【代码质量提升】:宿舍管理系统代码重构的实用技巧
发布时间: 2025-01-10 19:22:14 阅读量: 4 订阅数: 4 

Python代码重构:提升代码质量的艺术

# 摘要
代码重构是软件开发过程中提高代码质量、可维护性和可扩展性的关键实践。本文探讨了代码重构的重要性、基本原则以及识别和处理代码坏味道的策略。文中详细说明了重构技术的应用,包括提取方法、变量以及移除中间人等技术,并探讨了避免重构陷阱的方法。同时,本文也介绍了重构工具的选择、使用和自动化测试的重要性,以及在持续集成环境下保证代码质量的实践。本文还着重分析了面向对象设计原则在重构中的应用,如SOLID原则和设计模式,并探讨了代码解耦与高内聚的技术。通过宿舍管理系统的重构实践案例分析,本文进一步阐述了重构的挑战和解决方案。最后,本文提出了重构后代码的维护策略和长期优化计划。
# 关键字
代码重构;坏味道识别;SOLID原则;自动化测试;持续集成;设计模式;代码维护
参考资源链接:[C++实现的宿舍管理系统:数据结构课程设计](https://wenku.csdn.net/doc/7sju0mcnz8?spm=1055.2635.3001.10343)
# 1. 代码重构的重要性与基本原则
## 1.1 重构的必要性
在快速迭代的软件开发过程中,代码库往往会随着时间逐渐变得混乱和难以维护。重构就是对软件内部结构进行调整而不改变其外部行为的过程。它能够帮助我们改进设计、提升性能、增强可读性和可维护性,为软件的长期健康打下坚实基础。
## 1.2 重构的基本原则
重构代码应该遵循一些核心原则,比如不要在代码库中引入新的功能,保持外部行为不变;优先处理最迫切的问题,合理安排重构计划;并且持续集成、测试,确保每一次重构都具备可逆性。这些原则为代码重构提供方向性和安全性。
代码重构不仅限于清理旧代码,它更是一种确保软件质量的持续过程。以下是一个代码重构的基本步骤范例:
```java
// 原始代码
public double calculateDiscountedPrice(double originalPrice, double discountRate) {
double discountAmount = originalPrice * discountRate;
return originalPrice - discountAmount;
}
// 重构后代码
public double calculateDiscountedPrice(double originalPrice, double discountRate) {
double discountAmount = calculateDiscountAmount(originalPrice, discountRate);
return applyDiscount(originalPrice, discountAmount);
}
private double calculateDiscountAmount(double originalPrice, double discountRate) {
return originalPrice * discountRate;
}
private double applyDiscount(double originalPrice, double discountAmount) {
return originalPrice - discountAmount;
}
```
通过拆分成小方法,代码变得更清晰、易读,未来维护也更方便。这就是重构的精髓所在。
# 2. 识别和处理代码中的坏味道
软件开发是一个不断变化和演进的过程,随着项目的持续发展,代码库也往往会积累各种问题,这些问题在软件工程中通常被称为“坏味道”。坏味道可能表现为代码重复、过度复杂的设计、僵化的代码结构等,它们降低了代码的可读性、可维护性和可扩展性。在本章节中,我们将深入探讨如何识别和处理代码中的坏味道,并介绍一些实用的重构技术。
## 2.1 代码坏味道的识别
识别代码中的坏味道是重构的第一步,也是保障软件质量的关键步骤。下面我们将介绍两种常见的代码坏味道:重复代码和过长的函数与过大的类。
### 2.1.1 重复代码的识别与处理
重复代码是代码坏味道中最常见的一种。它不仅增加了维护的难度,还会导致修改时产生不一致,增加出错的风险。识别重复代码,我们通常可以遵循以下步骤:
- **代码审查**:定期对代码库进行审查,以识别相似或相同的代码块。
- **代码比较工具**:使用如Beyond Compare、WinMerge等工具对比不同文件中的代码,快速找出重复部分。
- **静态代码分析工具**:如SonarQube、ESLint等可以自动检测代码中的重复代码。
处理重复代码的方式很多,其中最常用的是“提取方法”(Extract Method)技术,即将重复的代码片段封装到独立的方法中。这样,当需要修改这些代码时,只需要修改一处地方。以下是一个简单的代码示例:
```java
// 原始代码
if (isSpecialOrder(order)) {
applySpecialDiscount(order);
sendSpecialOrderEmail(order);
}
if (isSpecialOrder(anotherOrder)) {
applySpecialDiscount(anotherOrder);
sendSpecialOrderEmail(anotherOrder);
}
// 使用提取方法重构
void processSpecialOrder(Order order) {
if (isSpecialOrder(order)) {
applySpecialDiscount(order);
sendSpecialOrderEmail(order);
}
}
```
在这个例子中,我们将处理特殊订单的逻辑提取到了一个新的方法`processSpecialOrder`中,这样,原本重复的代码块现在只需要调用这个方法即可。
### 2.1.2 过长的函数与过大的类
过长的函数和过大的类会导致代码难以理解,增加测试和维护的复杂度。函数应该保持短小,一个函数只做一件事情。类的大小也应该适度,职责单一。
识别过长的函数和过大的类的方法包括:
- **长度度量**:在很多编码规范中,建议函数长度不要超过20行。如果一个函数超过这个长度,应该考虑拆分。
- **抽象度检查**:如果一个函数内部做了太多的操作,特别是不同的操作,那么它可能需要被拆分成更小的函数。
- **类的职责分析**:一个类如果涉及到多个领域的问题,那么它可能就是过大。可以利用IDE提供的工具进行类的职责分析。
处理方法包括:
- **提取方法**:将一个函数拆分成几个小函数,每个小函数都有明确的职责。
- **拆分类**:如果一个类承担了过多的职责,应将其拆分成多个协作的类。
例如,假设有一个庞大的Order类,我们可以将其拆分成几个类,如OrderItem、OrderProcessor等,每个类负责订单处理的一个方面。
## 2.2 重构技术的应用
在识别和处理了代码中的坏味道后,我们需要应用一些重构技术来优化代码结构和设计。
### 2.2.1 提取方法和变量
提取方法和变量是重构中最常见的操作之一,它有助于改善代码的可读性和可维护性。
- **提取方法**:将一段代码封装到一个单独的方法中,并给这个方法一个意义明确的名字。如之前提到的提取处理特殊订单的代码。
- **提取变量**:将复杂的表达式或重复的值提取成一个变量,以便于理解和修改。
```java
// 原始代码
double price = quantity * itemPrice;
if (quantity > 100) {
price *= 0.95;
}
// 提取变量后的代码
double basePrice = quantity * itemPrice;
double discountFactor = quantity > 100 ? 0.95 : 1.0;
double price = basePrice * discountFactor;
```
在上面的Java代码中,将计算价格的部分分解成了basePrice和discountFactor两个变量,使计算过程更清晰。
### 2.2.2 移除中间人和引入解释变量
有时候,对象通过中间对象调用一系列方法,会导致很多层的间接调用,这被称为中间人模式。我们可以使用“移除中间人”(Remove Middle Man)的重构技术简化代码:
```java
// 原始代码
class Customer {
public void getAccount() {
return repository.findAccount();
}
}
// 移除中间人后的代码
class Customer {
public Account getAccount() {
return repository.findAccount();
}
}
```
在这个例子中,Customer类直接调用repository来获取account,减少了调用层级。此外,在复杂表达式中引入解释变量可以提高代码的可读性:
```java
// 原始代码
if ((platform.toLowerCase().startsWith("mac") && browser.toLowerCase().startsWith("safari")) || (platform.toLowerCase().startsWith("ipad"))) {
// do something
}
// 引入解释变量后的代码
boolean isMacSafari = platform.toLowerCase().startsWith("mac") && browser.toLowerCase().startsWith("safari");
boolean isiPad = platform.toLowerCase().startsWith("ipad");
if (isMacSafari || isiPad) {
// do something
}
```
通过定义`isMacSafari`和`isiPad`这两个解释变量,代码的意图变得更加清晰。
## 2.3 避免重构的陷阱
在重构过程中,我们必须避免一些常见的重构陷阱,这些陷阱可能会导致重构失败或者引入新的问题。
### 2.3.1 常见重构误区
一个常见的误区是认为重构只是简单的重写代码,而没有遵循重构的基本原则。重构并不意味着要重写整个系统,而是要通过一系列的小步修改来逐步改善代码。此外,不进行测试而进行重构也是一个常见的错误。重构必须在有良好测试覆盖的前提下进行,这样才能确保引入的改变不会破坏现有的功能。
### 2.3.2 如何安全地重构
安全地进行重构的关键是自动化测试。自动化测试可以在重构过程中快速发现问题,并确保代码在重构前后保持同样的行为。在重构前,确保有一个好的测试框架,并编写足够的单元测试和集成测试是非常重要的。
- **单元测试**:确保每个类、每个方法的行

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了宿舍管理系统的设计与实现,涵盖了从数据结构优化到用户体验设计、数据库连接、性能优化、代码质量提升等多个方面。专栏文章由经验丰富的专家撰写,提供实用技巧和深入见解,帮助开发者打造高效、易用且可维护的宿舍管理系统。通过学习这些文章,读者可以掌握面向对象设计、数据结构应用、数据库操作、性能提升、代码重构、用户界面设计、数据完整性、系统测试、多线程编程、数据持久化、代码可维护性、版本控制、模块化构建、单元测试、集成测试和持续集成等方面的知识和技能,全面提升宿舍管理系统开发水平。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
《建筑术语标准》实施指南:一步到位地掌握实践操作要点

# 摘要
《建筑术语标准》为建筑行业提供了一套明确且统一的术语框架,旨在确保沟通的准确性和设计施工的质量。本文概述了标准的背景和核心内容,详细解析了关键建筑术语,并探讨了其在建筑设计、项目管理和施工验收中的具体应用。同时,分析了实施标准过程中出现
【orCAD精确高效】:BOM导出错误减少与准确度提升技巧

# 摘要
本文系统地介绍了orCAD BOM导出的过程及其挑战,并探讨了如何精确控制BOM数据,以提高导出的准确度和效率。文章首先概述了BOM导出的基本流程和重要性,随后分析了在数据导出中常见的错误类型,如数据不一致性和格式兼容性问题,并提供了有效的数据精确度基础设置策略。接着,本文探讨了提高BOM导出效率的实践技巧,包括优化orCAD项目设置和实现自动
AdvanTrol-Pro性能优化必修课:新手也能轻松驾驭的首次调优手册
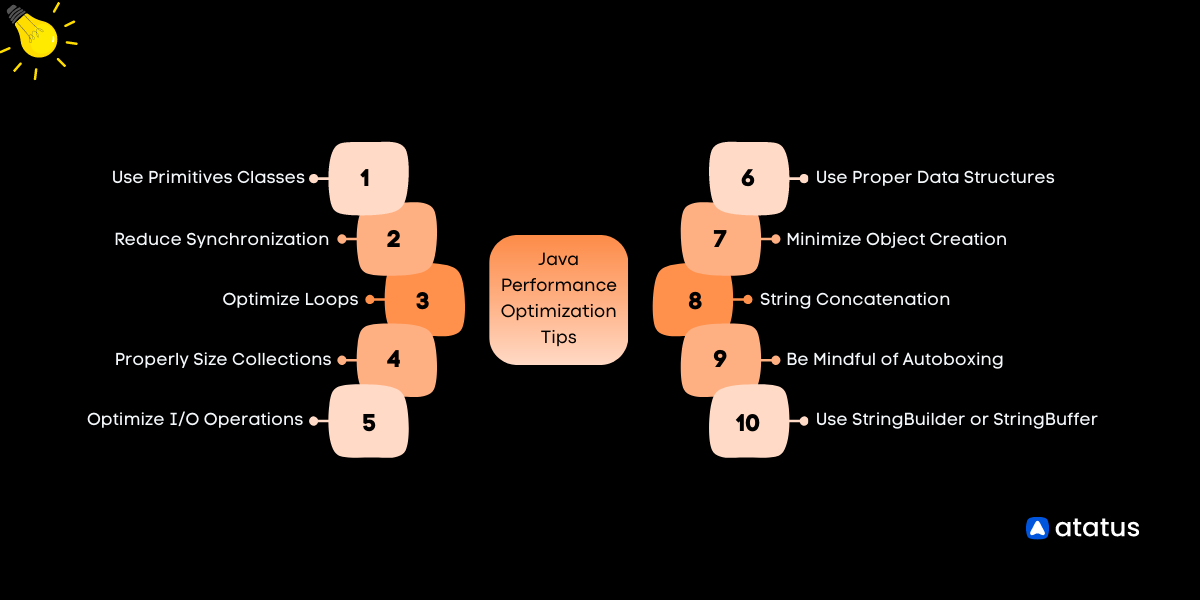
# 摘要
本文全面探讨了AdvanTrol-Pro在性能监控和调优方面的基础和高级应用。文章首先介绍了AdvanTrol-Pro的基础知识和性能优化的概要,随后深入讨论了性能监控工具的使用和配置,包括实时数据的分析和自动化监控策略。在系统调优实践中,本文详细阐述了内存、CPU、磁盘I/O和网络性能的优化技巧,并通过
【源码解构】:深入r3epthook架构设计,专家级理解

# 摘要
r3epthook是一个复杂的架构,设计用于高效的数据处理和系统集成。本文从架构设计、核心组件、高级功能、实战应用以及源码分析等多个维度深入解析了r3epthook的架构和功能。文章详细介绍了基础组件、模块化设计的优势、数据流处理方法,以及如何通过高级数据处理
【并发处理】:电子图书馆网站响应速度提升的5大秘诀

# 摘要
并发处理在现代软件系统中至关重要,它通过允许多个计算任务同时进行来提高系统性能。本文从理论基础开始,详细介绍了并发控制机制的实现,包括多线程编程基础、高级并发编程技术和无阻塞I/O与异步编程模型。随后,将理论应用于实践,探讨了电子图书馆系统中并发处理的优化策略,包括网站架构
【Psycopg2 Binary安全指南】:保护你的数据库免受攻击
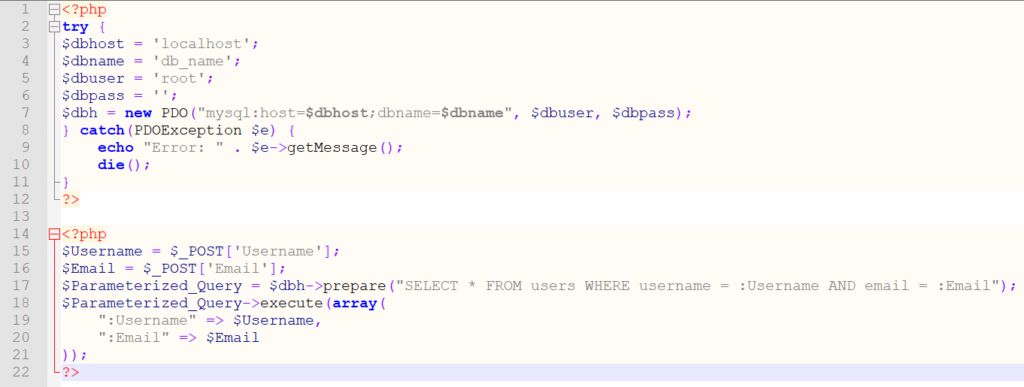
# 摘要
Psycopg2 Binary作为PostgreSQL数据库的Python适配器,其安全机制对数据库管理至关重要。本文旨在介绍Psycopg2 Binary的基本安全特性及其实施细节,着重分析其加密机制和认证机制。通过探讨加密基础,包括对称与非对称加密、哈希函数及数字签名,以及Psycopg2 Binary的加密实现,如连接和数据传输加密,本
I2C总线应用指南:LY-51S V2.3开发板设备互联与数据交换
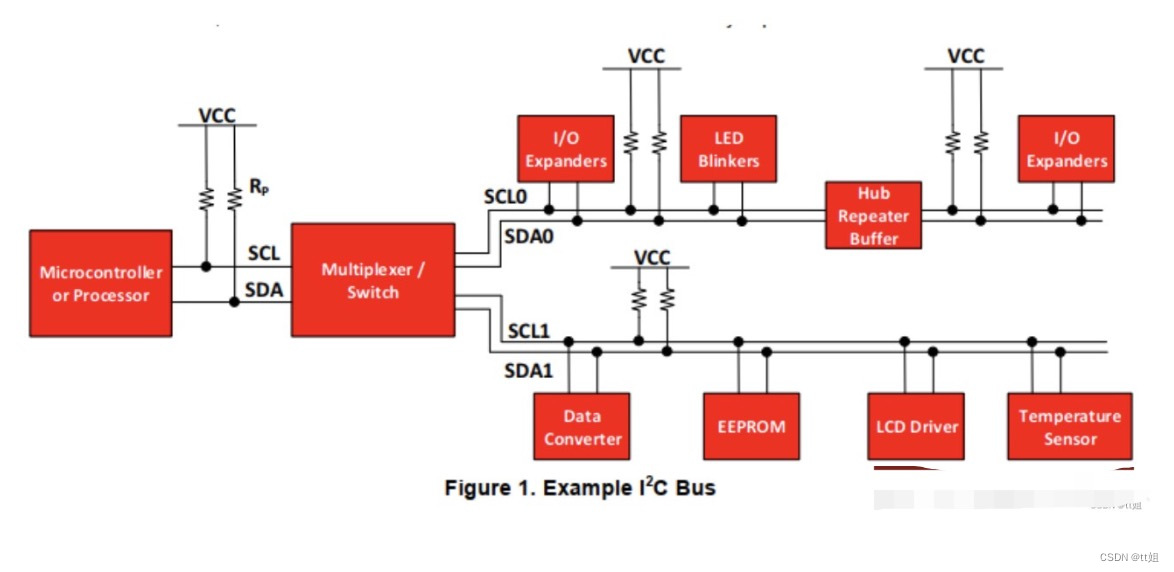
# 摘要
本文综合论述了I2C总线技术及其在LY-51S V2.3开发板上的实现细节。首先概述了I2C总线技术的基础知识,并针对LY-51S V2.3开发板介绍了硬件连接和软件配置的具体方法。接着,深入探讨了I2C总线的数据交换原理,包括通信协议、错误检测机制和设备编程实践。在讨论了I2C设备初始化与配置后,文章聚焦于嵌入式系统中I2C的高级应用技巧。最后,以LY-51S V2.3项目案例分析为结,展示了I2C在实际应用中的硬件连接、软件配置和
热管理专家:【M.2接口的热管理】在V1.0规范中的策略

# 摘要
M.2接口作为高速数据传输的硬件标准,在个人电脑和移动设备中扮演着关键角色。随着数据处理需求的不断增长,热管理成为确保M.2接口稳定运行的关键因素。本文首先概述了M.2接口的特点及其热管理的必要性,随后详细分析了M.2接口V1.0规范中的热管理策略,包括热设计原则和技术指标,以及实际应用中遇到的挑战和优化经验。进一步探讨了散热解决方案,
数据库性能监控工具精选:如何选择最适合的监控工具
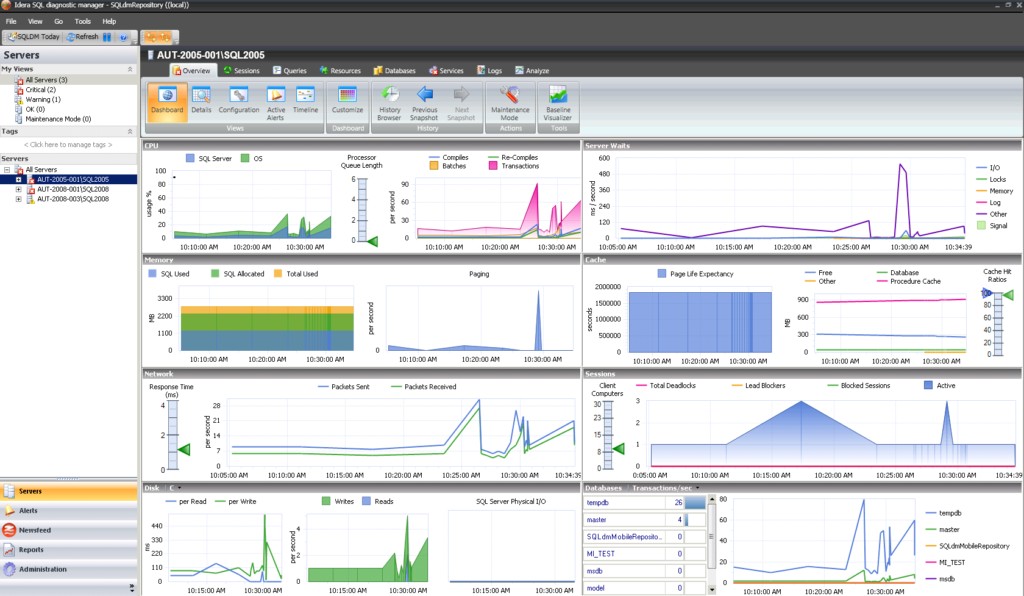
# 摘要
数据库性能监控是确保企业数据库稳定运行的关键环节。本文深入分析了数据库性能监控的重要性与需求,探讨了不同监控工具的基本理论,包括关键性能指标、工具分类、功能对比以及选择标准。通过对开源和商业监控工具案例的实践研究,本文展示了如何在不同环境中部署和应用这些工具。此外,文章还介绍了数据库性能监控工具的高级应用,如自定义监
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )