常用Python第三方库介绍
发布时间: 2024-01-18 00:31:50 阅读量: 51 订阅数: 40 
# 1. 简介
## 1.1 Python第三方库的作用
Python作为一种广泛应用于各个领域的编程语言,拥有丰富的标准库,但是在某些特定领域的功能方面仍然存在不足。为了满足这些特定需求,开发者们创造了大量的第三方库,通过引入这些库,我们可以方便地使用复杂的功能,提高代码开发效率。
## 1.2 为什么使用常用的Python第三方库
使用常用的Python第三方库有以下几个优势:
- **开发效率高**:常用的第三方库提供了丰富的功能和成熟的解决方案,可以简化代码编写过程,显著提高开发效率。
- **广泛应用**:常用的第三方库经过长时间的验证和使用,已经在各个领域得到广泛应用,具备了较高的稳定性和可靠性。
- **开源社区活跃**:常用的第三方库通常有庞大的开源社区支持,可以获取到大量的开发资源、文档和教程,方便学习和解决问题。
- **生态系统完善**:常用的第三方库通常会与其他相关库相互配合,形成完善的生态系统,可以更好地满足开发需求。
在接下来的章节中,我们将介绍一些常用的Python第三方库,包括数据处理库、Web开发库、数据库库、机器学习库和自然语言处理库。这些库在各自的领域具有重要的地位和应用价值。
# 2. 数据处理库
数据处理是数据分析中至关重要的一步,Python提供了许多强大的第三方库来帮助我们进行数据处理。下面介绍三个常用的数据处理库。
### 2.1 Numpy
Numpy是Python科学计算的核心库之一,它提供了高性能的多维数组对象和与数组相关的操作函数。Numpy的主要特点包括:
- 强大的多维数组对象:Numpy的核心是ndarray对象,它是高效存储大规模同类型元素的容器,可以进行快速的数值计算。
- 丰富的数组操作函数:Numpy提供了大量的数组操作函数,如数组的创建、变形、切片、拼接等,便于进行各种数据处理操作。
- 快速的数值计算:Numpy通过C语言编写底层实现,能够高效地处理大规模数据和复杂数值计算。
下面是一个简单的使用Numpy进行数组操作的示例代码:
```python
import numpy as np
# 创建数组
arr = np.array([1, 2, 3, 4, 5])
# 对数组进行变形
arr_reshape = arr.reshape(5, 1)
# 对数组进行切片
arr_slice = arr[1:3]
# 对数组进行拼接
arr_concat = np.concatenate((arr, arr_slice))
# 打印结果
print("原始数组:", arr)
print("变形后的数组:", arr_reshape)
print("切片后的数组:", arr_slice)
print("拼接后的数组:", arr_concat)
```
代码总结:上面的代码先创建一个一维数组,然后使用reshape对数组进行变形,再使用切片操作获取部分元素,最后使用concatenate进行数组拼接。最终将结果打印出来。
结果说明:运行上面的代码,会得到以下输出结果:
```
原始数组:[1 2 3 4 5]
变形后的数组:
[[1]
[2]
[3]
[4]
[5]]
切片后的数组:[2 3]
拼接后的数组:[1 2 3 4 5 2 3]
```
### 2.2 Pandas
Pandas是一个强大的数据处理库,提供了灵活且高效的数据结构和数据分析工具。Pandas的主要特点包括:
- 数据结构:Pandas提供了两种主要的数据结构,Series和DataFrame,能够方便地处理结构化和时间序列数据。
- 数据清洗:Pandas提供了一组丰富的函数和方法,用于数据清洗和处理缺失值、重复值等常见数据问题。
- 数据分析:Pandas提供了统计分析、聚合计算、数据透视等功能,能够快速进行数据分析和探索。
下面是一个使用Pandas进行数据处理的示例代码:
```python
import pandas as pd
# 创建DataFrame
data = {'Name': ['Tom', 'John', 'Mike'],
'Age': [25, 30, 35],
'Country': ['USA', 'UK', 'Canada']}
df = pd.DataFrame(data)
# 查看DataFrame的基本信息
print("DataFrame的形状:", df.shape)
print("DataFrame的列名:", df.columns)
print("DataFrame的前两行数据:")
print(df.head(2))
```
代码总结:上面的代码创建了一个包含姓名、年龄和国家信息的DataFrame,并使用shape属性查看DataFrame的形状,使用columns属性查看列名,使用head方法查看前两行数据。
结果说明:运行上面的代码,会得到以下输出结果:
```
DataFrame的形状: (3, 3)
DataFrame的列名: ['Name' 'Age' 'Country']
DataFrame的前两行数据:
Name Age Country
0 Tom 25 USA
1 John 30 UK
```
### 2.3 Matplotlib
Matplotlib是一个专业的绘图库,可用于生成高质量的二维图表、图形和可视化展示。Matplotlib的主要特点包括:
- 丰富的绘图功能:Matplotlib支持多种绘图类型,包括线图、散点图、柱状图、饼图等,适用于各种数据展示需求。
- 定制化程度高:Matplotlib提供了丰富的选项和功能,使用户能够完全控制图表的外观和样式,满足个性化的需求。
- 支持交互式绘图:Matplotlib可以与Jupyter Notebook等交互式环境结合使用,便于数据分析和交互式可视化。
下面是一个使用Matplotlib绘制折线图的示例代码:
```python
import matplotlib.pyplot as plt
# 数据
x = [1, 2, 3, 4, 5]
y = [1, 4, 9, 16, 25]
# 绘制折线图
plt.plot(x, y)
# 设置标题和坐标轴标签
plt.title("Square Numbers")
plt.xlabel("Value")
plt.ylabel("Square")
# 显示图表
plt.show()
```
代码总结:上面的代码创建了x和y的数据,然后使用plot方法绘制折线图,使用title、xlabel和ylabel方法设置标题和坐标轴标签,最后使用show方法显示图表。
结果说明:运行上面的代码,会弹出一个新窗口显示绘制的折线图,x轴为1到5,y轴为1到25。
# 3. Web开发库
在现代的Web开发中,使用Python第三方库可以大大简化开发人员的工作流程。以下是几个常用的Python Web开发库:
#### 3.1 Django
Django是一个简洁高效的Web开发框架,它提供了许多强大的功能和工具,使得开发一个数据库驱动的Web应用变得非常简单。下面是Django的几个特点:
- Django采用了MVC(Model-View-Controller)的架构模式,分离了数据层、业务逻辑层和视图层,使得代码更加清晰、易于维护。
- Django自带一个强大的ORM(Object Relational Mapping)工具,可以通过Python代码操作数据库,无需手动编写SQL语句。
- Django提供了内置的用户认证系统、表单验证、国际化支持等功能,可以大大加快Web应用的开发速度。
- Django拥有丰富而完善的社区支持和文档,有很多第三方插件可以扩展其功能。
下面是一个简单的Django应用示例,展示了如何创建一个简单的Web应用界面:
```python
# app/views.py
from django.http import HttpResponse
def hello(request):
return HttpResponse("Hello, Django!")
# app/urls.py
from django.urls import path
from . import views
urlpatterns = [
path('hello/', views.hello, name='hello'),
]
# project/urls.py
from django.contrib import admin
from django.urls import include, path
urlpatterns = [
path('admin/', admin.site.urls),
path('app/', include('app.urls')),
]
```
#### 3.2 Flask
Flask是一个轻量级的Web开发框架,具有灵活简单的设计理念。下面是Flask的几个特点:
- Flask采用了微内核的设计思想,核心库非常简洁,但功能强大。它提供了HTTP请求的处理、路由和模板渲染等基本功能,其他高级功能可以通过插件进行扩展。
- Flask具有非常友好的URL规则,可以根据不同的URL路径来处理不同的请求,使得开发RESTful API变得非常方便。
- Flask支持各种数据库,可以灵活选择使用SQLAlchemy、MongoDB等做为数据库引擎。
下面是一个简单的Flask应用示例:
```python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'Hello, Flask!'
if __name__ == '__main__':
app.run()
```
#### 3.3 Requests
Requests是一个简洁而优雅的HTTP库,用于向网络发送HTTP请求。使用Requests,我们可以很方便地发送HTTP请求、设置请求头、处理响应等操作。
下面是一个使用Requests发送GET请求的示例:
```python
import requests
url = 'https://api.github.com/users/octocat'
response = requests.get(url)
if response.status_code == 200:
user_data = response.json()
print(f"Username: {user_data['login']}")
print(f"Followers: {user_data['followers']}")
print(f"Repositories: {user_data['public_repos']}")
else:
print("Failed to fetch user data.")
```
以上是一些常用的Python Web开发库,它们各有特点,可根据具体项目需求选择使用。无论是开发大型的Web应用还是小型的API服务,这些库都能帮助开发人员提高开发效率,减少重复劳动。
# 4. 数据库库
在Python中,使用第三方库可以轻松地连接和操作各种数据库。以下是一些常用的Python第三方库,它们为数据库操作提供了非常便利的功能。
#### 4.1 SQLAlchemy
**简介:** SQLAlchemy 是一个 Python SQL 工具包和对象关系映射器,它允许 Python 开发人员在 Python 应用程序中以快速、高效和高度可扩展的方式使用 SQL 数据库。
**特点:**
- 提供了一种灵活而强大的方式来访问和操作多种数据库。
- 支持多种数据库后端,包括 MySQL、PostgreSQL、SQLite 等。
- 使用 ORM(对象关系映射)来映射数据库表到 Python 类,让数据库操作更加面向对象。
**应用场景:** 适用于需要在 Python 应用程序中进行复杂数据库操作的场景,尤其是需要支持多种不同类型的数据库后端时。
**基本示例:**
```python
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# 创建引擎
engine = create_engine('sqlite:///example.db', echo=True)
# 创建基类
Base = declarative_base()
# 定义模型类
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
age = Column(Integer)
# 创建所有表
Base.metadata.create_all(engine)
# 创建会话
Session = sessionmaker(bind=engine)
session = Session()
# 插入数据
new_user = User(name='Alice', age=25)
session.add(new_user)
session.commit()
# 查询数据
user = session.query(User).filter_by(name='Alice').first()
print(user.name, user.age)
# 关闭会话
session.close()
```
**代码总结:** 上述示例演示了如何使用 SQLAlchemy 创建表、插入数据、查询数据,并进行会话管理。
**结果说明:** 通过 SQLAlchemy,我们可以方便地在 Python 中操作数据库,实现了数据存储与业务逻辑的分离,使得代码更加清晰和易维护。
#### 4.2 Psycopg2
**简介:** Psycopg2 是 PostgreSQL 数据库的 Python 数据库适配器,提供了对 PostgreSQL 数据库的底层操作接口和功能。
**特点:**
- 提供了对 PostgreSQL 数据库连接和操作的底层 API。
- 支持执行 SQL 命令、数据查询和事务管理等功能。
- 提供了对 PostgreSQL 数据库特性(如数组、JSON 数据类型)的完整支持。
**应用场景:** 适用于需要在 Python 应用程序中直接操作 PostgreSQL 数据库的场景,尤其是对 PostgreSQL 特性有较高要求时。
**基本示例:**
```python
import psycopg2
# 连接到 PostgreSQL 数据库
conn = psycopg2.connect(
dbname="mydb",
user="user",
password="password",
host="localhost"
)
# 创建游标
cur = conn.cursor()
# 执行 SQL 查询
cur.execute("SELECT * FROM mytable")
rows = cur.fetchall()
for row in rows:
print(row)
# 关闭游标和连接
cur.close()
conn.close()
```
**代码总结:** 上述示例演示了如何使用 Psycopg2 连接到 PostgreSQL 数据库,并执行 SQL 查询以获取数据。
**结果说明:** Psycopg2 提供了直接而强大的方式来操作 PostgreSQL 数据库,使得 Python 应用程序能够轻松地与 PostgreSQL 数据库进行交互。
#### 4.3 pymongo
**简介:** pymongo 是 MongoDB 的 Python 驱动程序,提供了对 MongoDB 数据库的操作接口和功能。
**特点:**
- 使用 BSON 格式来表示数据,方便与 MongoDB 数据库进行交互。
- 提供了查询、插入、更新、删除等丰富的操作方法。
- 支持对 MongoDB 的集合、索引、聚合等进行管理。
**应用场景:** 适用于需要在 Python 应用程序中对 MongoDB 数据库进行灵活操作的场景,尤其是在数据存储的灵活性和伸缩性有较高要求时。
**基本示例:**
```python
import pymongo
# 连接到 MongoDB
client = pymongo.MongoClient("mongodb://localhost:27017/")
# 创建数据库和集合
db = client["mydatabase"]
collection = db["mycollection"]
# 插入文档
data = {"name": "Alice", "age": 25}
collection.insert_one(data)
# 查询文档
query = {"name": "Alice"}
result = collection.find(query)
for doc in result:
print(doc)
# 关闭连接
client.close()
```
**代码总结:** 上述示例演示了如何使用 pymongo 连接到 MongoDB 数据库,插入文档并进行查询操作。
**结果说明:** pymongo 提供了直观且灵活的方式来操作 MongoDB 数据库,使得 Python 应用程序能够充分利用 MongoDB 的特性和功能。
# 5. 机器学习库
在Python中,机器学习领域有许多强大的第三方库,使得开发人员能够轻松构建和训练机器学习模型。以下是几个常用的Python机器学习库:
#### 5.1 TensorFlow
TensorFlow是一个由Google开发的开源机器学习框架,它提供了丰富的工具和资源,用于构建和训练各种机器学习模型,包括神经网络和深度学习模型。TensorFlow具有良好的灵活性和扩展性,可适用于各种复杂的机器学习任务。
**特点:**
- 强大的数值计算能力,支持大规模的机器学习任务
- 高度灵活的架构,可用于构建各种类型的模型
- 支持分布式计算,可用于大规模并行训练
**应用场景:**
- 图像识别
- 自然语言处理
- 语音识别
- 推荐系统
**示例:**
```python
import tensorflow as tf
# 创建一个简单的神经网络模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, input_shape=(784,), activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5)
```
#### 5.2 Scikit-learn
Scikit-learn是一个简单而高效的机器学习库,它构建在NumPy、SciPy和matplotlib之上,提供了大量的机器学习算法和工具,涵盖了从数据预处理到模型评估的全套流程。
**特点:**
- 简单易用,适合初学者和专家
- 支持多种常见的监督学习和非监督学习算法
- 提供丰富的数据预处理和特征工程工具
**应用场景:**
- 分类
- 回归
- 聚类
- 降维
**示例:**
```python
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
X, y = load_iris(return_X_y=True)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建模型并训练
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 预测并评估模型性能
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
```
#### 5.3 Keras
Keras是一个高级神经网络API,它建立在TensorFlow、Theano和CNTK之上,提供了简单易用的接口,用于快速构建和训练神经网络模型。
**特点:**
- 简单易用,支持快速建模和迭代
- 支持多种常见的神经网络层和模型
- 可以无缝与TensorFlow等后端框架集成
**应用场景:**
- 图像分类
- 文本生成
- 序列建模
- 强化学习
**示例:**
```python
import keras
from keras.models import Sequential
from keras.layers import Dense
# 创建一个简单的多层感知器模型
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(data, labels, epochs=10, batch_size=32)
```
以上是几个常用的Python机器学习库,它们为开发人员提供了丰富的工具和资源,使得机器学习模型的构建和训练变得更加高效和便捷。
# 6. 自然语言处理库
自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要分支,涉及将计算机处理和理解人类语言的技术。Python拥有许多强大的第三方库,可以帮助我们在自然语言处理任务中进行文本预处理、特征提取、实体识别、情感分析等操作。下面是几个常用的Python自然语言处理库。
## 6.1 NLTK
[NLTK](https://www.nltk.org/)(Natural Language Toolkit)是Python自然语言处理的首选库之一。它提供了一系列用于处理文本和语言数据的工具和资源。NLTK涵盖了众多NLP任务,如分词、词性标注、命名实体识别、语言模型等。同时,NLTK还包含了大量语料库和预训练模型,方便用户进行实践和学习。
```python
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
text = "Hello, how are you? I am fine."
tokens = word_tokenize(text)
print(tokens)
```
代码解析:
- 首先,导入nltk库,并下载所需的资源。
- 然后,从nltk.tokenize模块中导入word_tokenize函数,用于将文本分词。
- 接下来,定义一个文本字符串。
- 最后,调用word_tokenize函数对文本进行分词,将结果保存在tokens变量中,并打印结果。
输出结果:
```
['Hello', ',', 'how', 'are', 'you', '?', 'I', 'am', 'fine', '.']
```
上述代码演示了如何使用NLTK进行分词操作。通过调用word_tokenize函数,将输入的文本字符串分割成单词和标点符号的列表。
## 6.2 SpaCy
[SpaCy](https://spacy.io/)是一个用于自然语言处理的现代Python库。它的设计目标是提供高效且快速的处理大规模文本数据的能力。SpaCy支持多种NLP任务,如分词、句法分析、命名实体识别、依存关系分析等。该库还提供了训练自定义NLP模型的功能,方便用户根据特定需求进行定制化开发。
```python
import spacy
nlp = spacy.load("en_core_web_sm")
text = "Apple is looking at buying U.K. startup for $1 billion."
doc = nlp(text)
for token in doc:
print(token.text, token.pos_, token.dep_)
```
代码解析:
- 首先,导入spacy库,并加载英文语言模型。
- 然后,定义一个文本字符串。
- 接下来,调用nlp函数,将文本转化为Doc对象。
- 最后,使用for循环遍历Doc对象中的每个Token,打印Token的文本、词性和依存关系。
输出结果:
```
Apple PROPN nsubj
is AUX aux
looking VERB ROOT
at ADP prep
buying VERB pcomp
U.K. PROPN compound
startup NOUN dobj
for ADP prep
$ SYM quantmod
1 NUM compound
billion NUM pobj
. PUNCT punct
```
上述代码演示了如何使用SpaCy进行分词、词性标注和依存关系分析。将输入的文本经过SpaCy的处理,可以得到每个单词的词性和依存关系。
## 6.3 Gensim
[Gensim](https://radimrehurek.com/gensim/)是一个用于主题建模、文档相似度计算和文本聚类等任务的Python库。它支持处理大规模的文本语料库,提供了高效的算法和工具。Gensim中的一个重要概念是词向量,它可以将词语表示为数值向量,有助于词义的理解和计算。
```python
from gensim.models import Word2Vec
sentences = [['apple', 'is', 'fruit'], ['banana', 'is', 'fruit'], ['apple', 'is', 'red']]
model = Word2Vec(sentences, min_count=1)
print(model.wv['is'])
```
代码解析:
- 首先,从gensim.models模块中导入Word2Vec类。
- 然后,定义一个包含多个文本句子的列表,用于训练Word2Vec模型。
- 接下来,创建一个Word2Vec对象,传入句子列表和最小词频的参数。
- 最后,通过访问模型的wv属性,可以获取特定词语的词向量。
输出结果:
```
[ 8.6341610e-04 -8.0916524e-03 -1.4243094e-03 6.7891282e-06
4.0278902e-03 -4.8660454e-03 -3.4760938e-03 2.6262677e-03
...
-3.7165231e-03 -4.6773955e-03 2.4936618e-03 -3.4154722e-03]
```
上述代码演示了如何使用Gensim的Word2Vec模型训练词向量。将输入的句子列表传入Word2Vec类的构造函数中,并通过访问模型的wv属性,可以获取特定词语的词向量。
以上是几个常用的Python自然语言处理库的简介和基本使用示例。这些库提供了一系列强大的工具和算法,可以大大简化自然语言处理任务的开发和实施过程。具体选择哪个库取决于具体的需求和项目要求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
零基础Python快速入门教程是一份综合全面的Python学习指南,为初学者提供了从基本语法到高级应用的全方位教学。该专栏包含众多内容,其中包括Python基础语法与变量、条件语句与循环结构、函数与模块的使用等基础知识的讲解。同时,还介绍了文件操作与异常处理、面向对象编程基础、正则表达式等高级主题。专栏还涵盖了常用的第三方库介绍、数据处理与分析、文本处理与分析、GUI编程、Web开发、数据可视化与图表绘制等实际应用。此外,还探讨了并发编程、人工智能与机器学习、自然语言处理、物联网与嵌入式开发、图像处理与计算机视觉等领域中Python的应用。无论是想快速入门Python的初学者,还是希望扩展应用领域的开发者,本专栏都能为您提供丰富的知识和实践经验。通过深入易懂的讲解和实例代码,让您迅速掌握Python,并能将其应用于您的项目中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
BTN7971驱动芯片使用指南:快速从新手变专家

# 摘要
本文详细介绍了BTN7971驱动芯片的多方面知识,涵盖了其工作原理、电气特性、硬件接口以及软件环境配置。通过对理论基础的分析,本文进一步深入到BTN7971的实际编程实践,包括控制命令的应用、电机控制案例以及故障诊断。文章还探讨了BTN7971的高级应用,如系统集成优化和工业应用案例,以及对其未来发展趋势的展望。最后,文章结合实战项目,提供了项目实施的全流程分析,帮助读者更好地理解和应用BTN7971驱动芯片。
# 关键字
BTN797
PSpice电路设计全攻略:原理图绘制、参数优化,一步到位

# 摘要
PSpice是广泛应用于电子电路设计与仿真领域的软件工具,本文从基础概念出发,详细介绍了PSpice在电路设计中的应用。首先,探讨了PSpice原理图的绘制技巧,包括基础工具操作、元件库管理、元件放置、电路连接以及复杂电路图的绘制管理。随后,文章深入讲解了参数优化、仿真分析的类型和工具,以及仿真结果评估和改进的方法。此外,本文还涉及了PSpice在
ASR3603性能测试指南:datasheet V8助你成为评估大师

# 摘要
本论文全面介绍了ASR3603性能测试的理论与实践操作。首先,阐述了性能测试的基础知识,包括其定义、目的和关键指标,以及数据表的解读和应用。接着,详细描述了性能测试的准备、执行和结果分析过程,重点讲解了如何制定测试计划、设计测试场景、进行负载测试以及解读测试数据。第三章进一步
【增强设备控制力】:I_O端口扩展技巧,单片机高手必修课!

# 摘要
随着技术的不断进步,I/O端口的扩展和优化对于满足多样化的系统需求变得至关重要。本文深入探讨了I/O端口的基础理论、扩展技术、电气保护与隔离、实际应用,以及高级I/O端口扩展技巧和案例研究。文章特别强调了单片机I/O端口的工作原理和编程模型,探讨了硬件和软件方法来实现I/O端口的扩展。此外,文中分析了总线技术、多任务管理、和高级保护技术,并通过智能家居、工业自动化和车载电子系统的案例研究,展示了I
【个性化配置,机器更懂你】:安川机器人自定义参数设置详解

# 摘要
本文全面阐述了安川机器人自定义参数设置的重要性和方法。首先介绍了安川机器人的工作原理及其核心构成,并强调了参数设置对机器性能的影响。随后,本文详细探讨了自定义参数的逻辑,将其分为运动控制参数、传感器相关参数和安全与保护参数,并分析了它们的功能。接着,文章指出了参数设置前的必要准备工作,包括系统检查和参数备份与恢复策略。为了指导实践,提供了参数配置工具的使用方法及具体参数的配置与调试实例。此外,文章还探讨了自定义参
深度剖析四位全加器:计算机组成原理实验的不二法门

# 摘要
四位全加器作为数字电路设计的基础组件,在计算机组成原理和数字系统中有广泛应用。本文详细阐述了四位全加器的基本概念、逻辑设计方法以及实践应用,并进一步探讨了其在并行加法器设
【跨平台性能比拼】:极智AI与商汤OpenPPL在不同操作系统上的表现分析
# 摘要
本文针对跨平台性能分析的理论基础与实际应用进行了深入研究,特别关注了极智AI平台和商汤OpenPPL平台的技术剖析、性能比拼的实验设计与实施,以及案例分析与行业应用。通过对极智AI和商汤OpenPPL的核心架构、并发处理、算法优化策略等方面的分析,本文探讨了这些平台在不同操作系统下的表现,以及性能优化的实际案例。同时,文章还涉及了性能评估指标的选取和性能数据的分析方法,以及跨平台性能在
【深入RN8209D内部】:硬件架构与信号流程精通

# 摘要
RN8209D作为一种先进的硬件设备,在工业自动化、智能家居和医疗设备等多个领域具有重要应用。本文首先对RN8209D的硬件架构进行了详细的分析,包括其处理器架构、存
【数据保护指南】:在救砖过程中确保个人资料的安全备份
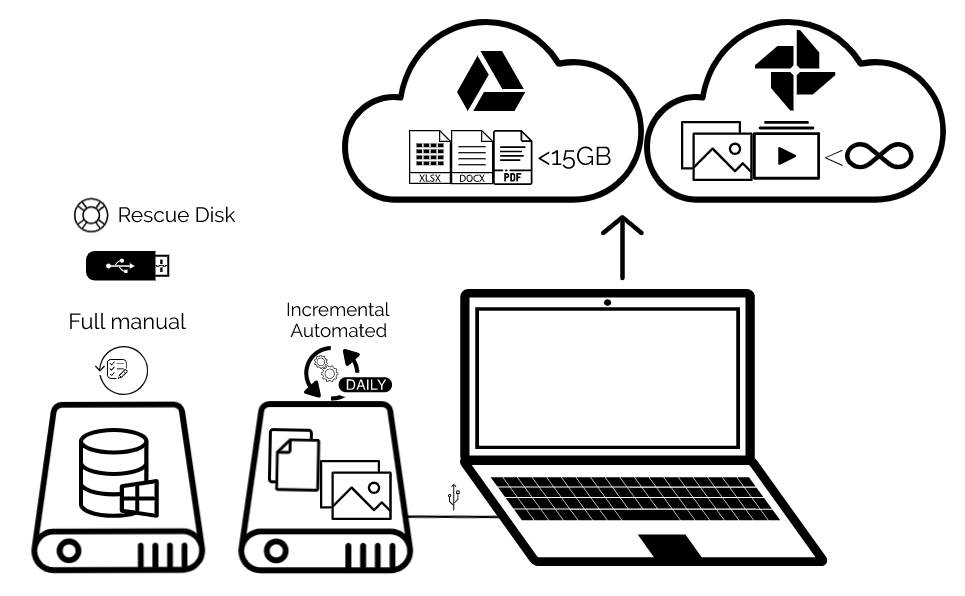
# 摘要
本文从数据保护的基础知识入手,详细介绍了备份策略的设计原则和实施方法,以及在数据丢失情况下进行恢复实践的过程。文章还探讨了数据保护相关的法律和伦理问题,并对未来数据保护的趋势和挑战进行了分析。本文强调了数据备份和恢复策略的重要性,提出了在选择备份工具和执行恢复流程时需要考虑的关键因素,并着重讨论了法律框架与个人隐私保护的伦理考量。同时,文章展望了云数据备份、恢复技术以及人工
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )