GRU在自然语言处理中的应用:从理论到实践,解锁语言理解新境界
发布时间: 2024-08-21 17:34:23 阅读量: 46 订阅数: 21 

深度学习在自然语言处理中的应用.docx
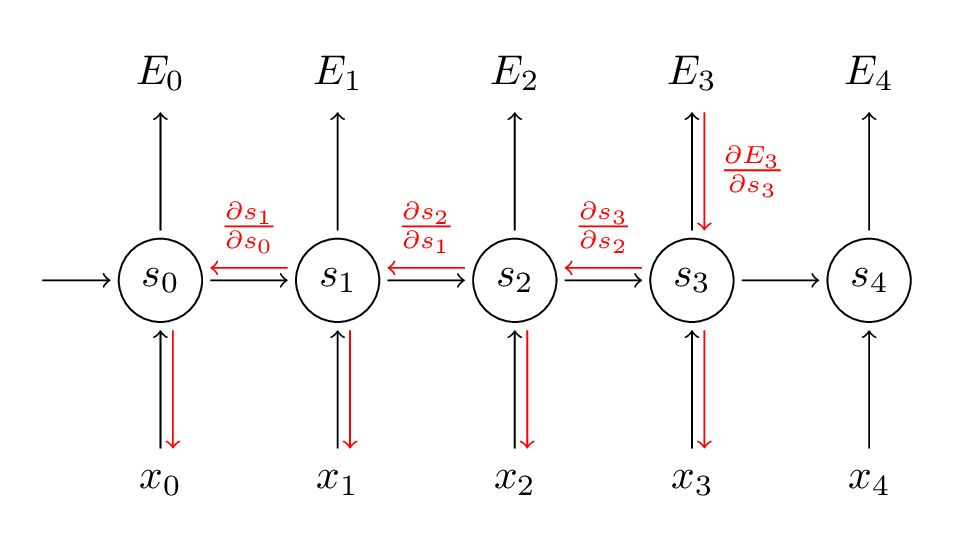
# 1. GRU神经网络基础**
GRU(门控循环单元)是一种循环神经网络(RNN),它通过引入更新门和重置门来解决传统RNN中长期依赖问题。GRU的结构如下:
```python
def GRUCell(x, h_prev):
# 更新门
z = tf.sigmoid(tf.matmul(x, Wz) + tf.matmul(h_prev, Uz))
# 重置门
r = tf.sigmoid(tf.matmul(x, Wr) + tf.matmul(h_prev, Ur))
# 候选隐藏状态
h_tilde = tf.tanh(tf.matmul(x, Wh) + tf.matmul(r * h_prev, Uh))
# 隐藏状态
h = (1 - z) * h_prev + z * h_tilde
return h
```
GRU更新门控制了前一时间步信息在当前时间步中的保留程度,重置门控制了前一时间步信息被遗忘的程度。通过这两个门,GRU可以有效地学习长期依赖关系。
# 2. GRU在NLP中的应用
GRU在自然语言处理(NLP)领域展现出强大的潜力,能够有效处理各种语言理解任务。本章将深入探讨GRU在文本分类、机器翻译和问答系统中的应用。
### 2.1 文本分类
文本分类是NLP中一项基本任务,涉及将文本片段分配到预定义类别。GRU模型通过学习文本序列中的模式和特征,可以高效地执行文本分类任务。
#### 2.1.1 理论基础
GRU模型采用门控循环单元(GRU)结构,该结构包含三个门:更新门、重置门和输出门。这些门负责控制信息在GRU单元中的流动,从而使模型能够学习长短期依赖关系。
在文本分类任务中,GRU模型通常将文本序列编码为向量序列。然后,这些向量序列被输入到GRU层,GRU层提取文本中的相关特征并生成隐藏状态。最后,一个全连接层将隐藏状态映射到输出类别。
#### 2.1.2 实践应用
```python
import tensorflow as tf
# 创建一个GRU模型
model = tf.keras.Sequential([
tf.keras.layers.GRU(128, return_sequences=True),
tf.keras.layers.GRU(64),
tf.keras.layers.Dense(3, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10)
# 评估模型
model.evaluate(X_test, y_test)
```
**代码逻辑分析:**
* `tf.keras.layers.GRU(128, return_sequences=True)`:创建一个GRU层,具有128个隐藏单元,并返回序列输出。
* `tf.keras.layers.GRU(64)`:创建一个GRU层,具有64个隐藏单元。
* `tf.keras.layers.Dense(3, activation='softmax')`:创建一个全连接层,具有3个输出单元和softmax激活函数。
* `model.compile()`:编译模型,指定优化器、损失函数和评估指标。
* `model.fit()`:训练模型,使用训练数据和标签。
* `model.evaluate()`:评估模型,使用测试数据和标签。
### 2.2 机器翻译
机器翻译是将一种语言的文本翻译成另一种语言。GRU模型通过学习两种语言之间的映射关系,可以实现高效的机器翻译。
#### 2.2.1 理论基础
在机器翻译任务中,GRU模型通常采用编码器-解码器架构。编码器是一个GRU层,负责将源语言文本编码为向量序列。解码器也是一个GRU层,负责根据编码器的输出生成目标语言文本。
GRU模型在机器翻译中表现出色,因为它能够捕捉源语言和目标语言之间的长期依赖关系。此外,GRU模型还可以处理不同长度的文本序列,这对于机器翻译任务至关重要。
#### 2.2.2 实践应用
```python
import tensorflow as tf
# 创建一个编码器-解码器模型
encoder = tf.keras.Sequential([
tf.keras.layers.GRU(128, return_sequences=True),
tf.keras.layers.GRU(64)
])
decoder = tf.keras.Sequential([
tf.keras.layers.GRU(64, return_sequences=True),
tf.keras.layers.GRU(32),
tf.keras.layers.Dense(target_vocab_size)
])
# 编译模型
model = tf.keras.Model(encoder.input, decoder.output)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10)
# 评估模型
model.evaluate(X_test, y_test)
```
**代码逻辑分析:**
* `encoder`:一个GRU编码器,具有128和64个隐藏单元。
* `decoder`:一个GRU解码器,具有64和32个隐藏单元,以及一个输出层,其大小等于目标语言词汇表的大小。
* `model = tf.keras.Model(encoder.input, decoder.output)`:创建一个编码器-解码器模型,将编码器的输出连接到解码器的输入。
* `model.compile()`:编译模型,指定优化器、损失函数和评估指标。
* `model.fit()`:训练模型,使用训练数据和标签。
* `model.evaluate()`:评估模型,使用测试数据和标签。
### 2.3 问答系统
问答系统允许用户提出问题并获得文本形式的答案。GRU模型通过理解问题和检索相关信息,可以构建有效的问答系统。
#### 2.3.1 理论基础
在问答系统中,GRU模型通常采用查询-检索-生成(QRG)架构。查询模块是一个GRU层,负责将问题编码为向量。检索模块是一个检索机制,负责从知识库中检索与问题相关的文档。生成模块是一个GRU层,负责根据查询向量和检索到的文档生成答案。
GRU模型在问答系统中表现出色,因为它能够理解问题中的复杂关系并生成相关的答案。此外,GRU模型还可以处理开放域问题,这对于问答系统至关重要。
#### 2.3.2 实践应用
```python
import tensorflow as tf
# 创建一个QRG模型
query_encoder = tf.keras.Sequential([
tf.keras.layers.GRU(128)
])
retriever = tf.keras.layers.Dense(100)
answer_generator = tf.keras.Sequential([
tf.keras.layers.GRU(128),
tf.keras.layers.Dense(target_vocab_size)
])
# 编译模型
model = tf.keras.Model(query_encoder.input, answer_generator.output)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10)
# 评估模型
model.evaluate(X_test, y_test)
```
**代码逻辑分析:**
* `query_encoder`:一个GRU查询编码器,具有128个隐藏单元。
* `retriever`:一个检索层,负责从知识库中检索与问题相关的文档。
* `answer_generator`:一个GRU答案生成器,具有128个隐藏单元,以及一个输出层,其大小等于目标语言词汇表的大小。
* `model = tf.keras.Model(query_encoder.input, answer_generator.output)`:创建一个QRG模型,将查询编码器的输出连接到答案生成器的输入。
* `model.compile()`:编译模型,指定优化器、损失函数和评估指标。
* `model.fit()`:训练模型,使用训练数据和标签。
* `model.evaluate()`:评估模型,使用测试数据和标签。
# 3. GRU模型的训练和优化
### 3.1 数据预处理
#### 3.1.1 文本预处理
文本预处理是GRU模型训练前必不可少的一步,其目的是将原始文本数据转换为模型可理解的格式。常见的文本预处理步骤包括:
- **分词:**将文本分解为单个单词或词组。
- **去停用词:**移除诸如"the"、"and"等无意义的单词。
- **词干化:**将单词还原为其基本形式,如"running"还原为"run"。
- **词嵌入:**将单词转换为数字向量,以捕获其语义信息。
#### 3.1.2 数据增强
数据增强技术可以扩大训练数据集,提高模型的鲁棒性和泛化能力。常用的数据增强方法包括:
- **同义词替换:**用同义词替换文本中的某些单词。
- **随机删除:**随机删除文本中的某些单词。
- **随机插入:**随机在文本中插入其他单词。
- **反向翻译:**将文本翻译成另一种语言,然后再翻译回来。
### 3.2 模型训练
#### 3.2.1 训练参数设置
GRU模型训练需要设置以下参数:
- **学习率:**控制模型更新权重的步长。
- **批大小:**每次训练迭代中使用的样本数量。
- **时代数:**训练模型的迭代次数。
- **优化器:**用于更新模型权重的算法,如Adam或RMSprop。
- **损失函数:**衡量模型预测与真实标签之间的差异,如交叉熵损失或均方误差。
#### 3.2.2 训练过程监控
在训练过程中,需要监控以下指标:
- **损失函数:**训练和验证集上的损失值。
- **准确率:**模型对验证集的预测准确率。
- **F1值:**模型对验证集的F1分数。
通过监控这些指标,可以评估模型的训练进度并及时调整训练参数。
### 3.3 模型优化
#### 3.3.1 正则化
正则化技术可以防止模型过拟合,提高其泛化能力。常用的正则化方法包括:
- **L1正则化:**添加权重绝对值的惩罚项。
- **L2正则化:**添加权重平方和的惩罚项。
- **Dropout:**在训练过程中随机丢弃一些神经元。
#### 3.3.2 超参数调整
超参数调整是优化GRU模型性能的关键。常用的超参数调整方法包括:
- **网格搜索:**在预定义的超参数范围内进行网格搜索,找到最佳组合。
- **贝叶斯优化:**使用贝叶斯优化算法在超参数空间中探索,找到最优值。
- **进化算法:**使用进化算法,如遗传算法,优化超参数。
# 4.1 情感分析
### 4.1.1 理论基础
情感分析,又称意见挖掘,旨在识别和提取文本中表达的情感倾向。GRU在情感分析中发挥着至关重要的作用,因为它能够有效捕获文本序列中的长期依赖关系。
GRU的情感分析模型通常由以下组件组成:
- **嵌入层:**将单词转换为数字向量。
- **GRU层:**捕获文本序列中的长期依赖关系。
- **全连接层:**将GRU层的输出映射到情感类别(例如,正面、负面、中性)。
### 4.1.2 实践应用
**代码块 1:GRU情感分析模型**
```python
import tensorflow as tf
# 嵌入层
embedding_layer = tf.keras.layers.Embedding(vocab_size, embedding_dim)
# GRU层
gru_layer = tf.keras.layers.GRU(units=hidden_size, return_sequences=True)
# 全连接层
output_layer = tf.keras.layers.Dense(num_classes, activation='softmax')
# 模型构建
model = tf.keras.Sequential([
embedding_layer,
gru_layer,
output_layer
])
```
**逻辑分析:**
- `embedding_layer`将单词转换为数字向量,维度为`(vocab_size, embedding_dim)`。
- `gru_layer`捕获文本序列中的长期依赖关系,返回形状为`(batch_size, max_seq_len, hidden_size)`的输出。
- `output_layer`将GRU层的输出映射到情感类别,返回形状为`(batch_size, num_classes)`的概率分布。
**参数说明:**
- `vocab_size`:词汇表大小。
- `embedding_dim`:嵌入向量的维度。
- `hidden_size`:GRU层的隐藏单元数。
- `num_classes`:情感类别的数量。
**优化方式:**
- **数据增强:**使用同义词替换、随机删除等技术增强训练数据,提高模型的泛化能力。
- **正则化:**添加L1或L2正则化项,防止模型过拟合。
- **超参数调整:**通过网格搜索或贝叶斯优化等方法调整学习率、批大小等超参数。
**代码块 2:情感分析示例**
```python
# 输入文本
text = "这部电影太棒了,我强烈推荐!"
# 预处理文本
processed_text = preprocess(text)
# 预测情感
prediction = model.predict(processed_text)
# 输出预测结果
print("预测的情感:", np.argmax(prediction))
```
**逻辑分析:**
- `preprocess()`函数对文本进行预处理,包括分词、词干化等操作。
- `model.predict()`函数输入预处理后的文本,输出情感类别的概率分布。
- `np.argmax()`函数返回概率分布中最大值的索引,即预测的情感类别。
# 5. GRU与其他NLP模型的比较
### 5.1 GRU与LSTM
#### 5.1.1 理论对比
GRU(门控循环单元)和LSTM(长短期记忆)都是循环神经网络(RNN)的变体,用于处理序列数据。然而,它们在结构和性能上存在一些关键差异:
- **门结构:** GRU使用一个更新门和一个重置门,而LSTM使用三个门(输入门、忘记门和输出门)。GRU的更新门控制着当前状态信息与前一状态信息之间的更新程度,而重置门控制着前一状态信息被遗忘的程度。LSTM的输入门控制着新信息的引入,忘记门控制着旧信息的遗忘,输出门控制着输出信息的产生。
- **计算效率:** GRU的计算成本比LSTM低,因为它使用更简单的门结构和更少的参数。这使得GRU在处理大型数据集时更具效率。
- **长期依赖性:** LSTM通过其忘记门和输出门机制能够学习长期依赖关系。GRU也能够学习依赖关系,但通常不如LSTM有效。
#### 5.1.2 实践对比
在实践中,GRU和LSTM在不同的NLP任务上表现出不同的优势:
- **文本分类:** GRU和LSTM在文本分类任务上都表现良好。然而,GRU通常在计算效率方面具有优势,特别是在处理大型数据集时。
- **机器翻译:** LSTM在机器翻译任务上通常优于GRU,因为它能够学习更复杂的长期依赖关系。
- **问答系统:** GRU和LSTM都可用于构建问答系统。然而,LSTM在处理需要长期记忆的任务时可能更有效,例如回答需要对上下文进行推理的问题。
### 5.2 GRU与Transformer
#### 5.2.1 理论对比
Transformer是一种基于注意力机制的NLP模型,它在自然语言处理领域取得了突破性的进展。与GRU不同,Transformer不使用循环连接,而是使用注意力机制来捕获序列中元素之间的关系。
- **架构:** Transformer由编码器和解码器组成。编码器将输入序列转换为一组向量,而解码器使用这些向量生成输出序列。
- **注意力机制:** Transformer使用注意力机制来计算序列中不同元素之间的权重。这使得模型能够专注于与当前输出最相关的输入元素。
- **并行化:** Transformer可以并行计算,这使得它能够在大型数据集上进行高效训练。
#### 5.2.2 实践对比
Transformer在以下NLP任务上通常优于GRU:
- **机器翻译:** Transformer在机器翻译任务上取得了最先进的性能,因为它能够捕获句子中的复杂依赖关系。
- **文本摘要:** Transformer能够生成高质量的文本摘要,因为它可以关注文本中的关键信息并忽略无关信息。
- **对话生成:** Transformer在对话生成任务上表现出色,因为它能够学习对话中的上下文并生成连贯且有意义的回复。
然而,GRU在以下方面具有优势:
- **计算效率:** GRU的计算成本比Transformer低,因为它不使用注意力机制。
- **小型数据集:** GRU在小型数据集上可能比Transformer表现得更好,因为Transformer需要大量的数据来训练。
# 6. GRU在NLP中的未来发展
### 6.1 融合多模态数据
近年来,多模态学习已成为NLP领域的研究热点。GRU模型可以与其他模态数据(如图像、音频、视频)相结合,以增强对语言理解的丰富性。通过融合多模态数据,GRU模型可以更好地捕捉语言的语义和情感信息,从而提高NLP任务的性能。
### 6.2 提升模型可解释性
GRU模型的可解释性一直是一个挑战。为了解决这一问题,研究人员正在探索各种方法来提高GRU模型的可解释性。一种方法是使用可解释的AI技术,如LIME和SHAP,来解释GRU模型的预测。另一种方法是开发新的GRU变体,这些变体具有更高的可解释性。
### 6.3 探索新型GRU变体
GRU模型的不断发展催生了各种新的GRU变体。这些变体旨在提高GRU模型的性能、可解释性和效率。例如,双向GRU(BiGRU)通过同时处理文本的正向和反向序列来提高语言理解能力。门控递归单元(GRU)通过引入门控机制来提高GRU模型的训练效率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
门控递归神经网络(GRU)是一类先进的神经网络,在众多领域展现出强大的应用潜力。本专栏深入探讨了 GRU 的门控机制,揭示了其与 LSTM 的异同。从自然语言处理到语音识别、机器翻译、图像识别、医疗保健、金融、推荐系统、异常检测、欺诈检测、网络安全、交通管理、能源管理、制造业、零售业和时序预测等领域,GRU 都发挥着至关重要的作用。本专栏提供了丰富的案例分析和最佳实践,帮助读者了解 GRU 的优势,并做出明智的选择,以解决不同的任务。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
数据链路层深度剖析:帧、错误检测与校正机制,一次学懂

# 摘要
数据链路层是计算机网络架构中的关键组成部分,负责在相邻节点间可靠地传输数据。本文首先概述了数据链路层的基本概念和帧结构,包括帧的定义、类型和封装过程。随后,文章详细探讨了数据链路层的错误检测机制,包括检错原理、循环冗余检验(CRC)、奇偶校验和校验和,以及它们在错误检测中的具体应用。接着,本文介绍了数据链路层的错误校正技术,如自动重传请求(ARQ
【数据完整性管理】:重庆邮电大学实验报告中的关键约束技巧
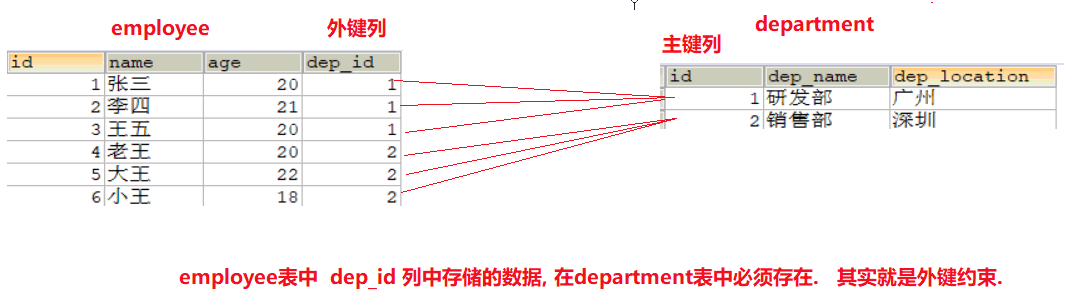
# 摘要
数据完整性是数据库管理系统中至关重要的概念,它确保数据的质量和一致性。本文首先介绍了数据完整性的概念、分类以及数据库约束的基本原理和类型。随后,文章深入探讨了数据完整性约束在实践中的具体应用,包括主键和外键约束的设置、域约束的管理和高级技巧如触发器和存储过程的运用。接着,本文分析了约束带来的性能影响,并提出了约束优化与维护的策略。最后,文章通过案例分析,对数据完整性管理进行了深度探讨,总结了实际操作中的
深入解析USB协议:VC++开发者必备的8个关键点
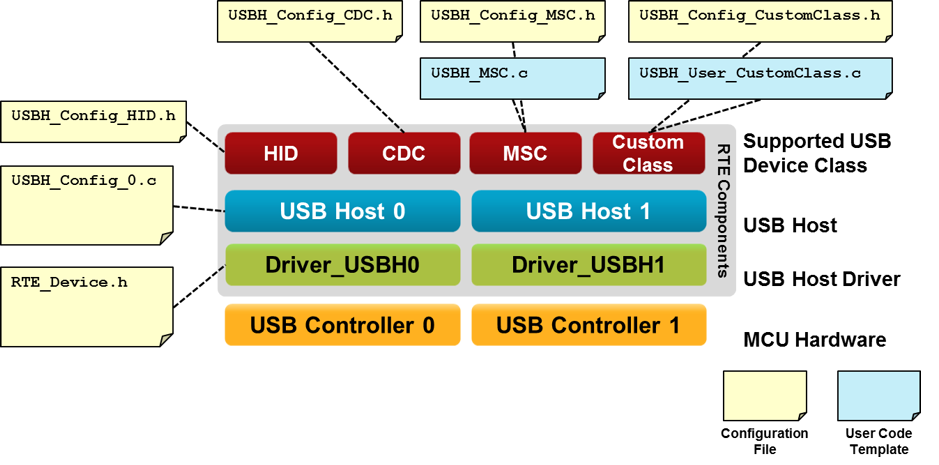
# 摘要
本文系统地介绍了USB协议的基础知识、硬件基础、数据传输机制、在VC++中的实现以及高级特性与编程技巧。首先概述USB协议的基础,然后详细探讨了USB硬件的物理接口、连接规范、电源管理和数据传输的机制。文章接着阐述了在VC++环境下USB驱动程序的开发和与USB设备通信的编程接口。此外,还涉及了USB设备的热插拔与枚举过程、性能优化,以及USB协议高级特性和编程技巧。最后,本文提供了USB设备的调试工具和方法,以
【科东纵密性能调优手册】:监控系统到极致优化的秘笈

# 摘要
性能调优是提高软件系统效率和响应速度的关键环节。本文首先介绍了性能调优的目的与意义,概述了其基本原则。随后,深入探讨了系统性能评估的方法论,包括基准测试、响应时间与吞吐量分析,以及性能监控工具的使用和系统资源的监控。在硬件优化策略方面,详细分析了CPU、内存和存储的优化方法。软件与服务优化章节涵盖了数据库、应用程序和网络性能调
【FPGA引脚规划】:ug475_7Series_Pkg_Pinout.pdf中的引脚分配最佳实践

# 摘要
本文全面探讨了FPGA引脚规划的关键理论与实践方法,旨在为工程师提供高效且可靠的引脚配置策略。首先介绍了FPGA引脚的基本物理特性及其对设计的影响,接着分析了设计时需考虑的关键因素,如信号完整性、热管理和功率分布。文章还详细解读了ug475_7S
BY8301-16P语音模块全面剖析:从硬件设计到应用场景的深度解读
# 摘要
本文详细介绍了BY8301-16P语音模块的技术细节、硬件设计、软件架构及其应用场景。首先概述了该模块的基本功能和特点,然后深入解析其硬件设计,包括主控芯片、音频处理单元、硬件接口和电路设计的优化。接着,本文探讨了软件架构、编程接口以及高级编程技术,为开发者提供了编程环境搭建和
【Ansys命令流深度剖析】:从脚本到高级应用的无缝进阶
# 摘要
本文深入探讨了Ansys命令流的基础知识、结构和语法、实践应用、高级技巧以及案例分析与拓展应用。首先,介绍了Ansys命令流的基本构成,包括命令、参数、操作符和分隔符的使用。接着,分析了命令流的参数化、数组操作、嵌套命令流和循环控制,强调了它们在提高命令流灵活性和效率方面的作用。第三章探讨了命令流在材料属性定义、网格划分和结果后处理中的应用,展示了其在提高仿真精度和效率上的实际价值。第四章介绍了命令流的高级技巧,包括宏定义、用户自定义函数、错误处理与调试以及并行处理与性能优化。最后,第五章通过案例分析和扩展应用,展示了命令流在复杂结构模拟和多物理场耦合中的强大功能,并展望了其未来趋势
【Ubuntu USB转串口驱动安装】:新手到专家的10个实用技巧

# 摘要
本文详细介绍了在Ubuntu系统下安装和使用USB转串口驱动的方法。从基础介绍到高级应用,本文系统地探讨了USB转串口设备的种类、Ubuntu系统的兼容性检查、驱动的安装步骤及其验证、故障排查、性能优化、以及在嵌入式开发和远程管理中的实际应用场景。通过本指南,用户可以掌握USB转串口驱动的安装与管理,确保与各种USB转串口设备的顺畅连接和高效使用。同时,本文还提
RH850_U2A CAN Gateway高级应用速成:多协议转换与兼容性轻松掌握

# 摘要
本文全面概述了RH850_U2A CAN Gateway的技术特点,重点分析了其多协议转换功能的基础原理及其在实际操作中的应用。通过详细介绍协议转换机制、数据封装与解析技术,文章展示了如何在不同通信协议间高效转换数据包。同时,本文还探讨了RH850_U2A CAN Gateway在实际操作过程中的设备初始化、协议转换功能实现以及兼容性测试等关键环节。此外,文章还介
【FPGA温度监测:Xilinx XADC实际应用案例】

# 摘要
本文探讨了FPGA在温度监测中的应用,特别是Xilinx XADC(Xilinx Analog-to-Digital Converter)的核心
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )