PyTorch梯度上升揭秘:可解释性的基石
发布时间: 2024-12-12 05:02:57 阅读量: 8 订阅数: 19 

基于java的经典诗文学习爱好者学习交流平台的设计与实现答辩PPT.ppt
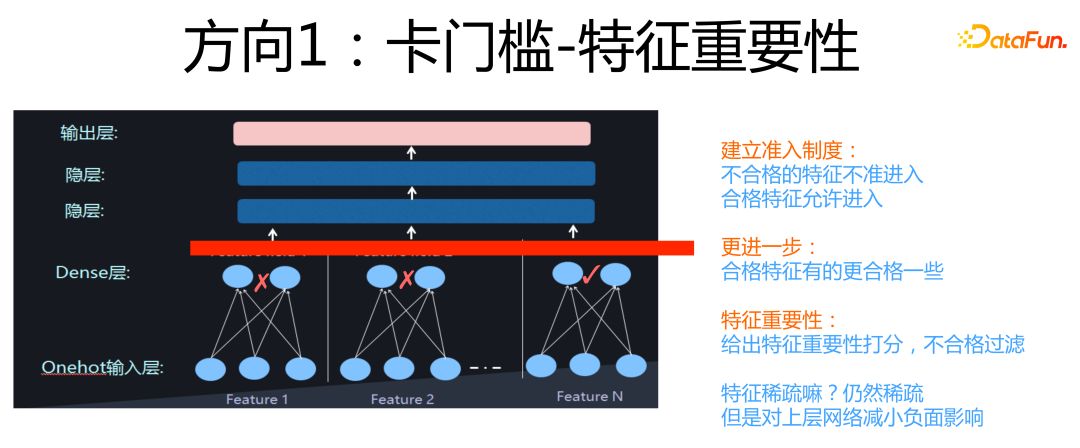
# 1. PyTorch梯度上升的基本概念
在机器学习领域,梯度上升是一种优化算法,用于求解最大化问题,尤其是在参数估计和模型训练中扮演着重要角色。通过迭代调整参数来增加目标函数的值,这种方法与梯度下降(最小化问题的解决方法)相对。在PyTorch框架中,梯度上升能够有效地用于各种机器学习任务,包括但不限于神经网络的训练。理解梯度上升的原理及其与PyTorch的结合使用,对于提高模型性能和开发复杂的机器学习系统至关重要。接下来的章节,我们将深入探讨PyTorch中的梯度计算、优化算法以及梯度上升的具体应用。
# 2. PyTorch中的梯度计算和优化算法
### 2.1 梯度计算的数学基础
#### 2.1.1 梯度定义及其几何意义
在数学中,梯度是多元函数偏导数构成的向量,指向的是函数增长最快的方向。几何上,我们可以将梯度视为在多维空间中,函数在某一点的切平面的法线方向。梯度的大小表示了函数在该方向上的增长率。
梯度的几何意义在机器学习中尤为重要,因为很多优化算法,比如梯度上升,都依赖于梯度来指导模型参数的更新方向。在优化过程中,我们通常希望沿着梯度的反方向(因为是最大化问题)移动参数以增加目标函数的值。
#### 2.1.2 自动微分机制解析
自动微分(Automatic Differentiation,AD)是计算导数的一种方法,它能够高效、准确地进行大规模计算。自动微分的关键在于将复杂函数分解为一系列基本运算,并利用链式法则逐步构建起计算导数的图(computational graph)。
在PyTorch中,自动微分机制主要通过定义一个动态计算图(Dynamic Computational Graph,DCG)来实现。在DCG中,每个运算节点会记录必要的信息用于反向传播。当执行反向传播时,PyTorch从输出节点开始,递归地计算并传播每个节点的梯度,最终得到关于模型参数的梯度信息。
### 2.2 PyTorch梯度上升的实现原理
#### 2.2.1 PyTorch张量和运算
PyTorch使用张量(tensor)作为数据结构来表示多维数组,是执行各种运算的基础。PyTorch张量支持各种运算,包括加法、乘法、指数等,并且还支持对张量的梯度进行跟踪。
为了进行梯度计算,PyTorch中的张量必须设置`requires_grad=True`属性。这意味着在进行运算时,PyTorch会跟踪对这些张量的操作,并为后续的梯度计算准备好计算图。
```python
import torch
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x * 2
z = y * y + 1
z.backward() # 计算 z 相对于 x 的梯度
print(x.grad) # 输出 [4.0, 8.0, 12.0]
```
在上面的例子中,我们创建了一个需要梯度的张量`x`,然后进行了两次运算。最后,通过调用`z.backward()`计算了`z`关于`x`的梯度,并将其存储在`x.grad`中。
#### 2.2.2 优化器的选择和配置
在PyTorch中,优化器(optimizer)是用来调整模型参数以最小化损失函数的算法。优化器内部包含了模型参数更新规则,常见的优化器包括SGD(随机梯度下降)、Adam、Adagrad等。
选择适当的优化器对于模型的收敛速度和最终性能至关重要。通常,Adam因为其自适应调整学习率的特性,在很多情况下表现良好。
```python
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
```
在上述代码中,我们创建了一个Adam优化器的实例,传入模型参数`model.parameters()`以及初始学习率`lr=1e-3`。在每次训练迭代中,我们可以使用如下代码进行参数更新:
```python
optimizer.zero_grad() # 清除之前梯度
loss.backward() # 计算新的梯度
optimizer.step() # 更新参数
```
### 2.3 PyTorch优化算法的深入探究
#### 2.3.1 常见优化算法的比较
不同的优化算法有不同的收敛速度和收敛质量,常见的优化算法包括:
- **SGD**:通过随机样本更新参数,需要设置合适的学习率和动量。
- **Adam**:结合了RMSprop和动量优化的特性,适用于不同的问题。
- **Adagrad**:适应性学习率算法,对于稀疏数据表现良好。
- **RMSprop**:通过调整学习率,避免了Adagrad的学习率衰减问题。
以下是使用PyTorch实现这些优化算法的基本代码示例:
```python
# 使用不同优化器的基本框架
# SGD
sgd_optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)
# Adam
adam_optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# Adagrad
adagrad_optimizer = torch.optim.Adagrad(model.parameters(), lr=1e-3)
# RMSprop
rmsprop_optimizer = torch.optim.RMSprop(model.parameters(), lr=1e-3)
```
#### 2.3.2 超参数调整与模型训练
超参数调整是机器学习中非常关键的步骤,对于优化算法来说,常见的超参数包括学习率、动量等。
调整学习率是影响模型训练效果的重要因素。学习率太高可能导致训练过程中损失函数无法稳定下降,而学习率太低则可能导致训练速度过慢或者陷入局部最小值。
动量(Momentum)则是一个帮助加速SGD在相关方向上的收敛,并抑制振荡的超参数。它通过累积先前梯度的一部分来实现,可以帮助算法跳出局部最小值。
```python
# 学习率和动量调整示例
# 学习率衰减策略
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
# 优化器配置
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
```
在训练模型时,通常会进行多次迭代,每一轮迭代称为一个epoch。每个epoch中,都会遍历一次训练数据集,并更新模型的参数。同时,一般在每个epoch结束后,对验证集进行评估,并根据需要调整超参数。
# 3. 梯度上升在PyTorch中的应用案例
在深度学习领域,梯度上升是优化算法的核心组成部分。通过对损失函数的梯度上升,我们可以迭代地调整模型参数,以最小化损失函数,从而训练出有效的机器学习模型。在本章中,我们将通过三个不同的应用场景深入探讨梯度上升法在PyTorch中的实际应用,以及如何使用PyTorch实现这些方法。
## 3.1 线性回归模型的梯度上升实现
### 3.1.1 线性回归基础和梯度上升法
线性回归是最基本的回归模型,其目的是根据一个或多个自变量(特征)来预测一个连续的因变量(目标变量)。在线性回归模型中,我们尝试找到最合适的权重(系数)来描述特征和目标变量之间的线性关系。梯度上升法作为一种优化手段,在线性回归中用于寻找使误差平方和最小化的参数值。
### 3.1.2 PyTorch代码实现和分析
在PyTorch中实现线性回归模型的梯度上升法可以分为以下步骤:
1. 定义模型参数和超参数。
2. 定义损失函数。
3. 实现梯度上升优化步骤。
4. 训练模型并评估结果。
下面是一个简单的线性回归模型的PyTorch实现示例代码:
```python
import torch
import torch.op
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“PyTorch实现模型可解释性的实例”提供了全面指南,帮助读者掌握PyTorch框架中的模型可解释性技术。从入门到精通,该专栏涵盖了十个关键步骤,深入解析了核心知识和技术原理。通过实践指南和详细的实例,读者将学习如何构建可解释的AI系统,提升模型的可视化和可解释性。专栏还探讨了PyTorch中的注意力机制、梯度上升和激活函数等高级技术,以及它们对模型可解释性的影响。此外,还提供了模型评估和调试技巧,帮助读者有效衡量和解决可解释性问题。通过这个专栏,读者将全面掌握PyTorch模型可解释性,打造透明、可信赖的AI系统。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Desigo CC 系统概述】:楼宇自动化的新视界

参考资源链接:[Desigo CC 培训资料.pdf](https://wenku.csdn.net/doc/6412b739be7fbd1778d49876?spm=1055.2635.3001.10343)
# 1. Desigo CC系统概念与架构
## Desigo CC系统简介
Desigo CC,作为楼宇自动化和智能建
【后端地图数据集成】:无缝融入Web应用的中国地图JSON数据包

参考资源链接:[中国省级行政区Json数据包](https://wenku.csdn.net/doc/3h7d7rsva2?spm=1055.2635.3001.10343)
# 1. 后端地图数据集成概述
在当今数字化的世界中,地图数据已成为后端服务不可或
PELCO-D协议入门指南:掌握基本概念与安装步骤(新手必看:一文读懂视频监控基础)
参考资源链接:[PELCO-D协议中文.docx](https://wenku.csdn.net/doc/6412b6c4be7fbd1778d47e68?spm=1055.2635.3001.10343)
# 1. PELCO-D协议概述
PELCO-D协议,一种广泛应用于闭路电视(CCTV)监控摄像机的控制协议,其核心优势在于实现了远程控制云台和镜头的动作。本章将简要介绍PELCO-D协议的定义、用途以及它的应用范围。
## 1.1 PELCO-D协议定义
PELCO-D协议是由美国PELCO公司开发的,用于控制PTZ(Pan, Tilt, Zoom)摄像机的行业标准协议。它使得用户能
【KEPServer EX Modbus性能调优】:实现最佳通讯效率的5个策略
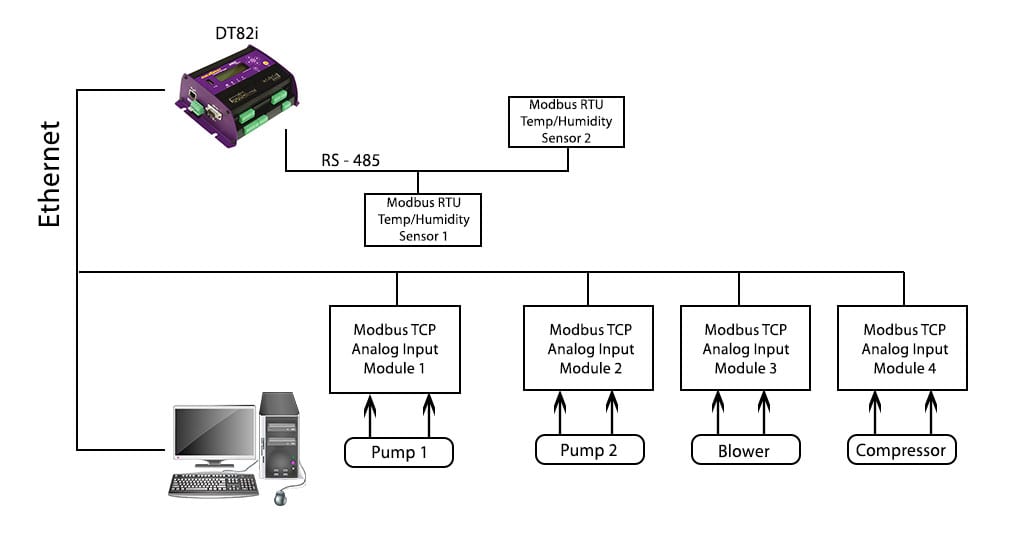
参考资源链接:[KEPServer配置Modibus从站通讯](https://wenku.csdn.net/doc/6412b74cbe7fbd1778d49caf?spm=1055.2635.3001.10343)
# 1. KEPServer EX Modbus的通讯基础
KEPServer EX是一种广泛使用的工业通讯服务器,它支持多种通讯协议,其中Modbu
进销存系统需求分析:揭示业务需求核心的终极指南

参考资源链接:[进销存管理系统详细设计:流程、类图与页面解析](https://wenku.csdn.net/doc/6412b5b2be7fbd1778d44129?spm=1055.2635.3001.10343)
# 1. 进销存系统需求概述
进销存系统是现代企业管理中不可或缺的组成部分,它涉及到企业的核心业务——采购、销售以及库存管理。正确理解并明确这些需求对于提高企业的运营效
自动化工程中的PIDE指令:最佳应用实践
参考资源链接:[RSLogix5000中的PIDE指令详解:高级PID控制与操作模式](https://wenku.csdn.net/doc/6412b5febe7fbd1778d45211?spm=1055.2635.3001.10343)
# 1. PIDE指令概念解析
PIDE(Programmable Industrial Digital Executor)指令,是一种专为工业自动化设计的高效指令集,它通过可编程接口使得工业设备能够实现精确、灵活的控制。在这一章中,我们将深入探讨PIDE指令的基本概念,包括它的应用场景、基本功能以及如何在实际工作中使用这一指令集。
## 1.1 P
产品规划与设计:IPD阶段三,确保愿景与技术方案的无缝对接

参考资源链接:[IPD产品开发评审要素详解与模板](https://wenku.csdn.net/doc/644b7797fcc5391368e5ed70?spm=1055.2635.3001.10343)
# 1. 产品规划与设计的IPD阶段三概述
在产品开发的旅程中,集成产品开发
深度剖析iTek相机技术:揭秘其工作原理与应用场景
参考资源链接:[Vulcan-CL采集卡与国产线扫相机设置指南](https://wenku.csdn.net/doc/4d2ufe0152?spm=1055.2635.3001.10343)
# 1. iTek相机技术概述
随着技术的不断进步,iTek相机已经成为图像捕捉领域中的佼佼者。其突破性的技术不仅仅依赖于先进的硬件配置,还涵盖了一系列智能软件的应用,从而在专业摄影、视频制作以及消费电子产品中取得了广泛的应用和好评。
## 1.1 iTek相机的核心价值
iTek相机的核心价值体现在其创新性的设计理念与独特的用户体验上。这一理念贯穿于相机的每一个细节,从硬件的选材、制作工艺,到软件
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )