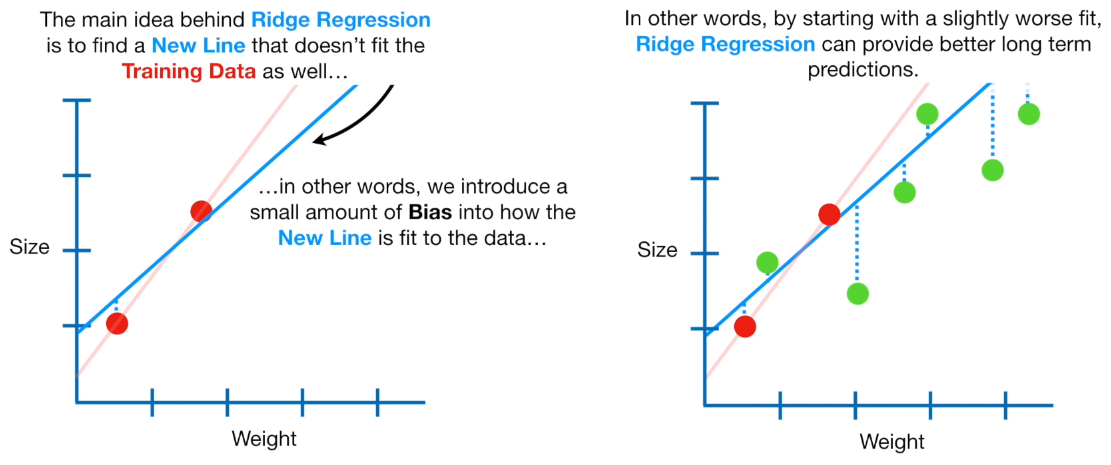
# 1. L2正则化的理论基础
在机器学习与深度学习模型中,正则化技术是避免过拟合、提升泛化能力的重要手段。L2正则化,也称为岭回归(Ridge Regression)或权重衰减(Weight Decay),是正则化技术中最常用的方法之一。其基本原理是在损失函数中引入一个附加项,通常为模型权重的平方和乘以一个正则化系数λ(lambda)。这个附加项对大权重进行惩罚,促使模型在训练过程中减小权重值,从而达到平滑模型的目的。L2正则化能够有效地限制模型复
【Lasso回归与岭回归的集成策略】:提升模型性能的组合方案(集成技术+效果评估)
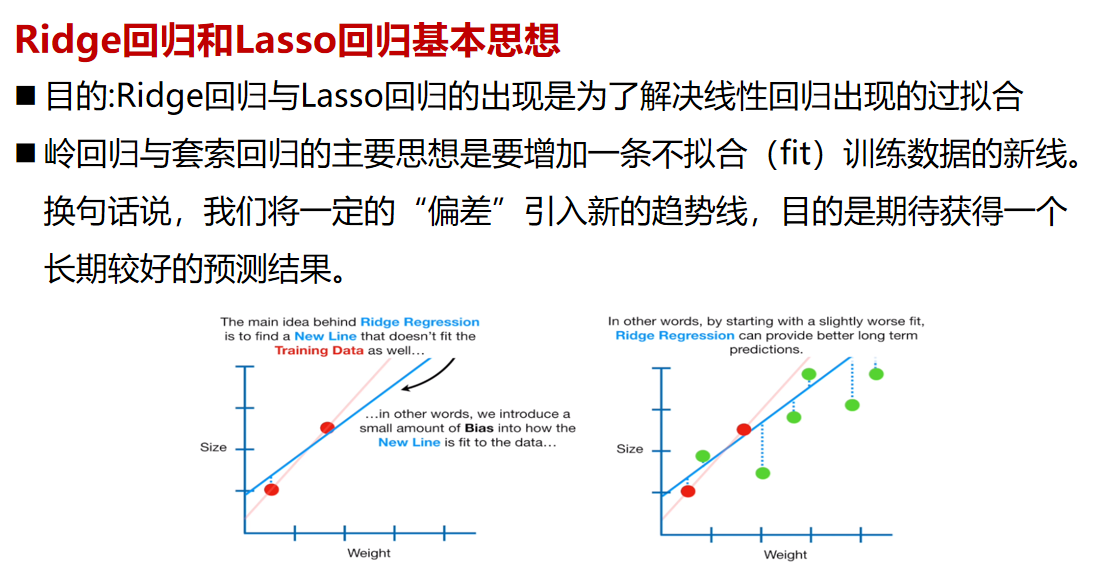
# 1. Lasso回归与岭回归基础
## 1.1 回归分析简介
回归分析是统计学中用来预测或分析变量之间关系的方法,广泛应用于数据挖掘和机器学习领域。在多元线性回归中,数据点拟合到一条线上以预测目标值。这种方法在有多个解释变量时可能会遇到多重共线性的问题,导致模型解释能力下降和过度拟合。
## 1.2 Lasso回归与岭回归的定义
Lasso(Least
如何用假设检验诊断机器学习模型的过拟合,专家教程

# 1. 假设检验在机器学习中的基础介绍
在数据科学领域,假设检验是一个重要的统计工具,用于确定研究中的观察结果是否具有统计学意义,从而支持或反对某个理论或模型的假设。在机器学习中,假设检验可以帮助我们判断模型的预测是否显著优于随机猜测,以及模型参数的变化是否导致性能的显著改变。
机器学习模型的性能评估常常涉及到多个指标,比如准确率、召回率、F1分数等。通过
自然语言处理中的过拟合与欠拟合:特殊问题的深度解读
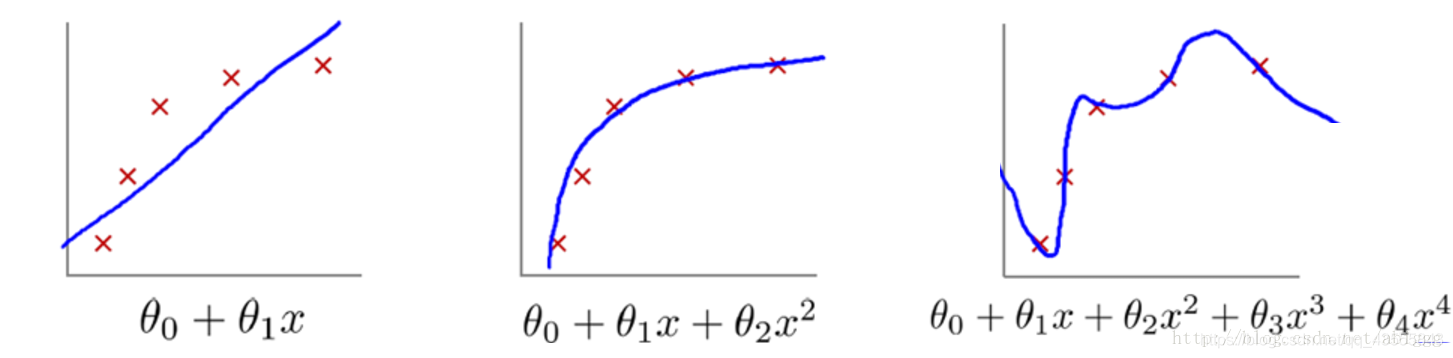
# 1. 自然语言处理中的过拟合与欠拟合现象
在自然语言处理(NLP)中,过拟合和欠拟合是模型训练过程中经常遇到的两个问题。过拟合是指模型在训练数据上表现良好
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
机器学习调试实战:分析并优化模型性能的偏差与方差
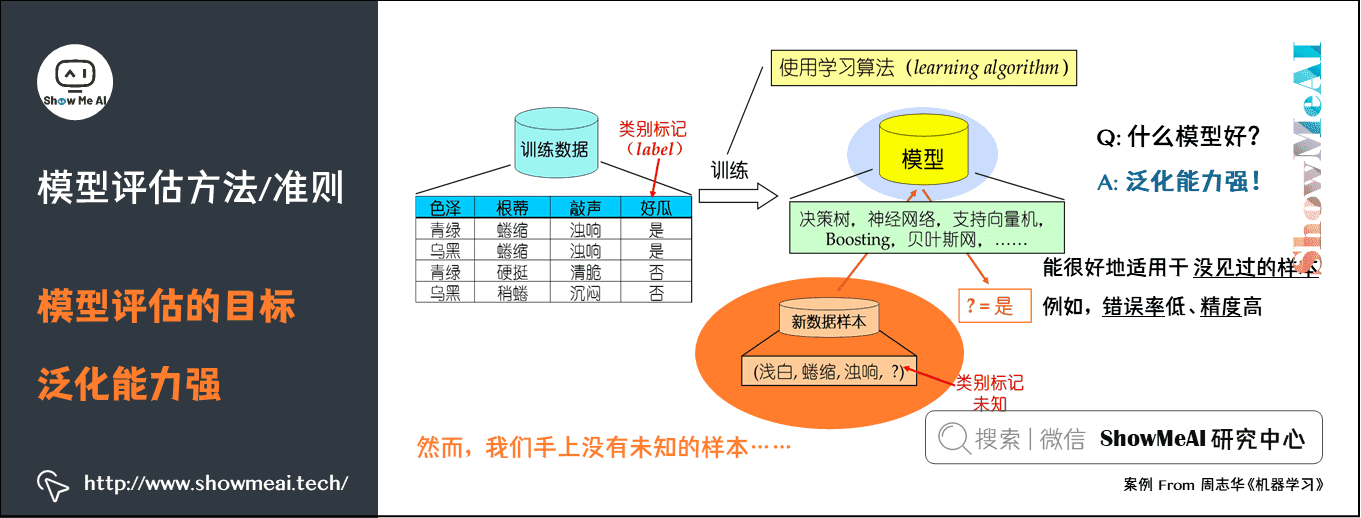
# 1. 机器学习调试的概念和重要性
## 什么是机器学习调试
机器学习调试是指在开发机器学习模型的过程中,通过识别和解决模型性能不佳的问题来改善模型预测准确性的过程。它是模型训练不可或缺的环节,涵盖了从数据预处理到最终模型部署的每一个步骤。
## 调试的重要性
有效的调试能够显著提高模型的泛化能力,即在未见过的数据上也能作出准确预测的能力。没有经过适当调试的模型可能无法应对实
【过拟合克星】:网格搜索提升模型泛化能力的秘诀

# 1. 网格搜索在机器学习中的作用
在机器学习领域,模型的选择和参数调整是优化性能的关键步骤。网格搜索作为一种广泛使用的参数优化方法,能够帮助数据科学家系统地探索参数空间,从而找到最佳的模型配置。
## 1.1 网格搜索的优势
网格搜索通过遍历定义的参数网格,可以全面评估参数组合对模型性能的影响。它简单直观,易于实现,并且能够生成可重复的实验结果。尽管它在某些
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )