【数据分析加速】:linecache在提取关键数据中的高效应用
发布时间: 2024-10-07 16:28:53 阅读量: 36 订阅数: 40 

python linecache 处理固定格式文本数据的方法

# 1. linecache模块概述
## 1.1 linecache模块的定义与重要性
linecache模块是Python标准库中的一个工具,专为高效逐行读取文本文件而设计。它通过缓存机制减少磁盘I/O操作,尤其适用于处理大文件或频繁访问同一文件的场景。对于数据密集型应用,如日志分析、数据分析和文本处理,linecache提供了一个简洁而强大的解决方案,有效地提升了数据读取效率和程序性能。
## 1.2 linecache模块与其他工具的对比
相较于Python内建的文件操作方法或其它第三方库,linecache的优势在于其特有的缓存行读取机制。它使得开发者在读取文件的每一行时,不需要重新打开或逐字节读取整个文件,这大大减少了资源的消耗和时间的开销。通过对比,我们能更好地理解linecache在处理大量数据时的效率提升和优势所在。
## 1.3 linecache模块的应用场景
linecache模块广泛应用于需要大量数据读取和分析的场景。例如,在日志文件分析中,linecache可以快速访问日志中的特定行或段落,极大地提高了日志分析的效率。在数据处理方面,linecache可用于快速提取特定数据记录,加速数据清洗和预处理。而在并发环境下,linecache也支持高效的数据读取和处理,这在大规模数据集的操作中尤为重要。
# 2. linecache模块的基本使用
## 2.1 linecache模块的安装与配置
### 2.1.1 安装linecache模块的方法
linecache模块是Python标准库的一部分,因此不需要单独安装。在大多数Python安装中,linecache模块默认就已经可用。对于需要单独安装的情况,可以通过Python的包管理工具pip来安装。通常情况下,由于linecache是内置模块,用户不需要手动进行安装。
对于需要安装的特殊场景,例如某个Python发行版没有包含该模块,可以使用以下命令安装:
```shell
pip install linecache2
```
这里需要注意的是,可能会存在一些细微的差异,比如老版本的Python中使用的是`linecache`,而在更新的版本中(例如Python 3.8以上),官方推荐使用`linecache2`。这是因为`linecache`在一些旧版本中可能不再维护,而`linecache2`提供了更多的功能和改进。
### 2.1.2 配置linecache模块的环境
在大多数使用场景中,linecache模块不需要额外的配置。一旦安装完成,该模块就会被Python自动加载到环境中。然而,如果用户需要自定义linecache模块的行为,比如调整缓存策略,可以通过设置环境变量或编程方式来实现。
例如,可以设置环境变量`PYTHON_LINECACHE_MAXSIZE`来限制linecache使用的最大缓存大小。以下是如何在命令行中设置环境变量的示例:
```shell
export PYTHON_LINECACHE_MAXSIZE=1000000
```
这将限制linecache的最大缓存大小为1000000字节。在Python代码中,可以使用`sys.setrecursionlimit()`来调整递归深度限制。由于linecache可能在递归处理大文件时使用,这个参数也可以间接影响linecache模块的性能。
```python
import sys
sys.setrecursionlimit(2000)
```
在设置以上参数时,需要注意过大的设置可能会导致程序内存使用不当,从而影响到系统的稳定性和性能。
## 2.2 linecache模块的基本功能
### 2.2.1 逐行读取文件
linecache模块最重要的一个功能就是能够高效地逐行读取文件。该模块提供了一个名为`getline`的函数,允许用户指定文件路径和行号来读取文件中指定的行。
```python
import linecache
# 读取文件第一行
line1 = linecache.getline('example.txt', 1)
print(line1)
```
`getline`函数的使用非常简单,但背后做了很多事情。当调用`getline`时,它会在内部缓存中查找是否已经有了指定文件的缓存。如果有,则直接返回对应行的内容。如果没有,它会打开文件,读取指定行的内容到缓存中,然后返回。这种方法大大提高了读取效率,特别是对于那些经常需要访问单行数据的大文件。
### 2.2.2 快速定位和提取数据行
除了逐行读取文件,linecache模块还能够快速定位和提取数据行,而无需加载整个文件到内存中。这对于处理大型文本文件非常有用,尤其是当只需要访问文件中特定几行的数据时。
```python
# 读取文件的第3、5、7行
lines = [linecache.getline('example.txt', i) for i in (3, 5, 7)]
for line in lines:
print(line, end='')
```
上述代码片段中,我们使用列表推导式来获取多个行的文本,这些行将被打印出来,而无需读取整个文件。linecache模块在内部缓存了这些行,使得连续读取操作可以重复利用缓存的数据,从而减少了磁盘I/O操作。
## 2.3 linecache模块的高级特性
### 2.3.1 缓存管理机制
linecache模块实现了缓存管理机制,它内部维护了一个缓存字典,用来存储已经被读取过的文件行。当再次读取同一文件的相同行时,linecache会从缓存中直接获取数据,而不会再次读取文件。
这种缓存机制提高了数据访问效率,但也带来了一些潜在的问题,比如缓存的同步问题。对于只读文件,这不是问题,但如果是可写的文件,文件内容的修改不会即时反映在缓存中,这可能导致数据的不一致。
为了避免这种情况,linecache提供了清空缓存的函数`clearcache()`,它会移除所有缓存的数据:
```python
linecache.clearcache()
```
### 2.3.2 内存使用优化
linecache模块在内存使用方面进行了优化。当文件行被读取时,linecache会将其存储在内存中。考虑到内存是一种宝贵的资源,linecache使用了一些策略来管理内存使用,比如使用最少使用的缓存淘汰策略(LRU)来确定哪些行应该被缓存。
这种策略允许linecache在不影响性能的情况下尽量减少内存的使用。然而,用户需要意识到大文件的读取仍然可能消耗大量的内存,特别是在缓存了大量行的情况下。因此,对于大文件,建议仅在必要时读取所需的行,而不要使用通配符一次性读取所有行。
```python
# 只读取所需行的策略示例
def read_needed_lines(file_path, line_numbers):
return [linecache.getline(file_path, line_number) for line_number in line_numbers]
```
通过这种方式,可以有效控制内存的使用,尤其是在处理大型文件时。
# 3. linecache模块在文本分析中的应用
linecache模块是Python标准库中的一个组成部分,它允许程序员轻松地访问和处理文件中的特定行。不同于一次性读取整个文件到内存中,linecache的设计允许按需读取文件行,这对于分析大型文本文件特别有用。linecache模块尤其适合处理那些需要频繁访问不同行的场景,例如,日志文件的分析或大型源代码文件的编辑。
## 3.1 文本数据的预处理
在开始深入文本分析之前,数据预处理是一个必须经过的步骤。预处理阶段的主要目标是清理数据并将其转换为适合分析的格式。
### 3.1.1 清洗和标准化文本数据
在清洗文本数据时,通常会处理如换行符、空格和特殊字符等。标准化文本数据涉及转换文本到统一的格式,例如,将所有字符转换为小写或删除不必要的空格。
```python
import linecache
def clean_text(text):
# 移除换行符
text = text.replace('\n', ' ').replace('\r', '')
# 去除多余空格
text = ' '.join(text.split())
return text.lower()
# 假设我们有一个文本行的列表,我们想要清洗它
lines = [
" Example of text with\n multiple line breaks\tand spaces. ",
"Another line of text with\t\textra spaces."
]
# 清洗每行文本
cleaned_lines = [clean_text(line) for line in lines]
print(cleaned_lines)
```
这段代码展示了如何通过自定义函数`clean_text`去除文本中的空白字符,并将所有字符转换为小写。这一步对于确保文本分析的一致性非常重要。
### 3.1.2 文本数据的格式化输出
格式化输出可以确保数据的可读性和进一步分析的便捷性。在Python中,可以通过字符串格式化方法来实现。
```python
for line in cleaned_lines:
formatted_line = f"{line}"
print(formatted_line)
```
这里使用了f-string(格式化字符串字面量)来格式化每一行,确保输出具有统一的样式。
## 3.2 提取关键数据实例分析
一旦文本数据被清洗和格式化,下一步通常是提取关键信息,以便于分析或进一步处理。
### 3.2.1 简单文本匹配示例
文本匹配是提取特定信息的最直接方式之一。使用linecache模块可以轻松地访问文件中的每一行并进行匹配。
```python
import re
def find_pattern_in_line(pattern, line):
return re.search(pattern, line)
# 假设我们要在文本中查找特定的模式
pattern = r"example"
# 我们已经有了清洗过的文本行
for line in cleaned_lines:
match = find_pattern_in_line(pattern, line)
if match:
print(f"Pattern found in: {line}")
```
这段代码演示了如何使用正则表达式`re.search`来查找包含"example"的行。在使用linecache时,这可以通过`linecache.getline`函数来实现,这在需要在文件中查找特定行时非常有用。
### 3.2.2 正则表达式在linecache中的应用
当面对更复杂的文本匹配需求时,正则表达式提供了一种强大的解决方案。linecache模块使读取文件的任意行变得简单,再结合正则表达式,可以实现复杂文本的高效分析。
```python
# 示例:查找所有包含数字的行
pattern = r"\d+"
for i in range(1, len(lines) + 1): # linecache编号从1开始
line = linecache.getline('example.txt', i)
if line and find_pattern_in_line(pattern, line):
print(f"Number found in line {i}: {line
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习之 linecache 专栏!本专栏将深入探索 linecache 库,全面解析其文件读取、性能优化、内存管理、并发读写、自定义扩展、数据清洗、异常处理、代码质量保证、Web 开发加速、性能瓶颈分析、并行处理、文件 IO 优化、国际化文件读取、数据分析加速等方方面面。通过一系列深入浅出的文章,你将掌握 linecache 的高效应用技巧,提升代码效率,解决文件处理中的各种难题。本专栏适合所有 Python 开发者,无论你是初学者还是经验丰富的程序员,都能从中受益匪浅,打造更强大、更可靠的 Python 程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MATLAB C4.5算法性能提升秘籍】:代码优化与内存管理技巧

# 摘要
本论文首先概述了MATLAB中C4.5算法的基础知识及其在数据挖掘领域的应用。随后,探讨了MATLAB代码优化的基础,包括代码效率原理、算法性能评估以及优化技巧。深入分析了MATLAB内存管理的原理和优化方法,重点介绍了内存泄漏的检测与预防
【稳定性与混沌的平衡】:李雅普诺夫指数在杜芬系统动力学中的应用

# 摘要
本文旨在介绍杜芬系统的概念与动力学基础,深入分析李雅普诺夫指数的理论和计算方法,并探讨其在杜芬系统动力学行为和稳定性分析中的应用。首先,本文回顾了杜芬系统的动力学基础,并对李雅普诺夫指数进行了详尽的理论探讨,包括其定义、性质以及在动力系统中的角色。
QZXing在零售业中的应用:专家分享商品快速识别与管理的秘诀

# 摘要
QZXing作为一种先进的条码识别技术,在零售业中扮演着至关重要的角色。本文全面探讨了QZXing在零售业中的基本概念、作用以及实际应用。通过对QZXing原理的阐述,展示了其在商品快速识别中的核心技术优势,例如二维码识别技术及其在不同商品上的应用案例。同时,分析了QZXing在提高商品识别速度和零售效率方面的实际效果
【AI环境优化高级教程】:Win10 x64系统TensorFlow配置不再难

# 摘要
本文详细探讨了在Win10 x64系统上安装和配置TensorFlow环境的全过程,包括基础安装、深度环境配置、高级特性应用、性能调优以及对未来AI技术趋势的展望。首先,文章介绍了如何选择合适的Python版本以及管理虚拟环境,接着深入讲解了GPU加速配置和内存优化。在高级特性应用
【宇电温控仪516P故障解决速查手册】:快速定位与修复常见问题

# 摘要
本文全面介绍了宇电温控仪516P的功能特点、故障诊断的理论基础与实践技巧,以及常见故障的快速定位方法。文章首先概述了516P的硬件与软件功能,然后着重阐述了故障诊断的基础理论,包括故障的分类、系统分析原理及检测技术,并分享了故障定位的步骤和诊断工具的使用方法。针对516P的常见问题,如温度显示异常、控制输出不准确和通讯故障等,本文提供了详尽的排查流程和案例分析,并探讨了电气组件和软件故障的修复方法。此外
【文化变革的动力】:如何通过EFQM模型在IT领域实现文化转型

# 摘要
EFQM模型是一种被广泛认可的卓越管理框架,其在IT领域的适用性与实践成为当前管理创新的重要议题。本文首先概述了EFQM模型的核心理论框架,包括五大理念、九个基本原则和持续改进的方法论,并探讨了该模型在IT领域的具体实践案例。随后,文章分析了EFQM模型如何在IT企业文化中推动创新、强化团队合作以及培养领导力和员工发展。最后,本文研究了在多样化
RS485系统集成实战:多节点环境中电阻值选择的智慧
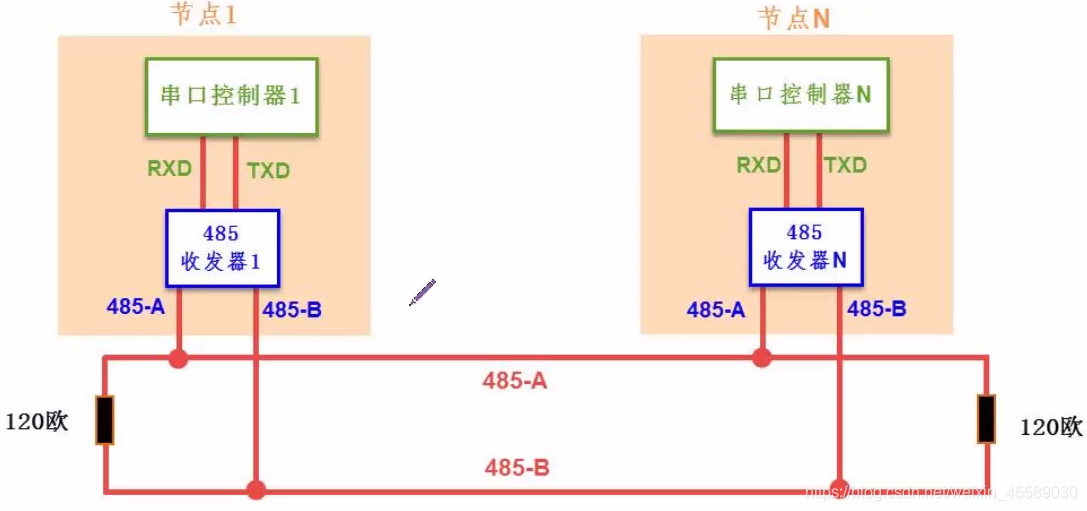
# 摘要
本文系统性地探讨了RS485系统集成的基础知识,深入解析了RS485通信协议,并分析了多节点RS485系统设计中的关键原则。文章
【高级电磁模拟】:矩量法在复杂结构分析中的决定性作用
# 摘要
本文全面介绍了电磁模拟与矩量法的基础理论及其应用。首先,概述了矩量法的基本概念及其理论基础,包括电磁场方程和数学原理,随后深入探讨了积分方程及其离散化过程。文章着重分析了矩量法在处理多层介质、散射问题及电磁兼容性(EMC)方面的应用,并通过实例展示了其在复杂结构分析中的优势。此外,本文详细阐述了矩量法数值模拟实践,包括模拟软件的选用和模拟流程,并对实际案例
SRIO Gen2在云服务中的角色:云端数据高效传输技术深度支持

# 摘要
本文旨在深入探讨SRIO Gen2技术在现代云服务基础架构中的应用与实践。首先,文章概述了SRIO Gen2的技术原理,及其相较于传统IO技术的显著优势。然后,文章详细分析了SRIO Gen2在云服务中尤其是在数据中心的应用场景,并提供了实际案例研
先农熵在食品质量控制的重要性:确保食品安全的科学方法

# 摘要
本文深入探讨了食品质量控制的基本原则与重要性,并引入先农熵理论,阐述其科学定义、数学基础以及与热力学第二定律的关系。通过对先农熵在食品稳定性和保质期预测方面作用的分析,详细介绍了先农熵测量技术及其在原料质量评估、加工过程控制和成品质量监控中的应用。进一步,本文探讨了先农熵与其他质量控制方法的结合,以及其在创新食品保存技术和食品安全法规标准中的应用。最后,通过案例分析,总结了先农熵在食品质量控制中
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )