Jinja2变量与过滤器:专家级指南,灵活运用模板技术
发布时间: 2024-10-14 09:02:45 阅读量: 71 订阅数: 23 

aiohttp-jinja2:aiohttp.web 的 jinja2 模板渲染器

# 1. Jinja2模板引擎概述
## 1.1 Jinja2的基本介绍
Jinja2是一个广泛使用的模板引擎,它被设计用来渲染HTML,XML或其他标记格式的文本。它最初是为Python语言编写的,但因其灵活性和强大的功能,已成为Web开发中的标准组件之一。Jinja2的语法清晰,易于学习,同时提供了丰富的功能,使得它不仅可以用于Web应用,也可以用于各种自动化任务。
## 1.2 Jinja2的设计哲学
Jinja2的设计哲学是简单而灵活。它将模板设计得尽可能简单,同时提供了强大的功能,如条件语句、循环控制、宏定义等。Jinja2的模板文件通常具有较高的可读性,这使得非程序员也能理解模板的结构和逻辑。
## 1.3 Jinja2与其他模板引擎的比较
与Django模板等其他模板引擎相比,Jinja2提供了更多的控制和更大的灵活性。例如,它允许自定义过滤器和测试,提供了更丰富的语法结构。此外,Jinja2也更加注重安全,它内置了防止模板注入攻击的功能。
在下一章中,我们将深入探讨Jinja2中变量的使用和管理,这是Jinja2模板的基础,也是理解更复杂概念的起点。
# 2. Jinja2变量的使用和管理
## 2.1 变量的基本概念和语法
### 2.1.1 变量的定义和引用
在Jinja2模板中,变量是用于存储和操作数据的基本单元。它们可以是字符串、数字、列表、字典或更复杂的数据类型。变量通过花括号`{{ }}`来定义和引用。
例如,如果你想在模板中显示一个变量的值,可以这样做:
```jinja
{{ variable_name }}
```
这里的`variable_name`是你在模板中定义的变量。在模板渲染时,它将被替换为相应的值。
### 2.1.2 变量的作用域和生命周期
Jinja2中的变量作用域分为全局作用域和局部作用域。全局变量在整个模板中都可用,而局部变量只在其定义的特定模板或代码块中可用。
变量的生命周期指的是变量存在的时间。在Jinja2模板中,变量的生命周期始于其定义,终于模板渲染结束。一旦模板渲染完成,变量将不再存在。
### 2.1.3 代码逻辑解读
下面是一个简单的Jinja2模板示例,展示了变量的定义、作用域和生命周期:
```jinja
{% set global_var = "global value" %}
{% for item in list %}
{% set local_var = item %}
<p>Global: {{ global_var }}, Local: {{ local_var }}</p>
{% endfor %}
```
在这个例子中,`global_var`是一个全局变量,它在模板的开始被定义,并在整个模板中可用。`local_var`是一个局部变量,它在循环内部被定义,并且只能在循环内部访问。
### 2.1.4 参数说明
- `set`:用于定义变量。
- `global_var`:全局变量的名称。
- `local_var`:局部变量的名称。
- `list`:这是一个假定存在的列表变量。
## 2.2 变量的高级特性
### 2.2.1 变量的过滤器应用
Jinja2允许你对变量应用过滤器,以修改其输出或行为。过滤器通过管道符号`|`来应用。
例如,要将变量转换为大写,可以这样做:
```jinja
{{ variable_name | upper }}
```
### 2.2.2 变量的自定义过滤器开发
除了内置的过滤器外,Jinja2还允许你创建自定义过滤器。这可以通过扩展Jinja2的环境对象来实现。
```python
from jinja2 import Environment
def custom_filter(value):
# 自定义过滤器的逻辑
return value.upper()
env = Environment()
env.filters['custom_filter'] = custom_filter
# 在模板中使用自定义过滤器
{{ variable_name | custom_filter }}
```
### 2.2.3 代码逻辑解读
下面是一个自定义过滤器的示例:
```python
from jinja2 import Template
def custom_filter(value):
return value.upper()
env = Environment()
env.filters['custom_filter'] = custom_filter
template = env.from_string('{{ "hello" | custom_filter }}')
result = template.render()
print(result) # 输出: HELLO
```
在这个例子中,我们定义了一个名为`custom_filter`的自定义过滤器,它将字符串转换为大写。然后我们创建了一个模板,并应用了这个过滤器。
### 2.2.4 参数说明
- `Environment`:Jinja2的环境对象,用于加载模板。
- `custom_filter`:自定义过滤器的名称。
- `value`:传递给过滤器的值。
## 2.3 变量的常见问题及解决策略
### 2.3.1 变量未定义的处理
在使用变量时,可能会遇到变量未定义的情况。为了避免程序抛出错误,可以使用`default`过滤器来指定一个默认值。
```jinja
{{ variable_name | default("default value") }}
```
### 2.3.2 变量的错误使用案例分析
错误使用变量可能会导致模板渲染失败或输出意外的结果。例如,尝试访问字典中不存在的键:
```jinja
{{ some_dict["nonexistent_key"] }}
```
这将引发一个`KeyError`。为了避免这种情况,可以使用`dict.get()`方法来安全地获取值:
```jinja
{{ some_dict.get("nonexistent_key", "default_value") }}
```
### 2.3.3 代码逻辑解读
下面是一个错误使用变量的示例,以及如何安全地处理它:
```python
from jinja2 import Template
some_dict = {'key': 'value'}
template = env.from_string('{{ some_dict["nonexistent_key"] }}')
result = template.render()
print(result) # 抛出KeyError
template = env.from_string('{{ some_dict.get("nonexistent_key", "default_value") }}')
result = template.render()
print(result) # 输出: default_value
```
在这个例子中,我们尝试访问字典`some_dict`中的`nonexistent_key`。第一个模板会引发错误,而第二个模板会输出`default_value`。
### 2.3.4 参数说明
- `some_dict`:一个字典变量。
- `nonexistent_key`:尝试访问的不存在的键。
- `default_value`:当键不存在时返回的默认值。
# 3. Jinja2过滤器的深入理解
## 3.1 内置过滤器的应用
### 3.1.1 字符串过滤器
Jinja2提供了一系列内置的字符串过滤器,这些过滤器可以对字符串进行格式化和变换,使得模板中的文本处理更加灵活。以下是一些常用的字符串过滤器及其用法:
- `upper`: 将字符串转换为大写。
- `lower`: 将字符串转换为小写。
- `title`: 将字符串的每个单词首字母大写。
- `trim`: 去除字符串首尾的空白字符。
- `striptags`: 去除字符串中的HTML标签。
```jinja
<p>{{ 'hello world' | upper }}</p>
<!-- 输出:HELLO WORLD -->
<p>{{ ' HELLO WORLD ' | trim }}</p>
<!-- 输出:HELLO WORLD -->
<p>{{ '<strong>hello world</strong>' | striptags }}</p>
<!-- 输出:hello world -->
```
### 3.1.2 列表和元组过滤器
列表和元组过滤器用于处理集合类型的变量,如列表、元组等。这些过滤器可以对集合进行排序、过滤、切片等操作。以下是一些常用的列表和元组过滤器:
- `sort`: 对列表进行排序。
- `reverse`: 反转列表。
- `length`: 获取集合的长度。
- `first`: 获取集合的第一个元素。
- `last`: 获取集合的最后一个元素。
```jinja
<ul>
{% for item in list | sort %}
<li>{{ item }}</li>
{% endfor %}
</ul>
```
### 3.1.3 数字和日期过滤器
数字和日期过滤器用于对数字和日期类型的数据进行格式化。以下是一些常用的数字和日期过滤器:
- `round`: 对数字进行四舍五入。
- `abs`: 获取数字的绝对值。
- `format`: 使用指定的格式化字符串对数字或日期进行格式化。
```jinja
<p>{{ 42 | round }}</p>
<!-- 输出:42 -->
<p>{{ -42 | abs }}</p>
<!-- 输出:42 -->
<p>{{ '2023-01-01' | format('%Y-%m-%d') }}</p>
<!-- 输出:2023-01-01 -->
```
## 3.2 自定义过滤器的创建和使用
### 3.2.1 自定义过滤器的基本步骤
在Jinja2中,除了使用内置过滤器外,我们还可以根据自己的需求创建自定义过滤器。以下是创建自定义过滤器的基本步骤:
1. 定义一个Python函数,该函数接收模板变量作为第一个参数,后续参数为传递给过滤器的参数。
2. 在Jinja2环境中注册该函数作为过滤器。
```python
# app/filters.py
from jinja2 import Environment
def custom_filter(value, arg):
# 自定义逻辑处理
return modified_value
# 创建Jinja2环境并注册过滤器
env = Environment(autoescape=True)
env.filters['custom_filter'] = custom_filter
```
### 3.2.2 自定义过滤器的最佳实践
在创建自定义过滤器时,有一些最佳实践可以帮助我们编写出更加高效和可维护的代码:
- **保持简洁**: 自定义过滤器应该只做一件事,这样它们更易于理解和维护。
- **参数化**: 允许过滤器接受参数可以提高其灵活性和重用性。
- **文档说明**: 为自定义过滤器编写文档说明,这样其他开发者可以了解其用途和用法。
## 3.3 过滤器的性能优化
### 3.3.1 过滤器链的性能影响
在模板中连续使用多个过滤器(过滤器链)可能会影响性能,特别是在处理大量数据时。为了优化性能,我们应该:
- 尽量减少过滤器链的长度。
- 对性能影响较大的操作,考虑在模板渲染前进行预处理。
### 3.3.2 过滤器的优化技巧
以下是一些优化过滤器性能的技巧:
- **缓存结果**: 对于不经常变化的数据,可以将过滤结果进行缓存,避免重复计算。
- **延迟加载**: 对于某些复杂的过滤器,可以使用延迟加载技术,即只有在真正需要时才进行计算。
```jinja
{% set result = some_variable | custom_filter1 | custom_filter2 %}
<!-- 如果 custom_filter2 计算成本很高,可以考虑缓存结果 -->
{% set cached_result = result %}
<!-- 然后使用 cached_result -->
{{ cached_result }}
```
通过本章节的介绍,我们了解了Jinja2过滤器的内置应用、自定义过滤器的创建和使用,以及过滤器性能优化的相关技巧。这些知识对于提高模板的灵活性和性能至关重要。在本章节中,我们通过代码示例和具体的逻辑分析,展示了如何在实际项目中应用这些过滤器。总结来说,掌握过滤器的使用和优化,可以显著提升开发效率和模板的运行效率。
# 4. Jinja2变量与过滤器的实践应用
## 4.1 模板数据的动态处理
在模板引擎的实际应用中,动态处理数据是常见的需求。Jinja2提供了丰富的变量和过滤器功能,使得数据的动态处理变得更加灵活和强大。本章节将深入探讨如何使用Jinja2的变量和过滤器进行数据筛选,并通过案例展示如何动态生成报表模板。
### 4.1.1 使用变量和过滤器进行数据筛选
Jinja2的变量不仅可以输出数据,还可以对数据进行筛选和处理。例如,你可以在模板中使用过滤器来筛选列表中的元素,或者格式化字符串。这些操作可以在模板渲染时动态完成,提高了模板的灵活性和可用性。
```jinja
{% set users = [{'name': 'Alice', 'age': 25}, {'name': 'Bob', 'age': 30}, {'name': 'Charlie', 'age': 28}] %}
{% set older_than_28 = users | selectattr('age', '>=', 28) %}
{% for user in older_than_28 %}
{{ user.name }} is {{ user.age }} years old.
{% endfor %}
```
在上述代码中,我们首先定义了一个包含多个用户信息的列表。然后,使用`selectattr`过滤器筛选出年龄大于或等于28岁的用户,并通过循环输出这些用户的名字和年龄。
### 4.1.2 案例:动态生成报表模板
报表模板的生成是一个典型的动态数据处理场景。通过使用Jinja2的变量和过滤器,我们可以根据不同的数据集动态生成各种报表。
```jinja
{% set sales_data = [
{'date': '2023-01-01', 'revenue': 1000},
{'date': '2023-01-02', 'revenue': 1500},
{'date': '2023-01-03', 'revenue': 2000}
] %}
<table>
<tr>
<th>Date</th>
<th>Revenue</th>
</tr>
{% for entry in sales_data %}
<tr>
<td>{{ entry.date }}</td>
<td>{{ entry.revenue | format_currency }}</td>
</tr>
{% endfor %}
</table>
```
在这个例子中,我们创建了一个包含销售额数据的列表。然后,我们使用一个HTML表格来展示这些数据。对于每一行数据,我们使用了自定义的`format_currency`过滤器来格式化收入金额。
#### 代码逻辑解读
- `{% set sales_data = [...] %}`:定义了一个包含销售额数据的列表。
- `{% for entry in sales_data %}`:循环遍历`sales_data`列表中的每个条目。
- `{{ entry.date }}`:输出条目的日期。
- `{{ entry.revenue | format_currency }}`:输出条目的收入,并通过`format_currency`过滤器进行格式化。
#### 参数说明
- `sales_data`:这是一个包含多个字典的列表,每个字典代表一条销售记录。
- `format_currency`:这是一个自定义过滤器,用于将数值格式化为货币格式。
#### 执行逻辑说明
在模板渲染时,Jinja2会遍历`sales_data`列表,对每个销售记录进行处理。对于每个记录,它会输出日期和经过`format_currency`过滤器处理的收入金额。
通过上述例子,我们可以看到,Jinja2的变量和过滤器在动态处理数据方面非常强大。无论是简单的列表筛选还是复杂的报表生成,Jinja2都能够提供灵活的解决方案。在本章节的介绍中,我们通过具体的代码示例和参数说明,展示了如何使用Jinja2的变量和过滤器进行动态数据处理,并通过案例演示了如何动态生成报表模板。
# 5. Jinja2高级技巧和最佳实践
在本章中,我们将深入探讨Jinja2在实际应用中的一些高级技巧和最佳实践。我们将从Jinja2与Django的集成开始,讨论如何安全地使用Jinja2,并分享一些调试和测试模板的有效方法。
## 5.1 Jinja2与Django的集成技巧
### 5.1.1 Django模板与Jinja2的比较
Django作为Python的一个高级Web框架,自带了一套模板引擎。虽然Django模板和Jinja2在语法上有许多相似之处,但它们在设计理念和功能上存在差异。Django模板更侧重于与Django的紧密集成,而Jinja2则提供更多的灵活性和扩展性。例如,Jinja2支持自定义过滤器和函数,而Django模板则相对固定。此外,Jinja2的表达式更加简洁,它支持更复杂的控制结构,如宏和继承。
### 5.1.2 在Django项目中高效使用Jinja2
为了在Django项目中使用Jinja2,你需要替换Django的默认模板引擎。这可以通过修改项目的设置文件`settings.py`来实现。以下是具体的步骤:
1. 安装Jinja2库(如果尚未安装):
```bash
pip install Jinja2
```
2. 在`settings.py`中将`TEMPLATES`配置项中的`'BACKEND'`值改为`'django.template.backends.jinja2.Jinja2'`。
3. 添加Jinja2的环境配置。例如,你可以添加自定义过滤器和全局变量:
```python
TEMPLATES = [
{
'BACKEND': 'django.template.backends.jinja2.Jinja2',
'DIRS': [os.path.join(BASE_DIR, 'templates')],
'APP_DIRS': True,
'OPTIONS': {
'environment': 'myapp.jinja2.environment',
},
},
]
```
4. 在应用目录下创建一个`jinja2.py`文件,并定义环境:
```python
import jinja2
from django.conf import settings
def environment(**options):
env = jinja2.Environment(**options)
# 添加自定义过滤器
env.filters['upper'] = str.upper
return env
```
这样,你就可以在Django项目中利用Jinja2的强大功能了。
## 5.2 Jinja2的安全实践
### 5.2.1 避免模板注入攻击
模板注入是一种常见的安全漏洞,攻击者可以通过模板注入攻击执行恶意代码。为了防止这种情况,Jinja2提供了几种安全措施:
- 使用`autoescape`功能,自动转义模板中的HTML和JavaScript代码,防止XSS攻击。
- 不要在模板中直接执行用户输入的代码。
- 限制模板中可用的变量和过滤器,只允许安全的操作。
### 5.2.2 Jinja2模板的安全配置
在Django项目中,你可以通过配置`TEMPLATES`选项来增强Jinja2模板的安全性。例如,你可以启用`autoescape`功能,并限制可用的全局变量:
```python
TEMPLATES = [
{
'BACKEND': 'django.template.backends.jinja2.Jinja2',
'DIRS': [os.path.join(BASE_DIR, 'templates')],
'APP_DIRS': True,
'OPTIONS': {
'environment': 'myapp.jinja2.environment',
'autoescape': True, # 启用自动转义
'extensions': [
'jinja2.ext.with_',
'jinja2.ext.autoescape',
],
'globals': {
# 限制全局变量
'safe': lambda x: x,
},
},
},
]
```
通过这些设置,你可以显著提高模板的安全性。
## 5.3 Jinja2模板的调试和测试
### 5.3.1 调试模板的常用方法
调试Jinja2模板可能比较棘手,因为它不像Python代码那样容易添加日志语句。以下是一些常用的调试方法:
- 使用`print`语句:在模板中使用`{{ print(debug_info) }}`来输出变量的值。
- 使用模板继承:创建一个基础模板,其中包含调试工具,然后让其他模板继承这个基础模板。
- 使用模板控制台:Jinja2没有内置的模板控制台,但你可以通过编写自定义的测试代码来实现。
### 5.3.2 编写和运行模板测试用例
为了确保模板的正确性和性能,编写和运行测试用例是非常重要的。你可以使用Python的`unittest`框架来测试Jinja2模板:
1. 创建一个测试用例,加载模板并渲染它:
```python
import unittest
from jinja2 import Environment, FileSystemLoader
class TemplateTestCase(unittest.TestCase):
def setUp(self):
self.env = Environment(loader=FileSystemLoader('templates'))
def test_template(self):
template = self.env.get_template('my_template.html')
result = template.render(var1='value1', var2='value2')
self.assertIn('expected_string', result)
if __name__ == '__main__':
unittest.main()
```
这个测试用例会加载`my_template.html`模板,并检查渲染结果中是否包含`expected_string`字符串。
通过这些高级技巧和最佳实践,你可以更有效地使用Jinja2,并确保你的模板既安全又高效。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面深入地探讨了 Python 库文件 Jinja2.runtime,为开发者提供了从入门到精通的全面指南。涵盖了核心概念、模板语法、控制结构、模板继承、宏的使用、扩展、环境配置、安全性、调试技巧、高级功能、上下文管理、模板加载器、缓存策略、错误处理和性能优化等关键主题。通过一系列循序渐进的教程和示例,本专栏旨在帮助开发者掌握 Jinja2 的强大功能,并将其应用于动态网页开发、模板复用、自定义过滤器和测试器、优化模板渲染性能以及确保模板安全等实际场景中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从停机到上线,EMC VNX5100控制器SP更换的实战演练
# 摘要
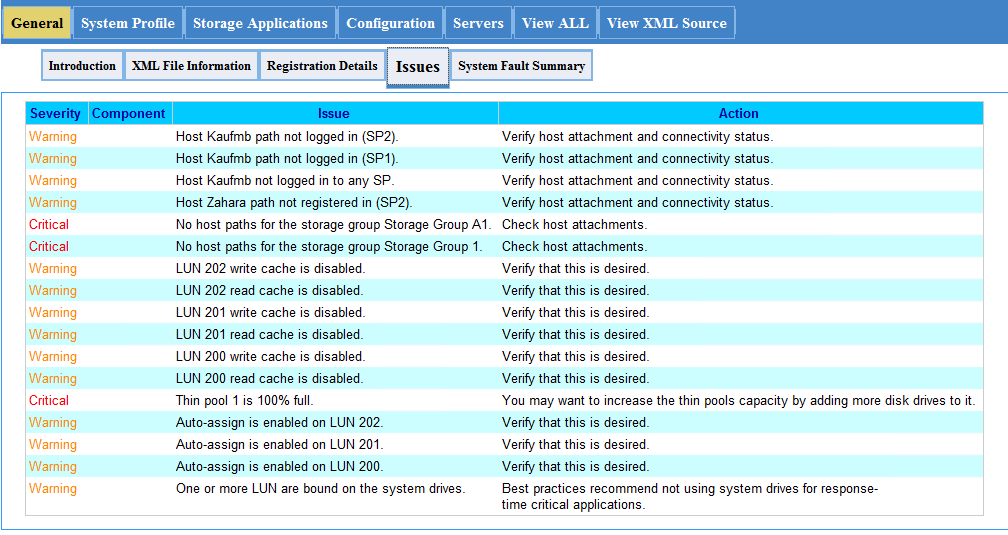
本文详细介绍了EMC VNX5100控制器的更换流程、故障诊断、停机保护、系统恢复以及长期监控与预防性维护策略。通过细致的准备工作、详尽的风险评估以及备份策略的制定,确保控制器更换过程的安全性与数据的完整性。文中还阐述了硬件故障诊断方法、系统停机计划的制定以及数据保护步骤。更换操作指南和系统重启初始化配置得到了详尽说明,以确保系统功能的正常恢复与性能优化。最后,文章强调了性能测试
【科大讯飞官方指南】:语音识别集成与优化的终极解决方案

# 摘要
本文综述了语音识别技术的当前发展概况,深入探讨了科大讯飞语音识别API的架构、功能及高级集成技术。文章详细分析了不同应用场景下语音识别的应用实践,包括智能家居、移动应用和企业级
彻底解决MySQL表锁问题:专家教你如何应对表锁困扰
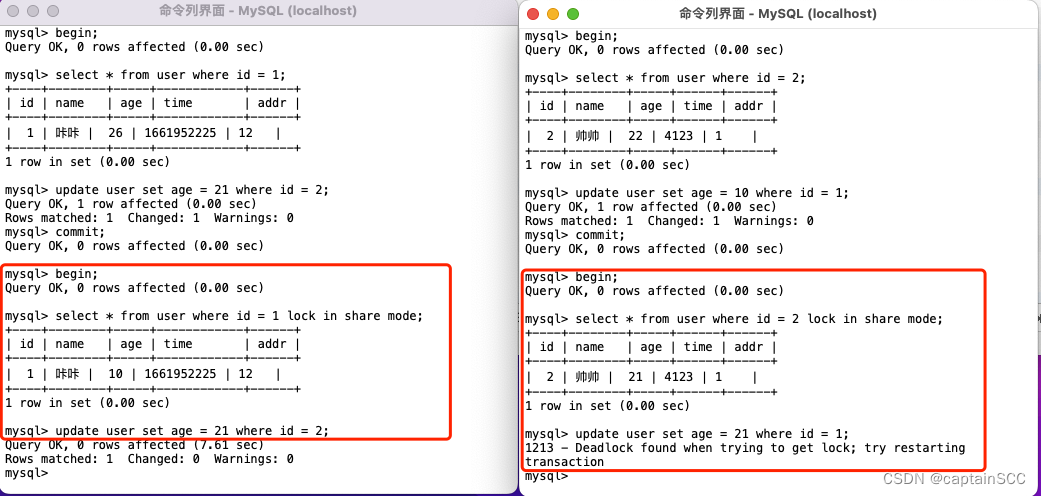
# 摘要
本文深入探讨了MySQL数据库中表锁的原理、问题及其影响。文章从基础知识开始,详细分析了表锁的定义、类型及其与行锁的区别。理论分析章节深入挖掘了表锁产生的原因,包括SQL编程习惯、数据库设计和事务处理,以及系统资源和并发控制问题。性能影响部分讨论了表锁对查询速度和事务处理的潜在负面效果。诊断与排查章节提供了表锁监控和分析工具的使用方法,以及实际监控和调试技巧。随后,本文介绍了避免和解决表锁问题
【双色球数据清洗】:掌握这3个步骤,数据准备不再是障碍
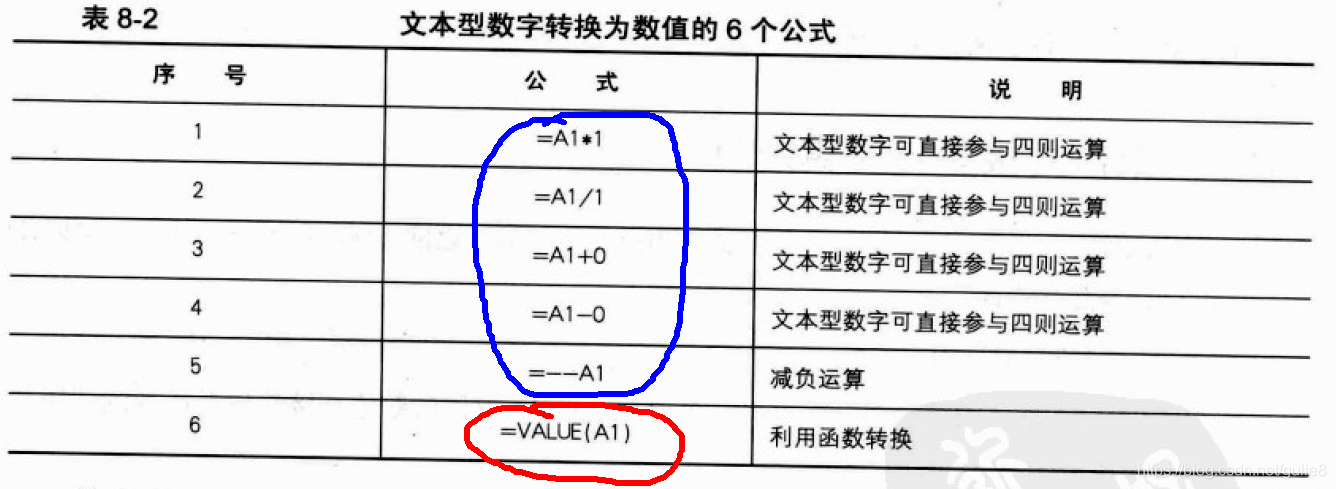
# 摘要
双色球数据清洗作为保证数据分析准确性的关键环节,涉及数据收集、预处理、实践应用及进阶技术等多方面内容。本文首先概述了双色球数据清洗的重要性,并详细解析
【SketchUp脚本编写】

# 摘要
随着三维建模需求的增长,SketchUp脚本编程因其自动化和高效性受到设计师的青睐。本文首先概述了SketchUp脚本编写的基础知识,包括脚本语言的基本概念、SketchUp API与命令操作、控制流与函数的使用。随后,深入探讨了脚本在建模自动化、材质与纹理处理、插件与扩展开发中的实际应用。文章还介绍了高级技巧,如数据交换、错误处理、性能优化
硬盘故障分析:西数硬盘检测工具在故障诊断中的应用(故障诊断的艺术与实践)

# 摘要
本文从硬盘故障的分析概述入手,系统地探讨了西数硬盘检测工具的选择、安装与配置,并深入分析了硬盘的工作原理及故障类型。在此基础上,本文详细阐述了故障诊断的理论基础和实践应用,包括常规状态检测、故障模拟与实战演练。此外,本文还提供了数据恢复与备份策略,以及硬盘故障处理的最佳实践和预防措施,旨在帮助读者全面理解和
关键参数设置大揭秘:DEH调节最佳实践与调优策略
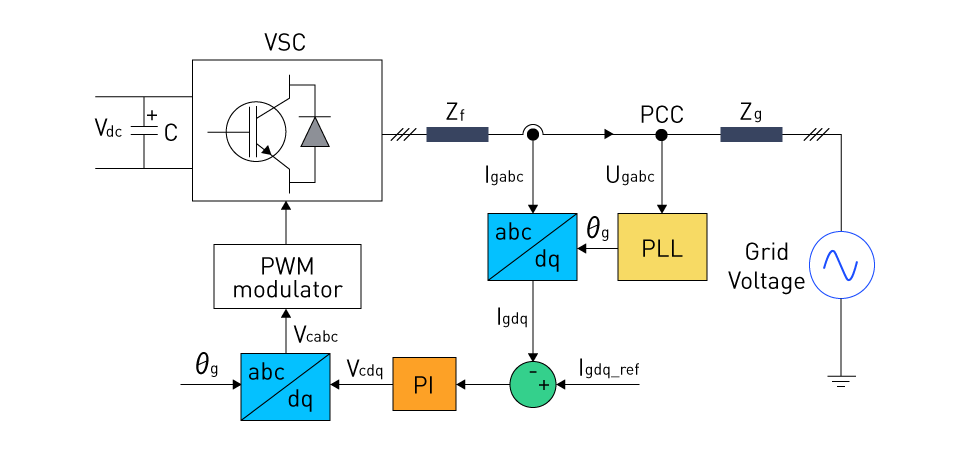
# 摘要
本文系统地介绍了DEH调节技术的基本概念、理论基础、关键参数设置、实践应用、监测与分析工具,以及未来趋势和挑战。首先概述了DEH调节技术的含义和发展背景。随后深入探讨了DEH调节的原理、数学模型和性能指标,详细说明了DEH系统的工作机制以及控制理论在其中的应用。重点分析了DEH调节关键参数的配置、优化策略和异
【面向对象设计在软件管理中的应用】:原则与实践详解
# 摘要
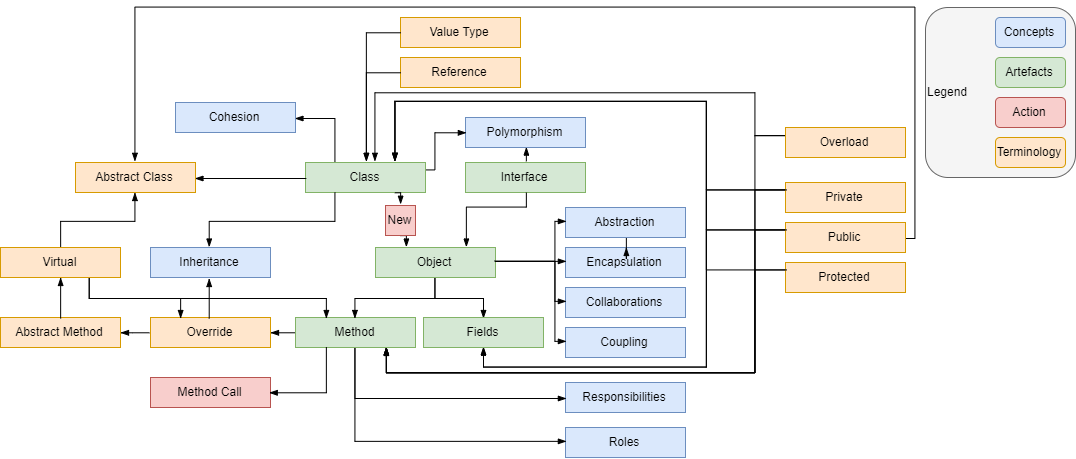
面向对象设计(OOD)是软件工程中的核心概念,它通过封装、继承和多态等特性,促进了代码的模块化和复用性,简化了系统维护,提高了软件质量。本文首先回顾了OOD的基本概念与原则,如单一职责原则(SRP)、开闭原则(OCP)、里氏替换原则(LSP)、依赖倒置原则(DIP)和接口隔离原则(ISP),并通过实际案例分析了这些原则的应用。接着,探讨了创建型、结构型和行为型设计模式在软件开发中的应用,以及面向对象设计
【AT32F435与AT32F437 GPIO应用】:深入理解与灵活运用

# 摘要
AT32F435/437微控制器作为一款广泛应用的高性能MCU,其GPIO(通用输入/输出端口)的功能对于嵌入式系统开发至关重要。本文旨在深入探讨GPIO的基础理论、配置方法、性能优化、实战技巧以及在特定功能中的应用,并提供故障诊断与排错的有效方法。通过详细的端口结构分析、寄存器操作指导和应用案例研究,
【sCMOS相机驱动电路信号同步处理技巧】:精确时间控制的高手方法
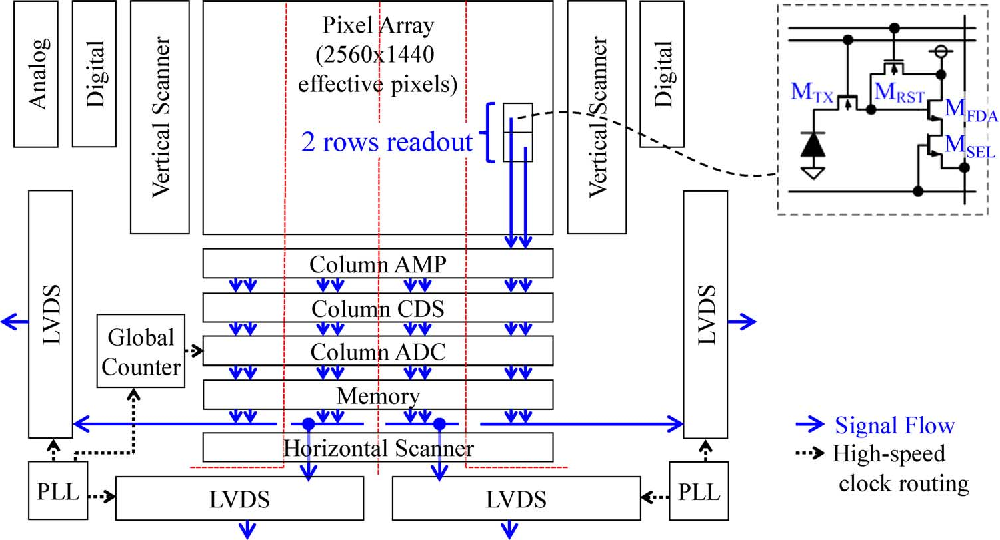
# 摘要
sCMOS相机作为高分辨率成像设备,在科学研究和工业领域中发挥着重要作用。本文首先概述了sCMOS相机驱动电路信号同步处理的基本概念与必要性,然后深入探讨了同步处理的理论基础,包括信号同步的定义、分类、精确时间控制理论以及时间延迟对信号完整性的影响。接着,文章进入技术实践部分,详细描述了驱动电路设计、同步信号生成控制以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )