【快速排序的极致优化】:应用与技巧,速度提升不是梦
发布时间: 2024-09-13 23:19:50 阅读量: 52 订阅数: 21 

通过MySQL优化Discuz!的热帖翻页的技巧
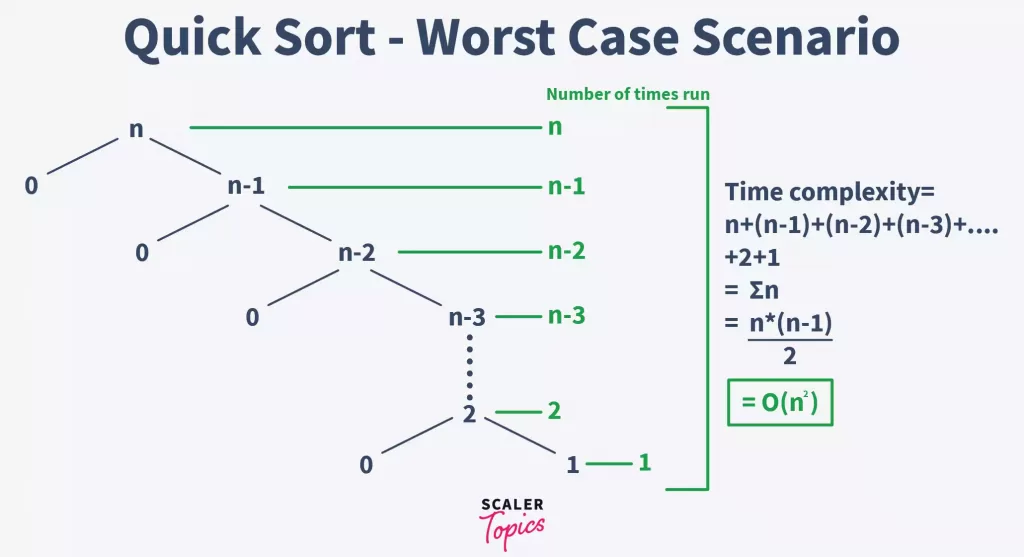
# 1. 快速排序算法概述
快速排序(Quick Sort)算法由C.A.R. Hoare在1960年提出,是一种高效的排序算法。它采用了分治法(Divide and Conquer)的策略,通过一个划分操作将待排序的数组分为两个子数组,其中一个的所有数据都比另一个的要小,然后递归地对这两个子数组继续进行排序,整个排序过程递归进行,直到所有子数组只包含一个元素为止。
快速排序的核心操作是分区(Partitioning),即将数组分为独立的两部分,其中一部分的所有数据都比另一部分的所有数据要小。快速排序的平均时间复杂度为O(n log n),但由于分区的原因,最坏情况下可能退化到O(n^2),这通常发生在每次分区操作选择到的是最小或者最大元素时。
由于其高效的平均性能,快速排序被广泛应用于各种数据处理场景中,尤其是在需要处理大数据集时。它的空间复杂度为O(log n),因为它通常采用原地排序(In-Place Sorting),不需要额外的存储空间。在本章的后续部分,我们将深入探讨快速排序算法的理论基础,以及它的实现和优化策略。
# 2. 快速排序算法的理论基础
### 2.1 快速排序算法原理
#### 2.1.1 分区过程解析
快速排序的核心在于分区操作,它将数组分为两个部分,其中一部分的所有元素都不大于另一部分的任何元素。这个过程通常称为“划分”(Partitioning)。划分操作一般选择一个元素作为基准(Pivot),重新排列数组,使得左边的元素小于等于基准,右边的元素大于等于基准。
划分过程通常由左右两个指针从数组两端开始,向中间移动。左指针向右移动直到找到大于等于基准的元素,右指针向左移动直到找到小于等于基准的元素,如果两个指针都停下了,则交换它们所指的元素。重复此过程直到左右指针相遇,最后基准元素所在的正确位置就是划分的分界点。
这里提供一个基本的分区操作的伪代码:
```
function partition(array, low, high) {
pivot = array[high] // 选择基准元素
i = low // i指向比基准小的区域的下一个位置
for j = low to high - 1 do {
if array[j] <= pivot then
swap array[i] with array[j]
i = i + 1
end if
end for
swap array[i] with array[high] // 将基准元素放到正确的位置
return i // 返回基准元素的位置
}
```
#### 2.1.2 递归机制详解
快速排序是一种递归算法,它利用了分治策略。一旦基准元素被放置到了正确的位置,算法递归地对基准左右两侧的子数组进行同样的排序操作。这种递归操作可以保证整个数组变得有序。
递归的终止条件是子数组的大小缩小到0或者1,这种情况下子数组已经有序,不需要进一步排序。
下面是一个递归版本快速排序的伪代码:
```
function quickSort(array, low, high) {
if low < high then
p = partition(array, low, high) // 划分数组并获得基准的位置
quickSort(array, low, p - 1) // 递归排序基准左侧的子数组
quickSort(array, p + 1, high) // 递归排序基准右侧的子数组
end if
}
```
在上述伪代码中,`quickSort` 函数将原数组进行排序,它接受数组以及子数组的起始和结束位置作为参数。每次递归调用都将数组划分成更小的部分,直到满足终止条件。
### 2.2 快速排序的性能分析
#### 2.2.1 时间复杂度与空间复杂度
快速排序的平均时间复杂度为 O(n log n),在最坏情况下为 O(n^2)。快速排序的平均性能优越,但在极少数情况下,当输入数组已经基本有序或完全有序时,性能会急剧下降。为了避免这种情况,通常需要选择一个好的基准元素,或者采用其他的优化手段。
快速排序的空间复杂度主要取决于递归的深度。最坏情况下的空间复杂度为 O(n),平均情况下为 O(log n),这是因为快速排序不需要额外的存储空间,它利用的是原数组空间。快速排序在栈上的使用主要来自于递归调用。
#### 2.2.2 算法稳定性和比较次数
快速排序是一个不稳定的排序算法,因为在排序过程中,元素的相对顺序可能会改变。例如,有多个具有相同值的元素时,它们之间原有的相对位置关系可能会在排序过程中被打破。
比较次数方面,快速排序是基于比较的排序算法。在最好和平均情况下,每次划分都将数组分为两个几乎相等的部分,因此比较次数接近于 O(n log n)。然而,在最坏情况下,每次划分只能将数组分为两个不等的部分,例如,当输入数组已经有序时,比较次数会增加到 O(n^2)。
快速排序的优化方法往往围绕着减少这种最坏情况出现的概率,或是通过其他手段减少比较次数和增加稳定性。这些优化手段包括但不限于随机选择基准、使用插入排序处理小数组、三数取中法等。
在后续章节中,我们将通过实例代码展示快速排序算法的实现,并探讨各种变种和优化策略。
# 3. 快速排序算法的实现
## 3.1 基本快速排序的代码实现
### 3.1.1 递归版本
快速排序的递归版本是该算法最经典且常见的实现方式。它的核心思想是分而治之,通过将数组分为两部分,并递归地对这两部分进行排序,直到达到基本有序的状态。
以下是快速排序递归版本的示例代码:
```python
def quick_sort_recursive(arr, low, high):
if low < high:
# Partition the array
pi = partition(arr, low, high)
# Sort the two halves
quick_sort_recursive(arr, low, pi - 1)
quick_sort_recursive(arr, pi + 1, high)
def partition(arr, low, high):
# Choose the rightmost element as pivot
pivot = arr[high]
i = low - 1
for j in range(low, high):
# If current element is smaller than the pivot
if arr[j] < pivot:
i += 1
# Swap elements at i and j
arr[i], arr[j] = arr[j], arr[i]
# Swap the pivot element with the element at i+1
arr[i + 1], arr[high] = arr[high], arr[i + 1]
# Return the partitioning index
return i + 1
# Example usage:
arr = [10, 7, 8, 9, 1, 5]
n = len(arr)
quick_sort_recursive(arr, 0, n-1)
print("Sorted array:", arr)
```
在上述代码中,`quick_sort_recursive` 函数是递归排序的核心,它接受数组和两个索引作为参数,分别表示当前需要排序的数组段的起始和结束位置。`partition` 函数负责找到分区点,并将小于基准值的元素移动到基准的左侧,将大于基准值的元素移动到基准的右侧。这个过程不断地重复,直到数组被完全排序。
### 3.1.2 非递归版本
非递归版本的快速排序利用栈来模拟递归过程。这种实现方式尤其在语言不支持或限制递归深度时特别有用。
下面是非递归版本快速排序的示例代码:
```python
def quick_sort_non_recursive(arr):
# Create a stack and push initial range onto it
stack = []
stack.append((0, len(arr) - 1))
# Keep popping from stack while it's not empty
while stack:
low, high = stack.pop()
# Partition the array and get the pivot index
pi = partition(arr, low, high)
# If there are elements on the left side of the pivot, push left range to
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“数据结构排序顺序表”专栏,在这里,我们将深入探讨顺序表排序的奥秘。从经典的冒泡排序到高效的快速排序,我们揭示了七种排序算法的秘密,并提供了实用技巧来提升算法效率。
专栏文章涵盖了排序算法的深层解析、优化方案、内部逻辑和极致优化。我们深入探讨了堆排序、希尔排序、计数排序、桶排序和基数排序等非传统算法。此外,我们还分析了排序算法的稳定性和效率,以及存储考量,帮助您全面理解排序算法的方方面面。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32F030C8T6专攻:最小系统扩展与高效通信策略
# 摘要
本文首先介绍了STM32F030C8T6微控制器的基础知识和最小系统设计的要点,涵盖硬件设计、软件配置及最小系统扩展应用案例。接着深入探讨了高效通信技术,包括不同通信协议的使用和通信策略的优化。最后,文章通过项目管理与系统集成的实践案例,展示了如何在实际项目中应用这些技术和知识,进行项目规划、系统集成、测试及故障排除,以提高系统的可靠性和效率。
# 关键字
STM32F030C8T6;
【PyCharm专家教程】:如何在PyCharm中实现Excel自动化脚本

# 摘要
本文旨在全面介绍PyCharm集成开发环境以及其在Excel自动化处理中的应用。文章首先概述了PyCharm的基本功能和Python环境配置,进而深入探讨了Python语言基础和PyCharm高级特性。接着,本文详细介绍了Excel自动化操作的基础知识,并着重分析了openpyxl和Pandas两个Python库在自动化任务中的运用。第四章通过实践案
ARM处理器时钟管理精要:工作模式协同策略解析

# 摘要
本文系统性地探讨了ARM处理器的时钟管理基础及其工作模式,包括处理器运行模式、异常模式以及模式间的协同关系。文章深入分析了时钟系统架构、动态电源管理技术(DPM)及协同策略,揭示了时钟管理在提高处理器性能和降低功耗方面的重要性。同时,通过实践应用案例的分析,本文展示了基于ARM的嵌入式系统时钟优化策略及其效果评估,并讨论了时钟管理常见问题的
【提升VMware性能】:虚拟机高级技巧全解析
# 摘要
随着虚拟化技术的广泛应用,VMware作为市场主流的虚拟化平台,其性能优化问题备受关注。本文综合探讨了VMware在虚拟硬件配置、网络性能、系统和应用层面以及高可用性和故障转移等方面的优化策略。通过分析CPU资源分配、内存管理、磁盘I/O调整、网络配置和操作系统调优等关键技术点,本文旨在提供一套全面的性能提升方案。此外,文章还介绍了性能监控和分析工具的运用,帮助用户及时发
【CEQW2数据分析艺术】:生成报告与深入挖掘数据洞察
# 摘要
本文全面探讨了数据分析的艺术和技术,从报告生成的基础知识到深入的数据挖掘方法,再到数据分析工具的实际应用和未来趋势。第一章概述了数据分析的重要性,第二章详细介绍了数据报告的设计和高级技术,包括报告类型选择、数据可视化和自动化报告生成。第三章深入探讨了数据分析的方法论,涵盖数据清洗、统计分析和数据挖掘技术。第四章探讨了关联规则、聚类分析和时间序列分析等更高级的数据洞察技术。第五章将
UX设计黄金法则:打造直觉式移动界面的三大核心策略

# 摘要
随着智能移动设备的普及,直觉式移动界面设计成为提升用户体验的关键。本文首先概述移动界面设计,随后深入探讨直觉式设计的理论基础,包括用户体验设计简史、核心设计原则及心理学应用。接着,本文提出打造直觉式移动界面的实践策略,涉及布局、导航、交互元素以及内容呈现的直觉化设计。通过案例分析,文中进一步探讨了直觉式交互设计的成功与失败案例,为设
数字逻辑综合题技巧大公开:第五版习题解答与策略指南

# 摘要
本文旨在回顾数字逻辑基础知识,并详细探讨综合题的解题策略。文章首先分析了理解题干信息的方法,包括题目要求的分析与题型的确定,随后阐述了数字逻辑基础理论的应用,如逻辑运算简化和时序电路分析,并利用图表和波形图辅助解题。第三章通过分类讨论典型题目,逐步分析了解题步骤,并提供了实战演练和案例分析。第四章着重介绍了提高解题效率的技巧和避免常见错误的策略。最后,第五章提供了核心习题的解析和解题参考,旨在帮助读者巩固学习成果并提供额外的习题资源。整体而言,本文为数字逻辑
Zkteco智慧云服务与备份ZKTime5.0:数据安全与连续性的保障
# 摘要
本文全面介绍了Zkteco智慧云服务的系统架构、数据安全机制、云备份解决方案、故障恢复策略以及未来发展趋势。首先,概述了Zkteco智慧云服务的概况和ZKTime5.0系统架构的主要特点,包括核心组件和服务、数据流向及处理机制。接着,深入分析了Zkteco智慧云服务的数据安全机制,重点介绍了加密技术和访问控制方法。进一步,本文探讨了Zkteco云备份解决方案,包括备份策略、数据冗余及云备份服务的实现与优化。第五章讨论了故障恢复与数据连续性保证的方法和策略。最后,展望了Zkteco智慧云服务的未来,提出了智能化、自动化的发展方向以及面临的挑战和应对策略。
# 关键字
智慧云服务;系统
Java安全策略高级优化技巧:local_policy.jar与US_export_policy.jar的性能与安全提升

# 摘要
Java安全模型是Java平台中确保应用程序安全运行的核心机制。本文对Java安全模型进行了全面概述,并深入探讨了安全策略文件的结构、作用以及配置过程。针对性能优化,本文提出了一系列优化技巧和策略文件编写建议,以减少不必要的权限声明,并提高性能。同时,本文还探讨了Java安全策略的安全加固方法,强调了对local_po
海康二次开发实战攻略:打造定制化监控解决方案

# 摘要
海康监控系统作为领先的视频监控产品,其二次开发能力是定制化解决方案的关键。本文从海康监控系统的基本概述与二次开发的基础讲起,深入探讨了SDK与API的架构、组件、使用方法及其功能模块的实现原理。接着,文中详细介绍了二次开发实践,包括实时视频流的获取与处理、录像文件的管理与回放以及报警与事件的管理。此外,本文还探讨了如何通过高级功能定制实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )