hive数据模型与数据类型
发布时间: 2024-01-10 23:14:13 阅读量: 22 订阅数: 23 
# 1. 简介
## 1.1 什么是Hive
Hive是一个基于Hadoop的数据仓库基础设施,它提供了类似于SQL的查询语言HiveQL,使得使用者可以通过编写SQL-like的查询语句来操作存储在Hadoop上的大型数据集。Hive的设计目标是提供简单、可扩展、容错和高性能的数据仓库解决方案。
## 1.2 Hive的数据模型概述
Hive的数据模型是基于表的数据模型,它把数据组织成多个表,每个表包含行和列,每个列都有一个相应的数据类型。Hive的表可以基于文件存储在Hadoop分布式文件系统(HDFS)上,也可以使用其他存储系统,如Amazon S3、HBase等。
## 1.3 Hive与传统关系型数据库的区别
Hive与传统关系型数据库在数据模型和查询语言上有一些区别。首先,Hive的数据模型是基于表的,而传统关系型数据库的数据模型是基于关系模型。其次,Hive使用类似于SQL的查询语言HiveQL,但与传统SQL有一些语法和语义上的差异。
另外,Hive在查询处理上采用了延迟执行的方式,即查询语句被转换为逻辑执行计划后不立即执行,而是在需要查询结果时再进行计算。这种设计可以提高查询的效率和灵活性,但也会导致一定的延迟。
总的来说,Hive适用于大规模数据处理和分析,而传统关系型数据库更适用于事务处理和实时查询等场景。Hive主要关注的是数据的批处理和离线分析,而传统关系型数据库则更注重数据的持久性和即时性。
# 2. Hive数据模型
Hive的数据模型是基于表的概念进行构建的,类似于传统的关系型数据库。在Hive中,表是数据的基本存储单位,它可以由一系列列和行组成。下面将介绍Hive数据模型的几个重要概念:表的概念与创建、分区与分桶、存储格式与压缩方式。
### 2.1 表的概念与创建
在Hive中,表是数据的逻辑视图,它可以由用户按照自己的需求进行创建和管理。表由一系列列和行组成,每列可以定义不同的数据类型。创建表的语法如下:
```sql
CREATE TABLE table_name (
column1 data_type,
column2 data_type,
...
)
```
其中,`table_name`是表的名称,`column1`、`column2`等是表的列名,`data_type`是列的数据类型。例如,我们可以创建一个名为`students`的表,包含学生的姓名、年龄和性别:
```sql
CREATE TABLE students (
name STRING,
age INT,
gender STRING
)
```
### 2.2 分区与分桶
在处理大规模数据时,分区和分桶是优化查询性能的重要手段。分区是将表中的数据按照某个字段进行划分,可以提高查询的效率。分桶是将分区后的数据再进行细分划分,可以进一步提高查询效率。
Hive使用分区和分桶可以对表的数据进行组织和管理。分区可以根据数据的某个字段(例如日期)进行划分,而分桶则是对分区后的数据再进行进一步划分。
分区的创建可以通过`PARTITIONED BY`关键字指定分区字段,例如:
```sql
CREATE TABLE logs (
date STRING,
time STRING,
log_message STRING
)
PARTITIONED BY (date)
```
分桶的创建可以通过`CLUSTERED BY`和`SORTED BY`关键字指定分桶字段和排序字段,例如:
```sql
CREATE TABLE user_data (
user_id INT,
user_name STRING,
user_age INT
)
CLUSTERED BY (user_id) SORTED BY (user_age) INTO 256 BUCKETS
```
### 2.3 存储格式与压缩方式
存储格式和压缩方式是对数据进行物理存储和压缩的方法。Hive支持多种存储格式和压缩方式,可以根据数据的特点和需求选择合适的方式。
常见的存储格式包括文本格式(TextFile)、序列化格式(SequenceFile)、Parquet、ORC等。文本格式是最常见的存储格式,易于读写和调试,但效率较低。Parquet和ORC是列式存储格式,具有较高的压缩比和查询效率。
压缩方式包括Gzip、Snappy、LZO等。不同的压缩方式在压缩比和解压缩速度上有所差异,可以根据数据的特点选择合适的压缩方式。
在创建表时,可以使用`STORED AS`关键字指定存储格式和压缩方式,例如:
```sql
CREATE TABLE orders (...)
STORED AS Parquet
```
```sql
CREATE TABLE logs (...)
STORED AS TextFile
```
```sql
CREATE TABLE user_data (...)
STORED AS ORC
```
综上所述,Hive的数据模型包含了表的概念与创建、分区与分桶、存储格式与压缩方式等要素。通过合理地使用这些特性,可以提高Hive查询的性能和效率。下一章节将介绍Hive的数据类型,与关系型数据库进行对比。
# 3. Hive数据类型
Hive提供了丰富的数据类型来支持不同类型的数据存储和查询。在Hive中,数据类型可以分为基本数据类型、复合数据类型和集合数据类型。
#### 3.1 基本数据类型
Hive的基本数据类型包括:
- TINYINT: 8位整数
- SMALLINT: 16位整数
- INT: 32位整数
- BIGINT: 64位整数
- FLOAT: 单精度浮点数
- DOUBLE: 双精度浮点数
- BOOLEAN: 布尔值(true或false)
- STRING: 字符串
- VARCHAR: 可变长度字符串
- CHAR: 定长字符串
- DATE: 日期类型(YYYY-MM-DD)
- TIMESTAMP: 时间戳类型(YYYY-MM-DD HH:MM:SS)
#### 3.2 复合数据类型
Hive的复合数据类型包括:
- STRUCT: 结构体,由多个不同类型的字段组成
- MAP: 键值对,由多个键值对组成
- ARRAY: 数组,由多个相同类型的元素组成
#### 3.3 集合数据类型
Hive的集合数据类型包括:
- ARRAY: 数组类型,用于存储一个元素集合
- MAP: 键值对类型,用于存储键值对集合
- STRUCT: 结构体类型,用于存储多个字段的集合
这些数据类型可以按需进行组合和嵌套,以满足不同场景下的数据存储和查询需求。
以下是使用Hive数据类型的示例:
```SQL
-- 创建一个包含复合数据类型的表
CREATE TABLE employees (
id INT,
name STRING,
address STRUCT<street:STRING, city:STRING, state:STRING, zipcode:INT>,
contacts ARRAY<STRUCT<type:STRING, value:STRING>>,
salary MAP<STRING, DOUBLE>
);
-- 插入数据
INSERT INTO employees
VALUES (1, 'John Doe', named_struct('street', '123 Main St', 'city', 'New York', 'state', 'NY', 'zipcode', 10001),
array(named_struct('type', 'email', 'value', 'john@example.com'), named_struct('type', 'phone', 'value', '123-456-7890')),
map('2022-01', 10000.00, '2022-02', 12000.00));
-- 查询数据
SELECT * FROM employees;
-- 结果如下:
+----+----------+----------------------------------------------------+-----------------------------------------------------------------+----------------------------------+
| id | name | address | contacts | salary |
+----+----------+----------------------------------------------------+-----------------------------------------------------------------+----------------------------------+
| 1 | John Doe | {"street":"123 Main St","city":"New York","state":NY,"zipcode":10001} | [{"type":"email","value":"john@example.com"},{"type":"phone","value":"123-456-7890"}] | {"2022-01":10000.0,"2022-02":12000.0} |
+----+----------+----------------------------------------------------+-----------------------------------------------------------------+----------------------------------+
```
以上示例展示了如何在Hive中创建一个包含复合数据类型的表,并插入数据。可以看到,Hive提供了灵活的数据类型来满足不同的数据存储需求。
# 4. Hive数据模型与数据类型的映射关系
在本章中,我们将探讨Hive数据模型与数据类型在实际应用中的映射关系。我们将分别对Hive数据模型中表与数据库的对应关系以及Hive数据类型与其他SQL数据库数据类型的映射进行详细讨论。
### 4.1 Hive数据模型中表与数据库的对应关系
在Hive中,一个数据库(Database)可以包含多张表(Table),类似于传统关系型数据库中的数据库与表的概念。在Hive中,数据库的概念主要用于组织和管理表,以及提供命名空间隔离。在实际使用中,我们可以通过Hive的SQL语句来创建数据库、切换数据库、查看数据库中的表等操作。
下面是一些常用的Hive数据库操作的示例代码:
```sql
-- 创建名为test_db的数据库
CREATE DATABASE IF NOT EXISTS test_db;
-- 切换到test_db数据库
USE test_db;
-- 展示当前数据库中的所有表
SHOW TABLES;
```
### 4.2 Hive数据类型与其他SQL数据库数据类型的映射
Hive数据类型与传统的SQL数据库数据类型之间存在一定的映射关系,在进行数据模型转换或数据迁移时,了解这些映射关系可以帮助我们更好地理解和使用Hive。下表列举了一些常见的Hive数据类型与其他SQL数据库数据类型的对应关系:
| Hive数据类型 | 其他SQL数据库数据类型 |
| ------------ | --------------------- |
| INT | INTEGER |
| STRING | VARCHAR, CHAR |
| BOOLEAN | BOOLEAN |
| FLOAT | FLOAT |
| DOUBLE | DOUBLE |
| TIMESTAMP | DATETIME, TIMESTAMP |
| ARRAY\<T> | ARRAY\<T> |
| MAP<K,V> | MAP<K,V> |
| STRUCT | STRUCT |
通过上表,我们可以清楚地看到Hive数据类型与其他SQL数据库数据类型之间的对应关系,这有助于我们在实际应用中进行数据模型的转换和使用。
在实际使用中,我们可以通过利用Hive的数据导入导出工具或者编写代码进行数据类型的转换和映射。下面是一个简单的示例,展示了如何在Hive中创建一个表并将其他SQL数据库中的数据导入到Hive表中:
```sql
-- 创建一个示例表
CREATE TABLE example_table (
id INT,
name STRING,
age INT
);
-- 从其他SQL数据库导入数据
INSERT INTO example_table
SELECT id, name, age
FROM other_sql_table;
```
通过以上示例,我们可以看到如何利用Hive表来映射其他SQL数据库的数据,进而实现数据的导入和导出操作。
在实际应用中,我们还可以根据具体的场景和需求对数据类型进行转换和处理,以满足特定的业务需求。
### 总结
通过本章的学习,我们更深入地了解了Hive数据模型与数据类型的映射关系。这对于我们在实际应用中进行数据模型转换、数据迁移以及数据处理操作非常有帮助。在后续的章节中,我们会通过实际案例来进一步探讨Hive数据模型与数据类型的使用方法。
希望读者通过本章的学习,对Hive数据模型与数据类型的映射关系有了更清晰的理解。
# 5. 数据模型与数据类型的使用案例
在本章中,我们将介绍使用Hive数据模型和数据类型的实际案例。我们会演示如何创建Hive表并插入数据,如何查询和筛选数据,以及如何对数据进行分区和分桶。同时,我们还会讨论如何进行数据格式转换和数据类型转换的操作。
### 5.1 创建Hive表并插入数据
首先,我们需要创建一个Hive表,并向其中插入一些数据。为了简单起见,假设我们要创建一个名为`employees`的表,用于存储员工的基本信息,包括员工ID、姓名、年龄和工资。
在Hive中,我们可以使用类似于SQL的语法来创建表。以下是一个示例DDL语句:
```sql
CREATE TABLE employees (
id INT,
name STRING,
age INT,
salary FLOAT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
```
上述语句定义了一个名为`employees`的表,它包含了四个列:`id`、`name`、`age`和`salary`。数据的分隔符是逗号,并且表的存储格式是文本文件。
接下来,我们可以使用INSERT语句向`employees`表中插入数据。以下是一个示例INSERT语句:
```sql
INSERT INTO TABLE employees
VALUES (1, 'John Smith', 30, 5000),
(2, 'Jane Doe', 28, 6000),
(3, 'Mike Johnson', 35, 7000);
```
上述语句将三条记录插入`employees`表中。
### 5.2 查询与筛选数据
一旦表和数据已经准备好,我们就可以使用Hive来查询和筛选数据了。在Hive中,我们可以使用类似于SQL的SELECT语句来实现。
以下是一个示例查询语句,用于检索`employees`表中的所有记录:
```sql
SELECT * FROM employees;
```
该语句将返回`employees`表中的所有记录。
除了查询所有数据外,我们还可以使用条件进行数据筛选。以下是一个示例查询语句,用于检索工资大于6000的员工记录:
```sql
SELECT * FROM employees WHERE salary > 6000;
```
### 5.3 对数据进行分区与分桶
在Hive中,我们可以使用分区和分桶的技术来提高数据查询的效率。
分区是指将数据按照某个列进行逻辑划分,并将每个分区单独存储在文件中。这样可以将数据划分为更小的块,从而加速查询。以下是一个示例创建分区表的DDL语句:
```sql
CREATE TABLE partitioned_employees (
id INT,
name STRING,
age INT,
salary FLOAT
)
PARTITIONED BY (department STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
```
上述语句创建了一个名为`partitioned_employees`的表,其中包含了额外的分区列`department`。
分桶是指将数据按照哈希函数的结果进行逻辑划分,并将划分后的数据放入不同的桶中。这样可以将数据更加均匀地分布在不同的桶中,进一步提高查询效率。以下是一个示例创建分桶表的DDL语句:
```sql
CREATE TABLE bucketed_employees (
id INT,
name STRING,
age INT,
salary FLOAT
)
CLUSTERED BY (id) INTO 4 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
```
上述语句创建了一个名为`bucketed_employees`的表,并按照`id`列进行分桶,共分成4个桶。
### 5.4 数据格式转换与数据类型转换
在实际应用中,我们可能需要对数据进行格式转换和类型转换。在Hive中,我们可以使用内置的函数来实现这些转换。
以下是一个示例查询语句,用于将`salary`列的数据转换为整型并进行筛选:
```sql
SELECT id, name, CAST(salary AS INT) FROM employees WHERE CAST(salary AS INT) > 6000;
```
上述语句使用`CAST`函数将`salary`列的数据转换为整型,并筛选出工资大于6000的记录。
除了数据格式转换外,我们还可以进行不同数据类型之间的转换。以下是一个示例查询语句,用于将`age`列的数据转换为字符串并进行筛选:
```sql
SELECT id, name, age, CAST(age AS STRING) FROM employees WHERE CAST(age AS STRING) = '30';
```
上述语句使用`CAST`函数将`age`列的数据转换为字符串,并筛选出年龄等于30的记录。
通过以上案例,我们展示了如何在Hive中使用数据模型和数据类型进行操作,并实现了一些常见的查询和转换操作。
## 总结与展望
本章中,我们详细介绍了使用Hive数据模型和数据类型的实际案例。我们学习了如何创建表、插入数据、查询数据、对数据进行分区和分桶,以及进行数据格式转换和数据类型转换的操作。
通过使用Hive的数据模型和数据类型,我们可以更方便地处理大数据,并充分利用Hive的高效查询和分析能力。
未来,随着大数据技术的不断发展,数据模型和数据类型的功能和性能将进一步提升。我们可以期待更多的新特性和优化,以满足不断增长的数据处理需求。
# 6. 总结与展望
Hive作为一种数据仓库工具,其数据模型和数据类型在大数据领域扮演着重要的角色。通过对Hive数据模型的理解与掌握,可以更好地进行数据存储和处理,从而为数据分析和数据挖掘提供更加便利的条件。
## 6.1 Hive数据模型与数据类型的优势
Hive的数据模型和数据类型具有以下优势:
- **灵活性**:Hive的数据模型可以适应不同类型和格式的数据,同时提供了丰富的数据类型,满足复杂数据存储需求。
- **扩展性**:Hive支持分区和分桶等数据划分方式,能够很好地应对大规模数据的存储和管理。
- **兼容性**:Hive的数据类型与其他SQL数据库的数据类型存在对应关系,便于用户在不同系统间进行数据迁移和集成。
- **性能优化**:Hive的存储格式和压缩方式能够对数据进行有效的压缩和加速查询,提升数据处理效率。
通过充分利用Hive的数据模型和数据类型的优势,可以更好地组织和管理数据,提高数据处理的效率和性能。
## 6.2 对未来的展望:数据模型与数据类型的发展趋势
随着大数据技术的不断发展,Hive的数据模型和数据类型也在不断地完善和发展。未来,我们可以期待以下方面的发展趋势:
- **更多数据类型的支持**:随着数据多样性的增加,Hive可能会增加更多复杂数据类型的支持,以满足更丰富的数据处理需求。
- **更高效的存储格式**:Hive可能会引入更高效的存储格式,如Parquet、ORC等,用于提升数据存储和查询的效率。
- **更智能的数据管理**:未来的Hive可能会提供更智能的数据管理功能,如数据自动化分区、智能压缩等,减少用户的手动操作,提升数据管理的便捷性。
总之,随着大数据技术的不断发展,可以预见Hive的数据模型和数据类型会朝着更加完善、高效和智能的方向发展,为用户提供更好的数据存储和处理体验。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《大数据之Hive详解》是一篇专栏,该专栏深入探讨了Hive在大数据处理中的重要性和使用方法。文章包含各个方面的主题,如Hive的数据模型与数据类型、数据查询与过滤、数据聚合与分组、表分区与分桶、数据存储格式、与Hadoop生态系统的集成等。此外,专栏还涉及了Hive表的设计与优化、动态分区与外部表、数据压缩与索引、与机器学习的结合、数据仓库与ETL、性能优化技巧以及数据安全与权限控制。同时,专栏还介绍了Hive中的高级函数、事件处理与触发器、与数据可视化工具的集成以及与实时数据处理的应用。通过这些文章,读者将全面了解Hive的各个方面,从而更好地应用它在大数据处理中的潜力。
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘MySQL数据库性能下降幕后真凶:提升数据库性能的10个秘诀

# 1. MySQL数据库性能下降的幕后真凶
MySQL数据库性能下降的原因多种多样,需要进行深入分析才能找出幕后真凶。常见的原因包括:
- **硬件资源不足:**CPU、内存、存储等硬件资源不足会导致数据库响应速度变慢。
- **数据库设计不合理:**数据表结构、索引设计不当会影响查询效率。
- **SQL语句不优化:**复杂的SQL语句、
云计算架构设计与最佳实践:从单体到微服务,构建高可用、可扩展的云架构

# 1. 云计算架构演进:从单体到微服务
云计算架构经历了从单体到微服务的演进过程。单体架构将所有应用程序组件打
Python在Linux下的安装路径在数据科学中的应用:在数据科学项目中优化Python环境
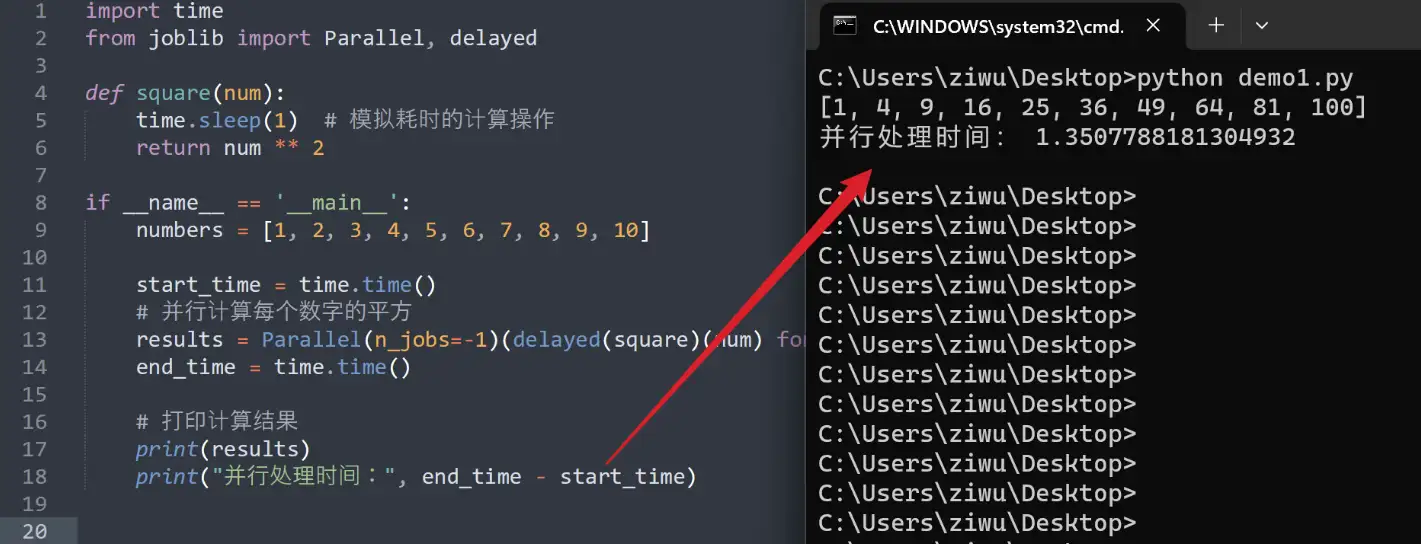
# 1. Python在Linux下的安装路径
Python在Linux系统中的安装路径因不同的Linux发行版和Python版本而异。一般情况下,Python解释器和库的默认安装路径为:
- **/usr/bin/python**:Python解释器可执行文件
- **/usr/lib/python3.X**:Python库的安装路径(X为Py
【进阶篇】数据可视化优化:Seaborn中的样式设置与调整

# 2.1 Seaborn的默认样式
Seaborn提供了多种默认样式,这些样式预先定义了图表的外观和感觉。默认样式包括:
- **darkgrid**:深色背景和网格线
- **whitegrid**:白色背景和网格线
- **dark**:深色背景,无网格线
- **white**:白色背景,无网格线
- **ticks**:仅显示刻度线,无网格线或背景
这些默认样
Python连接PostgreSQL机器学习与数据科学应用:解锁数据价值

# 1. Python连接PostgreSQL简介**
Python是一种广泛使用的编程语言,它提供了连接PostgreSQL数据库的
Python类方法与静态方法在金融科技中的应用:深入探究,提升金融服务效率
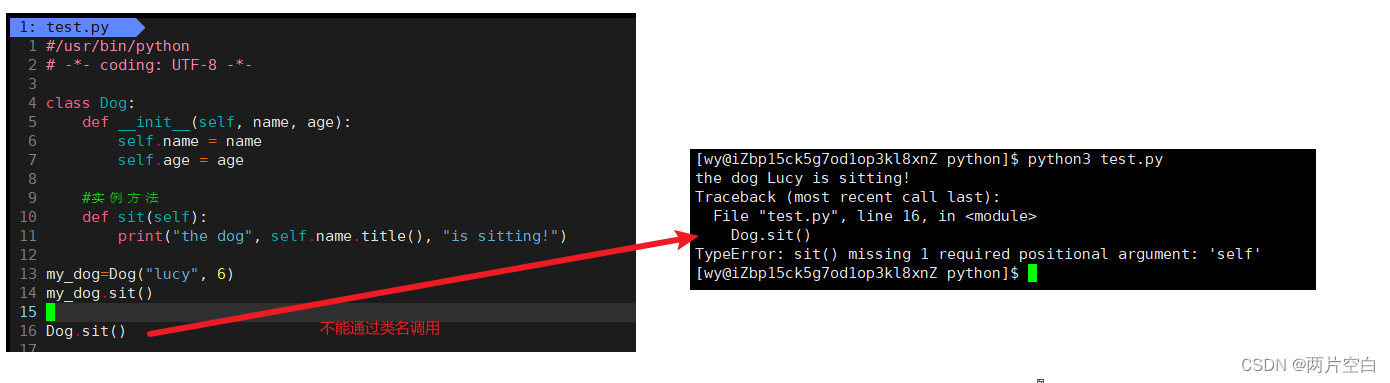
# 1. Python类方法与静态方法概述**
### 1.1 类方法与静态方法的概念和区别
在Python中,类方法和静态方法是两种特殊的方法类型,它们与传统的方法不同。类方法与类本身相关联,而静态方法与类或实例无关。
* **类方法:**类方法使用`@classmethod`装饰器,它允许访问类变量并修改类状态。类方法的第一个参数是`cls`,它代表类本身。
* **静态方法:**静态方法使用`@staticme
Python enumerate函数在医疗保健中的妙用:遍历患者数据,轻松实现医疗分析

# 1. Python enumerate函数概述**
enumerate函数是一个内置的Python函数,用于遍历序列(如列表、元组或字符串)中的元素,同时返回一个包含元素索引和元素本身的元组。该函数对于需要同时访问序列中的索引
实现松耦合Django信号与事件处理:应用程序逻辑大揭秘

# 1. Django信号与事件处理概述**
Django信号和事件是两个重要的机制,用于在Django应用程序中实现松散耦合和可扩展的事件处理。
**信号**是一种机制,允许在应用程序的各个部分之间发送和接收通知。当发生特定事件时,会触发信号,并调用注册的信号处理函数来响应该事件。
**事件**是一种机制,允许应用程序中的对象注册监听器,以在发生特定事件时执行操作。当触发事件时,会调用注册的事
Python连接MySQL数据库:区块链技术的数据库影响,探索去中心化数据库的未来

# 1. 区块链技术与数据库的交汇
区块链技术和数据库是两个截然不同的领域,但它们在数据管理和处理方面具有惊人的相似之处。区块链是一个分布式账本,记录交易并以安全且不可篡改的方式存储。数据库是组织和存储数据的结构化集合。
区块链和数据库的交汇点在于它们都涉及数据管理和处理。区块链提供了一个安全且透明的方式来记录和跟踪交易,而数据库提供了一个高效且可扩展的方式来存储和管理数据。这两种技术的结合可以为数据管
【实战演练】数据聚类实践:使用K均值算法进行用户分群分析
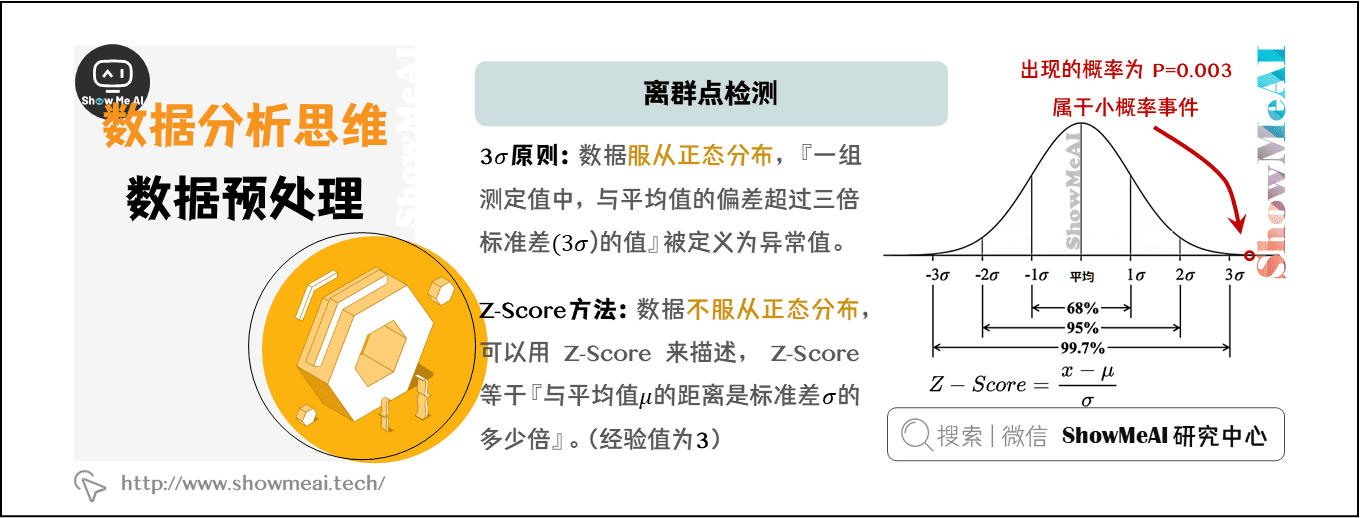
# 1. 数据聚类概述**
数据聚类是一种无监督机器学习技术,它将数据点分组到具有相似特征的组中。聚类算法通过识别数据中的模式和相似性来工作,从而将数据点分配到不同的组(称为簇)。
聚类有许多应用,包括:
- 用户分群分析:将用户划分为具有相似行为和特征的不同组。
- 市场细分:识别具有不同需求和偏好的客户群体。
- 异常检测:识别与其他数据点明显不同的数据点。
# 2
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )