Java 面试八股文2023:消息队列应用与原理解析
发布时间: 2024-04-09 21:53:44 阅读量: 54 订阅数: 23 

java 提供消息队列的使用
# 1. 消息队列基础概念
## 1.1 什么是消息队列
消息队列是一种应用间通信的方式,用来在应用之间传递消息。它基本上是一种**消息中转服务**,允许您发送和接收消息,通过队列保证消息的顺序一致性。
## 1.2 消息队列的作用
- **解耦**:消息队列将应用程序的各个部分解耦,使得它们可以独立地发展和部署。
- **异步处理**:消息队列提供异步通信机制,发送者无需等待接收者立即处理消息。
- **削峰填谷**:消息队列可以平滑处理流量高峰,避免突发流量对系统造成影响。
## 1.3 消息队列的优点与缺点
| 优点 | 缺点 |
|------------------------|-------------------------|
| **解耦** | **一致性难以保证** |
| **异步处理** | **维护成本高** |
| **削峰填谷** | **消息队列复杂度高** |
| **系统可靠性** | **消息积压可能导致问题** |
通过以上内容,我们了解了消息队列的基础概念,作用,以及优缺点。接下来,让我们深入探讨消息队列在不同场景中的应用。
# 2. 消息队列应用场景
消息队列在实际应用中有多种场景,以下是其中的一些典型应用场景:
1. **异步处理**:
- 在高并发系统中,消息队列可以将请求存储在队列中,由消费者异步处理,避免请求堆积和阻塞导致系统响应缓慢。
2. **应用解耦**:
- 将不同模块间的通信通过消息队列来实现,降低模块之间的依赖性,提高系统的灵活性和可维护性。
3. **流量削峰填谷**:
- 根据系统的实际情况动态调整消费者的处理速度,将消息进行缓存,避免系统因瞬时流量过大而导致宕机或性能下降。
4. **任务队列**:
- 用来处理定时任务,如定时邮件发送、数据备份等,通过消息队列可以保证任务的顺序执行和可靠性。
5. **日志处理**:
- 将日志异步发送到消息队列中,后续再进行日志的处理、存储或分析,提高系统的性能和可维护性。
| 应用场景 | 描述 |
|----------------|--------------|
| 异步处理 | 避免请求堆积和阻塞,提高系统响应速度 |
| 应用解耦 | 降低模块之间的依赖性,提高系统灵活性 |
| 流量削峰填谷 | 动态调整消费者处理速度,避免系统瞬时崩溃 |
| 任务队列 | 处理定时任务,保证任务执行的顺序和可靠性 |
| 日志处理 | 异步处理日志,提高系统性能和可维护性 |
```java
// 异步处理示例代码
ExecutorService executor = Executors.newFixedThreadPool(10);
public void processMessage(Message message) {
executor.submit(() -> {
// 异步处理消息
System.out.println("Processing message: " + message);
});
}
```
**代码总结**:以上代码演示了如何使用线程池实现消息的异步处理,避免阻塞主线程,提高系统的并发能力。
**结果说明**:通过异步处理消息,系统可以更快地响应请求,提高整体性能和用户体验。
```mermaid
graph TD;
A[请求] --> B(消息队列);
B --> C[消费者];
C --> D[响应结果];
```
**流程图解释**:该流程图展示了请求经过消息队列发送给消费者进行处理,最终返回响应结果的整个流程。通过消息队列实现了请求的异步处理,提高了系统的并发能力。
# 3. 消息队列常见应用
#### 3.1 RabbitMQ
RabbitMQ 是一个开源的消息队列实现,遵循 AMQP 协议。下表展示了 RabbitMQ 的一些特点:
| 特点 | 描述 |
|--------------|----------------------------------------------------------------|
| 可靠性 | 支持多种消息确认机制,确保消息能够正确到达消费者 |
| 灵活性 | 提供丰富的交换器类型及路由策略,支持多种消息模式的实现 |
| 插件化 | 可通过插件扩展功能,满足不同业务场景的需求 |
| 社区活跃 | 拥有庞大的社区支持,更新迭代较快,文档丰富,问题解决快捷 |
#### 3.2 Kafka
Kafka 是一个分布式的发布-订阅消息系统,具有高吞吐量和可水平扩展性。下面是 Kafka 的一些关键点:
- Kafka 通过分区机制实现水平扩展,可以应对大数据量的场景,适合实时数据处理和流处理应用。
- 支持消息持久化,并可配置副本数以保证数据可靠性。
- 提供高效的消息订阅机制,消费者可以自由控制消费进度,支持消费者组。
- 搭建 Kafka 集群时,需要考虑网络和硬件因素,以确保整体性能和可靠性。
```java
// Kafka 生产者示例代码
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<>("my_topic", Integer.toString(i), Integer.toString(i)));
}
producer.close();
```
以上代码展示了如何使用 Kafka 的 Java 客户端向主题发送消息。
#### 3.3 ActiveMQ
ActiveMQ 是一个基于 JMS(Java Message Service)规范的消息中间件。它具有以下特点:
- 支持多种传输协议,包括 TCP、SSL、NIO、UDP、HTTP 等,灵活适应不同网络环境。
- 提供高性能的消息传递能力,支持持久化、传输事务等功能。
- 集成了许多高级特性,如消息拦截器、消息转换器、调度器等,可方便地实现个性化需求。
- 可通过监控工具实时监测队列状态、消息传输情况,方便运维管理。
```merma
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“Java 面试八股文 2023”专栏汇集了 Java 技术面试的必备知识点,从入门基础到进阶应用,全面覆盖 Java 核心技术。专栏文章涵盖了面向对象编程、集合框架、多线程编程、IO 与 NIO、JVM 虚拟机、设计模式、Spring 框架、Spring Boot、Spring Cloud、MyBatis、Restful API、分布式系统、消息队列、Docker、Kubernetes、微服务架构监控和 ELK 栈等内容。通过阅读本专栏,读者可以快速掌握 Java 面试中的常见考点,为求职面试做好充分准备。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【硬件实现】:如何构建性能卓越的PRBS生成器

# 摘要
本文全面探讨了伪随机二进制序列(PRBS)生成器的设计、实现与性能优化。首先,介绍了PRBS生成器的基本概念和理论基础,重点讲解了其工作原理以及相关的关键参数,如序列长度、生成多项式和统计特性。接着,分析了PRBS生成器的硬件实现基础,包括数字逻辑设计、FPGA与ASIC实现方法及其各自的优缺点。第四章详细讨论了基于FPGA和ASIC的PRBS设计与实现过程,包括设计方法和验
NUMECA并行计算核心解码:掌握多节点协同工作原理
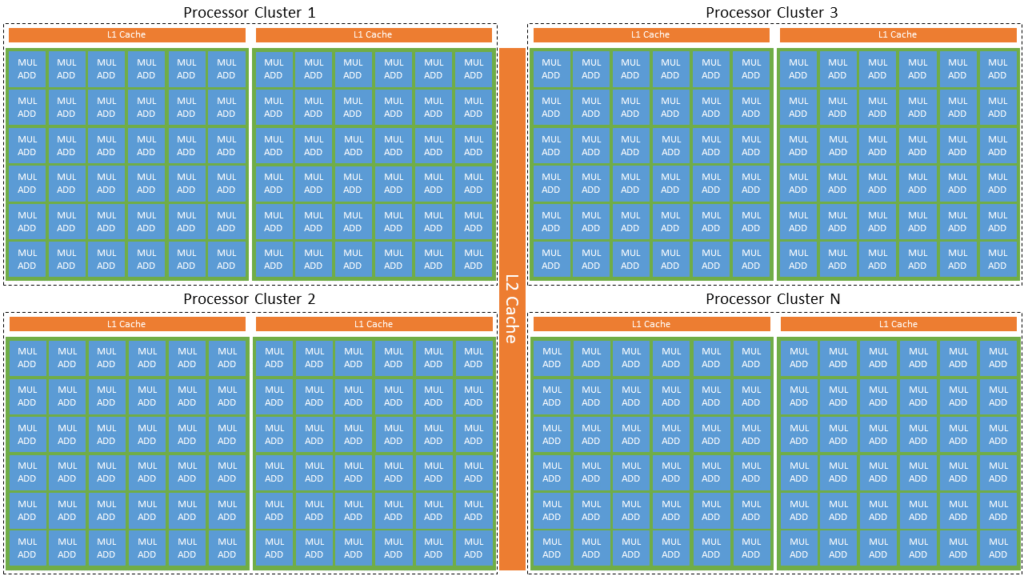
# 摘要
NUMECA并行计算是处理复杂计算问题的高效技术,本文首先概述了其基础概念及并行计算的理论基础,随后深入探讨了多节点协同工作原理,包括节点间通信模式以及负载平衡策略。通过详细说明并行计算环境搭建和核心解码的实践步骤,本文进一步分析了性能评估与优化的重要性。文章还介绍了高级并行计算技巧,并通过案例研究展示了NUMECA并行计算的应用。最后,本文展望了并行计
提升逆变器性能监控:华为SUN2000 MODBUS数据优化策略

# 摘要
逆变器作为可再生能源系统中的关键设备,其性能监控对于确保系统稳定运行至关重要。本文首先强调了逆变器性能监控的重要性,并对MODBUS协议进行了基础介绍。随后,详细解析了华为SUN2000逆变器的MODBUS数据结构,阐述了数据包基础、逆变器的注册地址以及数据的解析与处理方法。文章进一步探讨了性能数据的采集与分析优化策略,包括采集频率设定、异常处理和高级分析技术。
小红书企业号认证必看:15个常见问题的解决方案

# 摘要
本文系统地介绍了小红书企业号的认证流程、准备工作、认证过程中的常见问题及其解决方案,以及认证后的运营和维护策略。通过对认证前准备工作的详细探讨,包括企业资质确认和认证材料
FANUC面板按键深度解析:揭秘操作效率提升的关键操作
# 摘要
FANUC面板按键作为工业控制中常见的输入设备,其功能的概述与设计原理对于提高操作效率、确保系统可靠性及用户体验至关重要。本文系统地介绍了FANUC面板按键的设计原理,包括按键布局的人机工程学应用、触觉反馈机制以及电气与机械结构设计。同时,本文也探讨了按键操作技巧、自定义功能设置以及错误处理和维护策略。在应用层面,文章分析了面板按键在教育培训、自动化集成和特殊行业中的优化策略。最后,本文展望了按键未来发展趋势,如人工智能、机器学习、可穿戴技术及远程操作的整合,以及通过案例研究和实战演练来提升实际操作效率和性能调优。
# 关键字
FANUC面板按键;人机工程学;触觉反馈;电气机械结构
【UML类图与图书馆管理系统】:掌握面向对象设计的核心技巧
# 摘要
本文旨在探讨面向对象设计中UML类图的应用,并通过图书馆管理系统的需求分析、设计、实现与测试,深入理解UML类图的构建方法和实践。文章首先介绍了UML类图基础,包括类图元素、关系类型以及符号规范,并详细讨论了高级特性如接口、依赖、泛化以及关联等。随后,文章通过图书馆管理系统的案例,展示了如何将UML类图应用于需求分析、系统设计和代码实现。在此过程中,本文强调了面向对象设计原则,评价了UML类图在设计阶段
【虚拟化环境中的SPC-5】:迎接虚拟存储的新挑战与机遇
# 摘要
本文旨在全面介绍虚拟化环境与SPC-5标准,深入探讨虚拟化存储的基础理论、存储协议与技术、实践应用案例,以及SPC-5标准在虚拟化环境中的应用挑战。文章首先概述了虚拟化技术的分类、作用和优势,并分析了不同架构模式及SPC-5标准的发展背景。随后
硬件设计验证中的OBDD:故障模拟与测试的7大突破
# 摘要
OBDD(有序二元决策图)技术在故障模拟、测试生成策略、故障覆盖率分析、硬件设计验证以及未来发展方面展现出了强大的优势和潜力。本文首先概述了OBDD技术的基础知识,然后深入探讨了其在数字逻辑故障模型分析和故障检测中的应用。进一步地,本文详细介绍了基于OBDD的测试方法,并分析了提高故障覆盖率的策略。在硬件设计验证章节中,本文通过案例分析,展示了OBDD的构建过程、优化技巧及在工业级验证中的应用。最后,本文展望了OBDD技术与机器学习等先进技术的融合,以及OBDD工具和资源的未来发展趋势,强调了OBDD在AI硬件验证中的应用前景。
# 关键字
OBDD技术;故障模拟;自动测试图案生成
海康威视VisionMaster SDK故障排除:8大常见问题及解决方案速查
# 摘要
本文全面介绍了海康威视VisionMaster SDK的使用和故障排查。首先概述了SDK的特点和系统需求,接着详细探讨了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )