PycURL在Web爬虫中的角色:高效爬取网页数据的策略
发布时间: 2024-10-15 21:47:17 阅读量: 16 订阅数: 27 

# 1. PycURL简介与安装
## 1.1 PycURL简介
PycURL是一个用于发送HTTP请求的Python模块,它是libcurl的Python接口。libcurl是一个功能强大的、客户端的URL传输库,支持多种协议如HTTP、HTTPS、FTP等,并且具有丰富的配置选项。PycURL继承了这些特性,允许Python程序以简洁的方式执行复杂的网络请求。
## 1.2 安装PycURL
安装PycURL可以使用pip工具进行安装,打开终端或命令提示符,输入以下命令:
```bash
pip install pycurl
```
这个命令会自动下载并安装PycURL模块及其依赖项。安装完成后,你可以通过编写简单的Python代码来验证PycURL是否安装成功。
```python
import pycurl
from io import BytesIO
buffer = BytesIO()
c = pycurl.Curl()
c.setopt(c.URL, '***')
c.setopt(c.WRITEDATA, buffer)
c.perform()
c.close()
body = buffer.getvalue()
print(body.decode('utf-8'))
```
执行上述代码,如果输出了HTTP GET请求的响应内容,说明PycURL已经成功安装。
# 2. PycURL基础操作与数据处理
### 2.1 PycURL的基本使用
#### 2.1.1 初始化PycURL会话
在本章节中,我们将介绍如何使用PycURL库进行网络请求的基本操作。PycURL是一个强大的库,它使用libcurl的Python接口,允许用户发送各种类型的网络请求,并处理相应的响应。
首先,我们需要导入PycURL库,并初始化一个PycURL会话。以下是一个简单的示例代码,展示了如何创建一个新的会话:
```python
import pycurl
from io import BytesIO
# 创建一个新的PycURL会话对象
c = pycurl.Curl()
# 使用BytesIO对象作为响应数据的接收缓冲区
buffer = BytesIO()
# 设置请求的URL
c.setopt(pycurl.URL, '***')
# 设置接收响应数据的缓冲区
c.setopt(pycurl.WRITEFUNCTION, buffer.write)
# 执行请求
c.perform()
# 关闭会话
c.close()
# 打印响应数据
print(buffer.getvalue().decode('utf-8'))
```
在这个示例中,我们首先导入了必要的模块,然后创建了一个新的PycURL会话对象。我们使用`setopt`方法设置了请求的URL和接收响应数据的缓冲区。`WRITEFUNCTION`选项用于指定一个回调函数,这个函数会在数据被写入时被调用。最后,我们执行请求,并打印出响应数据。
#### 2.1.2 发送请求与接收响应
发送HTTP请求并接收响应是PycURL的基本功能。我们可以通过设置不同的选项来发送GET、POST、PUT等类型的请求,并处理服务器的响应。
以下是一个发送GET请求并打印响应头的示例代码:
```python
import pycurl
from io import BytesIO
# 创建一个新的PycURL会话对象
c = pycurl.Curl()
# 创建一个字典用于存储响应头信息
response_headers = {}
# 设置请求的URL
c.setopt(pycurl.URL, '***')
# 设置接收响应数据的缓冲区
c.setopt(pycurl.WRITEFUNCTION, buffer.write)
# 设置响应头信息的回调函数
def header_callback(header_line):
header = header_line.decode('utf-8')
header_name, header_value = header.split(':', 1)
response_headers[header_name.lower()] = header_value.strip()
c.setopt(pycurl.HEADERFUNCTION, header_callback)
# 执行请求
c.perform()
# 关闭会话
c.close()
# 打印响应头信息
for header, value in response_headers.items():
print(f'{header}: {value}')
# 打印响应数据
print(buffer.getvalue().decode('utf-8'))
```
在这个示例中,我们使用了一个额外的回调函数`header_callback`来处理响应头信息。我们设置了`HEADERFUNCTION`选项,当响应头被接收时,这个回调函数会被调用。然后,我们打印出所有的响应头信息和响应数据。
### 2.2 PycURL的数据处理
#### 2.2.1 响应数据的解析
处理和解析响应数据是网络请求中的一个重要步骤。PycURL提供了多种方式来处理不同类型的数据。
以下是一个解析JSON响应数据的示例代码:
```python
import pycurl
import json
# 创建一个新的PycURL会话对象
c = pycurl.Curl()
# 创建一个字典用于存储响应数据
response_data = {}
# 设置请求的URL
c.setopt(pycurl.URL, '***')
# 设置接收响应数据的缓冲区
c.setopt(pycurl.WRITEFUNCTION, buffer.write)
# 设置响应数据解析回调函数
def parse_response(data):
global response_data
response_data = json.loads(data.decode('utf-8'))
c.setopt(pycurl.WRITEFUNCTION, parse_response)
# 执行请求
c.perform()
# 关闭会话
c.close()
# 打印解析后的响应数据
print(response_data)
```
在这个示例中,我们定义了一个回调函数`parse_response`来解析JSON格式的响应数据。我们使用`json.loads`方法将JSON字符串转换为Python字典,并存储在全局变量`response_data`中。
#### 2.2.2 数据编码和解码
在进行网络请求时,有时需要对发送的数据进行编码,或者对响应数据进行解码。PycURL提供了选项来设置数据的编码和解码方式。
以下是一个编码POST请求数据并解码响应数据的示例代码:
```python
import pycurl
import json
# 创建一个新的PycURL会话对象
c = pycurl.Curl()
# 设置请求的URL
c.setopt(pycurl.URL, '***')
# 设置发送POST请求的数据
post_data = {'key': 'value'}
c.setopt(pycurl.POSTFIELDS, json.dumps(post_data))
# 设置响应数据的解码方式
c.setopt(pycurl.WRITEFUNCTION, buffer.write)
# 设置内容类型头部
c.setopt(pycurl.HTTPHEADER, ['Content-Type: application/json'])
# 执行请求
c.perform()
# 关闭会话
c.close()
# 打印响应数据
print(buffer.getvalue().decode('utf-8'))
```
在这个示例中,我们使用了`POSTFIELDS`选项来设置发送的POST数据,并设置了`HTTPHEADER`选项来指定内容类型为JSON。服务器返回的响应数据默认是解码后的字符串。
### 2.3 错误处理与异常管理
#### 2.3.1 常见错误处理
PycURL在执行请求时可能会遇到各种错误,例如网络问题、超时或服务器错误。我们可以使用异常处理来捕获这些错误,并进行相应的处理。
以下是一个处理PycURL异常的示例代码:
```python
import pycurl
from io import BytesIO
import pycurl
try:
# 创建一个新的PycURL会话对象
c = pycurl.Curl()
# 设置请求的URL
c.setopt(pycurl.URL, '***')
# 设置接收响应数据的缓冲区
buffer = BytesIO()
c.setopt(pycurl.WRITEFUNCTION, buffer.write)
# 执行请求
c.perform()
# 关闭会话
c.close()
# 打印响应数据
print(buffer.getvalue().decode('utf-8'))
except pycurl.error as e:
print(f"PycURL error: {e}")
```
在这个示例中,我们使用了`try-except`块来捕获`pycurl.error`异常。如果在执行请求时遇到错误,异常会被捕获,并打印出错误信息。
#### 2.3.2 异常捕获与日志记录
为了更好地调试和监控PycURL请求,我们可以将异常信息记录到日志文件中。这有助于我们分析请求失败的原因。
以下是一个记录PycURL异常的日志的示例代码:
```python
import pycurl
from io import BytesIO
import pycurl
import l
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**PycURL库精通指南**
本专栏是一个全面的指南,旨在帮助您掌握PycURL库,这是一个强大的Python库,用于处理网络请求。通过一系列深入的文章,您将学习:
* PycURL的基本概念和高级应用技巧
* 文件上传和下载的有效策略
* PycURL与requests库的比较,以选择最佳的网络请求库
* 处理网络请求异常的最佳实践
* 优化PycURL性能的实用技巧
* 确保数据传输安全的安全性措施
* 使用PycURL进行自动化API测试
* 从网络响应中提取有用信息
* 使用PycURL构建和调用RESTful服务
* 在Web爬虫中使用PycURL的策略
无论您是网络开发新手还是经验丰富的专业人士,本专栏都将为您提供掌握PycURL并有效处理网络请求所需的知识和技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【微分环节深度解析】:揭秘控制系统中的微分控制优化
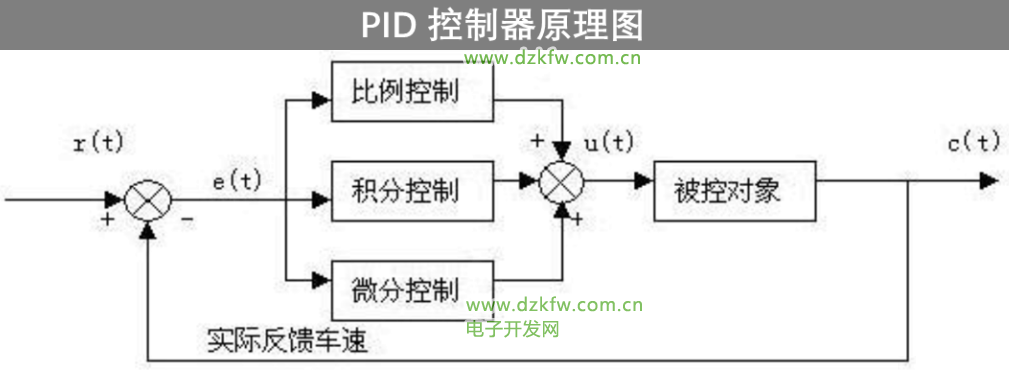
# 摘要
本文深入探讨了微分控制理论及其在控制系统中的应用,包括微分控制的基本概念、数学模型、理论作用和与其他控制环节的配合。通过对微分控制参数的分析与优化,本文阐述了如何调整微分增益和时间参数来改善系统响应和稳定性,减少超调和振荡。实践应用案例部分展示了微分控制在工业自动化和现代科技,如机器人控制及自动驾驶系统中的重要性。最后,本文展望了微分控制技术的未来发展与挑战,包括人工智能的融合和系
【OpenCV 4.10.0 CUDA配置秘籍】:从零开始打造超快图像处理环境

# 摘要
本文旨在介绍OpenCV CUDA技术在图像处理领域的应用,概述了CUDA基础、安装、集成以及优化策略,并详细探讨了CUDA加速图像处理技术和实践。文中不仅解释了CUDA在图像处理中的核心概念、内存管理、并行算法和性能调优技巧,还涉及了CUDA流与异步处理的高级技术,并展望了CUDA与深度学习结
【Romax高级功能】揭秘隐藏宝藏:深度解读与实战技巧

# 摘要
本文全面介绍了Romax软件的高级功能,从核心组件的深度剖析到高级功能的实际应用案例分析。文章首先概述了Romax的高级功能,然后详细解析了其核心组件,包括计算引擎、仿真模块和数据分析工具的工作原理及优化方法。在实战应用章节,讨论了参数化设计、多目标优化以及自动化测试与报告生成的具体应用和技
【iStylePDF深度解析】:功能特性与高效操作技巧揭秘
# 摘要
iStylePDF是一款集成了丰富功能的PDF编辑软件,旨在通过直观的界面和高效的文件处理技术提高用户操作的便捷性。本文详细介绍了iStylePDF的核心功能和工作原理,包括用户界面布局、操作流程、文件转换与高级编辑功能,以及格式支持与兼容性。文章还探讨了实用操作技巧,如编辑效率提升、PDF优化与压缩、内容安全性增强等。进一步地,本文分析了i
【Linux新手必备】:一步到位,快速安装Firefox ESR 78.6

# 摘要
本文旨在全面介绍Linux系统及其环境的配置和优化,同时深入探讨Firefox ESR的特点、安装和高级配置。首先,文章提供了Linux系统的基础知识以及如何进行有效配置和性能调优。接着,详细阐述了Firefox ESR的定位、主要功能及其对企业用户的适用性。文章还介绍了如何在Linux环境中一步到位地安装Firefox ESR 78.6,包括环境准备
高效算法构建指南:掌握栈、队列与树结构的实战应用
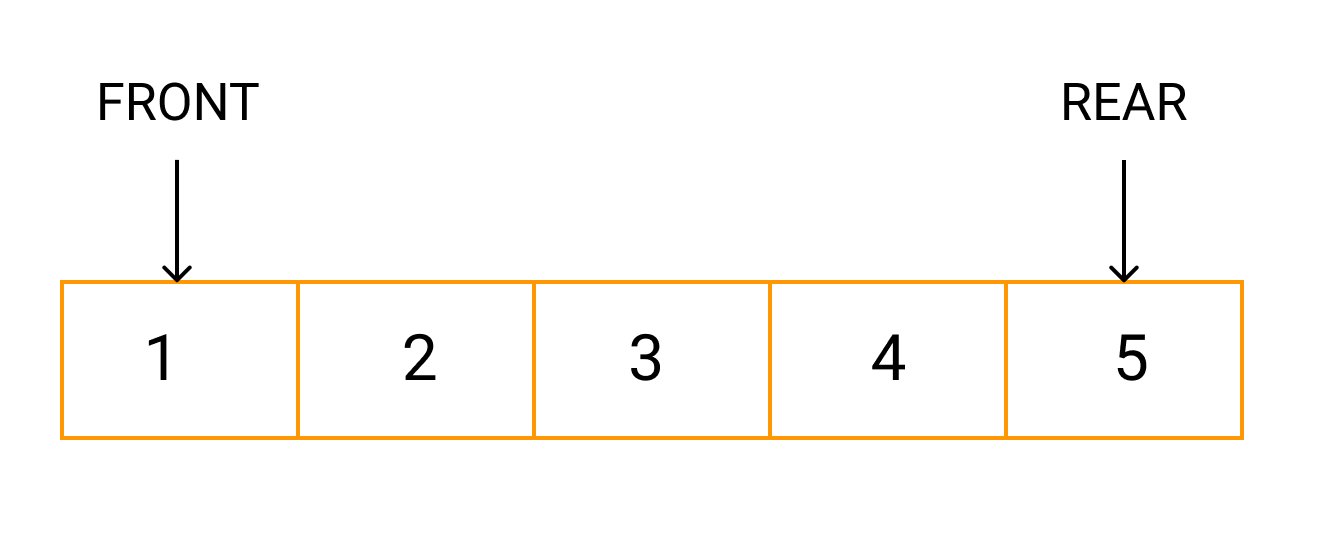
# 摘要
本文全面介绍了数据结构的基础知识,并深入探讨了栈和队列在理论与实践中的应用,包括其基本操作、性质以及算法实例。接着,文章深入分析了树结构的构建与遍历,二叉搜索树的原理及平衡树和堆结构的高级应用。此外,本文还论述了高效算法设计技巧,如算法复杂度分析、贪心算法与动态规划,以及分治法与回溯算法。最后,文章通过实际案例分析展示了数据结构在大数据处理、网络编程和算法优化中的应用。本文旨在为读者提供一份全面的数据结构知识
【提升控制器性能】LBMC072202HA2X-M2-D高级配置技巧:稳定与速度的双重秘诀

# 摘要
本文对LBMC072202HA2X-M2-D控制器进行了全面介绍,并探讨了性能稳定性的理论基础及实际意义。通过对稳定性定义、关键影响因素的理论分析和实际应用差异的探讨,提供了控制器稳定性的理论模型与评估标准。同时,文章深入分析了性能加速的理论基础和实现策略,包括硬件优化和软件调优技巧。在高级配置实践
MAC地址自动化攻略:Windows批处理脚本快速入门指南
# 摘要
本文详细探讨了MAC地址与Windows批处理技术的集成应用。首先介绍了MAC地址的基本概念及Windows批处理脚本的编写基础,然后深入分析了通过批处理实现MAC地址管理自动化的方法,包括查询、修改和安全策略的自动化配置。接着,文章通过实践案例展示了批处理脚本在企业网络中的应用,并分享了高级技巧,如网络监控、异常处理和性能优化。最后,本文对批处理脚本的安全性进行了分析,并展望了批处
KEPServerEX案例研究:如何通过Datalogger功能提升数据采集效率
# 摘要
本论文旨在深入探讨KEPServerEX和Datalogger在数据采集领域中的应用及其优化策略。首先概述了KEPServerEX和Datalogger的核心功能,然后着重分析Datalogger在数据采集中的关键作用,包括其工作原理及与其它数据采集方法的对比。接着,论文详细介绍了如何配置KEPServerEX以
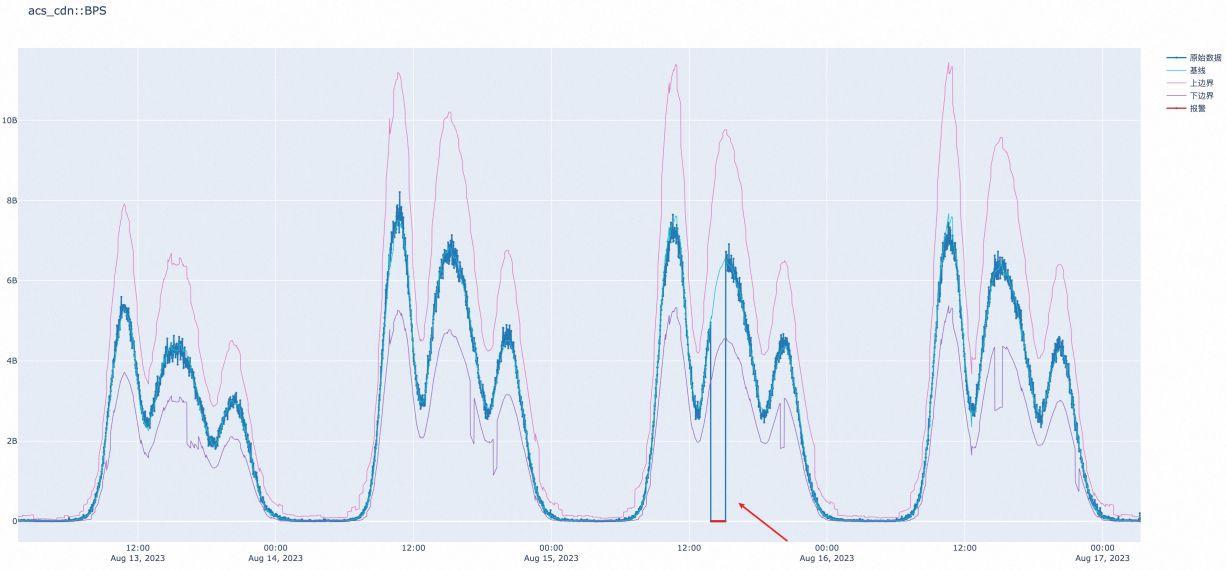
【系统性能监控】:构建24_7高效监控体系的10大技巧
# 摘要
系统性能监控是确保信息系统的稳定运行和高效管理的关键环节。本文从基础知识出发,详细阐述了监控体系的设计原则、工具的选择与部署、数据的收集与分析等构建要素。在监控实践章节中,本文进一步探讨了实时性能监控技术、性能问题诊断与定位以及数据可视化展示的关键技巧。此外,本文还讨论了自动化与智能化监控实践,包括自动化流程设计、智能监控算法的应用,以及监控体系的维护与
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )