MongoDB的基本查询语法
发布时间: 2024-01-07 20:55:43 阅读量: 31 订阅数: 31 
# 1. MongoDB简介
## 1.1 MongoDB是什么
MongoDB是一个基于分布式文件存储的数据库,由C++语言编写,旨在为web应用提供可扩展的高性能数据存储解决方案。
## 1.2 MongoDB的特点
- **面向文档**:数据以文档的形式存储,便于在应用程序中使用JSON格式的数据。
- **灵活的数据模型**:支持动态查询、索引、复制和聚合等功能。
- **高性能**:支持嵌入式数据模型,能够提供高性能的数据访问。
- **横向扩展**:能够通过横向扩展实现数据的规模化增长。
## 1.3 MongoDB的应用领域
MongoDB在以下领域得到广泛应用:
- **大数据存储和分析**:适用于需要处理大量非结构化数据的场景,如日志分析、内容管理和实时分析等。
- **实时数据分析**:能够提供实时的数据分析和快速的查询能力,适用于需要实时监控和分析的应用场景。
- **内容管理系统**:可存储和管理各种类型的内容数据,如博客文章、产品信息和用户评论等。
以上是关于MongoDB简介的内容,接下来将介绍MongoDB查询语法的概述。
# 2. MongoDB查询语法概述
### 2.1 MongoDB查询语法的基本结构
在MongoDB中,要进行数据查询,需要使用`find()`方法。`find()`方法可以接收一个查询条件对象作为参数,用于指定查询的条件。
例如,以下是一个简单的查询示例,查询集合中所有的文档:
```python
db.collectionName.find({})
```
在这个示例中,`db`表示当前数据库,`collectionName`表示要查询的集合。花括号`{}`表示查询条件,这里使用了空对象作为条件,表示查询所有文档。
除了空对象以外,还可以使用各种查询条件限制查询结果,例如按字段匹配、范围查询、逻辑操作等。
### 2.2 MongoDB的集合和文档
在MongoDB中,数据存储在集合(Collection)中,集合类似于关系数据库中的表。每个集合包含多个文档(Document),文档类似于关系数据库中的行。
文档是MongoDB中最基本的数据单元,表示一个键值对集合,可以包含嵌套的文档和数组。每个文档都有一个唯一的`_id`字段,用于标识文档。
以下是一个示例文档:
```json
{
"_id": ObjectId("60d4e4e61f2fc13633a3a87f"),
"name": "John Doe",
"age": 30,
"email": "johndoe@example.com"
}
```
在这个示例中,`_id`字段是自动生成的唯一标识符,`name`、`age`和`email`字段分别表示姓名、年龄和电子邮件。
通过使用查询语法,可以根据需要从集合中查找满足条件的文档,并进行各种操作和处理。
以上是关于MongoDB查询语法的简要概述,接下来将介绍基本查询操作。
# 3. 基本查询操作
在MongoDB中,我们可以通过基本的查询操作来检索数据,包括查询所有文档、条件查询和排序查询等。接下来我们将分别介绍这些基本查询操作的语法和示例。
#### 3.1 查询所有文档
要查询集合中的所有文档,可以使用find()方法。find()方法接受一个查询条件作为参数,如果没有指定查询条件,则返回集合中的所有文档。
**示例代码(Python):**
```python
# 连接到数据库
import pymongo
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["mydatabase"]
col = db["customers"]
# 查询所有文档
for x in col.find():
print(x)
```
**代码总结:**
- 使用find()方法查询集合中的所有文档。
- 遍历查询结果并打印每个文档。
**结果说明:**
- 将输出集合中的所有文档信息。
#### 3.2 条件查询
在MongoDB中,可以根据指定的条件来查询文档。可以使用查询操作符(如$eq、$gt、$lt等)构建查询条件。
**示例代码(Java):**
```java
// 创建查询条件
Document query = new Document("age", new Document("$gt", 18));
// 执行条件查询
FindIterable<Document> cursor = collection.find(query);
// 遍历查询结果
for (Document doc : cursor) {
System.out.println(doc.toJson());
}
```
**代码总结:**
- 创建查询条件,这里以年龄大于18岁为例。
- 使用find()方法执行条件查询。
- 遍历查询结果并打印每个文档的JSON格式。
**结果说明:**
- 将输出年龄大于18岁的文档信息。
#### 3.3 排序查询
在查询时,可以指定排序规则,例如按照某个字段的升序或降序排列。
**示例代码(Golang):**
```go
// 指定排序规则
opts := options.Find().SetSort(bson.D{{"age", 1}})
// 执行排序查询
cur, err := collection.Find(context.Background(), bson.D{}, opts)
if err != nil {
log.Fatal(err)
}
// 遍历查询结果
defer cur.Close(context.Background())
for cur.Next(context.Background()) {
var result bson.M
err := cur.Decode(&result)
if err != nil {
log.Fatal(err)
}
fmt.Println(result)
}
```
**代码总结:**
- 使用FindOptions设置排序规则,这里以年龄升序为例。
- 执行排序查询并遍历结果。
**结果说明:**
- 将按照年龄升序排列的文档信息输出。
以上就是MongoDB的基本查询操作,包括查询所有文档、条件查询和排序查询。在实际应用中,可以根据具体需求灵活运用这些查询操作,以实现对数据库的高效操作。
# 4. 高级查询操作
在MongoDB中,除了基本的查询操作外,还有一些高级查询操作可以帮助您更方便地获取所需的数据。本章将介绍一些高级查询操作的语法和用法。
#### 4.1 聚合查询
聚合查询是MongoDB中非常强大的功能之一,通过聚合查询可以对数据进行分组、计数、求和等操作。在MongoDB中,聚合查询使用聚合管道(aggregation pipeline)来实现,通过一系列阶段对文档进行处理,最终得到所需的结果。
以下是一个简单的聚合查询示例,假设我们有一个学生信息的集合(collection),其中包含了学生的姓名和成绩信息,我们希望对学生的成绩进行统计:
```python
pipeline = [
{"$group": {"_id": "$name", "avgScore": {"$avg": "$score"}}},
{"$sort": {"avgScore": -1}}
]
result = db.students.aggregate(pipeline)
for doc in result:
print(doc)
```
上述代码中,我们使用了`$group`阶段对学生的成绩进行分组,并计算每个学生的平均成绩,然后使用`$sort`阶段对平均成绩进行降序排序。最终,我们会得到按照平均成绩排名的学生列表。
#### 4.2 嵌套文档的查询
在MongoDB中,文档可以包含嵌套的子文档(子对象),而且可以对子文档进行查询操作。例如,我们有一个包含订单信息的集合,每个订单文档中包含了订单详情的子文档,我们可以针对子文档中的字段进行查询操作。
```java
Document query = new Document("orderDetails.productName", "iPhone");
FindIterable<Document> result = collection.find(query);
for (Document doc : result) {
System.out.println(doc);
}
```
以上代码中,我们通过指定`orderDetails.productName`字段来查询包含特定产品(例如iPhone)的订单,然后对查询结果进行遍历输出。
#### 4.3 复杂条件查询
除了简单的等值查询外,MongoDB还支持复杂条件的查询操作,例如范围查询、逻辑条件查询等。您可以使用各种查询运算符(如`$gt`、`$lt`、`$in`等)来构建复杂的查询条件,以满足不同的需求。
```javascript
const query = {
age: { $gt: 20, $lt: 30 },
department: 'IT'
};
const result = await EmployeeModel.find(query);
console.log(result);
```
在上述示例中,我们通过查询条件`age: { $gt: 20, $lt: 30 }`和`department: 'IT'`来查询年龄在20到30岁之间且所属部门为IT的员工信息。最终将符合条件的员工信息输出到控制台。
通过本章的介绍,您可以学习到MongoDB的一些高级查询操作的具体用法,希望这些内容能够帮助您更好地应用MongoDB进行数据查询与分析。
# 5. 索引和性能优化
在MongoDB中,索引和性能优化是非常重要的内容。本章将介绍MongoDB索引的概念、创建和管理索引的方法,以及如何通过索引来优化查询性能。
#### 5.1 MongoDB索引简介
索引是对数据库中一列或多列的值进行排序的一种结构,通过索引可以快速地定位到数据,从而提高查询性能。在MongoDB中,索引可以大大减少查询时需要扫描的数据量,加快检索速度。
#### 5.2 创建和管理索引
在MongoDB中,可以使用`createIndex()`方法来创建索引,语法如下:
```python
db.collection.createIndex({ field: 1 })
```
其中,`collection`表示集合名,`field`表示要创建索引的字段,`1`表示按升序进行索引,`-1`表示按降序进行索引。
除了创建索引,还可以使用`getIndexes()`方法来查看索引信息,使用`dropIndex()`方法来删除索引。
#### 5.3 查询性能优化
通过合理地创建索引,可以大大提高查询性能。在实际应用中,需要根据具体的查询场景来选择合适的索引策略,避免过多地创建索引,以免影响写入性能。
综上所述,索引和性能优化是MongoDB中非常重要的内容,合理地创建和管理索引可以大大提高查询的速度,从而提升系统的性能。
希望这部分内容能够帮助你更好地理解MongoDB索引和性能优化。
# 6. 实际应用案例分析
在本章中,我们将通过几个实际的应用案例来演示MongoDB查询语法的使用和性能优化。
##### 6.1 查询语法在实际应用中的使用
在实际应用中,我们经常需要查询和分析数据库中的数据。MongoDB提供了丰富的查询语法,可以灵活地满足不同的查询需求。
*案例一:查询用户购买记录*
假设我们有一个电商平台的订单数据库,其中有一个集合存储了用户的购买记录。我们想要查询某个用户的购买记录。
```python
db.orders.find({ "user_id": "123456" })
```
上述示例中,我们使用了`find`方法进行查询,并指定了`"user_id"`字段为`"123456"`的条件。结果将返回满足条件的所有文档。
*案例二:统计商品销量*
在上述订单数据库中,每个订单文档中都包含了商品的信息。我们可以使用聚合查询的方式统计每个商品的销量。
```python
db.orders.aggregate([
{
$group: {
_id: "$product_id",
total_sales: { $sum: "$quantity" }
}
},
{
$sort: { total_sales: -1 }
}
])
```
上述示例中,我们使用了`aggregate`方法进行聚合查询。首先通过`$group`操作将订单按`"product_id"`进行分组,并计算每个商品的销量,然后通过`$sort`操作按销量进行排序。
##### 6.2 查询语法的性能对比分析
在实际应用中,优化查询语句的性能是非常重要的。下面我们通过一个实例进行性能对比分析。
*案例:按条件查询订单*
假设我们要查询订单金额超过1000元的订单。
```java
// Java示例代码
db.orders.find({ "total_amount": { $gt: 1000 } })
```
```python
# Python示例代码
db.orders.find({ "total_amount": { $gt: 1000 } })
```
```javascript
// JavaScript示例代码
db.orders.find({ "total_amount": { $gt: 1000 } })
```
上述示例中,我们使用了不同的编程语言编写了查询语句。虽然语法稍有不同,但原理是一样的。我们通过指定`"total_amount"`字段大于1000的条件进行查询。
通过对比不同语言的查询语句,我们可以分析每种语言的性能差异,并选择性能最优的查询语句。
##### 6.3 查询语法的最佳实践
在使用MongoDB查询语法时,有一些最佳实践可以帮助我们优化查询性能:
- 创建合适的索引:根据查询的字段和频率来创建索引,以加快查询速度。
- 使用投影操作:只查询需要的字段,避免读取不必要的数据,提高性能。
- 缓存查询结果:对于不常变动的查询结果,可以缓存起来,减少数据库的访问次数。
总结:在实际应用中,我们可以根据具体的需求使用MongoDB的查询语法来获取数据,并通过性能优化来提高查询效率。
希望通过这些实际应用案例的演示,你能更好地理解和应用MongoDB的查询语法。下一章将介绍索引和性能优化的相关内容。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到通俗易懂的MongoDB教程专栏!本专栏将带您逐步掌握MongoDB的基本查询语法、文档插入、更新和删除操作等操作技巧。您还将学习到MongoDB中的聚合操作和简单示例,以及数据的备份与恢复方法。探索MongoDB的数据分片与水平扩展以及事务处理,您将了解如何在MongoDB中存储和查询地理位置数据,以及处理图形数据。我们还将分享数据模型设计与最佳实践、文本索引和全文搜索等内容,与关系型数据库进行对比和选择。探索MongoDB在大数据处理与分析、云环境中的部署与管理,以及性能优化和调优技巧。最后,我们将探讨MongoDB在实时数据处理和实时分析中的应用。无论您是初学者还是有经验的开发者,本专栏将为您提供全面且易于理解的MongoDB教程。让我们一起开始探索吧!
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Android二维码框架选择:如何集成与优化用户界面与交互

# 1. Android二维码框架概述
在移动应用开发领域,二维码技术已经成为不可或缺的一部分。Android作为应用广泛的移动操作系统,其平台上的二维码框架种类繁多,开发者在选择适合的框架时需要综合考虑多种因素。本章将为读者概述二维码框架的基本知识、功
全球高可用部署:MySQL PXC集群的多数据中心策略

# 1. 高可用部署与MySQL PXC集群基础
在IT行业,特别是在数据库管理系统领域,高可用部署是确保业务连续性和数据一致性的关键。通过本章,我们将了解高可用部署的基础以及如何利用MySQL Percona XtraDB Cluster (PXC) 集群来实现这一目标。
## MySQL PXC集群的简介
MySQL PXC集群是一个可扩展的同步多主节点集群解决方案,它能够提供连续可用性和数据一致
Python算法实现捷径:源代码中的经典算法实践

# 1. Python算法实现捷径概述
在信息技术飞速发展的今天,算法作为编程的核心之一,成为每一位软件开发者的必修课。Python以其简洁明了、可读性强的特点,被广泛应用于算法实现和教学中。本章将介绍如何利用Python的特性和丰富的库,为算法实现铺平道路,提供快速入门的捷径
【MATLAB控制系统设计】:仿真到实现的全步骤教程
# 1. MATLAB控制系统设计概述
在现代控制系统设计中,MATLAB已经成为了工程师不可或缺的工具。它提供了一个综合性的计算环境,让工程师能够进行算法开发、数据可视化、数据分析以及仿真等多种操作。MATLAB的控制系统工具箱(Control System Toolbox)为控制系统的设计和分析提供了全面的支持。借助这些工具,我们可以轻松地对系统进行建模、分析和调整,以实现
【JavaScript人脸识别的用户体验设计】:界面与交互的优化

# 1. JavaScript人脸识别技术概述
## 1.1 人脸识别技术简介
人脸识别技术是一种通过计算机图像处理和识别技术,让机器能够识别人类面部特征的技术。近年来,随着人工智能技术的发展和硬件计算能力的提升,JavaScript人脸识别技术得到了迅速的发展和应用。
## 1.2 JavaScript在人脸识别中的应用
JavaScript作为一种强
【NLP新范式】:CBAM在自然语言处理中的应用实例与前景展望

# 1. NLP与深度学习的融合
在当今的IT行业,自然语言处理(NLP)和深度学习技术的融合已经产生了巨大影响,它们共同推动了智能语音助手、自动翻译、情感分析等应用的发展。NLP指的是利用计算机技术理解和处理人类语言的方式,而深度学习作为机器学习的一个子集,通过多层神经网络模型来模拟人脑处理数据和创建模式
MATLAB遗传算法与模拟退火策略:如何互补寻找全局最优解

# 1. 遗传算法与模拟退火策略的理论基础
遗传算法(Genetic Algorithms, GA)和模拟退火(Simulated Annealing, SA)是两种启发式搜索算法,它们在解决优化问题上具有强大的能力和独特的适用性。遗传算法通过模拟生物
故障恢复计划:机械运动的最佳实践制定与执行

# 1. 故障恢复计划概述
故障恢复计划是确保企业或组织在面临系统故障、灾难或其他意外事件时能够迅速恢复业务运作的重要组成部分。本章将介绍故障恢复计划的基本概念、目标以及其在现代IT管理中的重要性。我们将讨论如何通过合理的风险评估与管理,选择合适的恢复策略,并形成文档化的流程以达到标准化。
## 1.1 故障恢复计划的目的
故障恢复计划的主要目的是最小化突发事件对业务的
拷贝构造函数的陷阱:防止错误的浅拷贝
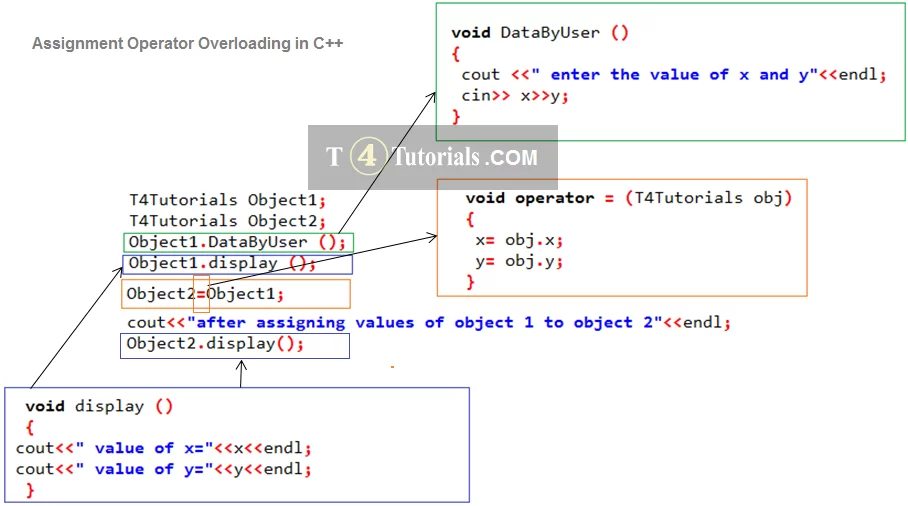
# 1. 拷贝构造函数概念解析
在C++编程中,拷贝构造函数是一种特殊的构造函数,用于创建一个新对象作为现有对象的副本。它以相同类类型的单一引用参数为参数,通常用于函数参数传递和返回值场景。拷贝构造函数的基本定义形式如下:
```cpp
class ClassName {
public:
ClassName(const ClassName& other); // 拷贝构造函数
MATLAB时域分析:动态系统建模与分析,从基础到高级的完全指南
# 1. MATLAB时域分析概述
MATLAB作为一种强大的数值计算与仿真软件,在工程和科学领域得到了广泛的应用。特别是对于时域分析,MATLAB提供的丰富工具和函数库极大地简化了动态系统的建模、分析和优化过程。在开始深入探索MATLAB在时域分析中的应用之前,本章将为读者提供一个基础概述,包括时域分析的定义、重要性以及MATLAB在其中扮演的角色。
时域
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )