【Python文件比较进阶教程】:如何优雅地处理异常与进行高效比较
发布时间: 2024-10-16 20:20:18 阅读量: 21 订阅数: 20 

Python进阶.pdf

# 1. Python文件比较基础
在本章节中,我们将探讨如何使用Python进行文件比较的基础知识。我们将从最简单的文件比较方法开始,逐步深入到更复杂的算法和数据结构。首先,我们将了解如何读取文件内容,并将其转换为字符串或字节序列。接着,我们将学习如何逐行或逐字符比较两个文件的内容。此外,我们还将介绍一些基本的字符串处理技巧,这些技巧对于检测和处理文件中的差异至关重要。通过本章节的学习,你将掌握如何编写一个基本的文件比较脚本,并为进一步的优化和异常处理打下坚实的基础。
```python
# 示例代码:逐行比较两个文件的内容
def compare_files(file_path1, file_path2):
try:
with open(file_path1, 'r') as file1, open(file_path2, 'r') as file2:
lines1 = file1.readlines()
lines2 = file2.readlines()
# 比较文件行数
if len(lines1) != len(lines2):
print("文件行数不同")
return False
for line1, line2 in zip(lines1, lines2):
if line1 != line2:
print("在第{}行发现差异:".format(lines1.index(line1) + 1))
print("文件1:{}\n文件2:{}".format(line1.strip(), line2.strip()))
return False
print("文件内容相同")
return True
except FileNotFoundError as e:
print(e)
return False
```
在上述代码中,我们定义了一个`compare_files`函数,它接受两个文件路径作为参数,并逐行比较它们的内容。如果发现差异,函数会打印出差异所在行的信息,并返回`False`。如果没有差异,函数将返回`True`。我们还考虑了文件不存在的异常情况,并捕获了`FileNotFoundError`异常。这个例子为接下来更深入的讨论奠定了基础,同时展示了如何在Python中进行简单的文件比较和异常处理。
# 2. 异常处理的艺术
## 2.1 异常处理的基本概念
### 2.1.1 异常类型和捕获
异常是程序运行过程中发生的不正常情况,它中断了正常的程序流程。在Python中,异常类型很多,如`TypeError`、`ValueError`、`IndexError`等,每种异常都有其特定的用途和含义。了解异常类型是进行有效异常处理的第一步。
```python
try:
result = 10 / 0
except ZeroDivisionError as e:
print(f"捕获到除零错误:{e}")
except Exception as e:
print(f"捕获到其他错误:{e}")
else:
print("没有异常发生")
finally:
print("执行清理工作")
```
在上述代码块中,我们尝试执行一个除法操作,但故意制造了一个除零错误。`try`块中的代码可能引发异常,而`except`块则捕获并处理这些异常。`else`块在没有异常发生时执行,而`finally`块则无论是否发生异常都会执行。
### 2.1.2 自定义异常和异常链
除了使用Python内置的异常类型,我们还可以定义自己的异常。这在我们需要对异常进行更细致的分类和处理时非常有用。
```python
class CustomError(Exception):
def __init__(self, message):
super().__init__(message)
try:
raise CustomError("自定义错误消息")
except CustomError as e:
print(f"捕获到自定义异常:{e}")
```
异常链是一种将一个异常嵌入到另一个异常的技术,它允许我们保留原始异常的堆栈跟踪信息,同时添加新的上下文。
```python
try:
# 故意引发一个除零错误
result = 10 / 0
except ZeroDivisionError as e:
# 创建一个新的异常实例,将原始异常作为参数
raise ValueError("发生了一个错误") from e
```
在上述代码中,我们首先故意引发了除零错误,然后捕获它,并引发一个新的`ValueError`异常,将原始的`ZeroDivisionError`作为上下文信息传递给新的异常。这样做可以帮助我们更好地调试和理解错误发生的上下文。
## 2.2 异常处理的高级技巧
### 2.2.1 上下文管理器和with语句
上下文管理器和`with`语句是Python中处理资源管理的一种高效方式,它们可以确保资源在使用后被正确释放,即使在发生异常的情况下也是如此。
```python
class ManagedResource:
def __enter__(self):
print("进入上下文管理器")
return self
def __exit__(self, exc_type, exc_value, traceback):
print("退出上下文管理器")
if exc_type:
print(f"发生异常:{exc_value}")
return False # 允许异常传播
with ManagedResource() as resource:
print("在上下文管理器内部")
raise ValueError("发生了一个错误")
print("with语句外部")
```
在上述代码中,我们定义了一个`ManagedResource`类,它实现了`__enter__`和`__exit__`方法,分别在进入和退出`with`语句时被调用。即使在`with`块内部发生异常,`__exit__`方法也会被调用,这使得我们可以在其中添加清理代码。
### 2.2.2 异常抑制和日志记录
有时候,我们可能不希望直接处理某些异常,而是希望记录它们的发生,以便于后续的分析和调试。这时,我们可以使用`logging`模块来记录异常信息。
```python
import logging
logging.basicConfig(level=logging.ERROR)
try:
# 故意引发一个除零错误
result = 10 / 0
except Exception as e:
logging.error("捕获到异常", exc_info=True)
```
在上述代码中,我们使用`logging.error`方法记录了一个错误,`exc_info=True`参数指示`logging`模块记录当前发生的异常信息。这使得我们可以在不直接处理异常的情况下,记录足够的信息用于后续分析。
## 2.3 实践:构建鲁棒的文件比较脚本
### 2.3.1 设计异常友好的比较逻辑
在文件比较脚本中,我们需要处理各种可能发生的异常,例如文件不存在、读取错误等。设计一个异常友好的比较逻辑,意味着我们需要确保所有可能的异常都被捕获并适当处理。
```python
def compare_files(file1, file2):
try:
with open(file1, 'r') as f1, open(file2, 'r') as f2:
content1 = f1.readlines()
content2 = f2.readlines()
# 比较文件内容
# ...
except FileNotFoundError as e:
print(f"文件不存在:{e}")
except IOError as e:
print(f"文件读取错误:{e}")
except Exception as e:
print(f"发生了一个未知错误:{e}")
```
在上述代码中,我们尝试打开两个文件并读取它们的内容,然后进行比较。我们使用`try-except`块捕获并处理了多种可能的异常,包括文件不存在、文件读取错误以及未知错误。
### 2.3.2 测试和验证异常处理效果
为了确保文件比较脚本的鲁棒性,我们需要对其进行充分的测试。测试应该包括各种可能的异常情况,以确保所有的异常都被正确捕获和处理。
```python
import unittest
class TestCompareFiles(unittest.TestCase):
def test_file_not_found(self):
with self.assertRaises(FileNotFoundError):
compare_files("non_existent_file1.txt", "non_existent_file2.txt")
def test_io_error(self):
with open("test_file1.txt", "w") as f:
f.write("test")
with self.assertRaises(IOError):
compare_files("test_file1.txt", "non_existent_file2.txt")
os.remove("test_file1.txt")
if __name__ == "__main__":
unittest.main()
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 文件比较的权威指南!本专栏深入探讨了 filecmp 库,提供了一系列全面的文章,涵盖从基础知识到高级技巧和最佳实践。通过掌握 filecmp,您可以提升代码效率、确保数据安全,并轻松处理文件比较任务。我们为您提供了专家指南、实战应用、性能优化策略、案例分析以及单元测试技巧,让您成为文件比较领域的专家。无论您是初学者还是经验丰富的开发者,本专栏都将为您提供宝贵的见解,帮助您充分利用 filecmp 的强大功能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
永磁同步电机控制策略仿真:MATLAB_Simulink实现
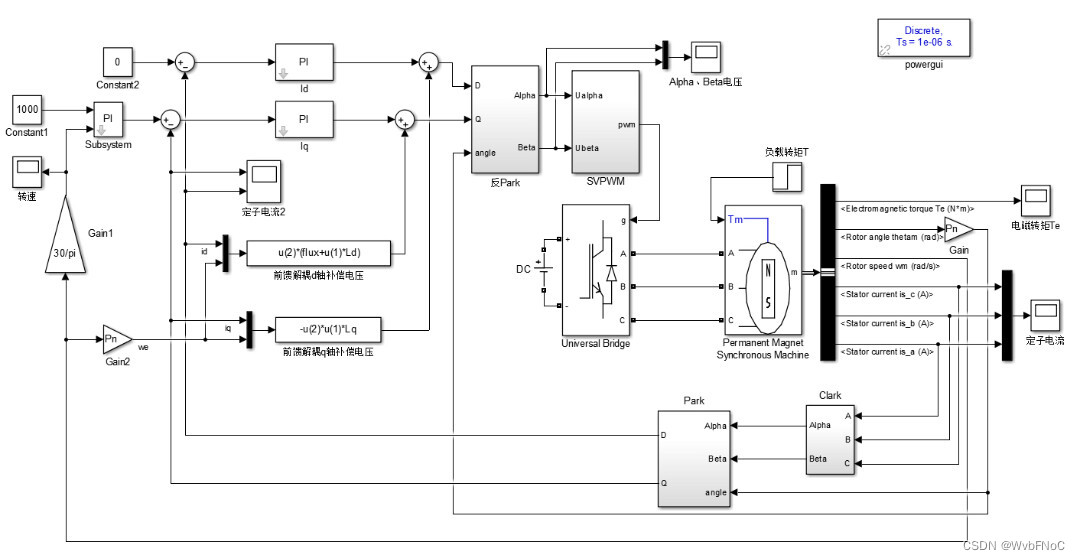
# 摘要
本文概述了永磁同步电机(PMSM)的控制策略,首先介绍了MATLAB和Simulink在构建电机数学模型和搭建仿真环境中的基础应用。随后,本文详细分析了基本控制策略,如矢量控制和直接转矩控制,并通过仿真结果进行了性能对比。在高级控制策略部分,我们探讨了模糊控制和人工智能控制策略在电机仿真中的应用,并对控制策略进行了优化。最后,通过实际应用案例,验证了仿真模型的有效性,并
【编译器性能提升指南】:优化技术的关键步骤揭秘
# 摘要
编译器性能优化对于提高软件执行效率和质量至关重要。本文详细探讨了编译器前端和后端的优化技术,包括前端的词法与语法分析优化、静态代码分析和改进以及编译时优化策略,和后端的中间表示(IR)优化、指令调度与并行化技术、寄存器分配与管理。同时,本文还分析了链接器和运行时优化对性能的影响,涵盖了链接时代码优化、运行时环境的性能提升和调试工具的应用。最后,通过编译器优化案例分析与展望,本文对比了不同编译器的优化效果,并探索了机器学习技术在编译优化中的应用,为未来的优化工作指明了方向。
# 关键字
编译器优化;前端优化;后端优化;静态分析;指令调度;寄存器分配
参考资源链接:[编译原理第二版:
Catia打印进阶:掌握高级技巧,打造完美工程图输出
# 摘要
本文全面探讨了Catia软件中打印功能的应用和优化,从基本打印设置到高级打印技巧,为用户提供了系统的打印解决方案。首先概述了Catia打印功能的基本概念和工程图打印设置的基础知识,包括工程图与打印预览的使用技巧以及打印参数和布局配置。随后,文章深入介绍了高级打印技巧,包括定制打印参数、批量打印、自动化工作流以及解决打印过程中的常见问题。通过案例分析,本文探讨了工程图打印在项目管理中的实际应用,并分享了提升打印效果
快速排序:C语言中的高效稳定实现与性能测试
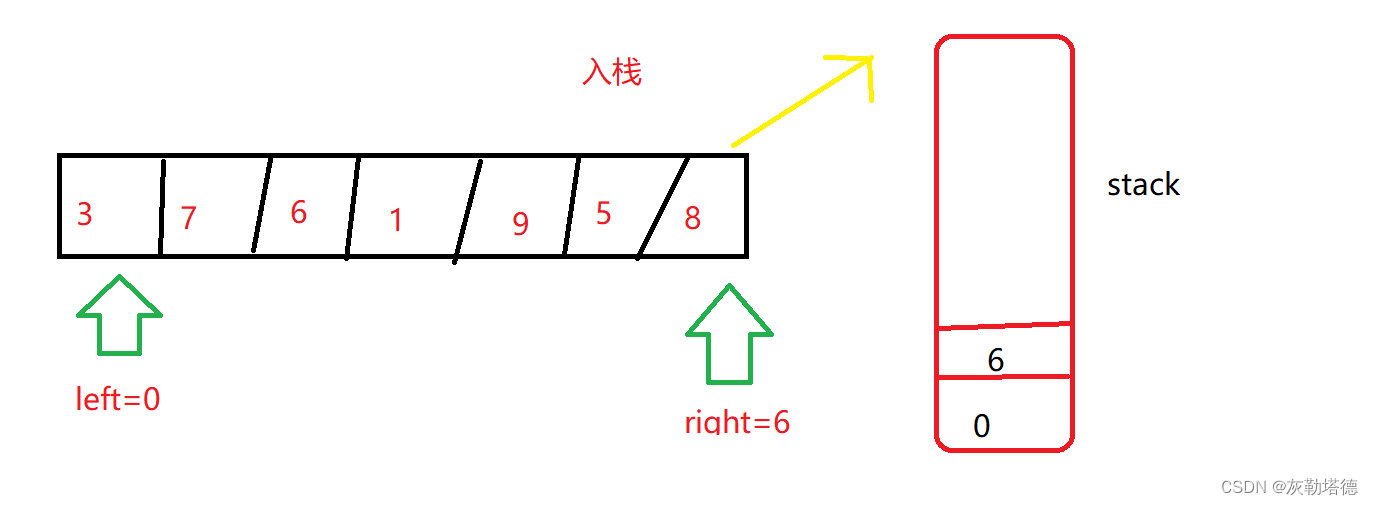
# 摘要
快速排序是一种广泛使用的高效排序算法,以其平均情况下的优秀性能著称。本文首先介绍了快速排序的基本概念、原理和在C语言中的基础实现,详细分析了其分区函数设计和递归调用机制。然后,本文探讨了快速排序的多种优化策略,如三数取中法、尾递归优化和迭代替代递归等,以提高算法效率。进一步地,本文研究了快速排序的高级特性,包括稳定版本的实现方法和非递归实现的技术细节,并与其他排序算法进行了比较。文章最后对快速排序的C语言代码实现进行了分析,并通过性能测
CPHY布局全解析:实战技巧与高速信号完整性分析
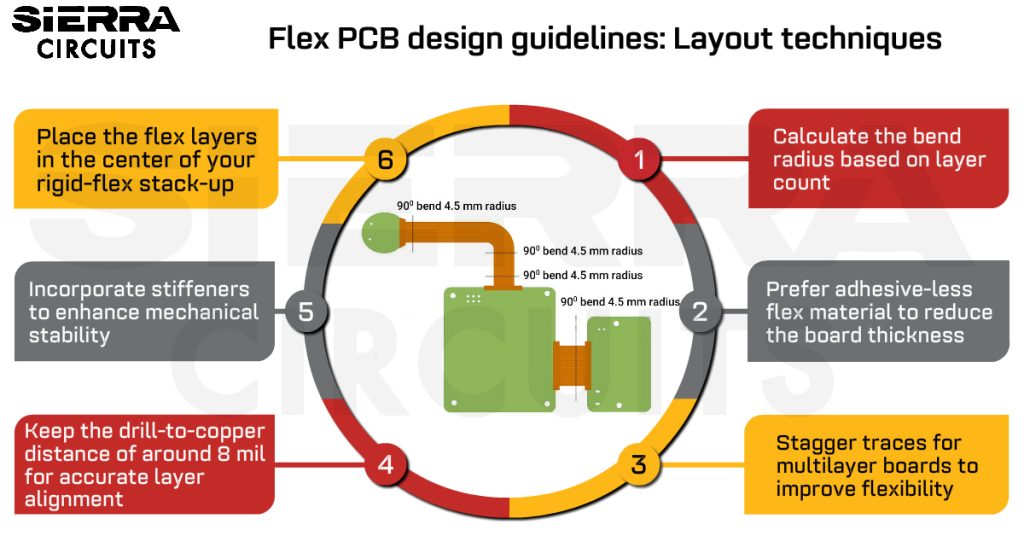
# 摘要
CPHY布局技术是支持高数据速率和高分辨率显示的关键技术。本文首先概述了CPHY布局的基本原理和技术要点,接着深入探讨了高速信号完整性的重要性,并介绍了分析信号完整性的工具与方法。在实战技巧方面,本文提供了CPHY布局要求、走线与去耦策略,以及电磁兼容(EMC)设计的详细说明。此外,本文通过案
四元数与复数的交融:图像处理创新技术的深度解析

# 摘要
本论文深入探讨了图像处理与数学基础之间的联系,重点分析了四元数和复数在图像处理领域内的理论基础和应用实践。首先,介绍了四元数的基本概念、数学运算以及其在图像处理中的应用,包括旋转、平滑处理、特征提取和图像合成等。其次,阐述了复数在二维和三维图像处理中的角色,涵盖傅里叶变换、频域分析、数据压缩、模型渲染和光线追踪。此外,本文探讨了四元数与复数结合的理论和应用,包括傅里叶变
【性能优化专家】:提升Illustrator插件运行效率的5大策略

# 摘要
随着数字内容创作需求的增加,对Illustrator插件性能的要求也越来越高。本文旨在概述Illustrator插件性能优化的有效方法
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )