【Java Set集合的高级特性】:探索Set的集合运算与PowerSet实现
发布时间: 2024-09-23 16:06:44 阅读量: 94 订阅数: 36 
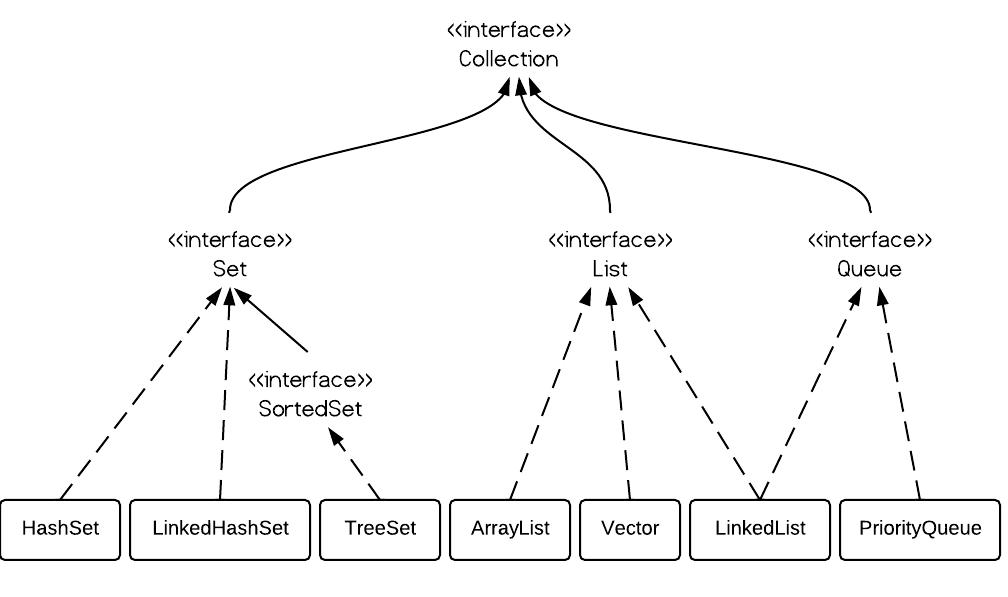
# 1. Java Set集合概述
在Java编程语言中,Set集合是一种不包含重复元素的集合,它继承自Collection接口,并且是Collection体系中的核心成员之一。Set集合的出现主要是为了解决数据的唯一性问题,因此它常被用于需要进行数据去重的场景。Set集合的特点使得它在数据处理和业务逻辑中扮演着重要角色。然而,值得注意的是,Set集合不保证元素的顺序性,这意味着在集合中的元素可能会呈现出与插入顺序不同的顺序。尽管如此,这种特性并未限制Set集合的广泛应用,反而在很多情况下提高了程序的效率和性能。本章节将介绍Set集合的基本概念,并为深入探讨其核心特性和操作打下基础。
# 2. ```
# 第二章:Set集合的核心特性与操作
在深入研究Set集合时,我们首先需要理解它所具备的核心特性。这不仅涉及理论知识,也包括实际操作中的应用,特别是在并发环境下的使用。
## 2.1 Set集合的数据结构原理
### 2.1.1 哈希表与TreeSet的实现机制
Set集合的实现机制主要基于两种数据结构:哈希表和树结构。它们都旨在保证元素的唯一性并提供高效的查找性能。
#### 哈希表
在Java中,`HashSet` 是最常用的Set实现之一,它底层是通过哈希表来实现的。哈希表依赖于哈希函数来决定元素的存储位置,这使得元素的查找速度非常快。通常情况下,查找操作的时间复杂度为O(1),但这也取决于哈希函数的质量和冲突解决策略。
```java
Set<Integer> hashSet = new HashSet<>();
hashSet.add(1);
hashSet.add(2);
hashSet.add(3);
```
上述代码中,`HashSet` 通过内部的哈希函数将每个元素映射到表中的一个位置,当添加或查找元素时,会利用此函数快速定位到元素所在的位置。
#### TreeSet
`TreeSet` 则是基于红黑树实现的。红黑树是一种自平衡的二叉搜索树,通过特定的旋转和重新着色操作,它能保证最坏情况下的时间复杂度为O(log n)。`TreeSet` 既支持快速的元素添加和删除,也支持有序遍历。
```java
SortedSet<Integer> treeSet = new TreeSet<>();
treeSet.add(1);
treeSet.add(2);
treeSet.add(3);
```
在此段代码中,`TreeSet` 会根据元素值的自然顺序或自定义比较器来维护一个有序集合。
### 2.1.2 不可变集合与CopyOnWriteArraySet
除了`HashSet`和`TreeSet`,Java还提供了其他一些特殊的Set实现,如不可变集合(`ImmutableSet`)和`CopyOnWriteArraySet`。
#### 不可变集合
不可变集合是一种一旦创建就不能被修改的集合。它在多线程环境中是安全的,因为它不需要额外的同步措施。不可变集合非常适合用作常量集合,或者是创建那些不希望被外部修改的数据结构。
```java
Set<String> immutableSet = Collections.unmodifiableSet(new HashSet<>(Arrays.asList("a", "b", "c")));
```
上述代码创建了一个不可变的集合,任何试图修改该集合的操作都会抛出异常。
#### CopyOnWriteArraySet
`CopyOnWriteArraySet` 是一种写时复制的集合,主要用于并发环境。当修改集合时,如添加或删除元素,它会创建底层数组的一个新副本来进行操作,这样避免了在迭代过程中对集合的修改,从而提高了并发访问的性能。
```java
Set<Integer> copyOnWriteArraySet = new CopyOnWriteArraySet<>();
copyOnWriteArraySet.add(1);
copyOnWriteArraySet.add(2);
```
`CopyOnWriteArraySet` 在多线程环境下,为每个修改操作复制底层数组,保持迭代器的稳定性。
## 2.2 Set集合的通用操作与实践
### 2.2.1 添加、删除和查找元素
Set集合的元素添加、删除和查找操作是最基本的操作,通常这些操作都具有较高的效率。
#### 添加元素
添加元素到Set中,可以使用 `add()` 方法。如果集合中已经包含该元素,则 `add()` 方法不会执行任何操作,并返回 `false`。
```java
Set<String> set = new HashSet<>();
boolean added = set.add("Element");
System.out.println(added); // 输出: true
```
#### 删除元素
删除元素则使用 `remove()` 方法,它会从集合中移除指定的元素。如果集合中存在该元素,则移除它并返回 `true`。
```java
boolean removed = set.remove("Element");
System.out.println(removed); // 输出: true
```
#### 查找元素
查找元素可以使用 `contains()` 方法,它会检查集合中是否包含指定的元素。
```java
boolean found = set.contains("Element");
System.out.println(found); // 输出: false
```
### 2.2.2 集合的遍历与比较
Set集合的遍历通常使用 `for-each` 循环,而集合的比较则依赖于 `equals()` 方法。
#### 遍历集合
```java
for (String element : set) {
System.out.println(element);
}
```
#### 比较集合
当需要比较两个Set集合是否相等时,可以使用 `equals()` 方法。对于 `HashSet`,`equals()` 方法会检查两个集合中的所有元素是否一一对应。
```java
Set<String> set1 = new HashSet<>(Arrays.asList("a", "b", "c"));
Set<String> set2 = new HashSet<>(Arrays.asList("a", "b", "c"));
System.out.println(set1.equals(set2)); // 输出: true
```
## 2.3 Set集合的并发操作
### 2.3.1 Java并发集合类概览
在并发编程中,处理集合数据的线程安全问题是一个重要的方面。Java提供了一系列线程安全的集合类,它们位于 `java.util.concurrent` 包中。
#### CopyOnWriteArrayList
`CopyOnWriteArrayList` 是一个线程安全的 `ArrayList` 实现。当修改列表时,它会创建并复制底层数组的副本,使得迭代器不会受到影响。
#### ConcurrentHashMap
`ConcurrentHashMap` 是一个线程安全的 `HashMap` 实现。它采用了分段锁(Segmentation)机制,允许并发访问不同的段(Segment),从而提供更好的并发性能。
### 2.3.2 使用ConcurrentSkipListSet进行排序并发访问
`ConcurrentSkipListSet` 是一个基于跳表结构的线程安全Set实现。它维护了一个有序序列,并提供并发的插入、删除和访问操作。
```java
ConcurrentSkipListSet<Integer> skipListSet = new ConcurrentSkipListSet<>();
skipListSet.add(1);
skipListSet.add(2);
skipListSet.add(3);
```
在并发环境下,`ConcurrentSkipListSet` 保证了集合元素的有序性,同时也支持快速的并发访问。
此章节的介绍部分展示了Set集合的核心数据结构、操作方法和并发使用。下章节将探讨Set集合的高级集合运算,包括交集、并集、差集等操作,以及如何使用Java集合框架进行集合间的高级运算。
```
在接下来的章节中,我们会通过实例代码和详细的解释,继续深入地探讨Set集合的高级运算和并发操作,以及它们在Java集合框架中的应用。
# 3. Set集合的高级集合运算
## 3.1 集合的交集、并集、差集操作
### 3.1.1 使用Java集合框架进行集合运算
在Java的集合框架中,可以非常方便地使用现有的类库来实现集合的交集、并集以及差集操作。`java.util.Collections`类和`java.util.Set`接口提供了这些功能的基本方法。例如,使用`Collections`类的`union`、`intersection`和`difference`方法可以轻松实现集合间的运算。
下面是一个简单的示例代码,演示了如何使用Java集合框架来对两个`Set`对象进行交集、并集和差集操作:
```java
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
public class SetOperationsExample {
public static void main(String[] args) {
Set<Integer> set1 = new HashSet<>(Arrays.asList(1, 2, 3, 4, 5));
Set<Integer> set2 = new HashSet<>(Arrays.asList(3, 4, 5, 6, 7));
// 并集操作
Set<Integer> unionSet = new HashSet<>(set1);
unionSet.addAll(set2);
System.out.println("Union: " + unionSet);
// 交集操作
Set<Integer> intersectionSet = set1.stream()
.filter(set2::contains)
.collect(Collectors.toSet());
System.out.println("Intersection: " + intersectionSet);
// 差集操作
Set<Integer> differenceSet = set1.stream()
.filter(i -> !set2.contains(i))
.collect(Collectors.toSet());
System.out.println("Difference (set1 - set2): " + differenceSet);
Set<Integer> differenceSet2 = set2.stream()
.filter(i -> !set1.contains(i))
.collect(Collectors.toSet());
System.out.println("Difference (set2 - set1): " + differenceSet2);
}
}
```
在上述代码中,`unionSet`展示了`set1`和`set2`的并集结果,`intersectionSet`则是两个集合的交集。我们通过流(Stream)操作实现了差集的计算,`differenceSet`代表`set1`相对于`set2`的差集,而`differenceSet2`则是`set2`相对于`set1`的差集。
### 3.1.2 实现自定义集合运算的策略
虽然Java标准库提供了一组方便的方法来进行集合运算,但在某些情况下,可能需要自定义这些运算的策略以满足特定需求。例如,如果我们希望在计算差集时不仅要考虑值,还要考虑对象的其他属性,则需要创建一个自定义的策略来实现这一需求。
自定义集合运算策略通常涉及以下步骤:
1. 定义一个策略接口,例如`SetOperationStrategy`,其中包含处理集合运算的方法,如`intersect`和`subtract`。
2. 实现该接口以提供具体的集合运算逻辑。
3. 在需要进行集合运算的地方,使用相应的策略实现。
下面是一个自定义集合运算策略接口及其实现的简单示例:
```java
@FunctionalInterface
public interface SetOperationStrategy<T> {
Set<T> intersect(Set<T> set1, Set<T> set2);
Set<T> subtract(Set<T> minuend, Set<T> subtrahend);
}
public class CustomSetOperationExa
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Java Set集合深度解析》专栏深入剖析了Java Set集合的方方面面。从不同实现类的特性与选择,到最佳实践和性能比较,再到线程安全、内存管理和源码原理,专栏提供了全面的指南。此外,专栏还探讨了Set集合的唯一性校验、数据结构演变、高级特性、误用陷阱、流操作和扩展知识。深入理解Set集合的原理和应用,将帮助开发者有效地使用Set集合,提高代码质量和性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
永磁同步电机控制策略仿真:MATLAB_Simulink实现
# 摘要
本文概述了永磁同步电机(PMSM)的控制策略,首先介绍了MATLAB和Simulink在构建电机数学模型和搭建仿真环境中的基础应用。随后,本文详细分析了基本控制策略,如矢量控制和直接转矩控制,并通过仿真结果进行了性能对比。在高级控制策略部分,我们探讨了模糊控制和人工智能控制策略在电机仿真中的应用,并对控制策略进行了优化。最后,通过实际应用案例,验证了仿真模型的有效性,并
【编译器性能提升指南】:优化技术的关键步骤揭秘
# 摘要
编译器性能优化对于提高软件执行效率和质量至关重要。本文详细探讨了编译器前端和后端的优化技术,包括前端的词法与语法分析优化、静态代码分析和改进以及编译时优化策略,和后端的中间表示(IR)优化、指令调度与并行化技术、寄存器分配与管理。同时,本文还分析了链接器和运行时优化对性能的影响,涵盖了链接时代码优化、运行时环境的性能提升和调试工具的应用。最后,通过编译器优化案例分析与展望,本文对比了不同编译器的优化效果,并探索了机器学习技术在编译优化中的应用,为未来的优化工作指明了方向。
# 关键字
编译器优化;前端优化;后端优化;静态分析;指令调度;寄存器分配
参考资源链接:[编译原理第二版:
Catia打印进阶:掌握高级技巧,打造完美工程图输出
# 摘要
本文全面探讨了Catia软件中打印功能的应用和优化,从基本打印设置到高级打印技巧,为用户提供了系统的打印解决方案。首先概述了Catia打印功能的基本概念和工程图打印设置的基础知识,包括工程图与打印预览的使用技巧以及打印参数和布局配置。随后,文章深入介绍了高级打印技巧,包括定制打印参数、批量打印、自动化工作流以及解决打印过程中的常见问题。通过案例分析,本文探讨了工程图打印在项目管理中的实际应用,并分享了提升打印效果
快速排序:C语言中的高效稳定实现与性能测试
# 摘要
快速排序是一种广泛使用的高效排序算法,以其平均情况下的优秀性能著称。本文首先介绍了快速排序的基本概念、原理和在C语言中的基础实现,详细分析了其分区函数设计和递归调用机制。然后,本文探讨了快速排序的多种优化策略,如三数取中法、尾递归优化和迭代替代递归等,以提高算法效率。进一步地,本文研究了快速排序的高级特性,包括稳定版本的实现方法和非递归实现的技术细节,并与其他排序算法进行了比较。文章最后对快速排序的C语言代码实现进行了分析,并通过性能测
CPHY布局全解析:实战技巧与高速信号完整性分析
# 摘要
CPHY布局技术是支持高数据速率和高分辨率显示的关键技术。本文首先概述了CPHY布局的基本原理和技术要点,接着深入探讨了高速信号完整性的重要性,并介绍了分析信号完整性的工具与方法。在实战技巧方面,本文提供了CPHY布局要求、走线与去耦策略,以及电磁兼容(EMC)设计的详细说明。此外,本文通过案
四元数与复数的交融:图像处理创新技术的深度解析

# 摘要
本论文深入探讨了图像处理与数学基础之间的联系,重点分析了四元数和复数在图像处理领域内的理论基础和应用实践。首先,介绍了四元数的基本概念、数学运算以及其在图像处理中的应用,包括旋转、平滑处理、特征提取和图像合成等。其次,阐述了复数在二维和三维图像处理中的角色,涵盖傅里叶变换、频域分析、数据压缩、模型渲染和光线追踪。此外,本文探讨了四元数与复数结合的理论和应用,包括傅里叶变
【性能优化专家】:提升Illustrator插件运行效率的5大策略

# 摘要
随着数字内容创作需求的增加,对Illustrator插件性能的要求也越来越高。本文旨在概述Illustrator插件性能优化的有效方法
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )