【Web开发加速】:linecache在后端文件处理中的高效应用
发布时间: 2024-10-07 16:11:22 阅读量: 26 订阅数: 38 

后端开发入门与实战教程:从0到1打造高效Web应用.zip

# 1. linecache的原理与基础应用
## 1.1 linecache的定义和作用
linecache是一种高效的Python模块,主要用于后端开发中,能够实现快速、高效的文件读写操作。它通过缓存文件的每一行,使得开发者在处理大文件或频繁读取同一文件时,可以大幅度提高效率。
## 1.2 linecache的工作机制
linecache的工作原理是将文件的每一行读取并存储到内存中,当需要读取文件的某一行时,直接从内存中获取,避免了重复的文件IO操作,从而提高了文件处理的速度。
## 1.3 linecache的基本使用方法
linecache的基本使用非常简单,只需要调用getlines()函数,传入文件名和行号,就可以获取到对应的文件行内容。例如,linecache.getlines('example.txt', 2)将会返回example.txt文件的第二行内容。
# 2. linecache在后端文件处理中的实践
## 2.1 linecache处理文本文件
### 2.1.1 逐行读取与处理
linecache库简化了文本文件的逐行读取和处理过程。相对于传统的文件读取,使用linecache可以直接访问特定行的内容,而无需从头到尾逐字节读取。这样不仅提高了效率,还减少了内存的使用。
通过简单的API调用,可以快速访问文件的任何一行,这对于需要逐行解析大量数据的应用场景尤其有用。下面是一个使用linecache逐行读取文件的代码示例:
```python
import linecache
# 假定我们有一个名为"example.txt"的大文件
file_path = 'example.txt'
def process_line(line_number):
content = linecache.getline(file_path, line_number)
# 在这里可以添加对content的处理逻辑
print(f"Line {line_number}: {content}")
# 假定我们想打印第100行的内容
process_line(100)
```
在上面的代码中,`getline` 函数从指定的文件路径读取特定行的内容。它返回的是一个字符串,包含了所请求行的数据。
### 2.1.2 大文件处理与内存优化
处理大文件时,内存的使用成为了一个关键问题。传统的文件读取方法会将整个文件内容加载到内存中,这在处理大型文本文件时可能会导致内存耗尽。然而,使用linecache可以避免这一问题,因为linecache在内部处理了内存的分配和回收。
linecache库会将文件分割成块,并且只将当前需要读取的行所在块加载到内存中。这样,即使是非常大的文件,也能以很小的内存开销来处理。
下面是一个示例,展示如何使用linecache对大文件进行处理,同时优化内存使用:
```python
import linecache
import os
def process_large_file(file_path, chunk_size=1024):
total_lines = sum(1 for line in open(file_path))
file_size = os.path.getsize(file_path)
num_chunks = (file_size / chunk_size) + 1
for chunk in range(1, int(num_chunks) + 1):
# 从当前块的第一个字节开始,读取一行
start_byte = (chunk - 1) * chunk_size
linecache.updatecache(file_path, start_byte, chunk_size)
for line_number in range(start_byte + 1, start_byte + chunk_size):
if line_number > total_lines:
break
content = linecache.getline(file_path, line_number)
# 在这里可以添加对content的处理逻辑
print(f"Chunk {chunk} Line {line_number}: {content}")
process_large_file('large_example.txt')
```
在这个例子中,`updatecache`函数会预加载一个数据块到内存中,然后通过`getline`函数读取块中的具体行。这种方法有效地优化了内存的使用,使得即使是大文件也可以被高效处理。
## 2.2 linecache与数据库交互
### 2.2.1 提高数据库文件导入速度
将大量文本数据导入数据库是数据处理中的常见任务。使用linecache可以加快这个过程。linecache可以逐行读取大型文本文件,这使得文件数据可以被直接导入数据库中,无需在内存中创建数据副本。
以下是一个示例,展示如何使用linecache将文件中的数据导入数据库:
```python
import linecache
import psycopg2
def import_data_to_db(file_path, db_connection):
with open(file_path, 'r') as ***
***
* 这里需要根据实际的行数据格式和数据库结构进行解析和适配
# 假设每行是一个逗号分隔的值列表
values = line.strip().split(',')
# 执行数据库插入操作
cursor = db_connection.cursor()
cursor.execute("INSERT INTO table_name (column1, column2) VALUES (%s, %s)", values)
db_***mit()
cursor.close()
print(f"Imported data from {file_path} into the database.")
# 假定数据库连接已经建立
db_connection = psycopg2.connect("dbname=test user=postgres")
import_data_to_db('data_file.csv', db_connection)
```
在此代码中,我们逐行读取文件,将每行数据进行必要的处理后直接导入到数据库中。使用linecache可以避免一次性读入整个文件,从而减少内存的消耗。
### 2.2.2 优化数据库查询中的文件处理
在某些情况下,数据库查询的结果可能包含大量的文本数据。在这种情况下,我们可以使用linecache来优化这些数据的处理。通过只提取需要的行,我们可以减少对内存的需求,并提高处理速度。
下面是一个例子,展示如何在数据库查询后使用linecache来优化处理:
```python
import linecache
import psycopg2
def process_large_query_result(query_result):
for row in query_result:
file_id = row['file_id']
line_number = row['line_number']
file_path = f"{file_id}.txt"
content = linecache.getline(file_path, line_number)
# 在这里可以添加对content的处理逻辑
print(f"File {file_id}, Line {line_number}: {content}")
# 假定查询结果是一个包含文件ID和行号的列表
query_result = [
{'file_id': 'file1', 'line_number': 42},
{'file_id': 'file2', 'line_number': 1001}
]
# 假定数据库连接已经建立
db_connection = psycopg2.connect("dbname=test user=postgres")
process_large_query_result(query_result)
```
在这个例子中,通过数据库查询得到的结果,我们使用linecache来获取特定文件的特定行,从而避免了将整个文件加载到内存中。
## 2.3 linecache在日志文件管理中的应用
### 2.3.1 实时监控日志文件
日志文件是监控应用运行状态和调试问题的宝贵资源。使用linecache可以实时监控这些文件,及时获取日志条目。由于linecache只读取文件的特定部分,它可以高效地监控大型日志文件的变化,而不会对系统性能造成太大影响。
下面是一个使用linecache监控日志文件的示例:
```python
import linecache
import time
def monitor_log_file(log_file_path):
while True:
current_size = os.path.getsize
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习之 linecache 专栏!本专栏将深入探索 linecache 库,全面解析其文件读取、性能优化、内存管理、并发读写、自定义扩展、数据清洗、异常处理、代码质量保证、Web 开发加速、性能瓶颈分析、并行处理、文件 IO 优化、国际化文件读取、数据分析加速等方方面面。通过一系列深入浅出的文章,你将掌握 linecache 的高效应用技巧,提升代码效率,解决文件处理中的各种难题。本专栏适合所有 Python 开发者,无论你是初学者还是经验丰富的程序员,都能从中受益匪浅,打造更强大、更可靠的 Python 程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【51单片机矩阵键盘扫描终极指南】:全面解析编程技巧及优化策略

# 摘要
本论文主要探讨了基于51单片机的矩阵键盘扫描技术,包括其工作原理、编程技巧、性能优化及高级应用案例。首先介绍了矩阵键盘的硬件接口、信号特性以及单片机的选择与配置。接着深入分析了不同的扫
【Pycharm源镜像优化】:提升下载速度的3大技巧

# 摘要
Pycharm作为一款流行的Python集成开发环境,其源镜像配置对开发效率和软件性能至关重要。本文旨在介绍Pycharm源镜像的重要性,探讨选择和评估源镜像的理论基础,并提供实践技巧以优化Pycharm的源镜像设置。文章详细阐述了Pycharm的更新机制、源镜像的工作原理、性能评估方法,并提出了配置官方源、利用第三方源镜像、缓存与持久化设置等优化技巧。进一步,文章探索了多源镜像组
【VTK动画与交互式开发】:提升用户体验的实用技巧
# 摘要
本文旨在介绍VTK(Visualization Toolkit)动画与交互式开发的核心概念、实践技巧以及在不同领域的应用。通过详细介绍VTK动画制作的基础理论,包括渲染管线、动画基础和交互机制等,本文阐述了如何实现动画效果、增强用户交互,并对性能进行优化和调试。此外,文章深入探讨了VTK交互式应用的高级开发,涵盖了高级交互技术和实用的动画
【转换器应用秘典】:RS232_RS485_RS422转换器的应用指南
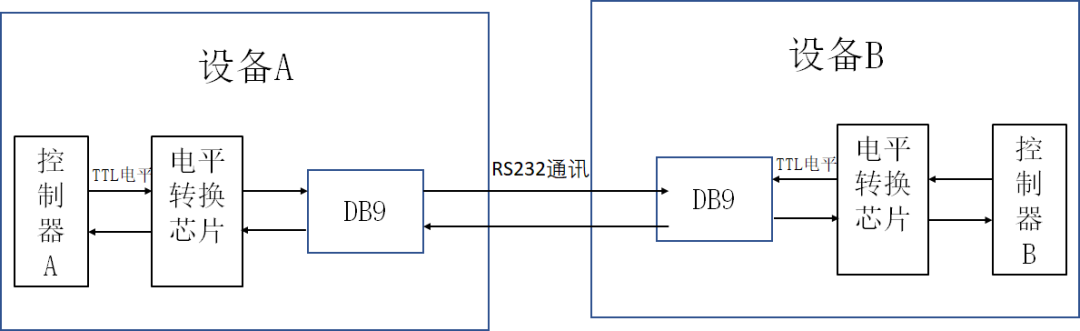
# 摘要
本论文全面概述了RS232、RS485、RS422转换器的原理、特性及应用场景,并深入探讨了其在不同领域中的应用和配置方法。文中不仅详细介绍了转换器的理论基础,包括串行通信协议的基本概念、标准详解以及转换器的物理和电气特性,还提供了转换器安装、配置、故障排除及维护的实践指南。通过分析多个实际应用案例,论文展示了转
【Strip控件多语言实现】:Visual C#中的国际化与本地化(语言处理高手)

# 摘要
本文全面探讨了Visual C#环境下应用程序的国际化与本地化实施策略。首先介绍了国际化基础和本地化流程,包括本地化与国际化的关系以及基本步骤。接着,详细阐述了资源文件的创建与管理,以及字符串本地化的技巧。第三章专注于Strip控件的多语言实现,涵盖实现策略、高级实践和案例研究。文章第四章则讨论了多语言应用程序的最佳实践和性能优化措施。最后,第五章通过具体案例分析,总结了国际化与本地化的核心概念,并展望了未来的技术趋势。
# 关
C++高级话题:处理ASCII文件时的异常处理完全指南
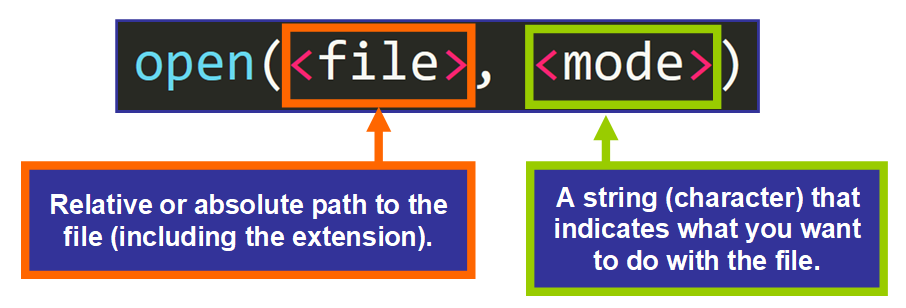
# 摘要
本文旨在探讨异常处理在C++编程中的重要性以及处理ASCII文件时如何有效地应用异常机制。首先,文章介绍了ASCII文件的基础知识和读写原理,为理解后续异常处理做好铺垫。接着,文章深入分析了C++中的异常处理机制,包括基础语法、标准异常类使用、自定义异常以及异常安全性概念与实现。在此基础上,文章详细探讨了C++在处理ASCII文件时的异常情况,包括文件操作中常见异常分析和异常处理策
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )