【Deepin Linux软件管理】:精通APT与DPKG的高级应用
发布时间: 2024-09-26 21:53:58 阅读量: 84 订阅数: 39 
# 1. Linux软件管理概述
## 1.1 Linux软件管理的重要性
Linux作为强大的开源操作系统,其软件管理机制对于系统的稳定性和可扩展性起着至关重要的作用。它不仅影响着系统更新、软件安装和卸载的效率,还决定了系统安全性和用户的工作流程。
## 1.2 Linux软件管理的方法论
Linux环境下的软件管理方法多样,包括从包管理器到构建自定义软件包仓库等。这些方法帮助用户高效地管理和优化他们的Linux环境,从而使得软件安装、更新和维护变得简单而直接。
## 1.3 软件管理的挑战与机遇
随着Linux社区的发展,我们看到各种新的软件管理工具和技术不断涌现,这为用户带来了更多的选择。然而,如何在众多工具中选择最适合自己的,并有效应对软件供应链的安全挑战,是Linux用户和管理员当前面临的重要课题。
在下一章中,我们将深入探讨Linux系统中最为广泛使用的APT包管理器,了解其架构、工作原理以及它如何简化软件包的安装、更新和管理任务。
# 2. 掌握APT包管理器
## 2.1 APT的基础知识
### 2.1.1 APT的架构和工作原理
APT(Advanced Package Tool)包管理器是Debian及其衍生系统中广泛使用的高级软件包工具。APT为用户提供了更加简洁和直观的方式来安装、升级、配置和卸载软件包。它通过建立在dpkg之上的高速缓存和元数据索引来实现这些功能,这使得APT能够对软件包的依赖关系进行智能处理和解析。
APT的架构主要由以下组件构成:
- **软件源(Sources List)**:定义了APT从哪些服务器获取软件包信息的配置文件。
- **本地高速缓存(Local Cache)**:APT会下载远程软件仓库中的索引文件到本地,并将其存储在本地高速缓存中,用于快速访问和处理依赖关系。
- **状态文件(Status File)**:记录了本地系统上所有已安装软件包的状态信息,用于处理升级操作。
- **下载器(Downloader)**:负责从软件源下载软件包到本地。
- **包管理后端(dpkg)**:处理实际的软件包安装、卸载和配置。
APT工作原理基于以下几个步骤:
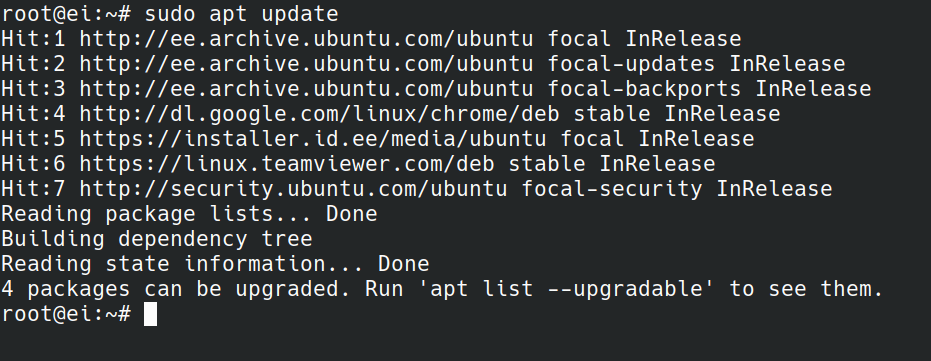
1. **更新软件源信息**:用户首先需要通过`sudo apt update`命令更新本地高速缓存,确保APT能够访问到最新的软件包和依赖信息。
2. **搜索和安装软件包**:通过`sudo apt install <package_name>`命令,用户可以安装软件包。APT会自动处理软件包之间的依赖关系。
3. **升级软件包**:使用`sudo apt upgrade`命令升级系统中的软件包。APT会计算出需要升级的软件包,并在满足依赖关系的情况下进行升级操作。
4. **移除软件包**:通过`sudo apt remove <package_name>`命令,用户可以卸载不需要的软件包。
### 2.1.2 APT的主要命令和功能
APT提供了一系列命令来帮助用户管理软件包,以下是一些常用命令及其功能:
- `sudo apt update`:更新软件源列表并获取最新的软件包状态信息。
- `sudo apt upgrade`:升级所有可升级的软件包到最新版本。
- `sudo apt install <package_name>`:安装指定的软件包。
- `sudo apt remove <package_name>`:移除已安装的软件包。
- `sudo apt autoremove`:删除不再需要的软件包。
- `sudo apt full-upgrade`:在软件包升级过程中进行更彻底的处理,包括处理被替换的软件包等。
- `sudo apt search <package_name>`:搜索远程仓库中的软件包。
- `sudo apt show <package_name>`:显示远程仓库中软件包的详细信息。
这些命令构成了APT包管理器的基础,为用户提供了强大的软件包管理能力。通过这些基本命令,用户可以轻松地安装、更新和维护其Linux系统中的软件。
## 2.2 APT高级操作技巧
### 2.2.1 高级搜索和过滤功能
APT提供了强大的搜索和过滤功能,可以帮助用户快速找到需要的软件包。这包括了使用正则表达式、过滤特定的软件包状态或版本等多种搜索方式。
例如,以下命令展示了如何利用APT进行高级搜索:
- `sudo apt search 'linux-image'`:搜索所有包含`linux-image`的软件包。
- `sudo apt list --upgradable`:列出所有可以升级的软件包。
- `apt list --installed | grep apache2`:列出已安装的包含`apache2`关键字的软件包。
这些高级搜索技巧对于快速定位和管理软件包非常有用,特别是在需要更新或卸载多个软件包时。
### 2.2.2 代理设置和性能优化
在某些环境下,例如网络受限或者需要通过代理访问外部仓库时,需要配置APT来通过代理服务器连接到互联网。可以通过编辑`/etc/apt/apt.conf`文件来设置APT的代理信息:
```bash
Acquire::*** "***";
Acquire::*** "***";
```
性能优化可以通过调整缓存大小、更新间隔、使用多线程下载等来实现。例如,`/etc/apt/apt.conf`文件中还可以设置如下:
```bash
APT::Cache-Limit ***; # 缓存大小限制
APT::Never-Interest-Size 1000; # 不感兴趣包大小限制
```
### 2.2.3 APT的源管理
在使用APT时,配置软件源是很重要的一步。用户可以通过编辑`/etc/apt/sources.list`文件或创建`.list`文件在`/etc/apt/sources.list.d/`目录下,来添加或修改软件源。
例如,添加Debian官方的稳定版仓库到`sources.list`文件中:
```plaintext
deb ***
```
使用多个软件源时,`apt`命令会根据优先级选择软件包版本。可以通过`Pin-Priority`设置来控制不同软件源的优先级。例如,如果需要指定Debian稳定版的优先级高于测试版,可以添加如下配置:
```plaintext
deb ***
```
在本章节中,通过介绍APT包管理器的基础知识、架构和工作原理,我们能够理解APT如何为Linux系统带来强大的软件包管理能力。接着,高级操作技巧的讲解,进一步展示了APT的灵活性和实用性。这为进一步深入学习和有效利用APT提供了坚实的基础。在后续章节中,我们将进一步探讨如何在不同场景下应用这些技巧,以及如何与DPKG等其他工具配合使用,以实现更为精细和复杂的软件包管理。
# 3. 深入DPKG工具
## 3.1 DPKG的内部机制
### 3.1.1 DPKG的工作流程
`dpkg` 是 Debian 及其衍生系统(包括 Deepin Linux)中用于安装、构建、删除和管理软件包的底层工具。它负责处理 `.deb` 软件包的安装和维护。
以下是 `dpkg` 的基本工作流程:
1. **依赖性检查**:在安装前,`dpkg` 会检查软件包的依赖性,并报告任何缺失的依赖。
2. **配置**:`dpkg` 确保所有必要的配置文件都已就绪,并且可以正确地进行设置。
3. **安装**:将软件包内的文件解压到系统目录中。
4. **脚本执行**:运行配置脚本,如 `preinst`(安装前)、`postinst`(安装后)、`prerm`(删除前)和 `postrm`(删除后)。
5. **维护**:更新软件包数据库,记录安装的文件和版本信息。
### 3.1.2 DPKG的配置文件解析
DPKG 使用 `/var/lib/dpkg/info/` 目录下的文件来存储每个软件包的信息。这些信息包括控制文件、状态文件和脚本。
- **控制文件**:包含软件包的元数据,如软件包描述、版本、维护者信息、依赖关系等。
- **状态文件**:记录了软件包的安装状态,包括其版本、安装位置、配置文件是否被修改过等。
- **脚本文件**:用于处理软件包的安装、卸载、更新等过程中的脚本。
## 3.2 DPKG的高级操作
### 3.2.1 手动安装和配置软件包
尽管 `dpkg` 不直接处理软件包的依赖问题(这通常是 `apt` 的工作),但我们可以使用 `dpkg` 手动安装 `.deb` 包。
```bash
sudo dpkg -i package.deb
```
**参数说明**:
- `-i`:安装包。
- `package.deb`:指定软件包文件。
在安装过程中,如果遇到依赖问题,需要手动解决依赖并

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Deepin Linux专栏深入探讨了Deepin Linux操作系统的方方面面,为用户提供高级技巧和专业知识。从应用商店的使用秘籍到软件管理的精通,从性能调优到文件系统优化,该专栏涵盖了广泛的主题。此外,它还提供了故障排查和维护指南,以及内核模块开发的教程,帮助用户解决系统问题并创建个性化的内核模块。通过深入浅出的讲解和实用的建议,该专栏旨在帮助用户充分利用Deepin Linux,提升他们的使用体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
紧急揭秘!防止Canvas转换中透明区域变色的5大技巧

# 摘要
Canvas作为Web图形API,广泛应用于现代网页设计与交互中。本文从Canvas转换技术的基本概念入手,深入探讨了在渲染过程中透明区域变色的理论基础和实践解决方案。文章详细解析了透明度和颜色模型,渲染流程以及浏览器渲染差异,并针对性地提供了预防透明区域变色的技巧。通过对Canvas上下文优化
超越MFCC:BFCC在声学特征提取中的崛起

# 摘要
声学特征提取是语音和音频处理领域的核心,对于提升识别准确率和系统的鲁棒性至关重要。本文首先介绍了声学特征提取的原理及应用,着重探讨
Flutter自定义验证码输入框实战:提升用户体验的开发与优化

# 摘要
本文详细介绍了在Flutter框架中实现验证码输入框的设计与开发流程。首先,文章探讨了验证码输入框在移动应用中的基本实现,随后深入到前端设计理论,强调了用户体验的重
光盘刻录软件大PK:10个最佳工具,找到你的专属刻录伙伴
# 摘要
本文全面介绍了光盘刻录技术,从技术概述到具体软件选择标准,再到实战对比和进阶优化技巧,最终探讨了在不同应用场景下的应用以及未来发展趋势。在选择光盘刻录软件时,本文强调了功能性、用户体验、性能与稳定性的重要性。此外,本文还提供了光盘刻录的速度优化、数据安全保护及刻录后验证的方法,并探讨了在音频光盘制作、数据备份归档以及多媒体项目中的应用实例。最后,文章展望了光盘刻录技术的创
【FANUC机器人接线实战教程】:一步步教你完成Process IO接线的全过程
# 摘要
本文系统地介绍了FANUC机器人接线的基础知识、操作指南以及故障诊断与解决策略。首先,章节一和章节二深入讲解了Process IO接线原理,包括其优势、硬件组成、电气接线基础和信号类型。随后,在第三章中,提供了详细的接线操作指南,从准备工作到实际操作步骤,再到安全操作规程与测试,内容全面而细致。第四章则聚焦于故障诊断与解决,提供了一系列常见问题的分析、故障排查步骤与技巧,以及维护和预防措施
ENVI高光谱分析入门:3步掌握波谱识别的关键技巧

# 摘要
本文全面介绍了ENVI高光谱分析软件的基础操作和高级功能应用。第一章对ENVI软件进行了简介,第二章详细讲解了ENVI用户界面、数据导入预处理、图像显示与分析基础。第三章讨论了波谱识别的关键步骤,包括波谱特征提取、监督与非监督分类以及分类结果的评估与优化。第四章探讨了高级波谱分析技术、大数据环境下的高光谱处理以及ENVI脚本
ISA88.01批量控制核心指南:掌握制造业自动化控制的7大关键点

# 摘要
本文详细介绍了ISA88.01批量控制标准的理论基础和实际应用。首先,概述了ISA88.01标准的结构与组件,包括基本架构、核心组件如过程模块(PM)、单元模块(UM)
【均匀线阵方向图优化手册】:提升天线性能的15个实战技巧
# 摘要
本文系统地介绍了均匀线阵天线的基础知识、方向图优化理论基础、优化实践技巧、系统集成与测试流程,以及创新应用。文章首先概述了均匀线阵天线的基本概念和方向图的重要性,然后
STM32F407 USB通信全解:USB设备开发与调试的捷径

# 摘要
本论文深入探讨了STM32F407微控制器在USB通信领域的应用,涵盖了从基础理论到高级应用的全方位知识体系。文章首先对USB通信协议进行了详细解析,并针对STM32F407的USB硬件接口特性进行了介绍。随后,详细阐述了USB设备固件开发流程和数据流管理,以及USB通信接口编程的具体实现。进一步地,针对USB调试技术和故障诊断、性能优化进行了系统性分析。在高级应用部分,重点介绍了USB主
车载网络诊断新趋势:SAE-J1939-73在现代汽车中的应用
# 摘要
随着汽车电子技术的发展,车载网络诊断技术变得日益重要。本文首先概述了车载网络技术的演进和SAE-J1939标准及其子标准SAE-J1939-73的角色。接着深入探讨了SAE-J1939-73标准的理论基础,包括数据链路层扩展、数据结构、传输机制及诊断功能。文章分析了SAE-J1939-73在现代汽车诊断中的实际应用,车载网络诊断工具和设备,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )