PycURL进阶技巧揭秘:文件上传下载的高效策略
发布时间: 2024-10-15 20:52:03 订阅数: 2 

# 1. PycURL简介与安装
## 简介
PycURL是一个强大的库,它是libcurl的Python接口,允许Python开发者通过简单地调用Python代码来执行各种网络请求。PycURL可以处理包括HTTP、HTTPS、FTP等多种协议,支持请求和响应的编码和解码,是网络编程和数据抓取的理想选择。
## 安装
安装PycURL相对简单,推荐使用pip工具进行安装:
```bash
pip install pycurl
```
如果你在安装过程中遇到任何问题,比如需要特定的编译器或依赖库,确保你的系统已经安装了这些工具。对于大多数Linux发行版,可以通过系统的包管理器安装依赖。
```bash
# For Ubuntu/Debian
sudo apt-get install libcurl4-openssl-dev
# For CentOS
sudo yum install libcurl-devel
```
安装完成后,你可以通过运行简单的测试代码来验证PycURL是否安装成功:
```python
import pycurl
from io import BytesIO
buffer = BytesIO()
c = pycurl.Curl()
c.setopt(c.URL, '***')
c.setopt(c.WRITEDATA, buffer)
c.perform()
c.close()
body = buffer.getvalue()
print(body.decode('utf-8')) # 输出响应内容
```
这个测试将向***发送一个HTTP GET请求,并打印响应的内容。如果安装正确,你将看到HTTP响应体的输出。
在接下来的章节中,我们将深入探讨PycURL的基础操作,包括如何设置URL和请求方式,处理响应数据,以及使用PycURL进行文件上传和下载的技巧。
# 2. PycURL基础操作
## 2.1 PycURL的基本用法
### 2.1.1 设置URL和请求方式
在本章节中,我们将介绍PycURL的基本用法,包括如何设置URL和请求方式。PycURL是一个强大的库,它允许你执行HTTP请求,而无需依赖复杂的框架。它提供了类似于Python标准库中的`urllib`的功能,但是具有更多的灵活性。
首先,我们需要安装PycURL库,这可以通过`pip`安装命令来完成:
```bash
pip install pycurl
```
安装完成后,我们可以开始编写一些基本的代码来了解PycURL如何工作。以下是一个简单的例子,展示了如何使用PycURL来发送一个GET请求:
```python
import pycurl
from io import BytesIO
# 创建一个BytesIO对象来捕获响应
buffer = BytesIO()
# 初始化一个PycURL对象
c = pycurl.Curl()
# 设置URL
c.setopt(c.URL, '***')
# 设置写数据的回调函数
c.setopt(c.WRITEDATA, buffer)
# 执行请求
c.perform()
# 关闭连接
c.close()
# 打印出获取到的响应内容
print(buffer.getvalue().decode('utf-8'))
```
在这个例子中,我们首先导入了`pycurl`模块和`BytesIO`类,然后创建了一个`BytesIO`对象来捕获响应内容。接着,我们创建了一个`Curl`对象,并使用`setopt`方法设置了请求的URL。我们还设置了写数据的回调函数为`buffer`对象,这样响应数据就可以被捕获到这个对象中。最后,我们调用了`perform`方法来执行请求,并通过`close`方法关闭了连接。
### 2.1.2 处理响应数据
处理响应数据是网络请求中的一个重要环节。在上面的例子中,我们使用了`BytesIO`对象来捕获响应内容。现在,我们将介绍如何解析这些响应内容,并提取我们需要的信息。
PycURL返回的响应数据是原始的字节流,因此我们需要将其解码为字符串才能进行处理。以下是如何解析响应数据并提取特定信息的步骤:
```python
import pycurl
from io import BytesIO
import json
# 创建一个BytesIO对象来捕获响应
buffer = BytesIO()
# 初始化一个PycURL对象
c = pycurl.Curl()
# 设置URL
c.setopt(c.URL, '***')
# 设置写数据的回调函数
c.setopt(c.WRITEDATA, buffer)
# 执行请求
c.perform()
# 关闭连接
c.close()
# 获取响应内容
response_data = buffer.getvalue().decode('utf-8')
# 解析JSON格式的响应内容
response_json = json.loads(response_data)
# 打印出URL和HTTP状态码
print(f"URL: {response_json['url']}")
print(f"HTTP Status Code: {response_json['status']}")
```
在这个例子中,我们首先将响应数据解码为字符串,然后使用`json.loads`方法将字符串解析为JSON对象。这样我们就可以非常方便地访问响应中的任何数据,例如URL和HTTP状态码。
在实际应用中,你可能需要根据实际情况调整解析方式,比如处理非JSON格式的响应内容,或者提取响应中的特定字段等。
在本章节中,我们介绍了PycURL的基本用法,包括如何设置URL和请求方式,以及如何处理响应数据。在下一节中,我们将深入探讨PycURL的高级特性,包括超时设置、重试逻辑、自定义HTTP头部和Cookie处理等。
# 3. PycURL文件上传策略
## 3.1 上传机制详解
### 3.1.1 POST请求和multipart/form-data
在文件上传机制中,POST请求是最常用的HTTP请求方法之一,它允许客户端向服务器发送数据,服务器则根据请求中的内容进行处理。PycURL作为libcurl的Python接口,提供了与libcurl相同的HTTP上传能力。为了进行文件上传,客户端通常需要使用`multipart/form-data`编码类型,这是一种特殊的编码类型,用于将表单数据和文件数据一起发送到服务器。
#### 表格:POST请求与multipart/form-data
| POST请求 | multipart/form-data |
|----------|---------------------|
| 请求方法 | 用于发送数据到服务器 |
| 编码类型 | application/x-www-form-urlencoded 或 multipart/form-data |
| 数据传输 | 将数据编码为键值对 |
| 适用场景 | 上传文本数据 |
| 优点 | 实现简单 |
| 缺点 | 不适合大文件上传 |
当上传文件时,`multipart/form-data`编码类型更为合适,因为它允许将文件内容和元数据(如文件名、MIME类型等)以多部分消息的形式发送。每个部分都是独立的,并且可以包含不同的内容类型。
### 3.1.2 大文件上传的分块处理
对于大文件上传,直接将整个文件内容作为HTTP请求的一部分发送到服务器是不现实的,这会消耗大量内存,同时也可能因为网络问题导致上传失败。因此,大文件通常会采用分块上传的方式。
分块上传是指将大文件分割成多个小块,然后逐个上传这些小块。服务器在收到所有小块后,再将它们组合成完整的文件。这种方法不仅可以减少内存的占用,还可以在上传过程中检测网络问题并重新上传失败的块。
#### 表格:大文件上传的分块处理
| 分块大小 | 描述 |
|----------|------|
| 小于1MB | 通常不需要分块 |
| 1MB-10MB | 推荐的分块大小 |
| 大于10MB | 考虑网络状况和服务器性能进行调整 |
## 3.2 PycURL上传实践案例
### 3.2.1 构建上传脚本的基本框架
在PycURL中实现文件上传,首先需要构建一个基本的脚本框架。这个框架将包括初始化PycURL句柄、设置POST请求、指定文件和分块上传的逻辑。
#### 代码块:构建上传脚本的基本框架
```python
import pycurl
from io import BytesIO
# 初始化PycURL
c = pycurl.Curl()
# 设置上传的URL和POST请求
c.setopt(pycurl.URL, '***')
c.setopt(pycurl.POST, 1)
# 指定要上传的文件
c.setopt(pycurl.POSTFIELDS, 'file=@path/to/your/file')
# 执行请求
c.perform()
# 关闭连接
c.close()
```
在这个例子中,我们使用了`pycurl.setopt`方法来设置上传的URL和POST请求。`POSTFIELDS`选项用于指定要上传的文件,`@`符号表示这是一个文件路径。当执行`perform`方法时,PycURL会将文件内容作为`multipart/form-data`数据发送到指定的URL。
### 3.2.2 处理复杂文件类型和元数据
对于需要上传的复杂文件类型或包含元数据的情况,PycURL也提供了灵活的处理方式。用户可以手动构建`multipart/form-data`数据,将文件内容和元数据组合成一个大的二进制数据流,然后通过`POSTFIELDS`选项发送。
#### 代码块:构建复杂文件上传数据
```python
import pycurl
from io import BytesIO
# 初始化PycURL
c = pycurl.Curl()
# 设置上传的URL
c.setopt(pycurl.URL, '***')
# 创建一个二进制数据流
buffer = BytesIO()
writer = pycurl附件(multipart/form-data数据)
# 添加文件内容
file_content = open('path/to/your/file', 'rb').read()
writer.write(file_content)
# 添加文件名元数据
writer.write('--'.encode('utf-8'))
writer.write(b'\r\n')
writer.write('Content-Disposition: form-data; name="file"; filename="yourfile.txt"'.encode('utf-8'))
writer.write(b'\r\n')
writer.write(b'\r\n')
# 添加文件MIME类型
mime_type = 'text/plain'
writer.write(mime_type.encode('utf-8'))
writer.write(b'\r\n')
# 添加空行表示分隔符
writer.write(b'\r\n')
# 执行请求
c.setopt(pycurl.POSTFIELDS, buffer.getvalue())
c.perform()
# 关闭连接
c.close()
```
在这个例子中,我们使用了`BytesIO`和`pycurl附件`来构建一个自定义的`multipart/form-data`数据。我们手动添加了文件内容、文件名和MIME类型等元数据,并且在数据流的末尾添加了一个空行作为分隔符。
## 3.3 上传性能优化
### 3.3.1 优化上传速度的策略
为了优化上传速度,可以采取以下策略:
1. **选择合适的分块大小**:根据网络状况和服务器性能调整分块大小,以减少网络延迟和提高上传效率。
2. **使用多线程或异步上传**:同时上传多个文件或多个文件块,可以充分利用网络带宽和服务器资源。
3. **优化网络连接设置**:例如设置合适的超时时间、重试逻辑和连接缓存。
### 3.3.2 多线程和异步上传的应用
在PycURL中实现多线程或异步上传,可以使用Python的`threading`模块或`asyncio`库。下面是一个使用`threading`模块实现多线程上传的例子。
#### 代码块:多线程上传的实现
```python
import pycurl
from threading import Thread
from io import BytesIO
# 定义上传函数
def upload_file(c, file_path):
c.setopt(pycurl.URL, '***')
c.setopt(pycurl.POST, 1)
c.setopt(pycurl.POSTFIELDS, 'file=@{}'.format(file_path))
c.perform()
# 创建PycURL句柄
c = pycurl.Curl()
# 设置上传的文件路径
file_path = 'path/to/your/file'
# 创建线程并开始上传
thread = Thread(target=upload_file, args=(c, file_path))
thread.start()
# 等待上传完成
thread.join()
# 关闭连接
c.close()
```
在这个例子中,我们定义了一个`upload_file`函数,它将一个文件路径作为参数,并使用PycURL执行上传操作。然后,我们创建了一个`Thread`对象,并将`upload_file`函数和文件路径作为参数传递给它。通过调用`start`方法启动线程,从而实现多线程上传。
#### Mermaid流程图:多线程上传流程
```mermaid
graph LR
A[开始] --> B[创建PycURL句柄]
B --> C[设置上传的文件路径]
C --> D[创建上传线程]
D --> E[启动线程]
E --> F[等待上传完成]
F --> G[关闭PycURL连接]
G --> H[结束]
```
请注意,上述代码示例仅为演示目的,并未包含错误处理和连接管理等完整操作。在实际应用中,需要添加适当的异常处理和资源管理逻辑。
# 4. PycURL在实际项目中的应用
## 5.1 网络爬虫中的应用
### 5.1.1 使用PycURL进行网页抓取
在本章节中,我们将探讨PycURL在网络爬虫应用中的实践,特别是在使用PycURL进行网页抓取方面的技巧和方法。PycURL作为一个强大的网络请求库,可以有效地用于网络爬虫项目中,因为它不仅支持HTTP和HTTPS协议,还能够处理cookie、自定义HTTP头部等高级特性。
#### 网络爬虫的基本原理
网络爬虫(Web Crawler),也称为网络蜘蛛(Spider),是一种自动获取网页内容的程序。它通过访问网页,解析网页内容,并提取网页中的链接来抓取更多网页。网络爬虫通常用于搜索引擎、数据挖掘、信息收集等领域。
#### PycURL在爬虫中的优势
PycURL相比于Python内置的`urllib`库,提供了更底层的网络请求接口,这使得开发者能够更细致地控制网络请求的各个方面。PycURL支持多种协议,且性能优异,特别适合于大规模的网络爬虫项目。
#### 使用PycURL进行网页抓取的基本步骤
1. **初始化PycURL环境**:首先需要导入pycurl模块,并初始化一个Curl对象。
```python
import pycurl
from io import BytesIO
buffer = BytesIO()
c = pycurl.Curl()
c.setopt(c.URL, '***')
c.setopt(c.WRITEDATA, buffer)
```
2. **设置请求参数**:根据需要设置请求方法(GET、POST)、HTTP头部等参数。
```python
c.setopt(c.HTTPHEADER, ['User-Agent: PycURL'])
```
3. **执行请求**:执行网络请求并获取响应。
```python
c.perform()
```
4. **处理响应数据**:将响应数据从缓冲区中取出并进行处理。
```python
response = buffer.getvalue().decode('utf-8')
print(response)
```
5. **关闭连接**:完成请求后,关闭Curl对象。
```python
c.close()
```
#### 网络爬虫的实际应用案例
**案例:使用PycURL抓取指定URL的内容**
```python
import pycurl
from io import BytesIO
# 初始化PycURL环境
c = pycurl.Curl()
buffer = BytesIO()
c.setopt(c.URL, '***')
c.setopt(c.WRITEDATA, buffer)
# 设置HTTP头部
c.setopt(c.HTTPHEADER, ['User-Agent: PycURL'])
# 执行请求
c.perform()
# 处理响应数据
response = buffer.getvalue().decode('utf-8')
print(response)
# 关闭连接
c.close()
```
**代码逻辑解读分析**
- **导入模块**:首先导入必要的模块,包括`pycurl`和`io`中的`BytesIO`。
- **创建Curl对象**:创建一个Curl对象,用于执行网络请求。
- **设置请求参数**:通过`setopt`方法设置URL和写入数据的对象。
- **执行请求**:调用`perform`方法执行网络请求。
- **处理响应数据**:从`BytesIO`对象中读取数据,将其解码为字符串,并打印出来。
- **关闭连接**:完成请求后关闭Curl对象。
### 5.1.2 处理反爬虫机制的技巧
网络爬虫在抓取网页内容时,常常会遇到各种反爬虫机制,如IP限制、请求频率限制、验证码等。为了有效地应对这些反爬虫措施,我们需要采取一些策略。
#### IP代理的使用
为了避免被网站识别出频繁的爬取行为,我们可以使用代理服务器。PycURL支持通过设置代理来隐藏真实的IP地址。
```python
c.setopt(c.PROXY, '代理地址')
c.setopt(c.PROXYPORT, 代理端口)
```
#### 请求头伪装
通过设置请求头,如`User-Agent`、`Referer`等,可以让我们的请求看起来更像是来自真实用户的浏览器。
```python
c.setopt(c.HTTPHEADER, [
'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
])
```
#### 限制请求频率
为了避免请求频率过高触发反爬虫机制,我们可以设置合理的请求间隔。
```python
import time
import random
time.sleep(random.uniform(1, 3)) # 随机等待1到3秒
```
#### CAPTCHA识别
对于验证码,我们可以使用OCR或第三方服务来自动识别,或者使用人工的方式进行识别。
```python
# 伪代码,使用OCR库识别验证码
from ocr_library import OCR
captcha_text = OCR.recognize(image)
```
## 5.2 数据处理和分析
### 5.2.1 从网络下载数据到本地
网络爬虫的一个重要应用是将网络上的数据下载到本地进行进一步的处理和分析。PycURL不仅可以下载网页内容,还可以下载图片、视频等多媒体数据。
#### 使用PycURL下载文件
以下是一个使用PycURL下载文件的基本示例:
```python
import pycurl
from io import BytesIO
import os
def download_file(url, local_filename):
with pycurl.Curl() as c:
c.setopt(c.URL, url)
c.setopt(c.WRITEDATA, BytesIO())
c.perform()
data = c.getinfo(***_CONTENT_LENGTH)
if data >= 0:
data = c.getinfo(***_CONTENT_LENGTH_DOWNLOAD)
with open(local_filename, 'wb') as f:
f.write(data)
f.flush()
# 示例:下载图片
download_file('***', 'local_image.jpg')
```
#### 代码逻辑解读分析
- **定义函数**:定义一个`download_file`函数,接受URL和本地文件名作为参数。
- **初始化PycURL环境**:创建一个Curl对象。
- **设置请求参数**:设置请求的URL。
- **执行请求并获取响应**:执行网络请求,并使用`BytesIO`对象作为响应数据的写入目标。
- **获取文件大小**:使用`getinfo`方法获取下载的文件大小。
- **写入文件**:打开本地文件,将响应数据写入文件。
### 5.2.2 数据清洗和预处理
下载的原始数据往往包含许多不需要的信息,因此需要进行数据清洗和预处理。这可能包括去除HTML标签、提取特定信息、格式化日期时间等。
#### 使用Python进行数据清洗
以下是使用Python进行数据清洗的一个基本示例:
```python
import re
def clean_html(raw_html):
cleanr = ***pile('<.*?>')
cleantext = re.sub(cleanr, '', raw_html)
return cleantext
# 示例:清洗HTML内容
raw_html = '<html><head><title>Page Title</title></head><body><p>Hello, World!</p></body></html>'
clean_text = clean_html(raw_html)
print(clean_text)
```
#### 代码逻辑解读分析
- **定义函数**:定义一个`clean_html`函数,用于去除HTML标签。
- **正则表达式匹配**:使用正则表达式匹配HTML标签。
- **替换文本**:将HTML标签替换为空字符串,得到清洁的文本。
## 5.3 自动化任务和监控系统
### 5.3.1 使用PycURL自动化更新数据
PycURL可以用于自动化更新数据的任务,例如定期从外部API获取最新信息,并更新本地数据库。
#### 自动化脚本的基本结构
以下是一个自动化更新数据的基本脚本结构:
```python
import pycurl
from datetime import datetime
import sqlite3
def update_data(api_url, db_file):
with pycurl.Curl() as c:
c.setopt(c.URL, api_url)
c.setopt(c.WRITEDATA, BytesIO())
c.perform()
response = c.getinfo(***_CONTENT_LENGTH_DOWNLOAD)
# 处理响应数据,例如插入数据库
conn = sqlite3.connect(db_file)
c = conn.cursor()
# 假设响应数据格式为JSON
data = json.loads(response)
for row in data:
c.execute('INSERT INTO table_name (column1, column2) VALUES (?, ?)', (row['value1'], row['value2']))
***mit()
conn.close()
# 示例:从API更新数据
api_url = '***'
db_file = 'local_database.db'
update_data(api_url, db_file)
```
#### 代码逻辑解读分析
- **定义函数**:定义一个`update_data`函数,接受API URL和数据库文件作为参数。
- **执行PycURL请求**:使用PycURL发送请求并获取响应。
- **处理响应数据**:假设响应数据为JSON格式,解析JSON数据并将其插入到数据库中。
### 5.3.2 监控网站可用性的实现
PycURL可以用于监控网站的可用性,例如定期检查网站是否在线,响应时间是否正常。
#### 网站可用性检查脚本
以下是一个简单的网站可用性检查脚本:
```python
import pycurl
import time
def check_website(url):
start_time = time.time()
with pycurl.Curl() as c:
c.setopt(c.URL, url)
c.setopt(c.NOPROGRESS, 1)
c.perform()
end_time = time.time()
response_time = end_time - start_time
if response_time < 1:
print(f'{url} is online and response time is {response_time:.2f}s')
else:
print(f'{url} is offline or response time is too slow')
# 示例:检查网站可用性
urls = ['***', '***']
for url in urls:
check_website(url)
time.sleep(1) # 间隔一秒检查下一个网站
```
#### 代码逻辑解读分析
- **定义函数**:定义一个`check_website`函数,接受URL作为参数。
- **执行PycURL请求**:使用PycURL发送请求,并记录开始和结束时间。
- **计算响应时间**:计算响应时间,并判断网站是否在线。
在本章节中,我们介绍了PycURL在网络爬虫、数据处理和自动化监控系统中的应用。通过具体的代码示例和逻辑分析,我们展示了如何使用PycURL进行网页抓取、处理反爬虫机制、下载数据到本地、数据清洗、自动化更新数据和监控网站可用性等操作。PycURL作为一个强大的网络请求库,能够有效地应用于各种实际项目中,提高开发效率和程序性能。
# 5. PycURL在实际项目中的应用
PycURL作为一个强大的库,不仅在简单的网络请求操作中有出色的表现,它在实际项目中的应用更是广泛而深入。在本章节中,我们将探讨PycURL在三个主要场景中的应用:网络爬虫、数据处理和分析以及自动化任务和监控系统。
## 5.1 网络爬虫中的应用
网络爬虫是互联网数据采集的一种常见方式,它自动化地访问网页并提取所需信息。PycURL在这一领域扮演着重要的角色,特别是在处理复杂的网页抓取任务时。
### 5.1.1 使用PycURL进行网页抓取
PycURL可以模拟浏览器的行为,发送HTTP请求并接收响应。与Python标准库中的`urllib`相比,PycURL更加灵活,支持更多的功能和更复杂的请求设置。
```python
import pycurl
from io import BytesIO
buffer = BytesIO()
c = pycurl.Curl()
c.setopt(c.URL, '***')
c.setopt(c.WRITEDATA, buffer)
c.perform()
c.close()
# 获取响应内容
html_content = buffer.getvalue()
print(html_content)
```
在上述代码中,我们使用PycURL发送一个GET请求到`***`,并捕获响应内容。`setopt`方法用于设置请求选项,`perform`方法执行请求,`close`方法关闭连接。通过这种方式,我们可以轻松地抓取网页内容。
### 5.1.2 处理反爬虫机制的技巧
许多网站实施了反爬虫机制,如检查User-Agent、使用Cookies、实施IP封锁等。PycURL通过提供自定义请求头部和Cookie处理的能力,帮助我们更好地应对这些挑战。
```python
from pycurl import Curl, HTTPHEADER, FOLLOWLOCATION
c = Curl()
c.setopt(c.URL, '***')
c.setopt(c.HTTPHEADER, ['User-Agent: Custom Browser'])
c.setopt(c.COOKIEFILE, 'cookies.txt')
c.setopt(c.FOLLOWLOCATION, True)
c.setopt(c.MAXREDIRS, 5)
c.perform()
# 检查是否跟随了重定向
print('HTTP response:', c.getinfo(c.HTTP_CODE))
```
在这个例子中,我们设置了自定义的User-Agent和Cookie文件,以及开启了重定向跟踪。通过这些设置,我们可以更好地模拟真实用户的行为,绕过一些基本的反爬虫检查。
## 5.2 数据处理和分析
数据处理和分析是PycURL的另一个重要应用领域。它可以帮助我们从网络上下载大量数据到本地进行进一步的分析。
### 5.2.1 从网络下载数据到本地
PycURL可以高效地下载大型文件,这对于数据采集工作来说非常有用。我们可以将下载的数据直接保存到磁盘或内存中。
```python
import pycurl
from io import BytesIO
url = '***'
buffer = BytesIO()
c = pycurl.Curl()
c.setopt(c.URL, url)
c.setopt(c.WRITEDATA, buffer)
c.perform()
c.close()
# 将数据写入文件
with open('largefile.zip', 'wb') as f:
f.write(buffer.getvalue())
```
在这个例子中,我们下载了一个大型的ZIP文件,并将其保存到了本地文件系统中。我们使用了内存缓冲区`BytesIO`来暂存下载的数据,然后将其写入到磁盘。
### 5.2.2 数据清洗和预处理
下载数据后,通常需要进行清洗和预处理。这可能包括解压缩文件、解析文件内容、过滤无效数据等。
```python
import zipfile
# 解压缩下载的ZIP文件
with zipfile.ZipFile('largefile.zip', 'r') as zip_ref:
zip_ref.extractall('data')
```
在这个例子中,我们使用`zipfile`模块解压了下载的ZIP文件,并将其内容解压到本地目录中。这是数据预处理的一个常见步骤。
## 5.3 自动化任务和监控系统
自动化任务和监控系统是PycURL的另一个重要的应用领域。它可以帮助我们自动化地执行各种网络相关的任务。
### 5.3.1 使用PycURL自动化更新数据
我们可以通过设置定时任务,使用PycURL定期下载最新的数据,从而保持本地数据的时效性。
### 5.3.2 监控网站可用性的实现
PycURL还可以用于监控网站的可用性。我们可以定期检查网站是否正常响应,并在出现故障时触发警报。
```python
import pycurl
from time import sleep
def check_website(url, interval):
while True:
c = pycurl.Curl()
c.setopt(c.URL, url)
c.setopt(c.NOSIGNAL, 1)
c.perform()
status = c.getinfo(c.HTTP_CODE)
if status != 200:
print(f'Website {url} is down!')
c.close()
sleep(interval)
# 每5分钟检查一次网站
check_website('***', 300)
```
在这个例子中,我们定义了一个函数`check_website`,它会定期检查指定网站的HTTP状态码。如果网站不可用,它会打印出一个警告信息。
在本章节中,我们介绍了PycURL在实际项目中的三种应用:网络爬虫、数据处理和分析以及自动化任务和监控系统。通过具体的代码示例和逻辑分析,我们展示了PycURL如何在这些场景中发挥作用。这些应用案例不仅展示了PycURL的强大功能,也为我们提供了将PycURL集成到自己项目中的思路。
# 6. PycURL进阶功能和性能调优
## 6.1 进阶功能探讨
### 6.1.1 HTTPS加密传输的处理
PycURL支持HTTPS协议,这意味着你可以安全地传输敏感数据。要启用HTTPS支持,你需要安装OpenSSL库,并在初始化PycURL时指定证书。以下是示例代码:
```python
import pycurl
from io import BytesIO
buffer = BytesIO()
c = pycurl.Curl()
c.setopt(c.URL, '***')
c.setopt(c.CERTINFO, True)
c.setopt(c.WRITEDATA, buffer)
c.perform()
response = buffer.getvalue().decode('utf-8')
print(response)
```
在这段代码中,我们通过设置`CERTINFO`选项为True来获取SSL证书信息。`WRITEDATA`选项用于指定写入数据的缓冲区。执行后,你可以从`buffer`中读取响应内容。
### 6.1.2 使用代理和负载均衡
为了提高效率和匿名性,PycURL支持使用HTTP代理。同时,通过设置多个代理,可以实现简单的负载均衡。以下是如何配置HTTP代理的示例:
```python
c = pycurl.Curl()
c.setopt(c.PROXY, '***')
c.setopt(c.PROXYPORT, 8080)
c.setopt(c.PROXYTYPE, pycurl.PROXYTYPE_SOCKS5_HOSTNAME)
```
在这段代码中,我们设置了代理服务器地址、端口和代理类型(SOCKS5通过主机名)。如果需要负载均衡,你可以在多个Curl对象之间共享相同的请求配置,并在它们之间分配任务。
## 6.2 性能调优实践
### 6.2.1 并发下载和上传的性能优化
PycURL支持并发请求,这可以通过使用`pycurl.threadpool`或`pycurl.concurrent`模块来实现。以下是一个使用线程池并发下载的示例:
```python
import pycurl
from pycurl import ThreadedCurlPool
from io import BytesIO
import threading
def download(url, buffer, index):
c = pycurl.Curl()
c.setopt(c.URL, url)
c.setopt(c.WRITEDATA, buffer)
c.perform()
print(f"Downloaded {url} to buffer {index}")
def main():
pool = ThreadedCurlPool()
urls = ['***', '***', '***']
buffers = [BytesIO() for _ in urls]
threads = []
for i, url in enumerate(urls):
t = threading.Thread(target=download, args=(url, buffers[i], i))
threads.append(t)
t.start()
for t in threads:
t.join()
for buffer in buffers:
print(buffer.getvalue().decode('utf-8'))
if __name__ == '__main__':
main()
```
在这个例子中,我们创建了一个线程池,并为每个URL分配了一个线程来并发下载文件。
### 6.2.2 内存和CPU资源的高效利用
为了高效地使用内存和CPU资源,你需要优化PycURL的设置和请求的处理方式。例如,设置合理的连接超时和读取超时,以及使用合适的缓冲区大小。以下是一些优化内存使用的建议:
- 使用`CURLOPT_TIMEOUT`和`CURLOPT_CONNECTTIMEOUT`来设置超时。
- 使用`CURLOPT_MAXREDIRS`限制重定向次数。
- 使用`CURLOPT_BUFFERSIZE`设置合适的缓冲区大小。
```python
c = pycurl.Curl()
c.setopt(c.URL, '***')
c.setopt(c.TIMEOUT, 30)
c.setopt(c.CONNECTTIMEOUT, 10)
c.setopt(c.MAXREDIRS, 5)
c.setopt(c.BUFFERSIZE, 1024)
```
在这段代码中,我们设置了连接超时、读取超时、最大重定向次数和缓冲区大小。
## 6.3 案例分析:真实世界的PycURL应用
### 6.3.1 大型项目中的PycURL应用实例
在一个大型项目中,PycURL可以用于高效地处理大量的网络请求。例如,在一个内容分发网络(CDN)监控系统中,PycURL可以用来定期检查各个节点的健康状态。以下是一个简化的示例:
```python
import pycurl
import threading
class CDNChecker:
def __init__(self, url, interval):
self.url = url
self.interval = interval
self.c = pycurl.Curl()
self.is_running = True
def check(self):
while self.is_running:
try:
response = self.c.perform().decode('utf-8')
if response.status == 200:
print(f"{self.url} is up!")
except Exception as e:
print(f"Error checking {self.url}: {e}")
time.sleep(self.interval)
def stop(self):
self.is_running = False
self.c.close()
def main():
urls = ['***', '***', '***']
checkers = []
for url in urls:
checker = CDNChecker(url, 60)
checker.start()
checkers.append(checker)
# Run for a while, then stop checking
time.sleep(300)
for checker in checkers:
checker.stop()
checker.join()
if __name__ == '__main__':
main()
```
在这个例子中,我们创建了一个`CDNChecker`类,它定期检查CDN节点的健康状态。我们使用线程来并发检查多个节点。
### 6.3.2 性能问题的诊断和解决方案
诊断PycURL性能问题通常涉及监控请求的响应时间和资源使用情况。以下是使用`pycurl`和`psutil`库来监控请求时间和内存使用的示例:
```python
import pycurl
import psutil
import time
def perform_request(url):
c = pycurl.Curl()
c.setopt(c.URL, url)
c.perform()
c.close()
def main():
url = '***'
proc = psutil.Process()
start_mem = proc.memory_info().rss
start_time = time.time()
perform_request(url)
end_time = time.time()
end_mem = proc.memory_info().rss
elapsed_time = end_time - start_time
print(f"Request took {elapsed_time} seconds.")
print(f"Memory usage increased by {end_mem - start_mem} bytes.")
if __name__ == '__main__':
main()
```
在这个例子中,我们监控了单个请求的执行时间和内存使用情况。这可以帮助识别是否存在内存泄漏或性能瓶颈。
以上是第六章的内容,希望对你有所帮助。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**PycURL库精通指南**
本专栏是一个全面的指南,旨在帮助您掌握PycURL库,这是一个强大的Python库,用于处理网络请求。通过一系列深入的文章,您将学习:
* PycURL的基本概念和高级应用技巧
* 文件上传和下载的有效策略
* PycURL与requests库的比较,以选择最佳的网络请求库
* 处理网络请求异常的最佳实践
* 优化PycURL性能的实用技巧
* 确保数据传输安全的安全性措施
* 使用PycURL进行自动化API测试
* 从网络响应中提取有用信息
* 使用PycURL构建和调用RESTful服务
* 在Web爬虫中使用PycURL的策略
无论您是网络开发新手还是经验丰富的专业人士,本专栏都将为您提供掌握PycURL并有效处理网络请求所需的知识和技能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Distutils Spawn与setuptools的抉择:如何选择最佳模块分发工具

# 1. Python模块分发工具概述
Python作为一种广泛使用的编程语言,其模块分发工具对于确保代码的可复用性和可维护性至关重要。本章将概述Python模块分发工具的基本概念、历史发展以及它们在Python生态系统中的作用。
Python模块分发工具,如Distutils和setuptools,提供了一套标准化的机制,用于构建、打包和分发Py
docutils.nodes扩展开发:创建自定义插件与工具的7个步骤

# 1. docutils.nodes概述
## 1.1 docutils.nodes模块简介
`docutils.nodes`是Docutils库中的核心组件,提供了一种树状结构来表示文档内容。这个模块定义了各种节点类型,每个节点代表文档中的一个逻辑单元,例如
深入解析Piston.Handler:构建RESTful API的Pythonic方式的终极指南
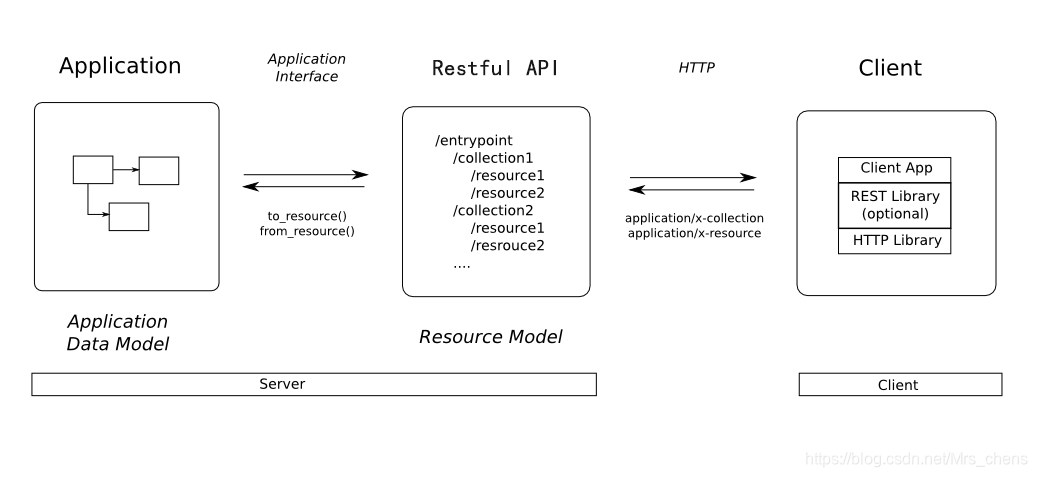
# 1. Piston.Handler简介与安装配置
## 简介
Piston.Handler是一个基于Py
Django 自定义模型字段:通过 django.db.models.sql.where 扩展字段类型

# 1. Django自定义模型字段概述
在Django框架中,模型字段是构成数据模型的基本组件,它们定义了数据库表中的列以及这些列的行为。在大多数情况下,Django提供的标准字段类型足以满足开发需求。然而,随着项目的复杂性和特定需求的增长,开发者可能需要自定义模型字段以扩展Django的功能或实现特
【Django意大利本地化应用】:选举代码与社会安全号码的django.contrib.localflavor.it.util模块应用

# 1. Django框架与本地化的重要性
## 1.1 Django框架的全球影响力
Django是一个高级的Python Web框架,它鼓励快速开发和干净、实用的设计。自2005年问世以来,它已经成为全球开发者社区的重要组成部分,支持着数以千计的网站和应用程序。
## 1.2 本地化在Django中的角色
本地化是软件国际化的一部分,它允许软件适应不同地区
【Django Admin验证与异步处理】:设计和实现异步验证机制的4大步骤

# 1. Django Admin验证与异步处理概述
Django Admin作为Django框架内置的后台管理系统,为开发者提供了便捷的数据管理接口。然而,在实际应用中,我们常常需要对数据的输入进行验证,确保数据的正确性和完整性。第一章将概述Django Admin的验证机制和异步处理的基本概念,为后续章节的深入探讨奠定基础。
## 2.1 Django Admi
Twisted.web.http自定义服务器:构建定制化网络服务的3大步骤
# 1. Twisted.web.http自定义服务器概述
## 1.1 Twisted.web.http简介
Twisted是一个事件驱动的网络框架,它允许开发者以非阻塞的方式处理网络事件,从而构建高性能的网络应用。Twisted.web.http是Twisted框架中处理HTTP协议的一个子模块,它提供了一套完整的API来构建HTTP服务器。通过使用Twisted.web.http,开发者可以轻松地创
【WebOb安全提升】:防御常见Web攻击的7大策略

# 1. WebOb与Web安全基础
## 1.1 WebOb的介绍
WebOb是一个Python库,它提供了一种用于访问和操作HTTP请求和响应对象的方式。它是WSGI标准的实现,允许开发人员编写独立于底层服务器的Web应用程序。WebOb的主要目的是简化HTTP请求和响应的处理,提供一个一致的接口来操作HTTP消息。
```python
from webob import Request
de
【Python库文件学习之odict】:数据可视化中的odict应用:最佳实践

# 1. odict基础介绍
## 1.1 odict是什么
`odict`,或有序字典,是一种在Python中实现的有序键值对存储结构。与普通的字典(`dict`)不同,`odict`保持了元素的插入顺序,这对于数据处理和分析尤为重要。当你需要记录数据的序列信息时,`odict`提供了一种既方便又高效的解决方案。
## 1.2 为什么使用odict
在数据处理中,我们经常需要保
Cairo性能优化秘籍:提升图形绘制性能的策略与实践

# 1. Cairo图形库概述
Cairo图形库是一个开源的2D矢量图形库,它提供了丰富的API来绘制矢量图形,支持多种输出后端,包括X Window System、Win32、Quartz、BeOS、OS/2和DirectFB。Cairo不仅能够高效地渲染高质量的图形,还支持高级特性,如抗锯齿、透明度处理和复杂的变换操作。
Cairo的设计哲学注重于可移植性和
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )