Python异常处理秘籍:从新手入门到专家级自定义异常
发布时间: 2024-10-01 15:18:56 阅读量: 8 订阅数: 17 
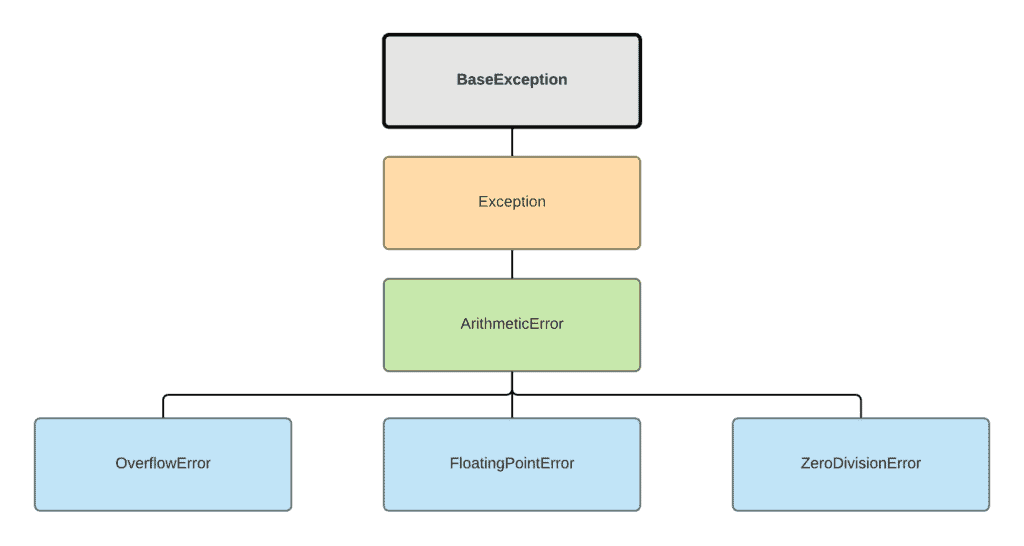
# 1. Python异常处理的基本概念
在编程的世界里,错误和异常是不可避免的。Python异常处理是程序设计的一个重要部分,它帮助开发者维护程序的稳定性和可预测性。异常处理允许程序在遇到运行时错误时能够优雅地处理,而不是直接崩溃。理解异常处理的基本概念是构建健壮、可维护的代码库的基石。
本章我们将首先探讨异常是如何在Python中定义的,以及它们与程序流程控制的关系。我们将了解到异常是如何中断程序正常流程,并介绍Python异常处理的基本元素,如`try`, `except`, `else`, 和 `finally`语句。在进入更高级的异常处理实践之前,让我们先打下坚实的基础。
# 2. 异常处理的基础实践
## 2.1 Python的内置异常类型
### 2.1.1 常见的内置异常及其用途
Python为开发者提供了丰富的内置异常类型,这些异常可以覆盖大多数常见的错误情况。当程序运行遇到问题时,Python解释器会抛出相应的异常。这里是一些常见的内置异常及其用途的概述:
- `SyntaxError`:当代码中存在语法错误时抛出。
- `TypeError`:当操作或函数应用于不适当的类型时抛出。
- `ValueError`:当函数得到正确类型的参数,但参数值不合适时抛出。
- `IOError`:当输入/输出操作失败时抛出,比如文件无法打开。
- `IndexError`:当使用不存在的索引访问序列时抛出。
- `KeyError`:当访问字典中不存在的键时抛出。
- `AttributeError`:当尝试访问对象不存在的属性或方法时抛出。
每种异常都有其特定的场景,正确理解和使用它们是编写健壮代码的关键。例如,如果你在一个循环中期望找到某个值,但最终没有找到,那么抛出`ValueError`比抛出`IndexError`更准确,因为`IndexError`通常意味着索引超出了序列的范围。
### 2.1.2 如何捕获和处理内置异常
处理内置异常通常涉及使用`try...except`语句。这种语句可以捕获特定的异常并对其做出响应,这样即使发生了错误,程序也可以优雅地继续执行。下面是一个捕获和处理内置异常的例子:
```python
try:
# 尝试执行一些可能会抛出异常的代码
result = 10 / 0
except ZeroDivisionError as e:
# 这里处理特定的异常,这里是除以零的情况
print(f"捕获到异常:不能除以零,错误信息:{e}")
finally:
# 这部分代码无论是否发生异常都会执行
print("这总是会被执行")
```
在上面的代码中,我们尝试除以零,这将抛出`ZeroDivisionError`异常。我们通过`except`子句捕获这个异常,并打印出一条错误信息。`finally`子句确保了无论是否发生异常,最后的打印语句都会执行。
### 2.2 理解和使用try-except语句
#### 2.2.1 try-except的基本语法
`try...except`语句是Python异常处理的核心结构。它允许开发者对可能抛出异常的代码进行监控,并在异常发生时执行特定的代码块。以下是一个简单的例子:
```python
try:
# 尝试执行的代码
result = 10 / some_variable
except Exception as e:
# 如果try块中的代码抛出异常,则执行这里的代码
print(f"发生了一个错误:{e}")
```
在这个例子中,`try`块包含可能会抛出异常的代码。如果在`try`块中的代码执行期间发生异常,`except`块会被执行。`Exception`是一个通用的异常类,可以捕获大多数的异常。
#### 2.2.2 多个except子句的使用和注意事项
在复杂的程序中,你可能希望对不同的异常做出不同的响应。这时可以使用多个`except`子句来捕获和处理不同的异常:
```python
try:
# 尝试执行的代码
result = 10 / some_variable
except ZeroDivisionError:
# 特定处理除零错误
print("错误:不能除以零")
except NameError:
# 特定处理未定义的变量错误
print("错误:未定义变量")
except Exception as e:
# 捕获所有其他异常
print(f"发生了一个未知错误:{e}")
```
使用多个`except`子句时,需要注意异常捕获的顺序。Python解释器从上到下依次检查每个`except`子句,一旦某个子句匹配了异常类型,就会执行该子句,并且不会再检查后续的`except`子句。因此,你需要将特定的异常类型放在前面,通用的异常类型放在后面。
#### 2.2.3 else和finally子句的高级用法
`try...except`语句还包含`else`和`finally`子句,它们提供了额外的控制逻辑。
`else`子句只有在`try`块没有异常发生时才会执行:
```python
try:
# 尝试执行的代码
result = 10 / some_variable
except ZeroDivisionError:
print("错误:不能除以零")
else:
# 当try块没有异常时执行
print("除法成功完成,结果是:", result)
```
`finally`子句无论是否发生异常都会执行:
```python
try:
# 尝试执行的代码
result = 10 / some_variable
except ZeroDivisionError:
print("错误:不能除以零")
finally:
# 无论是否发生异常都会执行
print("这是最后执行的代码")
```
`finally`子句通常用于清理资源,例如关闭文件、释放锁等,以确保即使发生异常,程序也能保持一致的状态。
异常处理是Python编程中不可或缺的一部分。理解如何有效地使用`try-except`语句,可以帮助你编写更加健壮和易于维护的代码。通过捕获和处理异常,你的程序将能够优雅地处理错误情况,而不是完全崩溃。
# 3. 异常处理的高级技巧
## 3.1 异常的抛出和传递
异常处理不仅涉及捕捉和处理异常,还包括如何有效地抛出异常以及在代码中传递异常。理解如何正确地抛出和传递异常对于编写健壮的代码至关重要。
### 3.1.1 如何在函数中抛出异常
在Python中,可以通过`raise`关键字来抛出一个异常。当函数遇到无法处理的情况时,应该抛出一个异常以通知调用者存在错误。例如:
```python
def divide(dividend, divisor):
if divisor == 0:
raise ValueError("除数不能为0")
return dividend / divisor
```
在这个函数中,如果`divisor`为0,那么会抛出一个`ValueError`异常。这个异常将被抛出并传递给函数的调用者,调用者需要负责处理这个异常。这是异常传递的基本方式。
### 3.1.2 异常的捕获和传递机制
异常的捕获和传递通常涉及`try-except`块。如果你在一个函数中捕获了异常,并决定不处理它,那么你可以使用`raise`关键字将异常重新抛出。这样,异常就会被传递到更高的调用层次。以下是一个例子:
```python
def validate_data(data):
try:
if not isinstance(data, dict):
raise TypeError("数据必须是一个字典")
except TypeError as e:
print(f"数据验证失败: {e}")
raise # 重新抛出捕获的异常
try:
validate_data("不是字典类型的数据")
except TypeError as e:
print(f"函数调用者捕获了异常: {e}")
```
在这个例子中,`validate_data`函数检查传入的`data`是否是一个字典。如果不是,它会捕获`TypeError`并打印一条错误消息,然后使用`raise`重新抛出异常。这个异常随后被外部的`try-except`块捕获。
理解异常的这种传递机制可以帮助我们更好地控制异常处理流程,确保异常在合适的地方被妥善处理。
## 3.2 使用上下文管理器处理异常
上下文管理器是处理异常的一个强大工具,它们主要通过`with`语句提供一种方式,以确保资源被适当管理和释放,即使在发生异常的情况下。
### 3.2.1 上下文管理器的基本原理
上下文管理器定义了一个在代码块执行前后执行的协议,即实现了`__enter__()`和`__exit__()`方法的对象。`__enter__()`方法在进入`with`代码块时被调用,而`__exit__()`方法在退出代码块时被调用,无论是正常退出还是因为异常退出。
以下是一个简单的上下文管理器示例:
```python
class Managed***
***
***
***
*** 'w')
return self.file
def __exit__(self, exc_type, exc_val, exc_tb):
if self.***
***
***'somefile.txt') as f:
f.write('这里是一些内容。')
```
在这个例子中,`ManagedFile`是一个上下文管理器,它打开一个文件并返回文件对象给`with`代码块。无论在`with`代码块中发生什么,`__exit__()`方法都会被调用,并且文件会自动关闭。
### 3.2.2 with语句的高级用法
`with`语句可以和任何实现了`__enter__()`和`__exit__()`方法的对象一起使用。这意味着我们可以创建自定义的上下文管理器来处理特定的资源管理或异常处理逻辑。
一个高级用法的例子是结合异常处理和文件操作:
```python
class ErrorHandle***
***
***
***
*** 'w')
return self.file
def __exit__(self, exc_type, exc_val, exc_tb):
if self.***
***
***"在处理文件时发生异常: {exc_val}")
self.file.close()
with ErrorHandleFile('errorfile.txt') as f:
f.write('这里是一些内容。')
raise ValueError("这是示例中故意抛出的异常")
```
在这个例子中,`ErrorHandleFile`上下文管理器在异常发生时提供了一个机会来执行额外的错误处理逻辑。如果在`with`代码块中发生了异常,`__exit__()`方法将打印一条消息,并且文件仍然会被关闭。
通过这种方式,`with`语句和上下文管理器提供了一种简洁而强大的方法来管理资源和异常,使得代码更加清晰和健壮。
## 3.3 使用日志记录异常
日志记录是跟踪和诊断程序运行中出现问题的有用工具。正确地记录异常可以提供宝贵的调试信息,帮助开发者理解异常发生的上下文。
### 3.3.1 配置日志记录器
Python的`logging`模块提供了灵活的日志记录系统。首先,我们需要配置一个日志记录器来指定日志的格式和级别。
```python
import logging
# 配置日志记录器
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
# 记录一些信息
logging.debug('这是一个调试信息。')
***('这是一个常规信息。')
logging.warning('这是一个警告信息。')
```
上述代码段将配置基础的日志记录器来记录调试信息、常规信息和警告信息。日志消息将包括时间戳、日志级别和实际消息内容。
### 3.3.2 记录和追踪异常信息
在异常处理中,记录异常信息是非常重要的。使用`try-except`块捕获异常,并使用`logging`记录异常详情:
```python
try:
# 可能会引发异常的代码
result = 10 / 0
except Exception as e:
logging.error("发生除零错误", exc_info=True)
```
在这个例子中,如果发生除零错误,`logging.error()`会记录错误信息,并且`exc_info=True`参数会让`logging`模块记录异常的堆栈跟踪信息。这为追踪异常发生的具体位置和原因提供了极大的帮助。
正确的异常日志记录不仅可以帮助定位和修复当前问题,也可以在将来的开发和维护中提供有用的信息。
通过本章节的介绍,我们已经深入探讨了异常处理的高级技巧,包括异常的抛出与传递、上下文管理器的使用以及如何利用日志记录异常信息。这些技巧和实践是编写健壮且易于维护的Python程序不可或缺的一部分。
# 4. ```
# 第四章:异常处理的最佳实践
在软件开发中,异常处理不仅仅是为了编写可以处理错误的代码,更是为了增强程序的健壮性和可维护性。本章节将从设计原则出发,介绍异常处理的最佳实践,帮助开发者避免在实际应用中的常见误区,并确保代码的健壮性。
## 4.1 异常处理的设计原则
### 4.1.1 理解何时使用异常处理
异常处理是编程中的一个重要方面,它允许程序在遇到意外情况时以一种有控制的方式进行响应。在Python中,异常处理通常使用try-except语句。然而,并非所有的错误都应通过异常来处理。以下是应当使用异常处理的一些原则:
- 当错误发生时,程序无法继续正常运行,应当使用异常处理来通知调用者。
- 避免使用异常处理来控制程序逻辑。这会导致程序执行流程变得不可预测,增加维护的难度。
- 不要捕获一个异常除非你能够处理它。通常,这意味着异常应当被传递到更高层的处理代码。
### 4.1.2 异常处理的性能考量
异常处理可能会带来额外的性能开销,因为它涉及到堆栈跟踪和异常对象的创建。因此,在设计异常处理策略时,应考虑以下因素:
- 避免在循环内部使用异常处理,尤其是频繁执行的循环。在循环中进行异常处理会大大降低代码的性能。
- 只捕获你能够处理的异常。不必要的异常捕获会增加代码的复杂性,同时也会带来性能上的损耗。
- 使用日志记录异常信息而不是打印它们,这样可以避免在每次异常发生时都进行I/O操作。
## 4.2 异常处理中的常见误区和解决方案
### 4.2.1 避免使用异常进行流程控制
在某些情况下,开发者可能会滥用异常处理来进行程序的流程控制,这是不推荐的做法。例如,使用异常处理来实现分支逻辑或循环控制,这会掩盖程序中的正常流程,使得代码难以理解和维护。正确的做法是使用常规的条件语句和循环结构来处理正常的程序流程。
### 4.2.2 正确处理和清理资源
在使用资源(如文件操作、网络连接等)时,应当确保在出现异常的情况下,资源能够得到正确的处理和清理。Python提供了`finally`子句来确保无论是否发生异常,资源都能够被释放:
```python
try:
open('file.txt', 'w')
except IOError as e:
print(f"IOError: {e}")
finally:
print("Resources are cleaned up.")
```
## 4.3 实现健壮的代码
### 4.3.1 测试和验证异常处理
编写异常处理代码后,必须进行彻底的测试,以确保异常处理逻辑可以正确地执行。自动化测试可以捕捉到许多在手工测试中可能遗漏的异常场景。
- 编写单元测试时,使用mock对象模拟可能抛出异常的操作。
- 在集成测试中模拟外部系统的行为,确保异常处理代码能够被触发。
### 4.3.2 编写可读性强和可维护的异常代码
为了编写出高质量的异常处理代码,应当遵循一些通用的编码准则:
- 确保异常信息清晰,并包含足够的上下文,以便于问题的诊断和解决。
- 不要过度捕获异常。如果无法在当前代码块中处理异常,应当将异常传递到上层调用者。
- 使用自定义异常来表示应用程序特定的错误情况。这使得异常处理代码更加直观,并且有助于在不同层之间传递错误信息。
接下来的章节将深入探讨异常处理的进阶应用,包括在并发编程和网络安全中的使用,以及如何与第三方库结合以实现更复杂的异常管理策略。
```
以上就是关于“异常处理的最佳实践”这一章节的内容,它涵盖了异常处理的设计原则、常见误区与解决方案,以及如何实现健壮代码的细节性内容。这些知识能够帮助开发者在实践中更加高效、正确地使用异常处理机制。
# 5. 异常处理的进阶应用
在了解了Python异常处理的基础和高级技巧后,本章将探讨异常处理在进阶应用中的具体实践。我们将从并发编程、网络安全和第三方库的使用三个维度深入探讨异常处理在不同场景下的应用。
## 5.1 异常与并发编程
并发编程是现代软件开发中一个重要的领域,异常处理在这一领域扮演着至关重要的角色。在多线程和多进程环境中,正确的异常处理机制能够保障程序的健壮性并提高用户体验。
### 5.1.1 在多线程和多进程环境中处理异常
多线程和多进程环境中,线程或进程可能会因为各种原因产生异常。为了确保异常不会导致整个程序崩溃,我们通常在程序中设置异常处理器来捕获和处理这些异常。
```python
import threading
import traceback
def thread_function(name):
"""线程运行函数"""
print(f'Thread {name}: starting')
try:
# 模拟异常的代码
raise RuntimeError(f'Thread {name}: error occurred')
except Exception as e:
# 异常捕获
print(f'Thread {name}: {e}')
traceback.print_exc() # 打印异常信息
# 创建线程
thread1 = threading.Thread(target=thread_function, args=(1,))
thread2 = threading.Thread(target=thread_function, args=(2,))
# 启动线程
thread1.start()
thread2.start()
# 等待所有线程完成
thread1.join()
thread2.join()
```
在上述代码中,定义了一个线程函数`thread_function`,在函数内部模拟了一个异常。使用`try-except`块捕获异常并打印相关错误信息。每个线程都可能产生异常,因此每个线程都需要有异常处理的机制。
### 5.1.2 异常安全性和原子操作
在多线程和多进程环境中,异常安全性是另一个需要重视的概念。异常安全性意味着当异常发生时,程序能够保持一个合理的状态,不会留下数据不一致或资源未正确释放的问题。
为了实现异常安全性,一种常见的做法是使用原子操作。原子操作指的是一组操作要么全部成功,要么全部失败,中间不会被其他操作打断。Python的`threading`模块提供了`Lock`等同步机制,可以帮助我们实现原子操作。
```python
import threading
# 创建一个锁对象
lock = threading.Lock()
def critical_section():
"""临界区代码"""
with lock: # 锁定临界区
# 执行敏感操作
print('Critical section is locked and running')
# 创建线程
thread1 = threading.Thread(target=critical_section)
thread2 = threading.Thread(target=critical_section)
# 启动线程
thread1.start()
thread2.start()
# 等待所有线程完成
thread1.join()
thread2.join()
```
在上面的代码示例中,`lock`用于保护临界区,确保同时只有一个线程可以执行其中的代码。这样可以避免因并发执行导致的数据不一致问题。
## 5.2 异常处理在网络安全中的应用
随着网络攻击技术的不断进步,网络应用面临着严峻的安全挑战。在这样的背景下,正确处理异常对于保障网络应用的安全性至关重要。
### 5.2.1 网络编程中的异常捕获
网络编程时,可能会遇到各种网络相关的异常,比如连接超时、服务不可用等。正确地捕获和处理这些异常能够提升程序的健壮性和用户体验。
```python
import socket
def connect_to_server(host, port):
"""尝试连接服务器"""
try:
# 建立与服务器的连接
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.connect((host, port))
print(f'Connected to server on {host}:{port}')
except socket.timeout:
print(f'Timeout error connecting to {host}:{port}')
except socket.error as e:
print(f'Error connecting to {host}:{port}: {e}')
except Exception as e:
print(f'An unexpected error occurred: {e}')
# 尝试连接到服务器
connect_to_server('***', 80)
```
上述代码尝试建立一个到指定服务器的连接。在尝试连接的过程中,如果发生超时或错误,将通过`try-except`块捕获并处理这些异常。
### 5.2.2 加强网络应用的安全性
为了加强网络应用的安全性,开发者通常会在异常处理中加入安全措施。比如,不向用户显示详细的错误信息,而是返回一个通用的错误提示,以此避免潜在的安全威胁,例如信息泄露。
```python
from flask import Flask, render_template
app = Flask(__name__)
@app.route('/')
def index():
try:
# 假设这是一段潜在危险的代码
risky_code()
except Exception as e:
# 返回一个通用错误提示
return render_template('error.html', error_message='An unexpected error occurred, please try again later.')
def risky_code():
"""这段代码可能抛出异常"""
pass
if __name__ == '__main__':
app.run()
```
在这个示例中,我们使用了Flask框架创建了一个web应用。如果`risky_code`函数抛出异常,将不会向用户显示具体的错误信息,而是渲染一个通用的错误页面。
## 5.3 使用第三方库进行异常处理
虽然Python标准库中的异常处理功能已经足够强大,但第三方库提供了更多的工具和功能,能够进一步简化和增强异常处理的能力。
### 5.3.1 探索第三方异常处理库的优势
第三方异常处理库通常提供了更加简洁和高效的异常处理方式。例如,`sentry-sdk`可以用来捕获和记录运行时错误,并将错误信息发送到Sentry,一个错误监控和分析平台。
```python
import sentry_sdk
from sentry_sdk.integrations.django import DjangoIntegration
sentry_sdk.init(
dsn='***',
integrations=[DjangoIntegration()]
)
try:
# 可能抛出异常的代码
raise ValueError('This is an error!')
except Exception as e:
# 使用sentry_sdk捕获异常
sentry_sdk.capture_exception(e)
```
在上述代码中,通过`sentry_sdk.init`初始化Sentry的配置,并通过`sentry_sdk.capture_exception`来捕获异常,然后将异常信息发送到Sentry服务进行分析。
### 5.3.2 集成和使用第三方异常处理工具
集成第三方异常处理工具通常非常简单。开发者只需按照工具提供的文档进行配置,然后在代码中调用相应的方法即可实现异常处理。
```python
import rollbar
from flask import Flask
app = Flask(__name__)
# 配置Rollbar
rollbar.init(
'your_access_token',
'environment',
root='/path/to/app',
allow_logging_basic_config=False
)
@app.before_first_request
def setup_rollbar():
"""初始化Rollbar监控"""
@rollbar.contrib.flask.report_to_rollbar
def before_request():
pass
@app.errorhandler(Exception)
def handle_exception(e):
# 记录异常到Rollbar
rollbar.contrib.flask.report_exception(e)
return 'An error occurred. Please try again.'
if __name__ == '__main__':
app.run()
```
以上示例中使用了`rollbar`库,它同样是一个用于错误和异常监控的工具。代码中`setup_rollbar`函数在请求开始前进行配置,而`handle_exception`函数捕获异常并将它们发送到Rollbar。
在本章中,我们深入探讨了异常处理在并发编程、网络安全以及第三方库中的应用。这些内容不仅扩展了我们对异常处理的理解,也为我们提供了在实际开发中遇到类似情况时的解决方案。了解这些进阶应用,有助于我们更好地利用异常处理来提升软件的可靠性和安全性。
# 6. 自定义异常与框架开发
在软件开发中,异常处理不仅仅是一个防御性编程的技术手段,它还是构建健壮、可维护和用户友好的应用程序的关键组件。在本章节中,我们将深入探讨自定义异常与框架开发之间的关系,以及如何在API设计中有效地利用异常处理机制。
## 6.1 设计可扩展的异常系统
设计一个可扩展的异常系统意味着你需要为未来的扩展预留足够的空间,同时确保系统的稳定性和可靠性。在构建异常处理框架时,我们必须遵循一些基本的原则。
### 6.1.1 构建异常处理框架的原则
构建异常处理框架时,首先需要定义清晰的异常层次结构。这包括:
- **基类异常**:通常所有的自定义异常都应该继承于一个基类异常,这个基类异常可以包含一些通用的方法和属性,比如错误消息的获取、异常跟踪等。
- **异常分类**:将异常按照其性质进行分类,比如数据异常、业务逻辑异常、系统异常等。
- **异常代码**:为每个异常定义一个唯一的代码,这样可以方便地在日志和错误报告中引用和追踪。
- **文档记录**:为每个异常编写清晰的文档,包括异常发生的情景、预期的异常处理方式等。
### 6.1.2 异常处理框架在大型项目中的应用
异常处理框架在大型项目中至关重要。例如,一个大型分布式系统可能会包含成百上千的服务。在这样的环境中,异常处理框架能够帮助开发者以统一的方式处理不同服务的异常,并通过日志记录、告警系统等手段,及时发现和定位问题。
## 6.2 异常处理在API设计中的角色
API作为应用程序之间通信的桥梁,异常处理是API设计不可或缺的一部分。它确保了API的调用者能够得到足够的信息来了解错误的性质,并据此作出合适的响应。
### 6.2.1 设计RESTful API时的异常处理策略
在设计RESTful API时,异常处理策略应该遵循HTTP状态码的标准,比如:
- **4xx** 系列状态码代表客户端错误,如 `400 Bad Request` 表示无效请求。
- **5xx** 系列状态码代表服务器端错误,如 `500 Internal Server Error` 表示服务内部错误。
对于每个状态码,你应该提供详细、有用的错误信息,有时甚至可以包含错误发生的具体代码位置。使用统一的错误格式使得API用户能够更容易地理解和处理错误。
```json
{
"error": {
"code": 1001,
"message": "Invalid data provided.",
"details": "Field 'username' is required."
}
}
```
### 6.2.2 异常处理与API文档的整合
异常处理策略应该在API文档中进行详细的描述,包括可能返回的异常类型、HTTP状态码以及如何处理这些异常。这不仅有助于API的用户了解错误响应的结构,还可以提高API的透明度和用户的信任感。
```mermaid
graph LR
A[发起API请求] -->|错误响应| B[查阅文档]
B --> C[理解错误]
C --> D[采取措施]
```
## 6.3 自定义异常与错误码的统一
自定义异常和错误码是异常处理框架中不可或缺的两个组件。它们之间应该存在着清晰的映射关系,确保开发者和API用户都能以一致的方式理解和使用错误信息。
### 6.3.1 设计统一的错误码体系
统一的错误码体系可以提供一个简单、可读的方式来标识错误,它应该易于开发者记忆,并且足够详细,以便于定位问题。
```python
class CustomError(Exception):
CODES = {
1000: "Generic error",
1001: "Invalid input",
1002: "Resource not found",
# ... 更多错误码
}
def __init__(self, code, message=None):
self.code = code
self.message = message if message else self.CODES.get(code, "Unknown error")
super().__init__(self.message)
```
### 6.3.2 自定义异常与错误码的映射关系
自定义异常应该直接关联到错误码,使得在捕获异常的时候,可以直接通过异常对象获取错误码和错误消息。这样的设计不仅使得异常处理更加标准化,也便于后期的维护和调试。
```python
try:
# 业务逻辑代码
except CustomError as e:
if e.code == 1001:
# 处理无效输入
elif e.code == 1002:
# 处理资源未找到
else:
# 其他异常处理逻辑
```
在实际的框架开发中,自定义异常与错误码的统一可以显著提高开发效率,使得团队成员能够更快速地定位和解决问题。
在这一章节中,我们了解了如何设计一个可扩展的异常系统,并且探讨了异常处理在API设计中的重要性。同时,我们也学习了如何将自定义异常与错误码相结合,来实现更加高效和统一的错误管理机制。这些原则和实践,对于构建一个健壮的软件系统至关重要。在后续章节中,我们将继续深入探讨异常处理在不同领域中的应用,以及如何进一步优化和扩展这些实践。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**Python 异常处理专栏**
本专栏深入探讨 Python 异常处理的各个方面,旨在提升代码清晰度、避免程序崩溃、解决常见陷阱并优化性能。从异常与可读性的黄金法则到自定义异常类的最佳实践,您将了解如何有效管理异常,确保代码稳定性和可维护性。此外,专栏还涵盖了日志记录、资源管理、单元测试和多线程异常处理等高级主题,让您掌握处理复杂异常场景所需的技能。无论您是 Python 初学者还是经验丰富的开发人员,本专栏将为您提供全面的指南,帮助您提升 Python 异常处理能力。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Python命令行工具】:Optparse的扩展与插件魔法

# 1. Python命令行工具概述
命令行工具是开发者日常工作中不可或缺的一部分,Python凭借其简洁易读的语法以及丰富的库支持,成为开发命令行工具的首选语言之一。本章节将概览Python命令行工具的基本概念、特点以及它在不同场景下的应用。我们将从命令行工具的基本工作原理
【数据分析加速】:linecache在提取关键数据中的高效应用

# 1. linecache模块概述
## 1.1 linecache模块的定义与重要性
linecache模块是Python标准库中的一个工具,专为高效逐行读取文本文件而设计。它通过缓存机制减少磁盘I/O操作,尤其适用于处理大文件或频繁访问同一文件的场景。对于数据密集型应用,如日志分析、数据分析和文本处理,linecache提供了一个简洁而强大的解决方案,有效地
【Python 3的traceback改进】:新特性解读与最佳实践指南
# 1. Python 3 traceback概述
Python作为一门高级编程语言,在编写复杂程序时,难免会遇到错误和异常。在这些情况发生时,traceback信息是帮助开发者快速定位问题的宝贵资源。本章将为您提供对Python 3中traceback机制的基本理解,介绍其如何通过跟踪程序执行的堆栈信息来报告错误。
Python 3 的traceback通过
【代码安全防护】:Mock模拟中的安全性探讨

# 1. Mock模拟技术概述
在软件开发过程中,模拟技术(Mocking)扮演着重要角色,特别是在单元测试和集成测试中。Mock模拟允许开发者创建一个虚拟对象,它能够模仿真实的对象行为,但不依赖于外部系统或组件的复杂性。这种技术有助于隔离测试环境,确保测试的准确性和可靠性。
Mock技术的核心优势在于它能模拟各种边界条件和异常情况,这对于提升软件质量、减少bug和提高代码覆盖率至关重要。此外,
【Python算法效率分析】:用hotshot优化算法性能
# 1. Python算法效率的重要性与分析基础
## 1.1 算法效率的概念
在软件开发中,算法效率是指完成特定任务所需的时间和空间资源。对于Python这样高级语言,虽然内置了大量高效的算法和数据结构,但当面对大规模数据处理时,算法效率就成为了衡量程序性能的关键因素。
## 1.2 分析Python算法效率的必要性
Python简洁易读,但其解释型特性和动态类型系统,往往意味着
Django模板上下文的调试技巧:追踪和分析上下文数据的高级方法
# 1. Django模板上下文基础
在Django框架中,模板上下文扮演着传递数据到模板系统的角色。理解这一基础概念对于开发者来说至关重要,因为它直接影响到视图和模板之间的交互方式。本章节将介绍模板上下文的基本概念,并对如何在Django项目中创建和使用上下文进行概述。
## Django模板上下文基础概念
首先,我们需要明确“上下文”(Contex
字符串与日期时间处理:结合String库的高效方法,优化时间管理技巧
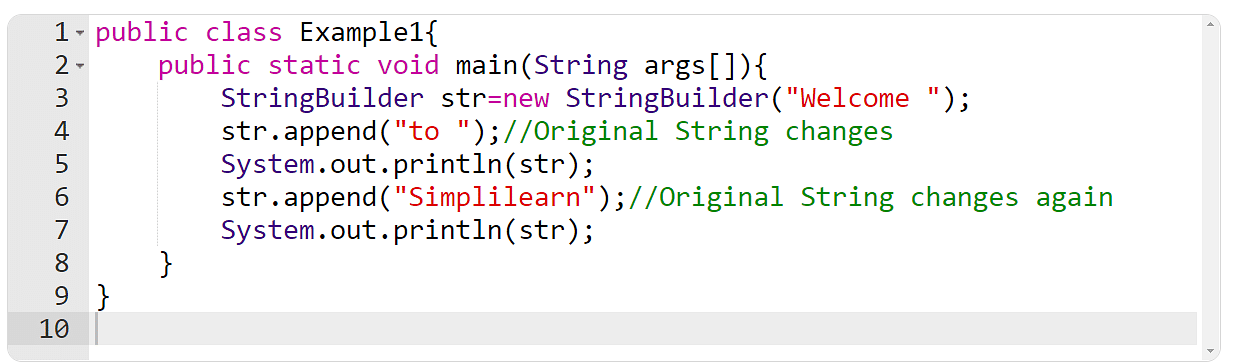
# 1. 字符串与日期时间处理基础
在IT行业中,对字符串与日期时间的处理是不可或缺的一部分。本章将为您提供处理字符串和日期时间的基础知识,帮助您掌握其处理技巧,为后续深入理解String库和时间管理技巧打下坚实的基础。
首先,字符串是程序设计中的基本概念,它是由零个或多个字符组成的有限序列。在大多数编程语言中,字符串通常被视为一个连续的字符数组。常
Setuptools与pip协同:自动化安装与更新的高效方法

# 1. Setuptools与pip简介
## Setuptools与pip简介
在Python的世界里,setuptools和pip是两个不可或缺的工具,它们简化了包的创建和管理过程。setuptools是Python包的分发工具,提供了一系列接口来定义和构建包,而pip是Python包管理器,使得安装和更新这些包变得异常简单。通过利用这两个工具,开发者可以更高效地处理项目依
【Python包迁移指南】:告别easy_install,迁移到最新包管理工具的策略
# 1. Python包管理的历史演进
自Python诞生以来,包管理工具的演进反映了Python生态系统的成长和变化。从早期的脚本到现代的全面管理工具,这一过程中涌现出了多个关键工具和解决方案。
## 1.1 早期的脚本工具
在Python包管理工具变得成熟之前,开发者们依赖于简单的脚本来下载和安装包。`distutils` 是早期的一个
【Django事务测试策略】:确保逻辑正确性,保障交易安全

# 1. Django事务的基本概念和重要性
在Web开发的世界里,数据的完整性和一致性是至关重要的。Django作为一个高级的Python Web框架,提供了强大的事务支持,这使得开发者能够确保数据库操作在遇到错误时能够正确回滚,并保持数据的一致性。
##
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )