【内核模块开发】:在Deepin Linux上打造个性化的内核模块
发布时间: 2024-09-26 22:42:58 阅读量: 154 订阅数: 39 
# 1. 内核模块开发概述
在现代操作系统中,内核模块扮演着至关重要的角色,它们是操作系统灵活性和扩展性的关键。内核模块是动态链接到Linux内核的一段代码,它允许在运行时添加或移除功能,而无需重启系统。开发者可以借助内核模块实现硬件驱动的热插拔,提高系统的可维护性与安全性。
## 1.1 内核模块的简介和重要性
内核模块是Linux内核提供的一个强大特性,它使得内核不必包含所有功能,而是只包含最基本的代码。这意味着系统管理员和开发者可以将特定的功能编译成模块,在需要时加载这些模块来扩展内核的功能。这种机制不仅减少了内核的大小,还允许用户针对特定硬件或服务定制系统。
## 1.2 内核模块的优势
内核模块的优势在于其动态性。它们使得系统管理员可以在不影响系统其他部分运行的情况下,更新或替换模块。此外,模块化的设计还使得开发者能够独立地开发和测试各自的功能模块,从而提高开发效率和代码质量。这些优势为内核的可伸缩性和安全性提供了坚实的基础。
# 2. Linux内核模块的理论基础
### 2.1 Linux内核模块的概念与结构
Linux内核模块是一种特殊类型的可加载代码,它允许开发者在不重新编译整个内核的情况下添加或删除功能。这种机制极大地提高了内核的灵活性,使得操作系统可以根据需要动态地扩展其功能。
#### 2.1.1 内核模块的作用和优点
内核模块作为一种即插即用(Plug and Play)的机制,使得硬件驱动程序和某些功能可以以模块形式独立于内核存在。它的主要作用和优点如下:
- **动态扩展性**:系统管理员和开发者可以随时加载或卸载内核模块,无需重启系统,这增加了系统的灵活性。
- **资源优化**:只加载需要的模块,可以优化系统的内存和磁盘空间使用。
- **安全更新**:模块化使得内核功能可以独立于内核主体进行更新,降低了更新带来的风险。
- **模块化开发**:内核模块促进了代码的模块化开发和维护,有利于管理大型代码库。
#### 2.1.2 内核模块的基本组成
一个基本的内核模块由以下几个部分组成:
- **模块入口和出口函数**:模块加载时执行的初始化函数`init_module()`和卸载时执行的清理函数`cleanup_module()`。
- **模块许可证声明**:声明模块遵守的许可证类型,如`GPL`。
- **模块信息**:包括模块的名称、版本和作者等信息。
- **模块依赖**:声明模块依赖于哪些其他模块。
- **内核函数与数据结构的引用**:模块运行时需要引用的内核函数和数据结构。
### 2.2 Linux内核编程环境的搭建
#### 2.2.1 开发工具的选择与配置
搭建Linux内核编程环境的首要任务是选择合适的开发工具。以下是必须的开发工具:
- **文本编辑器**:如`vim`或`emacs`。
- **编译器**:`GCC`是编译Linux内核模块的首选编译器。
- **构建工具**:如`make`和`automake`。
- **版本控制系统**:如`git`,用于源码版本管理。
- **内核头文件**:确保安装了内核头文件包,这样才能正确编译内核模块。
#### 2.2.2 内核源码的获取和编译
获取Linux内核源码通常通过官方提供的途径,如***。编译内核源码需要一定的配置步骤:
1. 下载内核源码。
2. 解压源码到一个目录,如`/usr/src/`。
3. 运行`make menuconfig`,选择编译选项。
4. 执行`make`命令进行内核编译。
5. 使用`make modules_install`安装模块。
6. 将编译好的内核`bzImage`拷贝到启动目录,如`/boot/`。
### 2.3 Linux内核模块的加载与卸载
#### 2.3.1 内核模块的编译和安装
内核模块的编译通常是在内核源码目录之外进行的,可以使用如下命令:
```bash
make -C /path/to/kernel/source M=$PWD modules
```
这个命令会在当前目录编译模块,`$PWD`是当前工作目录。成功编译后,使用`insmod`命令加载模块:
```bash
insmod module.ko
```
#### 2.3.2 使用insmod、rmmod、lsmod等命令操作模块
加载模块后,可以使用`lsmod`查看已加载的模块列表:
```bash
lsmod
```
当不再需要模块时,可以使用`rmmod`来卸载它:
```bash
rmmod module_name
```
此外,`modprobe`是一个更智能的加载和卸载模块的工具,它可以自动处理模块的依赖关系。
以上内容展示了Linux内核模块的理论基础。在第二章中,我们详细地介绍了内核模块的概念、作用、优点和基本结构,接着讲解了如何搭建Linux内核编程环境,并提供了内核源码的获取和编译指南。最后,阐述了内核模块加载与卸载的基本步骤和相关命令,为读者深入理解和操作Linux内核模块打下了坚实的基础。
# 3. 编写内核模块的实践过程
## 3.1 编写第一个内核模块
### 3.1.1 Hello World模块的实现
编写一个内核模块并不复杂,我们从一个经典的“Hello World”模块开始。这个模块的工作是在加载时打印一条消息到内核日志,然后在卸载时删除这条消息。
首先创建一个新的C文件,名为 `hello_world.c`,并添加如下代码:
```c
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("A simple example Linux module.");
MODULE_VERSION("0.01");
static int __init hello_start(void) {
printk(KERN_INFO "Loading hello module...\n");
printk(KERN_INFO "Hello world\n");
return 0;
}
static void __exit hello_end(void) {
printk(KERN_INFO "Goodbye Mr.\n");
}
module_init(hello_start);
module_exit(hello_end);
```
在这段代码中,`__init`和`__exit`宏定义了模块初始化和清理函数。`MODULE_LICENSE`定义了模块的许可证,`MODULE_AUTHOR`定义了作者信息,而`MODULE_DESCRIPTION`和`MODULE_VERSION`提供了模块的描述和版本信息。`printk`函数用于向内核日志缓冲区写入信息,其中`KERN_INFO`是一个日志级别。
要编译这个模块,还需要一个Makefile,内容如下:
```makefile
obj-m += hello_world.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
```
这个Makefile使用内核构建系统来编译模块。它首先确定当前运行的内核版本,然后调用相应的内核构建工具来编译模块。
### 3.1.2 模块加载和卸载的调试
加载和卸载模块,使用 `insmod` 和 `rmmod` 命令:
```bash
sudo insmod hello_world.ko
sudo rmmod hello_world
```
加载模块后,查看内核日志,可使用 `dmesg` 命令:
```bash
dmesg | tail
```
这将显示模块加载和卸载时的打印信息。如果你看到 "Hello world" 和 "Goodbye Mr." 消息,说明你的模块正常工作。
### 3.2.1 模块参数的传递与处理
为了使模块更加灵活,可以接受参数。修改 `hello_world.c` 添加模块参数功能:
```c
static int myint = 0;
module_param(myint, int, 0644);
static char *mystr = "world";
module_param(mystr, charp, 0644);
static int __init hello_start(void) {
printk(KERN_INFO "Loading hello module...\n");
printk(KERN_INFO "Hello, %s, with int: %d\n", mystr, myint);
return 0;
}
```
现在你可以加载模块并传入参数:
```bash
sudo insmod hello_world.ko myint=10 mystr="everyone"
```
这个模块的 `dmesg` 输出将包含你传入的参数值。
### 3.2.2 导出符号和模块依赖
导出符号(exported symbol)允许其他模块知道并使用你的模块功能。使用 `EXPORT_SYMBOL` 或 `EXPORT_SYMBOL_GPL` 宏导出符号。模块依赖可以通过 `depends` 指令在Makefile中声明。
通过向内核模块添加参数、导出符号和管理模块依赖,我们可以让模块更加强大和灵活,从而更好地适应不同的系统配置和使用场景。
### 3.3.1 设备驱动的基本框架
设备驱动编程是内核模块编程的重要组成部分,设备驱动的基本框架包括入口函数(probe)和出口函数(remo

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Deepin Linux专栏深入探讨了Deepin Linux操作系统的方方面面,为用户提供高级技巧和专业知识。从应用商店的使用秘籍到软件管理的精通,从性能调优到文件系统优化,该专栏涵盖了广泛的主题。此外,它还提供了故障排查和维护指南,以及内核模块开发的教程,帮助用户解决系统问题并创建个性化的内核模块。通过深入浅出的讲解和实用的建议,该专栏旨在帮助用户充分利用Deepin Linux,提升他们的使用体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
紧急揭秘!防止Canvas转换中透明区域变色的5大技巧

# 摘要
Canvas作为Web图形API,广泛应用于现代网页设计与交互中。本文从Canvas转换技术的基本概念入手,深入探讨了在渲染过程中透明区域变色的理论基础和实践解决方案。文章详细解析了透明度和颜色模型,渲染流程以及浏览器渲染差异,并针对性地提供了预防透明区域变色的技巧。通过对Canvas上下文优化
超越MFCC:BFCC在声学特征提取中的崛起

# 摘要
声学特征提取是语音和音频处理领域的核心,对于提升识别准确率和系统的鲁棒性至关重要。本文首先介绍了声学特征提取的原理及应用,着重探讨
Flutter自定义验证码输入框实战:提升用户体验的开发与优化

# 摘要
本文详细介绍了在Flutter框架中实现验证码输入框的设计与开发流程。首先,文章探讨了验证码输入框在移动应用中的基本实现,随后深入到前端设计理论,强调了用户体验的重
光盘刻录软件大PK:10个最佳工具,找到你的专属刻录伙伴
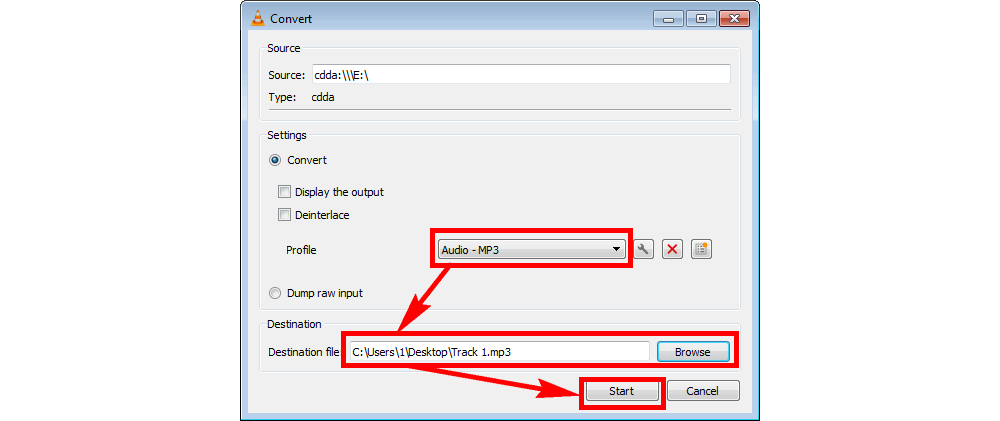
# 摘要
本文全面介绍了光盘刻录技术,从技术概述到具体软件选择标准,再到实战对比和进阶优化技巧,最终探讨了在不同应用场景下的应用以及未来发展趋势。在选择光盘刻录软件时,本文强调了功能性、用户体验、性能与稳定性的重要性。此外,本文还提供了光盘刻录的速度优化、数据安全保护及刻录后验证的方法,并探讨了在音频光盘制作、数据备份归档以及多媒体项目中的应用实例。最后,文章展望了光盘刻录技术的创
【FANUC机器人接线实战教程】:一步步教你完成Process IO接线的全过程
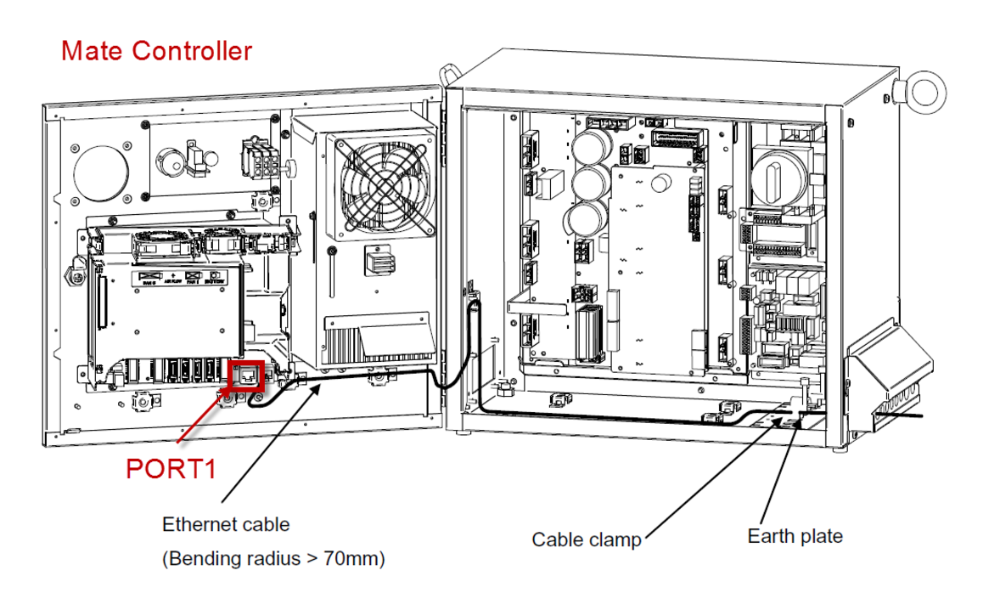
# 摘要
本文系统地介绍了FANUC机器人接线的基础知识、操作指南以及故障诊断与解决策略。首先,章节一和章节二深入讲解了Process IO接线原理,包括其优势、硬件组成、电气接线基础和信号类型。随后,在第三章中,提供了详细的接线操作指南,从准备工作到实际操作步骤,再到安全操作规程与测试,内容全面而细致。第四章则聚焦于故障诊断与解决,提供了一系列常见问题的分析、故障排查步骤与技巧,以及维护和预防措施
ENVI高光谱分析入门:3步掌握波谱识别的关键技巧

# 摘要
本文全面介绍了ENVI高光谱分析软件的基础操作和高级功能应用。第一章对ENVI软件进行了简介,第二章详细讲解了ENVI用户界面、数据导入预处理、图像显示与分析基础。第三章讨论了波谱识别的关键步骤,包括波谱特征提取、监督与非监督分类以及分类结果的评估与优化。第四章探讨了高级波谱分析技术、大数据环境下的高光谱处理以及ENVI脚本
ISA88.01批量控制核心指南:掌握制造业自动化控制的7大关键点

# 摘要
本文详细介绍了ISA88.01批量控制标准的理论基础和实际应用。首先,概述了ISA88.01标准的结构与组件,包括基本架构、核心组件如过程模块(PM)、单元模块(UM)
【均匀线阵方向图优化手册】:提升天线性能的15个实战技巧
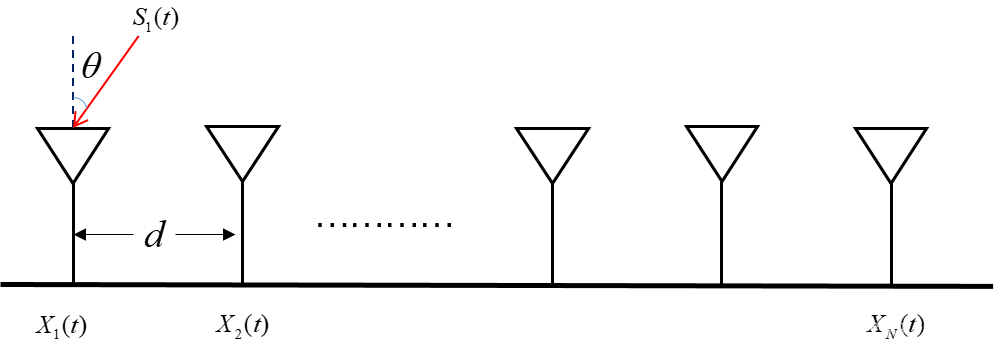
# 摘要
本文系统地介绍了均匀线阵天线的基础知识、方向图优化理论基础、优化实践技巧、系统集成与测试流程,以及创新应用。文章首先概述了均匀线阵天线的基本概念和方向图的重要性,然后
STM32F407 USB通信全解:USB设备开发与调试的捷径

# 摘要
本论文深入探讨了STM32F407微控制器在USB通信领域的应用,涵盖了从基础理论到高级应用的全方位知识体系。文章首先对USB通信协议进行了详细解析,并针对STM32F407的USB硬件接口特性进行了介绍。随后,详细阐述了USB设备固件开发流程和数据流管理,以及USB通信接口编程的具体实现。进一步地,针对USB调试技术和故障诊断、性能优化进行了系统性分析。在高级应用部分,重点介绍了USB主
车载网络诊断新趋势:SAE-J1939-73在现代汽车中的应用
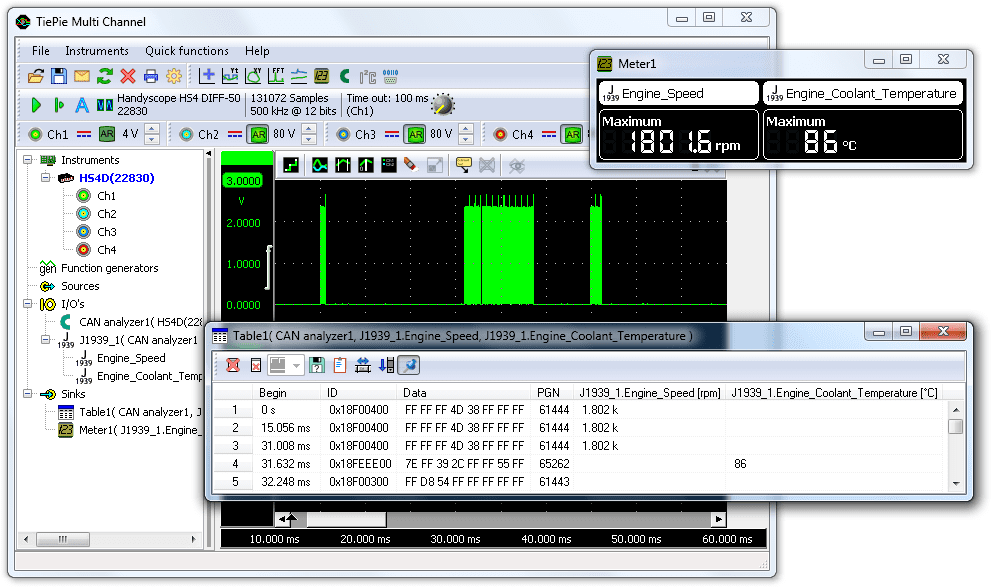
# 摘要
随着汽车电子技术的发展,车载网络诊断技术变得日益重要。本文首先概述了车载网络技术的演进和SAE-J1939标准及其子标准SAE-J1939-73的角色。接着深入探讨了SAE-J1939-73标准的理论基础,包括数据链路层扩展、数据结构、传输机制及诊断功能。文章分析了SAE-J1939-73在现代汽车诊断中的实际应用,车载网络诊断工具和设备,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )