【Python文件比较全攻略】:掌握filecmp,提升代码效率与安全性
发布时间: 2024-10-16 20:01:47 阅读量: 54 订阅数: 20 
# 1. 文件比较的基础知识与Python中的filecmp模块
文件比较是IT行业中常见的一项任务,用于检测两个文件或目录是否相同,以及它们之间存在哪些差异。这种比较对于版本控制、代码审查、数据同步等多个领域都至关重要。在Python中,`filecmp`模块提供了一种简单而有效的方式来比较文件和目录。
## 1.1 文件比较的基本概念
在深入探讨`filecmp`模块之前,我们需要了解文件比较的基本概念。文件比较主要分为两种类型:**浅比较**和**深比较**。浅比较仅比较文件的元数据(如大小、修改时间等),而深比较则会检查文件内容的每一个字节是否完全相同。
## 1.2 filecmp模块简介
Python的`filecmp`模块是处理文件比较问题的一个内置模块,它提供了多种方法来进行文件和目录的比较。该模块使用C语言编写,因此在性能上有不错的表现,适合在自动化脚本和程序中使用。
## 1.3 模块导入与主要函数介绍
要使用`filecmp`模块,首先需要将其导入到我们的Python脚本中。基本的导入方式如下:
```python
import filecmp
```
这个模块中最重要的函数是`cmp`,它可以用来比较两个文件是否相同:
```python
filecmp.cmp('file1', 'file2')
```
此函数返回一个布尔值,如果两个文件相同,则返回`True`,否则返回`False`。
通过了解这些基础知识,我们可以开始探索`filecmp`模块更高级的功能,以及如何将其应用于实际的文件比较任务中。
# 2. 深入理解filecmp模块的工作原理
在本章节中,我们将深入探讨Python中的filecmp模块,这个模块提供了简单的方法来比较文件或者目录。我们将从基本用法开始,逐步深入到高级特性,并最终探讨性能考量。通过本章节的介绍,你将能够充分理解filecmp模块的工作原理,并能够有效地应用它来满足你的文件比较需求。
## 2.1 filecmp模块的基本用法
### 2.1.1 模块导入与主要函数介绍
在Python中,filecmp模块不需要额外安装,可以直接通过import语句导入使用。这个模块提供了几个核心函数,其中最主要的两个是`cmp()`和`cmpfiles()`。`cmp()`函数用于比较两个文件,而`cmpfiles()`则用于比较两个目录中的多个文件。
```python
import filecmp
# 比较两个文件
def compare_files(file1, file2):
result = filecmp.cmp(file1, file2)
print(f"The files {file1} and {file2} are {'identical' if result else 'different'}.")
# 比较两个目录中的文件
def compare_directories(dir1, dir2, files):
results = filecmp.cmpfiles(dir1, dir2, files)
print(f"Files that are different: {list(filter(None, results[2]))}")
```
在上面的代码中,`cmp()`函数返回True如果两个文件相同,否则返回False。`cmpfiles()`返回一个三元组,其中包含所有相同的文件列表、不同文件列表和无法访问的文件列表。
### 2.1.2 文件和目录的比较方法
使用`cmp()`函数比较单个文件,而使用`cmpfiles()`函数比较目录中的多个文件。这些方法可以递归地比较整个目录结构。
```python
import os
# 比较两个目录
def compare_directories_recursively(dir1, dir2):
results = filecmp.dircmp(dir1, dir2)
***mon_files:
print(f"Common files: {***mon_files}")
***mon_dirs:
print(f"Common subdirectories: {***mon_dirs}")
if results.diff_files:
print(f"Different files: {results.diff_files}")
for common_***mon_dirs:
compare_directories_recursively(
os.path.join(dir1, common_dir),
os.path.join(dir2, common_dir)
)
```
在上面的代码中,`dircmp()`函数用于比较两个目录,并提供了递归比较的方法。它返回一个`dircmp`对象,其中包含了比较结果的信息。
## 2.2 深入filecmp的高级特性
### 2.2.1 忽略元数据的比较
filecmp模块提供了高级选项来忽略文件的元数据,如修改时间、权限等。这可以通过使用`cmpfiles()`函数和传递额外的参数来实现。
```python
import time
# 创建文件并设置不同的修改时间
file1 = 'file1.txt'
file2 = 'file2.txt'
with open(file1, 'w') as f:
f.write('Test')
time.sleep(1) # 等待一秒确保时间戳不同
with open(file2, 'w') as f:
f.write('Test')
# 忽略修改时间进行比较
def compare_files_ignore_metadata(file1, file2):
results = filecmp.cmp(file1, file2, shallow=False)
print(f"Files are {'identical' if results else 'different'}.")
compare_files_ignore_metadata(file1, file2)
```
在上面的代码中,`cmp()`函数的`shallow`参数被设置为`False`,这意味着比较会忽略文件的元数据。默认情况下,`shallow`参数为`True`,比较会考虑文件的元数据。
### 2.2.2 深度比较(递归比较)
深度比较指的是递归地比较两个目录,包括它们的所有子目录。这可以通过使用`dircmp()`类和其`report()`方法来实现。
```python
def deep_compare_directories(dir1, dir2):
results = filecmp.dircmp(dir1, dir2)
print(f"Common subdirectories: {***mon_dirs}")
print(f"Subdirectories that only appear in {dir1}: {results.left_only}")
print(f"Subdirectories that only appear in {dir2}: {results.right_only}")
print(f"Files that differ: {results.diff_files}")
print(f"Files that are in both directories but have different metadata: {results.diff_files}")
for common_***mon_dirs:
deep_compare_directories(
os.path.join(dir1, common_dir),
os.path.join(dir2, common_dir)
)
```
在上面的代码中,`dircmp()`类用于比较两个目录,并且可以通过递归调用来比较子目录。`report()`方法会打印出比较的总结报告。
## 2.3 filecmp模块的性能考量
### 2.3.1 比较速度的优化
filecmp模块在比较大量文件时可能会遇到性能瓶颈。为了优化比较速度,可以考虑使用缓存或者并行处理。
```python
import concurrent.futures
# 使用线程池来并行比较文件
def compare_files_in_pool(files):
with concurrent.futures.ThreadPoolExecutor() as executor:
results = list(executor.map(lambda f: filecmp.cmp(*f), files))
return results
# 示例文件列表
files_to_compare = [
('file1.txt', 'file2.txt'),
('file3.txt', 'file4.txt'),
('file5.txt', 'file6.txt'),
]
# 获取比较结果
results = compare_files_in_pool(files_to_compare)
print(f"Comparison results: {results}")
```
在上面的代码中,`concurrent.futures.ThreadPoolExecutor`用于创建一个线程池,`map()`函数并行地比较多个文件。这样可以显著提高比较大量文件时的效率。
### 2.3.2 大文件和大量文件的比较策略
对于大文件和大量文件的比较,可以采用分块比较的策略。这意味着将大文件分成多个小块,然后比较每个小块。
```python
import hashlib
# 分块比较文件
def chunk_compare(file1, file2, chunk_size=1024):
with open(file1, 'rb') as f1, open(file2, 'rb') as f2:
while True:
chunk1 = f1.read(chunk_size)
chunk2 = f2.read(chunk_size)
if chunk1 != chunk2:
return False
if not chunk1:
return True
# 检查两个大文件是否相同
def check_large_files(file1, file2):
result = chunk_compare(file1, file2)
print(f"The large files {file1} and {file2} are {'identical' if result else 'different'}.")
check_large_files('large_file1.txt', 'large_file2.txt')
```
在上面的代码中,`chunk_compare()`函数将两个文件分成多个小块进行比较。如果所有块都相同,那么可以认为两个文件是相同的。这种方法可以避免将整个文件内容加载到内存中,特别适合处理大文件。
在本章节中,我们深入探讨了Python中filecmp模块的基本用法、高级特性以及性能考量。通过实例代码和具体的解释,我们展示了如何使用这个模块来比较文件和目录,以及如何优化比较过程以适应不同的需求。在下一章节中,我们将通过实践案例来进一步理解filecmp模块的应用,并学习如何处理文件比较中可能遇到的错误和异常。
# 3. 基于filecmp模块的文件比较实践
## 3.1 基本文件比较实践
### 3.1.1 创建脚本进行文件比较
在本章节中,我们将通过实际编写Python脚本来进行文件比较的实践操作。我们首先创建一个简单的脚本,使用filecmp模块提供的基本功能来比较两个文件是否相同。
```python
import filecmp
def compare_files(file1, file2):
result = filecmp.cmp(file1, file2)
print(f"Files '{file1}' and '{file2}' are the same: {result}")
if __name__ == "__main__":
file1 = 'path/to/first/file'
file2 = 'path/to/second/file'
compare_files(file1, file2)
```
在上述代码中,我们首先导入了filecmp模块,然后定义了一个`compare_files`函数,该函数接收两个文件路径作为参数,并使用`filecmp.cmp`函数来比较这两个文件。`filecmp.cmp`函数返回一个布尔值,表示两个文件是否相同。在`__main__`部分,我们调用`compare_files`函数并传入两个文件的路径。
### 3.1.2 结果的解读和使用
当我们运行上述脚本时,脚本将输出两个文件是否相同的比较结果。这个结果可以直接用于控制流程,例如,如果两个文件相同,我们可以继续执行后续的文件处理操作;如果不同,则可以提示用户或执行特定的错误处理流程。
```python
if compare_files(file1, file2):
print("Proceed with further file processing.")
else:
print("Files are different, handle the discrepancy accordingly.")
```
在上述代码片段中,我们使用了if-else结构来根据`compare_files`函数的返回值来决定后续的操作。这种简单的逻辑可以根据实际需求进行扩展和定制。
## 3.2 高级文件比较实践
### 3.2.1 忽略权限和修改时间的比较
在某些情况下,我们可能需要比较文件内容,但忽略文件的权限和修改时间等元数据。filecmp模块提供了`cmpfiles`函数,允许我们指定要比较的文件,并且可以选择忽略某些元数据。
```python
import filecmp
import os
def compare_files_with_ignores(file1, file2, ignores=None):
result = filecmp.cmpfiles(file1, file2, os.listdir(file1), shallow=False, ignore=ignores)
print(f"Files '{file1}' and '{file2}' are the same: {result}")
if __name__ == "__main__":
file1 = 'path/to/first/directory'
file2 = 'path/to/second/directory'
ignores = [os.path.join(dp, f) for dp, dn, filenames in os.walk(file1) for f in filenames if '.git' in f]
compare_files_with_ignores(file1, file2, ignores)
```
在这个示例中,我们使用`cmpfiles`函数来比较两个目录中的文件,并且通过`ignores`参数忽略了所有包含`.git`的文件路径。`cmpfiles`函数返回一个三元组,其中包含两个列表和一个布尔值,分别表示匹配的文件、不匹配的文件和两个目录是否完全相同。
### 3.2.2 处理符号链接和硬链接
处理符号链接和硬链接时,filecmp模块默认情况下可能不会按照预期工作,因为它会将链接本身视为文件。为了正确比较链接指向的实际内容,我们需要自定义比较逻辑。
```python
import filecmp
import os
def compare_links(file1, file2):
if os.path.islink(file1) and os.path.islink(file2):
link1 = os.readlink(file1)
link2 = os.readlink(file2)
return link1 == link2
return filecmp.cmp(file1, file2, shallow=False)
if __name__ == "__main__":
file1 = 'path/to/first/file'
file2 = 'path/to/second/file'
result = compare_links(file1, file2)
print(f"Files '{file1}' and '{file2}' are the same: {result}")
```
在这个脚本中,我们首先检查两个文件是否都是链接,如果是,则读取它们各自指向的实际路径,并比较这些路径。如果不是链接,则使用`filecmp.cmp`函数来比较文件内容。
## 3.3 文件比较脚本的错误处理
### 3.3.1 常见错误和异常处理
在编写文件比较脚本时,我们需要考虑并处理可能出现的错误和异常情况,例如文件不存在、没有读取权限等。
```python
import filecmp
def compare_files(file1, file2):
try:
if not os.path.isfile(file1) or not os.path.isfile(file2):
raise FileNotFoundError(f"One of the files does not exist: {file1} or {file2}")
result = filecmp.cmp(file1, file2)
print(f"Files '{file1}' and '{file2}' are the same: {result}")
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == "__main__":
file1 = 'path/to/first/file'
file2 = 'path/to/second/file'
compare_files(file1, file2)
```
在这个脚本中,我们使用try-except结构来捕获并处理可能出现的异常。我们检查文件是否存在,并且在处理文件时捕获任何异常,然后将其打印出来。
### 3.3.2 日志记录和故障诊断
为了更好地理解和诊断脚本执行过程中可能出现的问题,我们可以添加日志记录功能。
```python
import filecmp
import logging
logging.basicConfig(level=***)
def compare_files(file1, file2):
try:
if not os.path.isfile(file1) or not os.path.isfile(file2):
raise FileNotFoundError(f"One of the files does not exist: {file1} or {file2}")
result = filecmp.cmp(file1, file2)
***(f"Files '{file1}' and '{file2}' are the same: {result}")
except Exception as e:
logging.error(f"An error occurred: {e}")
if __name__ == "__main__":
file1 = 'path/to/first/file'
file2 = 'path/to/second/file'
compare_files(file1, file2)
```
在这个示例中,我们使用了Python的`logging`模块来记录信息和错误。日志信息可以帮助我们了解脚本执行的状态,而错误日志则可以提供异常发生时的详细信息,便于我们进行故障诊断。
## 3.4 文件比较脚本的扩展应用
### 3.4.1 批量比较多个文件
在实际应用中,我们可能需要比较多个文件,而不是仅限于两个。我们可以扩展脚本来支持批量比较。
```python
import filecmp
import os
import glob
def compare_directory_contents(dir1, dir2):
files1 = glob.glob(os.path.join(dir1, '*'))
files2 = glob.glob(os.path.join(dir2, '*'))
return filecmp.cmpfiles(dir1, dir2, files1, shallow=False)
if __name__ == "__main__":
directory1 = 'path/to/first/directory'
directory2 = 'path/to/second/directory'
result = compare_directory_contents(directory1, directory2)
print(f"All files in '{directory1}' and '{directory2}' are the same: {all(result)}")
```
在这个脚本中,我们使用`glob.glob`函数来获取两个目录中的所有文件,并使用`filecmp.cmpfiles`来比较这些文件。`cmpfiles`函数返回一个三元组,我们使用`all`函数来检查所有文件是否相同。
### 3.4.2 使用回调函数处理比较结果
为了提供更多的灵活性,我们可以使用回调函数来处理每个文件的比较结果。
```python
import filecmp
import os
def compare_files_callback(file1, file2, result):
print(f"Comparing '{file1}' and '{file2}': {'same' if result else 'different'}")
def compare_files_with_callback(file1, file2):
def callback(file1, file2, result):
compare_files_callback(file1, file2, result)
filecmp.cmp(file1, file2, shallow=False, callback=callback)
if __name__ == "__main__":
file1 = 'path/to/first/file'
file2 = 'path/to/second/file'
compare_files_with_callback(file1, file2)
```
在这个示例中,我们定义了一个`compare_files_callback`函数,它接受三个参数:两个文件的路径和比较结果。然后我们将其作为回调函数传递给`filecmp.cmp`函数。这样,每次比较两个文件时,都会调用`compare_files_callback`函数来处理结果。
以上是基于filecmp模块的文件比较实践的详细介绍。通过这些示例和代码,我们可以看到如何使用filecmp模块来进行基本和高级的文件比较,以及如何处理脚本中的错误和异常情况。此外,我们还展示了如何扩展脚本来支持批量比较和自定义回调函数,以满足更复杂的文件比较需求。
# 4. Python文件比较的实际应用案例
## 4.1 文件版本控制与备份
### 4.1.1 自动备份新文件的策略
在IT行业中,文件版本控制与备份是确保数据安全和业务连续性的重要手段。Python的`filecmp`模块可以用于实现自动备份新文件的策略。以下是一个具体的实现方案:
```python
import filecmp
import os
import shutil
def backup_new_files(source_dir, backup_dir):
"""
备份源目录中的新文件到备份目录。
:param source_dir: 源目录路径
:param backup_dir: 备份目录路径
"""
# 确保备份目录存在
if not os.path.exists(backup_dir):
os.makedirs(backup_dir)
# 遍历源目录中的文件
for filename in os.listdir(source_dir):
source_file = os.path.join(source_dir, filename)
backup_file = os.path.join(backup_dir, filename)
# 检查文件是否存在以及是否为文件
if os.path.isfile(source_file) and not os.path.isfile(backup_file):
# 比较文件是否相同,忽略元数据
if not filecmp.cmp(source_file, backup_file, shallow=False):
# 文件不同,执行备份
shutil.copy2(source_file, backup_file)
print(f"文件 {filename} 已备份到 {backup_dir}")
else:
print(f"文件 {filename} 未发生变化,无需备份")
```
在上述代码中,我们定义了一个`backup_new_files`函数,它接受源目录和备份目录作为参数。函数首先确保备份目录存在,然后遍历源目录中的所有文件。对于每个文件,它使用`filecmp.cmp`函数进行比较,忽略元数据。如果文件发生变化,则使用`shutil.copy2`将其复制到备份目录。
### 4.1.2 版本控制中的文件比较
在版本控制系统中,文件比较是一个核心功能,用于追踪文件的变更。例如,我们可以使用`filecmp`模块来比较不同版本之间的文件差异。以下是一个简化的示例:
```python
import filecmp
import difflib
def compare_versions(version1_path, version2_path, file_path):
"""
比较两个版本之间的文件差异。
:param version1_path: 版本1的路径
:param version2_path: 版本2的路径
:param file_path: 需要比较的文件路径
"""
v1_file_path = os.path.join(version1_path, file_path)
v2_file_path = os.path.join(version2_path, file_path)
# 比较两个文件
if filecmp.cmp(v1_file_path, v2_file_path, shallow=False):
print(f"文件 {file_path} 在两个版本之间未发生变化。")
else:
# 文件不同,使用 difflib 显示差异
with open(v1_file_path, 'r') as file1, open(v2_file_path, 'r') as file2:
diff = difflib.context_diff(file1.readlines(), file2.readlines())
print(f"文件 {file_path} 在两个版本之间的差异:")
print("\n".join(diff))
```
在这个函数中,我们比较两个版本之间的文件差异。如果两个文件完全相同,则输出未发生变化的信息;否则,使用`difflib`模块的`context_diff`方法来显示具体的差异。
## 4.2 持续集成中的文件比较
### 4.2.1 自动化测试中的文件比较
在持续集成(CI)流程中,自动化测试是确保代码质量的关键步骤。通过比较测试前后的文件状态,我们可以验证代码更改是否按预期工作。
```python
def compare_test_results(test_dir, baseline_dir):
"""
比较测试结果与基线结果之间的差异。
:param test_dir: 测试结果目录
:param baseline_dir: 基线结果目录
"""
# 遍历测试结果目录中的所有文件
for filename in os.listdir(test_dir):
test_file = os.path.join(test_dir, filename)
baseline_file = os.path.join(baseline_dir, filename)
# 比较文件是否相同,忽略元数据
if not filecmp.cmp(test_file, baseline_file, shallow=False):
print(f"测试结果文件 {filename} 与基线不匹配,需要检查。")
# 进一步分析差异
# ...
else:
print(f"测试结果文件 {filename} 与基线匹配。")
```
在上述代码中,我们定义了一个`compare_test_results`函数,它比较测试结果目录和基线结果目录中的文件差异。如果测试结果文件与基线不匹配,则提示需要进一步检查。
### 4.2.2 部署过程中的文件校验
在软件部署过程中,确保部署的文件与预期一致是非常重要的。使用`filecmp`模块,我们可以校验部署的文件是否完整无误。
```python
def verify_deployment(deployment_dir, expected_dir):
"""
校验部署的文件是否与预期一致。
:param deployment_dir: 部署目录
:param expected_dir: 预期目录
"""
# 遍历预期目录中的所有文件
for filename in os.listdir(expected_dir):
expected_file = os.path.join(expected_dir, filename)
deployment_file = os.path.join(deployment_dir, filename)
# 比较文件是否相同,忽略元数据
if not filecmp.cmp(expected_file, deployment_file, shallow=False):
print(f"部署文件 {filename} 与预期不一致,部署失败。")
# 进一步分析差异
# ...
else:
print(f"部署文件 {filename} 与预期一致,部署成功。")
```
在`verify_deployment`函数中,我们比较部署目录和预期目录中的文件差异。如果部署的文件与预期不一致,则输出部署失败的信息。
## 4.3 安全性检查与合规性
### 4.3.1 文件完整性检查
文件完整性检查是确保文件未被未授权更改的重要手段。通过比较文件的校验和,我们可以检测文件是否被篡改。
```python
import hashlib
def compute_checksum(file_path):
"""
计算文件的MD5校验和。
:param file_path: 文件路径
:return: 文件的MD5校验和
"""
hash_md5 = hashlib.md5()
with open(file_path, 'rb') as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
def check_file_integrity(file_path, expected_checksum):
"""
检查文件的完整性。
:param file_path: 文件路径
:param expected_checksum: 预期的MD5校验和
:return: 文件是否完整
"""
actual_checksum = compute_checksum(file_path)
return actual_checksum == expected_checksum
```
在上述代码中,我们定义了`compute_checksum`函数来计算文件的MD5校验和,以及`check_file_integrity`函数来检查文件的完整性。通过比较实际的校验和与预期的校验和,我们可以判断文件是否完整。
### 4.3.2 安全策略中的文件比较应用
在安全策略中,文件比较可以用来检测潜在的安全威胁,例如检测系统文件或关键配置文件的更改。
```python
def monitor_system_files(directory, checksums):
"""
监控系统文件的变化。
:param directory: 系统文件所在目录
:param checksums: 系统文件的预期校验和
"""
for filename, expected_checksum in checksums.items():
file_path = os.path.join(directory, filename)
if os.path.isfile(file_path):
if not check_file_integrity(file_path, expected_checksum):
print(f"系统文件 {filename} 的校验和不匹配,可能存在安全风险。")
# 进一步的响应措施
# ...
else:
print(f"系统文件 {filename} 不存在,需要关注。")
```
在`monitor_system_files`函数中,我们监控系统文件目录中的文件变化。通过计算文件的实际校验和与预期校验和的比较,我们可以检测文件是否被篡改。
通过以上案例,我们可以看到`filecmp`模块在实际应用中的多样性和强大功能。它不仅可以用于基本的文件比较,还可以扩展到更复杂的场景,如版本控制、持续集成、文件完整性检查等。希望这些案例能够激发你对`filecmp`模块的兴趣,并在你的项目中找到合适的应用场景。
# 5. 文件比较工具的比较与选择
在本章节中,我们将深入探讨filecmp模块与其他文件比较工具的比较,以及如何根据不同的需求和环境选择合适的工具。此外,我们还将讨论自定义开发文件比较工具的可能性。
## 5.1 filecmp模块与其他文件比较工具的比较
### 5.1.1 性能对比
filecmp模块作为Python标准库的一部分,其性能与其他专门的文件比较工具有所不同。由于它内置在Python环境中,无需额外安装,这为开发者提供了便利。然而,filecmp可能在处理大量文件或大文件时,性能不如一些专门优化过的第三方工具。
### 5.1.2 功能对比
filecmp模块提供了基本的文件和目录比较功能,例如深度比较和忽略元数据的比较。但是,它可能缺乏一些高级功能,如二进制文件比较、图形用户界面(GUI)支持、版本控制集成等。这些功能在第三方工具中更为常见,例如WinMerge、Beyond Compare和Meld等。
## 5.2 如何选择合适的文件比较工具
### 5.2.1 根据需求选择
选择文件比较工具时,首先要考虑实际需求。如果是一个简单的项目,且不需要额外的图形界面或版本控制支持,filecmp模块可能就足够了。但如果需要进行复杂的版本控制或持续集成,那么专业的第三方工具可能是更好的选择。
### 5.2.2 根据环境和平台选择
不同的工具可能支持不同的操作系统和环境。例如,WinMerge和Beyond Compare主要针对Windows系统,而Meld则支持Linux和macOS。此外,如果项目环境中有特定的集成需求,如与Jenkins或Git集成,那么选择支持这些平台的工具将更为合适。
## 5.3 自定义文件比较工具的开发
### 5.3.1 开发环境的搭建
自定义文件比较工具的开发需要选择合适的编程语言和开发环境。Python是一个不错的选择,因为它简单易学,且有丰富的库支持。开发时,可以使用IDE如PyCharm,搭配版本控制工具如Git,以及单元测试框架如pytest。
### 5.3.2 实现高级比较逻辑
在实现高级比较逻辑时,可以考虑以下几个方面:
1. **二进制文件比较**:除了文本文件,还需要比较二进制文件,这可能需要读取和分析文件的字节。
2. **性能优化**:对于大文件和大量文件,可以采用多线程或异步IO来提高比较速度。
3. **用户界面**:开发图形用户界面(GUI)可以提高用户体验,可以使用Tkinter或PyQt等库来实现。
以下是一个简单的Python脚本,演示了如何使用filecmp模块比较两个文件,并打印出不同的部分:
```python
import filecmp
def compare_files(file1, file2):
if filecmp.cmp(file1, file2):
print(f"文件 {file1} 和 {file2} 是相同的。")
else:
print(f"文件 {file1} 和 {file2} 是不同的。")
with open(file1, 'rb') as f1, open(file2, 'rb') as f2:
file1_lines = f1.readlines()
file2_lines = f2.readlines()
if len(file1_lines) != len(file2_lines):
print("文件长度不同。")
else:
for line1, line2 in zip(file1_lines, file2_lines):
if line1 != line2:
print(f"不同之处: {line1.strip()} vs {line2.strip()}")
compare_files('file1.txt', 'file2.txt')
```
在实际应用中,我们可以根据比较结果执行不同的逻辑,如自动备份、版本控制或触发自动化测试。
通过以上内容,我们对filecmp模块与其他文件比较工具的比较与选择有了更深入的理解,并且了解了如何根据不同的需求和环境选择合适的工具。此外,我们也探讨了自定义开发文件比较工具的可能性,以及如何搭建开发环境和实现高级比较逻辑。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 文件比较的权威指南!本专栏深入探讨了 filecmp 库,提供了一系列全面的文章,涵盖从基础知识到高级技巧和最佳实践。通过掌握 filecmp,您可以提升代码效率、确保数据安全,并轻松处理文件比较任务。我们为您提供了专家指南、实战应用、性能优化策略、案例分析以及单元测试技巧,让您成为文件比较领域的专家。无论您是初学者还是经验丰富的开发者,本专栏都将为您提供宝贵的见解,帮助您充分利用 filecmp 的强大功能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Cyclone数据持久化策略:持久层最佳实践,数据安全无忧

# 摘要
本文首先概述了Cyclone数据持久化的基本概念及其在软件系统中的核心作用。随后深入探讨了数据持久化的理论基础,包括数据库事务的ACID属性、数据一致性和备份与灾难恢复策略。接着,文章详细阐述了Cyclone持久层的设计原则与核心组件,并通过案例分析展示其实践应用和优化策略。此外,本文还强调了数据安全性的重要性,探讨了数据安全的挑战、数据完整性和安全性增强措施。最后,本文讨论了性能优化和监控在Cyclone持久化
提升仪器控制效率:高级VISA函数编程技巧大揭秘
# 摘要
VISA(Virtual Instrument Software Architecture)是一种标准的I/O接口软件,广泛应用于自动化测试与测量领域中仪器通信的编程和控制。本文从VISA的基本概念和函数编程基础开始,详细探讨了VISA函数的安装、配置、基本语法及其在实现仪器通信中的应用。进阶章节深入讲解了高级编程技巧,包括高级通信控制技术、编写可复用代码的方法以及处理复杂仪器协议。随后,本文展示了V
代码与文档同步更新指南:协同工作流的优化之道

# 摘要
在现代软件开发中,代码与文档的同步更新对于保持项目信息一致性、提高工作效率和质量至关重要。本文强调了协同工作流中理论与实践的重要性,并探讨了实施同步更新的挑战和进阶策略。文章通过分析协同工作流的理论基础,包括定义、工作流角色、同步更新的理论模型以及自动化工具的应用,为实现高效同步更新提供了理论支持。实践案例部分则深入探讨了工具选择、工作流程设计、操作挑战及
【工程标准的IT实践】:ANSI SAE花键案例研究
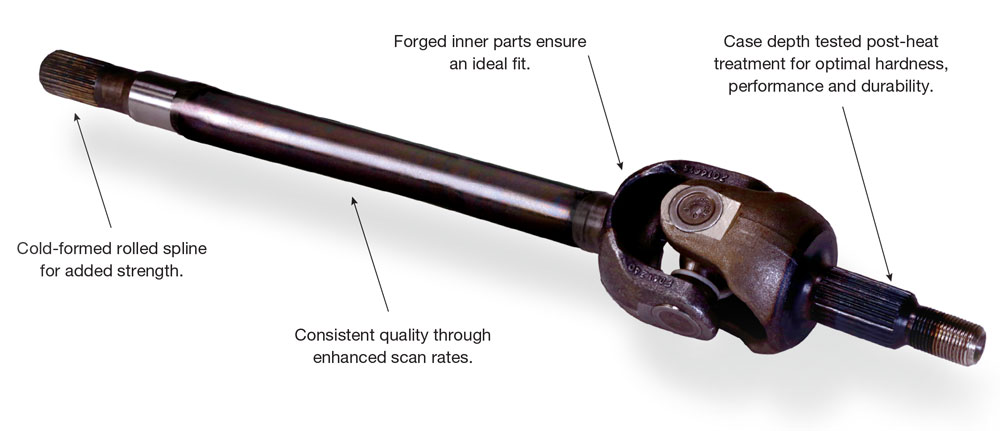
# 摘要
本文详细探讨了ANSI SAE花键的设计、工程标准以及在工程实践中的实现,并分析了IT技术在提升花键工程标准实践中的作用。文章首先概述了ANSI SAE花键的标准及其在工程设计中的重要性,并详细讨论了设计和制造流程的具体标准要求。随后,文章转向工程实践,研究了花键加工技术和质量检验流程,并通过案例分析展示了花键在不同行业中的应用。第四章重点介绍了C
彻底解析:S7-200 Smart与KEPWARE的OPC通信协议精髓
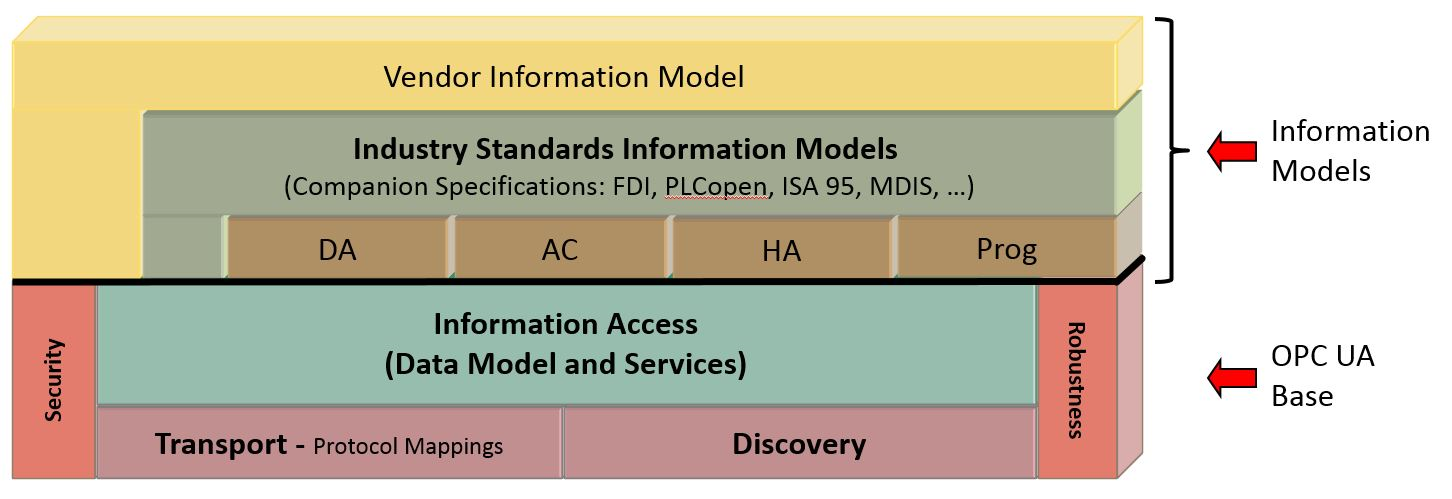
# 摘要
本论文系统地探讨了S7-200 Smart PLC与OPC(OLE for Process Control)技术在工业自动化领域的通信实现。介绍了OPC通信协议的基础知识,包括其发展历程、架构组成以及数据访问规范。同时,详细阐述了S7-200 Smart PLC的硬件特点和编程实践,以及如何使用KEPWARE OPC服务器进行有效配置和管理。本文还展示了如何实现S
【数字电位器工作原理揭秘】:掌握其工作模式与应用
# 摘要
数字电位器是一种电子元件,用于调节电路中的电压或电流。本文首先介绍数字电位器的基本概念和功能,然后深入探讨其工作模式,包括内部结构、工作原理、主要参数和特性。接着,本文分析数字电位器的应用实例,如电路设计、信号调节和电子设备中的应用。此外,本文还讨论了数字电位器的编程与控制方法,以及调试和性能优化策略。最后,本文展望了数字电位器的未来发展趋势,包括技术创新和应用前景,并
【质量控制策略】:确保GMW14241翻译无误的关键措施

# 摘要
本文旨在深入探讨GMW14241标准的翻译质量控制流程,以及如何通过翻译实践技巧确保翻译准确性。首先,文章概述了GMW14241标准,并分析了翻译流程中质量控制的重要性及其基本原则。随后,重点介绍了翻译质量评估体系、翻译工具和技术运用以及翻译团队的管理与培训。在确保翻译准确性方面,探讨了汽车行业特定术语的理解与应用、翻译质量控制的实施步骤以及翻译错误的预防与纠正措施。最后,通过案例研究,分析了GM
【组态王历史数据管理】:优化存储与查询的4大方法
# 摘要
组态王系统在工业自动化领域中扮演着重要角色,尤其在历史数据的管理上。本文首先概述了组态王系统以及历史数据的重要性。随后,深入探讨了历史数据存储的理论基础,包括数据存储基本概念、数据库技术的应用,以及数据压缩技术。在历史数据查询方面,本文分析了查询效率的影响因素、数据仓库与OLAP技术,以及大数据技术在查询优化中的应用。接着,本文讨论了历史数据管理优化方法实践,包括存储结构优化、查询性能提升以及数据安全和备份。高级应用章节则聚焦于实时数据分析、预测性维护和自动化报告生成。最后,本文展望了未来趋势与技术创新,特别关注人工智能、云计算融合以及数据安全性与合规性的发展方向。文章综合应用理论与
【CAN2.0布线实务与OSI模型】:硬件连接到通信层次的全面指导
# 摘要
本论文全面介绍了CAN2.0总线技术,涵盖了其基础理论、布线标准、实践应用、与OSI模型的关系、网络配置及故障排除,以及布线的高级应用和创新。通过详细探讨CAN2.0的布线基础和实践,包括线材规格选择、布线长度布局、接地屏蔽技术及端接电阻配置,本文为实现可靠和高效的CAN2.0通信网络提供了重要指导。此外,论文深入分析了OSI模型与CAN2.0的相互作用,并探讨了在
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )