【OpenCV调用YOLOv5模型ONNX:实战指南】:从环境搭建到实战部署
发布时间: 2024-08-10 17:04:36 阅读量: 1015 订阅数: 51 

Yolov5_onnx
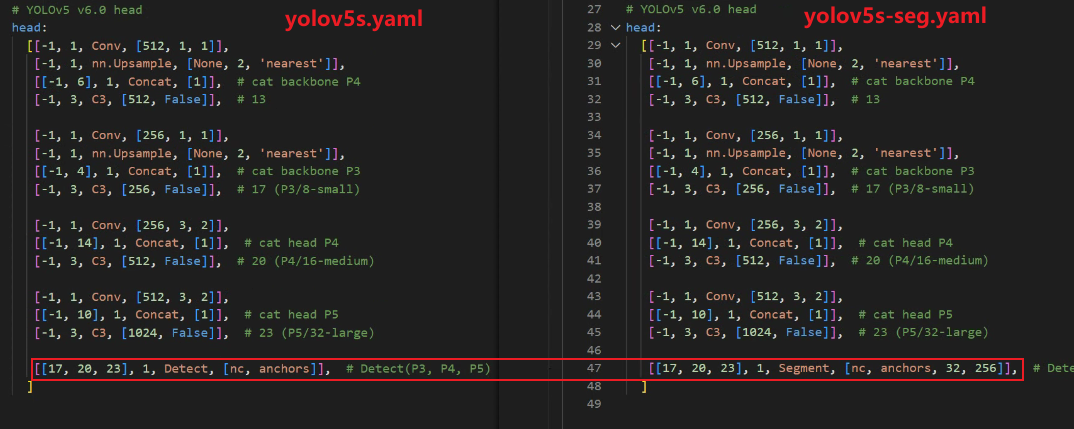
# 1. OpenCV简介和YOLOv5模型**
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,提供了一系列图像处理、视频分析和机器学习算法。YOLOv5(You Only Look Once version 5)是一个高效的目标检测模型,它使用单次卷积神经网络来预测图像中对象的边界框和类别。
OpenCV和YOLOv5的集成使我们能够利用OpenCV的图像处理功能和YOLOv5的强大目标检测能力。通过将YOLOv5模型转换为ONNX(Open Neural Network Exchange)格式,我们可以轻松地将其与OpenCV集成,并在各种应用程序中使用它进行实时目标检测。
# 2. OpenCV和YOLOv5模型集成
### 2.1 OpenCV环境搭建
**1. 安装Anaconda**
Anaconda是一个科学计算平台,提供了一个预先配置的Python发行版,其中包含了OpenCV和其他必要的库。从Anaconda网站下载并安装Anaconda发行版。
**2. 创建虚拟环境**
虚拟环境允许您在隔离的环境中安装和管理Python包,避免与系统安装的包冲突。使用以下命令创建一个名为"opencv-yolo5"的虚拟环境:
```
conda create -n opencv-yolo5 python=3.8
```
**3. 激活虚拟环境**
激活虚拟环境以使用其安装的包:
```
conda activate opencv-yolo5
```
**4. 安装OpenCV**
使用以下命令安装OpenCV:
```
pip install opencv-python
```
### 2.2 YOLOv5模型ONNX转换
**1. 导出YOLOv5模型**
使用YOLOv5提供的导出脚本将训练好的YOLOv5模型导出为ONNX格式:
```
python export.py --weights weights/yolov5s.pt --output yolov5s.onnx
```
**2. 优化ONNX模型**
使用ONNX优化器优化ONNX模型以提高推理速度和减少内存占用。例如,可以使用以下命令使用TensorRT优化器:
```
trtexec --onnx=yolov5s.onnx --save_engine=yolov5s.trt
```
### 2.3 OpenCV与YOLOv5模型集成
**1. 加载ONNX模型**
使用OpenCV的`readNetFromONNX`函数加载优化的ONNX模型:
```python
import cv2
net = cv2.readNetFromONNX("yolov5s.trt")
```
**2. 预处理图像**
将输入图像预处理为YOLOv5模型所需的格式,包括调整大小、归一化和转换为Blob:
```python
image = cv2.imread("image.jpg")
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (640, 640), (0, 0, 0), swapRB=True, crop=False)
```
**3. 推理**
将Blob输入网络进行推理,获得检测结果:
```python
net.setInput(blob)
detections = net.forward()
```
**4. 后处理检测结果**
解析检测结果,包括过滤置信度低的检测、非最大值抑制和转换边界框坐标:
```python
for detection in detections:
# 过滤置信度低的检测
if detection[5] < 0.5:
continue
# 非最大值抑制
if cv2.iou(detection[0], detection[1]) > 0.5:
continue
# 转换边界框坐标
x1, y1, x2, y2 = detection[0].astype(int)
```
**5. 可视化检测结果**
在输入图像上绘制检测结果:
```python
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
```
# 3. YOLOv5模型训练和评估
### 3.1 YOLOv5模型训练
**训练数据集准备**
训练YOLOv5模型需要准备高质量的训练数据集。数据集应包含大量带标注的目标图像,以确保模型能够学习目标的特征和位置。可以使用现有的数据集,如COCO数据集或VOC数据集,也可以根据特定应用场景收集自己的数据集。
**训练参数设置**
YOLOv5模型训练需要设置一系列参数,包括:
- **batch_size:**每个训练批次中图像的数量。
- **epochs:**训练迭代的次数。
- **learning_rate:**优化器学习率。
- **weight_decay:**权重衰减正则化参数。
- **optimizer:**优化器类型,如Adam或SGD。
**训练过程**
训练YOLOv5模型的过程如下:
1. **数据预处理:**将训练图像预处理为模型输入格式,包括调整大小、归一化和数据增强。
2. **模型初始化:**使用预训练权重或从头开始初始化模型。
3. **正向传播:**将训练图像输入模型,并计算损失函数。
4. **反向传播:**计算损失函数对模型权重的梯度。
5. **权重更新:**使用优化器更新模型权重。
6. **迭代训练:**重复步骤2-5,直到达到指定的训练轮数或损失函数收敛。
**代码示例:**
```python
import torch
from yolov5.models.common import DetectMultiBackend
from yolov5.utils.datasets import LoadImagesAndLabels
from yolov5.utils.general import increment_path
from yolov5.utils.train import train_one_epoch
# 训练参数
batch_size = 16
epochs = 100
learning_rate = 0.01
weight_decay = 0.0005
# 数据集路径
train_path = 'path/to/train_dataset'
# 模型初始化
model = DetectMultiBackend(weights='yolov5s.pt')
# 训练数据集
train_dataset = LoadImagesAndLabels(train_path, augment=True)
# 训练循环
for epoch in range(epochs):
# 训练一个epoch
train_one_epoch(model, train_dataset, batch_size, learning_rate, weight_decay)
```
### 3.2 YOLOv5模型评估
**评估指标**
YOLOv5模型评估的指标包括:
- **平均精度(AP):**目标检测任务的标准评估指标,衡量模型检测目标的准确性和召回率。
- **每秒帧数(FPS):**衡量模型的实时推理速度。
- **模型大小:**模型文件的大小,影响模型的部署和使用。
**评估过程**
评估YOLOv5模型的过程如下:
1. **准备验证数据集:**使用与训练数据集不同的验证数据集来评估模型的泛化能力。
2. **推理:**将验证图像输入模型,并获得检测结果。
3. **计算指标:**使用AP、FPS和模型大小等指标评估模型性能。
**代码示例:**
```python
import torch
from yolov5.models.common import DetectMultiBackend
from yolov5.utils.datasets import LoadImagesAndLabels
from yolov5.utils.general import increment_path
from yolov5.utils.metrics import ap_per_class, box_iou
# 评估参数
batch_size = 16
iou_threshold = 0.5
conf_threshold = 0.5
# 验证数据集路径
val_path = 'path/to/val_dataset'
# 模型初始化
model = DetectMultiBackend(weights='yolov5s.pt')
# 验证数据集
val_dataset = LoadImagesAndLabels(val_path, augment=False)
# 评估循环
for batch in val_dataset:
# 推理
preds = model(batch['imgs'])
# 计算指标
ap, _, _, _ = ap_per_class(preds, batch['targets'], iou_threshold=iou_threshold, conf_threshold=conf_threshold)
print(f'AP: {ap}')
```
**评估结果分析**
评估结果可以帮助确定模型的性能和不足之处。高AP值表示模型具有良好的目标检测能力。高FPS值表示模型可以快速进行实时推理。小模型大小有利于模型的部署和使用。根据评估结果,可以对模型进行进一步的调整和优化。
# 4. OpenCV调用YOLOv5模型实战
### 4.1 图像目标检测
#### 4.1.1 代码实现
```python
import cv2
import numpy as np
# 加载YOLOv5模型
net = cv2.dnn.readNet("yolov5s.onnx")
# 加载图像
image = cv2.imread("image.jpg")
# 预处理图像
blob = cv2.dnn.blobFromImage(image, 1/255.0, (640, 640), (0, 0, 0), swapRB=True, crop=False)
# 设置输入
net.setInput(blob)
# 前向传播
detections = net.forward()
# 解析检测结果
for detection in detections[0, 0]:
score = float(detection[2])
if score > 0.5:
left, top, right, bottom = detection[3:7] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
cv2.rectangle(image, (int(left), int(top)), (int(right), int(bottom)), (0, 255, 0), 2)
cv2.putText(image, f"{detection[5]:.2f}", (int(left), int(top) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 显示结果
cv2.imshow("Image", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
#### 4.1.2 代码逻辑分析
1. **加载YOLOv5模型:**使用`cv2.dnn.readNet()`函数加载预训练的YOLOv5模型。
2. **加载图像:**使用`cv2.imread()`函数加载目标图像。
3. **预处理图像:**使用`cv2.dnn.blobFromImage()`函数将图像预处理为YOLOv5模型所需的格式。
4. **设置输入:**将预处理后的图像设置为主网络的输入。
5. **前向传播:**使用`net.forward()`函数进行前向传播,得到检测结果。
6. **解析检测结果:**遍历检测结果,过滤置信度低于阈值的检测结果。
7. **绘制边界框:**对于置信度高于阈值的检测结果,绘制边界框和标签。
8. **显示结果:**将检测结果显示在图像上并等待用户输入。
### 4.2 视频目标检测
#### 4.2.1 代码实现
```python
import cv2
import numpy as np
# 加载YOLOv5模型
net = cv2.dnn.readNet("yolov5s.onnx")
# 打开视频流
cap = cv2.VideoCapture("video.mp4")
while True:
# 读取帧
ret, frame = cap.read()
if not ret:
break
# 预处理帧
blob = cv2.dnn.blobFromImage(frame, 1/255.0, (640, 640), (0, 0, 0), swapRB=True, crop=False)
# 设置输入
net.setInput(blob)
# 前向传播
detections = net.forward()
# 解析检测结果
for detection in detections[0, 0]:
score = float(detection[2])
if score > 0.5:
left, top, right, bottom = detection[3:7] * np.array([frame.shape[1], frame.shape[0], frame.shape[1], frame.shape[0]])
cv2.rectangle(frame, (int(left), int(top)), (int(right), int(bottom)), (0, 255, 0), 2)
cv2.putText(frame, f"{detection[5]:.2f}", (int(left), int(top) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 显示结果
cv2.imshow("Video", frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# 释放视频流
cap.release()
cv2.destroyAllWindows()
```
#### 4.2.2 代码逻辑分析
1. **加载YOLOv5模型:**与图像目标检测类似,加载预训练的YOLOv5模型。
2. **打开视频流:**使用`cv2.VideoCapture()`函数打开视频流。
3. **循环读取帧:**使用`cap.read()`函数循环读取视频帧。
4. **预处理帧:**与图像目标检测类似,预处理视频帧。
5. **设置输入:**将预处理后的帧设置为主网络的输入。
6. **前向传播:**进行前向传播,得到检测结果。
7. **解析检测结果:**与图像目标检测类似,过滤置信度低于阈值的检测结果。
8. **绘制边界框:**对于置信度高于阈值的检测结果,绘制边界框和标签。
9. **显示结果:**将检测结果显示在视频帧上并等待用户输入。
10. **释放视频流:**当用户按下`q`键时,释放视频流。
# 5.1 YOLOv5模型优化
### 5.1.1 量化
量化是将浮点权重和激活转换为定点表示的过程。这可以通过使用诸如TensorRT或ONNX Runtime之类的框架来实现。量化可以显着减少模型的大小和推理时间,而不会显著降低准确性。
### 5.1.2 剪枝
剪枝是删除模型中不重要的权重和激活的过程。这可以通过使用诸如Network Slimming或Magnitude Pruning之类的技术来实现。剪枝可以显着减少模型的大小和推理时间,同时保持准确性。
### 5.1.3 知识蒸馏
知识蒸馏是将大型教师模型的知识转移到较小、更有效的学生模型的过程。这可以通过使用诸如教师-学生学习或知识蒸馏损失之类的技术来实现。知识蒸馏可以显着提高学生模型的准确性,同时保持较小的模型大小和推理时间。
## 5.2 YOLOv5模型部署
### 5.2.1 云端部署
云端部署涉及将模型部署到云平台,例如AWS、Azure或Google Cloud。云端部署提供了可扩展性和弹性,允许模型在需求高峰期处理大量请求。
### 5.2.2 边缘设备部署
边缘设备部署涉及将模型部署到边缘设备,例如智能手机、嵌入式设备或物联网设备。边缘设备部署提供了低延迟和离线功能,允许模型在没有互联网连接的情况下运行。
### 5.2.3 Web部署
Web部署涉及将模型部署到Web服务器,例如Apache或Nginx。Web部署允许模型通过Web浏览器访问,使其易于与用户共享和交互。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了使用 OpenCV 调用 YOLOv5 模型 ONNX 的各个方面。从环境搭建到实战部署,它提供了全面的指南,涵盖了优化技巧、性能提升、常见问题和解决方案。专栏还提供了附有案例代码和性能优化技巧的实战案例,展示了 YOLOv5 模型 ONNX 与 OpenCV 的强大组合在图像目标检测中的应用。此外,它还介绍了部署策略,帮助读者优化模型性能并将其部署到实际应用中。通过本专栏,读者可以掌握使用 OpenCV 调用 YOLOv5 模型 ONNX 进行目标检测的方方面面,并获得提高模型性能和部署效率的实用技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【软件使用说明书的可读性提升】:易理解性测试与改进的全面指南
# 摘要
软件使用说明书作为用户与软件交互的重要桥梁,其重要性不言而喻。然而,如何确保说明书的易理解性和高效传达信息,是一项挑战。本文深入探讨了易理解性测试的理论基础,并提出了提升使用说明书可读性的实践方法。同时,本文也分析了基于用户反馈的迭代优化策略,以及如何进行软件使用说明书的国际化与本地化。通过对成功案例的研究与分析,本文展望了未来软件使用说明书设
【音频同步与编辑】:为延时作品添加完美音乐与声效的终极技巧
# 摘要
音频同步与编辑是多媒体制作中不可或缺的环节,对于提供高质量的视听体验至关重要。本论文首先介绍了音频同步与编辑的基础知识,然后详细探讨了专业音频编辑软件的选择、配置和操作流程,以及音频格式和质量的设置。接着,深入讲解了音频同步的理论基础、时间码同步方法和时间管理技巧。文章进一步聚焦于音效的添加与编辑、音乐的混合与平衡,以及音频后期处理技术。最后,通过实际项目案例分析,展示了音频同步与编辑在不同项目中的应用,并讨论了项目完成后的质量评估和版权问题。本文旨在为音频技术人员提供系统性的理论知识和实践指南,增强他们对音频同步与编辑的理解和应用能力。
# 关键字
音频同步;音频编辑;软件配置;
多模手机伴侣高级功能揭秘:用户手册中的隐藏技巧
# 摘要
多模手机伴侣是一款集创新功能于一身的应用程序,旨在提供全面的连接与通信解决方案,支持多种连接方式和数据同步。该程序不仅提供高级安全特性,包括加密通信和隐私保护,还支持个性化定制,如主题界面和自动化脚本。实践操作指南涵盖了设备连接、文件管理以及扩展功能的使用。用户可利用进阶技巧进行高级数据备份、自定义脚本编写和性能优化。安全与隐私保护章节深入解释了数据保护机制和隐私管理。本文展望
PLC系统故障预防攻略:预测性维护减少停机时间的策略

# 摘要
本文深入探讨了PLC系统的故障现状与挑战,并着重分析了预测性维护的理论基础和实施策略。预测性维护作为减少故障发生和提高系统可靠性的关键手段,本文不仅探讨了故障诊断的理论与方法,如故障模式与影响分析(FMEA)、数据驱动的故障诊断技术,以及基于模型的故障预测,还论述了其数据分析技术,包括统计学与机器学习方法、时间序列分析以及数据整合与
数据挖掘在医疗健康的应用:疾病预测与治疗效果分析(如何通过数据挖掘改善医疗决策)

# 摘要
数据挖掘技术在医疗健康领域中的应用正逐渐展现出其巨大潜力,特别是在疾病预测和治疗效果分析方面。本文探讨了数据挖掘的基础知识及其与医疗健康领域的结合,并详细分析了数据挖掘技术在疾病预测中的实际应用,包括模型构建、预处理、特征选择、验证和优化策略。同时,文章还研究了治疗效果分析的目标、方法和影响因素,并探讨了数据隐私和伦理问题,
【提升R-Studio恢复效率】:RAID 5数据恢复的高级技巧与成功率
# 摘要
RAID 5作为一种广泛应用于数据存储的冗余阵列技术,能够提供较好的数据保护和性能平衡。本文首先概述了RAID 5数据恢复的重要性,随后介绍了RAID 5的基础理论,包括其工作原理、故障类型及数据恢复前的准备工作。接着,文章深入探讨了提升RAID 5数据恢复成功率的高级技巧,涵盖了硬件级别和软件工具的应用,以及文件系统结构和数据一致性检查。通过实际案例分析,
【实战技巧揭秘】:WIN10LTSC2021输入法BUG引发的CPU占用过高问题解决全记录

# 摘要
本文对Win10 LTSC 2021版本中出现的输入法BUG进行了详尽的分析与解决策略探讨。首先概述了BUG现象,然后通过系统资源监控工具和故障排除技术,对CPU占用过高问题进行了深入分析,并初步诊断了输入法BUG。在此基础上,本文详细介绍了通过系统更新
【大规模部署的智能语音挑战】:V2.X SDM在大规模部署中的经验与对策

# 摘要
随着智能语音技术的快速发展,它在多个行业得到了广泛应用,同时也面临着众多挑战。本文首先回顾了智能语音技术的兴起背景,随后详细介绍了V2.X SDM平台的架构、核心模块、技术特点、部署策略、性能优化及监控。在此基础上,本文探讨了智能语音技术在银行业和医疗领域的特定应用挑战,重点分析了安全性和复杂场景下的应用需求。文章最后展望了智能语音和V2.X SDM
【脚本与宏命令增强术】:用脚本和宏命令提升PLC与打印机交互功能(交互功能强化手册)
# 摘要
本文探讨了脚本和宏命令的基础知识、理论基础、高级应用以及在实际案例中的应用。首先概述了脚本与宏命令的基本概念、语言构成及特点,并将其与编译型语言进行了对比。接着深入分析了PLC与打印机交互的脚本实现,包括交互脚本的设计和测试优化。此外,本文还探讨了脚本与宏命令在数据库集成、多设备通信和异常处理方面的高级应用。最后,通过工业
飞腾X100+D2000启动阶段电源管理:平衡节能与性能
# 摘要
本文旨在全面探讨飞腾X100+D2000架构的电源管理策略和技术实践。第一章对飞腾X100+D2000架构进行了概述,为读者提供了研究背景。第二章从基础理论出发,详细分析了电源管理的目的、原则、技术分类及标准与规范。第三章深入探讨了在飞腾X100+D2000架构中应用的节能技术,包括硬件与软件层面的节能技术,以及面临的挑战和应对策略。第四章重点介绍了启动阶
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )