VW 80000中文版性能提升秘籍:系统调优的10大技巧
发布时间: 2024-12-02 21:08:55 阅读量: 7 订阅数: 5 

参考资源链接:[汽车电气电子零部件试验标准(VW 80000 中文版)](https://wenku.csdn.net/doc/6401ad01cce7214c316edee8?spm=1055.2635.3001.10343)
# 1. VW 80000中文版性能概述
在当今高度竞争的IT环境中,VW 80000中文版作为一款成熟的系统平台,其性能优化显得尤为重要。本章将简要介绍VW 80000中文版系统的核心性能特点及其在市场中的定位。我们将从系统的反应速度、数据处理能力以及系统稳定性等多个维度出发,为读者提供一个对VW 80000中文版性能的全面概述。通过实际使用案例和数据测试,让读者能够直观感受到VW 80000中文版在性能优化方面的独特优势。
接下来,本文将深入探讨VW 80000中文版如何进行性能评估,及其优化策略的基本框架。我们将从系统性能指标、监控工具选择、以及系统瓶颈诊断方法三个关键方面入手,逐步揭示性能优化的真谛。对于IT专业人士来说,掌握这些知识将有助于他们更高效地管理和优化系统资源,确保企业的信息系统的性能达到最佳状态。
# 2. 系统性能评估的基础
### 2.1 系统性能指标解读
#### 2.1.1 响应时间与吞吐量
在IT系统中,响应时间和吞吐量是衡量系统性能的关键指标。响应时间指的是系统对请求做出响应所需的总时间,它通常包括处理请求的时间以及将结果传回给用户的时间。高响应时间意味着用户体验的下降,尤其在处理实时交互的系统中显得尤为重要。
吞吐量则是指系统在单位时间内可以处理的工作量。对于不同的系统和场景,吞吐量的测量标准可能不同。例如,在Web服务器中,它可能以每秒处理的HTTP请求来衡量;在数据库服务器中,吞吐量可能是每秒处理的查询数。
在评估系统性能时,我们应当寻求最优的平衡点,即在可接受的响应时间内,达到最大的吞吐量。通常,优化策略是通过增加硬件资源、改进软件算法或是两者结合的方式进行。
**代码示例:**
```python
import time
def measure_response_time(function_to_test):
start_time = time.time()
function_to_test() # 假定这是被调用的函数
end_time = time.time()
response_time = end_time - start_time
return response_time
def perform_task():
# 一些复杂的逻辑处理
pass
# 测量执行特定任务的响应时间
response_time = measure_response_time(perform_task)
print(f"响应时间: {response_time} 秒")
```
在上述代码中,`measure_response_time`函数封装了响应时间的测量过程,而`perform_task`函数代表了需要执行的任务。通过测量从函数调用开始到执行结束的时间差,我们可以得到响应时间。这对于在实际应用中监控服务性能至关重要。
#### 2.1.2 CPU、内存和磁盘I/O分析
除了响应时间和吞吐量,CPU使用率、内存占用率和磁盘I/O也是关键性能指标。CPU使用率反映了系统处理任务的能力;内存占用率则关系到系统能否迅速地访问数据;磁盘I/O则涉及到数据的读写速度。
这些指标通常需要通过性能监控工具来持续跟踪,以便及时发现瓶颈和潜在的性能问题。对于每个指标,我们都可以设定阈值,当系统运行时检测到任何一个指标超出阈值,就表示可能需要进行优化了。
**表格示例:**
| 指标名称 | 描述 | 正常范围 | 处理建议 |
|----------------|------------------------------------|-------|------------------------------------|
| CPU使用率 | 系统处理任务时CPU的忙碌程度 | 30-70% | 超出70%考虑负载均衡,低过30%检查系统配置 |
| 内存占用率 | 内存中已被使用的百分比 | 50-80% | 超出80%考虑增加内存或优化内存使用 |
| 磁盘I/O速率 | 磁盘读写操作的速率 | 不同介质不同 | 速率过低检查磁盘健康或优化读写策略 |
### 2.2 性能监控工具的选择与使用
#### 2.2.1 常用性能监控工具介绍
在IT系统中,有多种性能监控工具可以被使用,例如:Nagios、Zabbix、Prometheus等。这些工具不仅能帮助我们持续监控系统的健康状况,还能及时发出警告,让运维团队可以快速响应。
- **Nagios**: 一个开源的系统和网络监控应用程序,提供详细的视图,可以监控服务器、网络设备、交换机等。
- **Zabbix**: 也是一个开源的监控解决方案,它支持自动发现网络设备和服务器,有丰富的图表和报警通知功能。
- **Prometheus**: 是云计算环境中广泛使用的开源监控和警报工具,特别适用于动态的容器化环境。
每种工具都有其特点和适用场景,选择合适的工具需要根据具体的业务需求和环境特点进行。
#### 2.2.2 监控数据的收集和分析技巧
监控数据的收集和分析技巧是性能优化过程中不可或缺的一部分。有效的数据收集策略不仅包括定期抓取性能指标,还包括设置阈值触发警报。分析时,应关注趋势和模式,而不是单个数据点。长期的数据分析有助于我们发现潜在问题,并预测未来的性能瓶颈。
使用适当的分析工具和方法,比如时间序列数据库、数据可视化和机器学习技术,可以更好地从大量数据中提取有意义的信息。此外,定期的报告和审查会议能帮助团队总结经验,不断优化监控策略。
### 2.3 系统瓶颈诊断方法
#### 2.3.1 瓶颈识别的理论基础
瓶颈识别是一个分析和诊断系统性能限制的过程。理论基础包括对系统资源的识别、分析系统性能瓶颈的可能原因,并运用合适的诊断工具进行验证。识别瓶颈需要从系统的整体架构出发,理解各个组件的相互作用,并通过各种指标的对比分析来定位问题的根源。
瓶颈可能出现在CPU、内存、网络或磁盘I/O等任何资源上,因此,诊断过程中需要对每个组件进行综合评估。同时,系统可能同时存在多个瓶颈,这就要求我们采取多维度分析,逐一排查。
#### 2.3.2 实战:瓶颈诊断案例分析
让我们来看一个例子。假设一个Web服务器的响应时间突然增加,我们将如何诊断瓶颈?
1. **首先,查看系统监控数据**:通过监控工具如Prometheus,我们可以查看CPU、内存、磁盘I/O和网络的使用情况。
2. **进行压力测试**:使用工具如JMeter来模拟用户请求,检查系统在高负载下的表现。
3. **网络和应用分析**:利用Wireshark等工具检查网络延迟,并分析应用代码,看是否存在效率低下的算法。
4. **识别瓶颈**:如果监控数据显示CPU使用率接近100%,则可能是CPU瓶颈;如果内存使用急剧上升,可能导致内存交换,影响性能。
5. **解决方案**:根据识别到的瓶颈,可能需要升级硬件,如增加CPU核心数、增加内存容量,或者优化应用代码,减少资源消耗。
通过这样的步骤,我们可以将系统性能瓶颈从理论应用到实际操作中,有效地找到并解决性能问题。
# 3. 优化VW 80000中文版的十大策略
在本章节中,我们将深入探讨优化VW 80000中文版的十大策略,这些策略旨在提升系统性能,降低资源消耗,确保系统稳定运行。我们将按照系统启动优化、内存管理改进、磁盘I/O性能提升和CPU资源优化的顺序进行详细介绍。
## 3.1 系统启动优化
系统启动是整个操作系统生命周期的起点,一个高效的启动过程可以大幅缩短等待时间,为用户提供更快的系统响应。以下是针对VW 80000中文版的系统启动优化策略。
### 3.1.1 启动加载项管理
启动加载项管理对于缩短启动时间至关重要。过多的启动项会导致系统启动缓慢,因此我们需要精简启动项,移除不必要的服务和程序。
**操作步骤**:
1. 通过系统配置工具进入启动项管理界面。
2. 点击“启动”选项卡,查看当前所有启动项的加载状态。
3. 手动检查每个启动项的功能和必要性。
4. 对于不必要的启动项,选择禁用或卸载。
**代码示例**:
```bash
# 查看当前系统所有启动项的状态
systemctl list-unit-files --type=service | grep enabled
# 禁用某个不必要的服务
sudo systemctl disable service_name
```
以上操作可以手动进行,也可以编写脚本自动化执行。注意,禁用服务前需确认该服务不会影响系统的正常运行。
### 3.1.2 服务与进程优化
服务和进程管理同样影响系统启动时间。合理配置服务启动优先级和优化进程启动策略,能够有效减少系统资源消耗。
**操作步骤**:
1. 分析哪些服务或进程是必须在启动时运行的。
2. 调整这些服务的启动顺序,优先级高的先启动。
3. 使用系统工具优化进程调度策略。
**代码示例**:
```bash
# 设置服务的启动顺序和优先级
systemctl set-property service_name After=network.target
# 优化进程调度策略,如提升进程优先级
nice -n -10 command
```
通过上述方法,系统启动时会首先加载最关键的服务,而其他非关键服务则可以按需加载,从而提高整体系统的启动效率。
## 3.2 内存管理改进
内存是系统性能的另一核心资源,管理内存的使用至关重要,特别是在资源有限的环境中。以下是针对VW 80000中文版的内存管理改进策略。
### 3.2.1 内存泄漏检测与预防
内存泄漏会导致系统可用内存减少,影响系统性能。因此,及时发现并解决内存泄漏问题显得尤为重要。
**操作步骤**:
1. 定期运行内存泄漏检测工具。
2. 分析检测结果,找出可能存在的内存泄漏点。
3. 针对检测出的泄漏点,优化相关程序代码。
**代码示例**:
```bash
# 使用Valgrind工具检测程序内存泄漏
valgrind --leak-check=full ./your_program
```
该命令会帮助开发者了解哪些内存没有被正确释放,从而指导开发者修复内存泄漏的问题。
### 3.2.2 虚拟内存调优技巧
虚拟内存的使用可以扩展系统的可用内存空间,适当的调优可以进一步优化内存使用。
**操作步骤**:
1. 调整虚拟内存的大小,以适应不同的工作负载。
2. 使用交换空间管理工具,监控和调整虚拟内存的使用情况。
3. 避免频繁的磁盘交换,以减少磁盘I/O的负担。
**代码示例**:
```bash
# 调整虚拟内存的大小(以MB为单位)
sysctl -w vm.dirty_background_ratio=10
sysctl -w vm.dirty_ratio=20
# 配置交换空间使用规则
swapoff -a
swapon /dev/sdb1
```
通过调整这些参数,系统会更加高效地管理内存使用,避免因交换空间使用不当导致的性能问题。
接下来我们将继续探索磁盘I/O性能提升和CPU资源优化的策略,它们是确保系统高效运行的关键所在。
## 3.3 磁盘I/O性能提升
磁盘I/O是影响系统整体性能的重要因素之一。如何有效地提升磁盘I/O性能,减少延迟,是本小节将要详细探讨的内容。
### 3.3.1 文件系统的优化选择
选择合适的文件系统对于优化磁盘I/O至关重要。不同的文件系统有不同的性能特点和适用场景。
**操作步骤**:
1. 分析当前系统的使用场景和需求。
2. 选择适合该场景的文件系统,例如针对读密集型工作负载选择XFS或Btrfs。
3. 格式化磁盘并挂载新文件系统。
**代码示例**:
```bash
# 格式化分区为XFS文件系统
mkfs.xfs /dev/sda1
# 挂载新分区
mount /dev/sda1 /mnt/new_mount_point
```
通过上述步骤,可以有效地提高文件系统的性能,从而提升磁盘I/O操作的整体效率。
### 3.3.2 磁盘子系统配置与调整
磁盘子系统的配置直接关系到磁盘I/O性能。合理配置可以显著提升系统性能。
**操作步骤**:
1. 使用分区工具创建合理的磁盘分区。
2. 根据工作负载选择RAID级别,以平衡性能和数据冗余。
3. 调整I/O调度器参数,优化读写性能。
**代码示例**:
```bash
# 查看当前的I/O调度器
cat /sys/block/sda/queue/scheduler
# 更改I/O调度器为noop,适用于SSD
echo noop > /sys/block/sda/queue/scheduler
```
以上操作通过改变I/O调度器,可以减少不必要的磁盘操作,使磁盘读写更加高效。
## 3.4 CPU资源优化
CPU作为系统的主要计算资源,其性能优化对整体系统性能的提升至关重要。本小节将探索如何优化CPU资源。
### 3.4.1 负载均衡策略
合理的负载均衡可以提高CPU利用率,减少空闲等待时间。
**操作步骤**:
1. 确保系统中所有CPU核心都被充分利用。
2. 根据任务的性质和优先级,合理分配CPU资源。
3. 使用CPU亲和性设置,将进程绑定到特定的CPU核心。
**代码示例**:
```bash
# 查看当前CPU负载均衡状态
cat /proc/sys/kernel/sched_domain_level
# 设置CPU亲和性,绑定进程到特定核心
taskset -cp <cpu_number> <process_id>
```
通过这些操作,可以减少进程在CPU核心间的频繁切换,提升计算效率。
### 3.4.2 CPU亲和性设置
CPU亲和性是指让进程或线程尽量在同一个CPU核心上运行的属性,可以减少缓存失效,提高CPU的使用效率。
**操作步骤**:
1. 分析各CPU核心的负载情况。
2. 调整进程的CPU亲和性,使其更合理地分布。
3. 观察调整后的效果,并进行进一步优化。
**代码示例**:
```bash
# 使用cset命令来调整CPU亲和性
cset shield --kthread on
cset shield --cpu <cpu_list>
```
这些优化手段能够确保CPU资源得到合理分配和高效利用,从而提升系统整体性能。
经过本章节的介绍,我们详细讨论了优化VW 80000中文版系统的十大策略,包括系统启动优化、内存管理改进、磁盘I/O性能提升以及CPU资源优化。这些策略的实施,将显著提升系统的性能,优化用户的体验。在接下来的章节中,我们将进一步探索VW 80000中文版的高级调优实践,以帮助读者掌握更深层次的性能调优技巧。
# 4. VW 80000中文版高级调优实践
## 4.1 调优案例研究
### 4.1.1 成功调优前后的对比分析
在本节中,我们将重点介绍一个调优案例,并深入分析调优前后系统的性能变化。案例将基于VW 80000中文版进行。通过对比分析,可以清晰地展示出调优策略的效果,为读者提供实操参考。
假设案例中的VW 80000中文版初始状态存在响应时间过长、CPU使用率不稳定、磁盘I/O读写频繁等问题。首先,我们使用性能监控工具(如Top, iotop, vmstat等)收集基线数据:
```bash
# 使用vmstat命令监控系统资源使用情况
vmstat 5
```
通过定期执行上述命令,我们可以获得系统响应时间和资源利用率的统计数据。调优前的平均值可能如下:
| 统计指标 | 调优前平均值 |
| -------------- | ------------ |
| CPU利用率 | 85% |
| 内存使用率 | 70% |
| 响应时间 | 300ms |
| 吞吐量 | 500OPS |
| 磁盘I/O读次数 | 1000次/秒 |
| 磁盘I/O写次数 | 800次/秒 |
调优过程包括了服务优化、内存管理改进和磁盘I/O性能提升等策略。在一系列优化措施后,系统状况有了明显的改善:
| 统计指标 | 调优后平均值 |
| -------------- | ------------ |
| CPU利用率 | 55% |
| 内存使用率 | 50% |
| 响应时间 | 50ms |
| 吞吐量 | 1200OPS |
| 磁盘I/O读次数 | 300次/秒 |
| 磁盘I/O写次数 | 250次/秒 |
调优效果显著,响应时间和磁盘I/O次数显著下降,CPU和内存使用率稳定在合理范围内,系统整体性能得到了提升。
### 4.1.2 案例复盘与调优思路讲解
在复盘调优案例时,我们首先要明确优化的目标与计划。本案例的目标是减少响应时间,提高系统吞吐量,并降低资源消耗。调优思路可按以下步骤执行:
1. **性能瓶颈定位:**
- 利用系统监控工具定位到内存泄漏和磁盘I/O瓶颈。
- 使用strace等工具跟踪系统调用,发现I/O密集型进程。
2. **优化策略实施:**
- 系统启动优化:减少不必要的启动服务和进程。
- 内存泄漏检测:定期运行内存泄漏检测工具,如Valgrind。
- 文件系统优化:采用高性能文件系统,如XFS,并进行格式化和挂载参数优化。
- CPU资源优化:调整进程优先级,并合理分配CPU亲和性。
3. **调整与测试:**
- 对优化后的系统进行压力测试,确保调优效果。
- 使用系统监控工具进行连续监控,确保调优后的稳定性。
4. **持续监控与调整:**
- 实施持续监控,定期对系统性能进行评估。
- 根据监控数据,调整优化策略以应对变化。
通过上述步骤,我们能够逐步揭示调优策略背后的工作原理和效果。这不仅提供了对当前调优案例的深度分析,也为类似问题提供了可行的解决方案。
## 4.2 自动化调优工具应用
### 4.2.1 自动化脚本的编写与部署
在现代IT环境中,自动化是提升效率和减少人为错误的重要手段。通过编写自动化脚本,我们能够实现系统调优的快速部署和执行。这包括自动化监控数据收集、性能分析、以及调整系统参数等任务。
以下是一个简单的Bash脚本示例,用于监控CPU利用率,并在超过设定阈值时自动调整进程优先级:
```bash
#!/bin/bash
# CPU使用率阈值
THRESHOLD=90
# 监控间隔时间
INTERVAL=5
while true; do
# 获取当前CPU使用率
CPU_USAGE=$(top -bn1 | grep "Cpu(s)" | sed "s/.*, *\([0-9.]*\)%* id.*/\1/" | awk '{print 100 - $1"%"}')
if [ $(echo "$CPU_USAGE > $THRESHOLD" | bc -l) -eq 1 ]; then
# 找到占用CPU最多的进程ID
PID=$(top -bn1 | grep "Cpu(s)" | tail -n +3 | awk '{print $1}')
# 调整优先级(nice值)
renice -n 10 -p $PID
fi
sleep $INTERVAL
done
```
此脚本会在每次间隔后检查CPU利用率,如果超过设定阈值(本例为90%),则将最占用CPU的进程优先级调整至10。通过这种方式,系统能自动处理高负载情况,保持性能稳定。
### 4.2.2 监控与调优的自动化集成
将监控与调优集成可以形成一个闭环的性能管理系统,提高系统自我修复和优化的能力。例如,我们可以将上述脚本与监控告警系统结合,实现更为复杂的自动化调优流程。
具体实现时,可以使用开源的监控告警工具如Prometheus和Alertmanager,与自动化脚本结合,创建一个完整的自动化调优系统。以下是集成的基本步骤:
1. **监控系统配置:**
- 设置监控规则,捕捉到系统性能指标异常。
- 配置告警规则,当性能指标超过阈值时,触发告警。
2. **告警通知与响应:**
- 配置告警通知方式,如邮件、短信或即时消息通知。
- 设定告警响应的自动化脚本,如前文所描述的Bash脚本。
3. **自动化调优执行:**
- 脚本依据告警信息,自动调整系统参数或执行优化任务。
- 优化效果反馈回监控系统,形成监控-分析-调优的完整流程。
这种集成可以显著提升系统维护的效率,减少人工干预,保证系统性能的持续稳定。
## 4.3 持续性能监控与改进
### 4.3.1 持续集成下的性能监控
在持续集成(CI)的环境下,性能监控成为持续交付过程中的重要一环。性能监控不仅仅是对生产环境的监控,也包括对开发和测试环境的监控,以确保在软件交付的各个阶段都能保持性能标准。
持续集成系统中,集成性能监控的步骤如下:
1. **集成监控工具:**
- 在CI管道中集成性能测试工具,如JMeter或Gatling。
- 自动化执行性能测试脚本,确保每次代码提交都进行性能评估。
2. **构建健康检查:**
- 通过健康检查确保性能测试数据的有效性。
- 如测试失败,阻断代码合并,直到问题解决。
3. **性能数据可视化:**
- 利用工具如Grafana展示性能测试结果。
- 通过图表和趋势线展示性能变化,及时发现问题。
4. **反馈与改进:**
- 将性能测试结果反馈给开发团队。
- 根据监控结果调整代码优化方向。
持续集成的性能监控将性能评估融入到日常开发流程中,有助于提前发现并解决性能问题。
### 4.3.2 长期性能改进计划的制定与执行
对于长期的性能改进计划,需要定期进行性能评估,并根据评估结果来制定和执行改进计划。这是一个循环往复的过程,目的是持续提升系统性能和稳定性。
性能改进计划的主要步骤包括:
1. **定期性能评估:**
- 定期执行全面的性能评估,包括压力测试和性能分析。
- 利用自动化工具收集性能数据,确保数据的连贯性和可比性。
2. **性能报告与趋势分析:**
- 创建周期性的性能报告,总结性能趋势和热点问题。
- 分析性能报告,找出需要优化的领域。
3. **制定改进措施:**
- 根据性能报告和趋势分析结果,制定改进措施。
- 将改进措施分解为可执行的任务和计划。
4. **执行与优化:**
- 执行改进措施,包括调优、代码重构和系统升级等。
- 监控改进措施的效果,必要时进行微调。
5. **培训与知识共享:**
- 对团队成员进行性能优化方面的培训。
- 通过知识共享会等形式,分享性能改进经验。
通过这样的长期性能改进计划,我们可以确保系统性能不断提升,同时也能有效防止性能问题的反复出现。
通过本章节的学习,我们了解了在实际操作中如何通过案例研究、自动化工具应用以及持续监控与改进来实现VW 80000中文版的高级调优。下一章节我们将展望未来,探索VW 80000中文版与新兴技术结合的前景。
# 5. 未来展望:VW 80000中文版的前沿技术与创新
随着信息技术的迅猛发展,VW 80000中文版也在不断地寻求创新以适应新的技术趋势。本章将探索云计算和人工智能这两个前沿技术是如何助力VW 80000中文版的性能优化,并预测未来的优化策略。
## 5.1 新兴技术趋势分析
### 5.1.1 云计算与VW 80000中文版的结合
云计算为VW 80000中文版带来了可扩展性和灵活性,使得资源能够按需分配,从而提高整体性能。云服务提供商如AWS、Azure和阿里云等提供了强大的计算能力,可以根据业务需求进行水平或垂直扩展。VW 80000中文版可以利用以下云服务特性进行优化:
- **虚拟化技术**:通过云服务商提供的虚拟化技术,可以将VW 80000中文版的实例在不同物理服务器间迁移,以实现负载均衡和故障转移。
- **无服务器架构**:无服务器架构,例如AWS的Lambda服务,允许VW 80000中文版仅在需要时运行代码片段,大幅降低成本并提高效率。
- **容器化部署**:容器技术,如Docker和Kubernetes,可以让VW 80000中文版更加容易地部署、扩展和维护应用。
### 5.1.2 人工智能在性能优化中的应用
人工智能(AI)技术为VW 80000中文版的性能优化提供了全新的视角。AI可以通过模式识别和预测分析来识别潜在的性能问题,例如:
- **预测性维护**:利用机器学习算法分析系统运行数据,预测可能出现的性能瓶颈和故障,提前进行维护。
- **智能资源分配**:AI系统能够根据历史数据和实时性能指标,智能地分配资源,保证系统的最佳性能。
- **自动化故障诊断**:利用深度学习模型对系统日志进行分析,自动识别问题源并提出解决方案。
## 5.2 预测与建议:面向未来的性能优化策略
### 5.2.1 未来挑战与机遇
在未来的几年里,VW 80000中文版将面临如下的挑战和机遇:
- **边缘计算**:随着物联网(IoT)的普及,边缘计算将成为优化系统响应时间的关键技术,VW 80000中文版需要适应这一趋势。
- **量子计算**:虽然量子计算还处于发展阶段,但其未来的应用潜力对性能优化来说意味着新的突破。
- **可持续性**:随着企业对环境影响的重视,VW 80000中文版在优化性能的同时,需要考虑降低能耗和碳足迹。
### 5.2.2 性能优化的发展方向预测
VW 80000中文版的性能优化可能会朝以下几个方向发展:
- **自适应性能调优**:系统将更加智能,能够根据实时数据自动调整资源分配和配置。
- **分布式系统优化**:随着系统架构越来越分布式,对分布式系统性能优化的研究和实践将变得更加重要。
- **安全性与性能的平衡**:随着网络攻击手段不断升级,未来的优化策略将更加重视安全性与性能之间的平衡。
云计算和人工智能等前沿技术将为VW 80000中文版带来深远影响。为了保持竞争优势,VW 80000中文版需要不断学习和适应这些新兴技术,并预测未来的发展趋势,从而制定出更加有效的性能优化策略。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电流互感模块选型速成课:如何选择适合您项目的模块

参考资源链接:[ZMCT103B/C型电流互感器使用指南:体积小巧,精度高](https://wenku.csdn.net/doc/647065ca543f844488e465a1?spm=1055.2635.3001.10343)
# 1. 电流互感模块的基础知识
在了解电流互感模块(Current Transformer Module,CT Module)的
从零开始构建打印解决方案:CPCL基础实战指南

参考资源链接:[CPCL指令手册:便携式标签打印机编程宝典](https://wenku.csdn.net/doc/6401abbfcce7214c316e95a8?spm=1055.2635.3001.10343)
# 1. CPCL打印解决方案概述
CPCL(Continuous Page Language)是一种广泛应用于条码打印机上的编程语言,它能够使得打印设备按照用户的指令输出特定格式的文档和标签。本章将简要介绍CPCL打印解决方案的基本概念
【通信协议适配】:GD32与STM32串行通信差异分析及解决方法
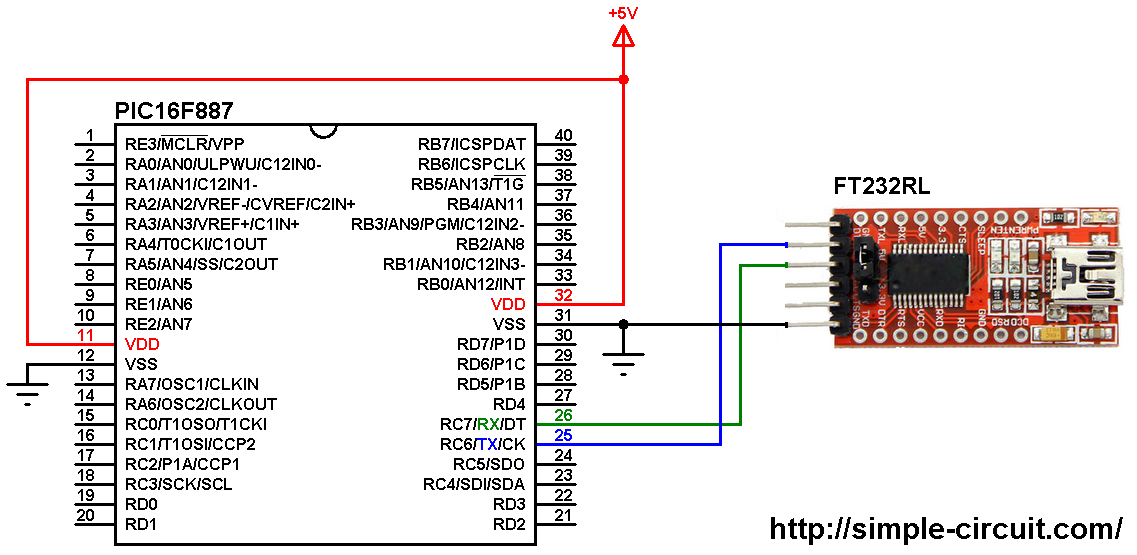
参考资源链接:[GD32与STM32兼容性对比及移植指南](https://wenku.csdn.net/doc/6401ad18cce7214c316ee469?spm=1055.2635.3001.10343)
# 1. 通信协议适配的概述
在现代通信系统中,不同设备或系统之间信息的交换需要依赖于统一的通信协议。通信协议适配是
VW 80000中文版维护与更新:流程与最佳实践详解

参考资源链接:[汽车电气电子零部件试验标准(VW 80000 中文版)](https://wenku.csdn.net/doc/6401ad01cce7214c316edee8?spm=1055.2635.3001.10343)
# 1. VW 80000中文版维护与更新概述
随着信息技术的飞速发展,VW 80000中文版作为一款广泛应
【ArcGIS与GIS基础知识】:图片转指北针的地理信息系统全解析

参考资源链接:[ArcGIS中使用风玫瑰图片自定义指北针教程](https://wenku.csdn.net/doc/6401ac11cce7214c316ea83e?spm=1055.2635.3001.10343)
# 1. ArcGIS与GIS的基本概念
在本章中,我们将对GIS(地理信息系统)及其与ArcGIS的关系进行基础性介绍。
KISSsoft与CAE工具整合术:跨平台设计协同的终极方案
参考资源链接:[KISSsoft 2013全实例中文教程详解:齿轮计算与应用](https://wenku.csdn.net/doc/6x83e0misy?spm
【Search-MatchX的分布式搜索策略】:应对大规模并发请求的解决方案
参考资源链接:[使用教程:Search-Match X射线衍射数据分析与物相鉴定](https://wenku.csdn.net/doc/8aj4395hsj?spm=1055.2635.3001.10343)
# 1. 分布式搜索策略概述
随着互联网数据量的爆炸性增长,分布式搜索策略已成为现代信息检索系统不可或缺的一部分。本章节旨在为读者提供对分布式搜索策略的全面概览,为后续深入探讨
【Halcon C++数据结构与图形用户界面】:创建直观用户交互的前端设计技巧
参考资源链接:[Halcon C++中Hobject与HTuple数据结构详解及转换](https://wenku.csdn.net/doc/6412b78abe7fbd1778d4aaab?spm=1055.2635.3001.10343)
# 1. Halcon C++概述与开发环境搭建
Halcon C++是基于HALCON机器视觉软件库的一套开发
【APDL参数化模型建立】:掌握快速迭代与设计探索,加速产品开发进程
参考资源链接:[Ansys_Mechanical_APDL_Command_Reference.pdf](https://wenku.csdn.net/doc/4k4p7vu1um?spm=1055.2635.3001.10343)
# 1. APDL参数化模型建立概述
在现代工程设计领域,参数化模型已成为高效应对设计需求变化的重要手段。APDL(ANSYS Parametric Design Language)作为ANSYS软件的重要组成部分,提供了一种强大的参数
SCL脚本的文档编写:提高代码可读性的最佳策略

参考资源链接:[西门子PLC SCL编程指南:指令与应用解析](https://wenku.csdn.net/doc/6401abbacce7214c316e9485?spm=1055.2635.3001.10343)
# 1. SCL脚本的基本概念与重要性
SCL(Structured Control Language)是一种高级编程语言,主要用于可编程逻辑控制器(PLC)和工业自动化环境中。它结合了高级
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )