Python核心库文件学习之core:多线程与多进程编程,解锁并发世界
发布时间: 2024-10-16 23:18:52 阅读量: 21 订阅数: 19 

# 1. Python多线程与多进程基础
Python的多线程和多进程是实现并发编程的两种主要方式,它们各有特点和适用场景。在深入探讨它们的高级应用和实战案例之前,我们需要首先理解它们的基本概念。
## 1.1 多线程的基本概念
### 1.1.1 线程的创建和管理
线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。在Python中,我们通常使用`threading`模块来创建和管理线程。
```python
import threading
def thread_function(name):
print(f"Thread {name}: starting")
if __name__ == "__main__":
thread = threading.Thread(target=thread_function, args=(1,))
thread.start()
thread.join()
print("Done")
```
上述代码展示了如何创建一个线程并启动它。我们定义了一个`thread_function`函数,然后创建一个`Thread`对象,指定了目标函数和参数,最后通过调用`start()`方法来启动线程。
### 1.1.2 线程同步机制
当多个线程同时访问共享资源时,线程同步机制就显得尤为重要。Python提供了多种同步原语,如锁(Lock)、信号量(Semaphore)、事件(Event)等,用于控制线程间的协作。
例如,使用锁可以避免多个线程同时修改同一个数据:
```python
import threading
lock = threading.Lock()
def thread_function(name):
lock.acquire()
try:
print(f"Thread {name}: critical section")
finally:
lock.release()
if __name__ == "__main__":
threads = []
for index in range(3):
thread = threading.Thread(target=thread_function, args=(index,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
print("Done")
```
在这个例子中,我们创建了一个锁对象`lock`,并在`thread_function`中使用`acquire()`方法来获取锁,在`finally`块中使用`release()`方法来释放锁。这样可以确保同一时间只有一个线程可以执行临界区的代码。
# 2. Python多线程编程
### 2.1 多线程的基本概念
#### 2.1.1 线程的创建和管理
在Python中,多线程编程是通过`threading`模块来实现的。线程的创建和管理是并发编程的基础,它允许我们执行多个任务同时操作,提高程序的效率和响应速度。
线程的创建通常是通过继承`Thread`类并重写`run`方法来实现的。例如,创建一个简单的线程类:
```python
import threading
class MyThread(threading.Thread):
def __init__(self):
super(MyThread, self).__init__()
def run(self):
print("This is a new thread.")
```
要启动这个线程,我们可以简单地创建一个实例并调用它的`start`方法:
```python
thread = MyThread()
thread.start()
thread.join() # 等待线程执行完成
```
在这个例子中,`thread.start()`启动线程,而`thread.join()`是一个阻塞调用,它使主线程等待新线程执行完成。
线程的管理还涉及到线程的生命周期控制,如线程的暂停、恢复和终止。这些可以通过`threading`模块提供的方法来实现,例如`threading.Event`可以用来控制线程的暂停和恢复,而`threading.Thread.terminate()`方法可以尝试终止线程,但这并不是一个安全的操作,因为它不会做任何清理工作。
#### 2.1.2 线程同步机制
多线程编程中,线程同步是一个重要的概念。当多个线程需要共享资源或者修改共享数据时,如果不进行同步,就可能会发生数据不一致的问题,这就是所谓的竞态条件。
Python中的同步机制主要包括锁(Locks)、信号量(Semaphores)、条件变量(Conditions)等。其中,锁是最基本的同步工具。
```python
import threading
lock = threading.Lock()
def shared_resource():
with lock:
# 临界区代码
print("Accessing shared resource")
# 创建线程
thread1 = threading.Thread(target=shared_resource)
thread2 = threading.Thread(target=shared_resource)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
```
在这个例子中,`with lock:`语句块确保了同一时间只有一个线程可以访问临界区代码。当一个线程获得了锁,其他线程将等待直到锁被释放。
### 2.2 多线程高级应用
#### 2.2.1 线程池的使用
线程池是一种多线程处理形式,它包含了固定数量的线程,并且它们一次性地由系统创建好。当有新的任务提交时,线程池中的空闲线程会被用来执行任务,任务完成后线程不会销毁,而是继续等待新的任务。
Python中的`concurrent.futures`模块提供了线程池的实现,它支持返回`Future`对象来跟踪线程池中的任务。
```python
from concurrent.futures import ThreadPoolExecutor
def task(n):
return f"Task {n} result"
# 使用线程池执行任务
with ThreadPoolExecutor(max_workers=5) as executor:
future1 = executor.submit(task, 1)
future2 = executor.submit(task, 2)
result1 = future1.result()
result2 = future2.result()
print(result1)
print(result2)
```
在这个例子中,`ThreadPoolExecutor`创建了一个线程池,它接受`max_workers`参数来指定线程池中的线程数。通过`submit`方法提交任务,`result`方法获取任务的执行结果。
#### 2.2.2 多线程性能优化
多线程性能优化是一个复杂的话题,它涉及到线程的数量、任务的性质、资源共享等多个方面。一个基本的优化方法是避免不必要的线程创建和销毁,这可以通过使用线程池来实现。
此外,减少线程竞争,合理安排线程任务,避免死锁,都是优化多线程性能的重要手段。
### 2.3 多线程实战案例
#### 2.3.1 网络爬虫的多线程实现
网络爬虫的多线程实现可以显著提高爬取效率。以下是一个简单的多线程爬虫示例:
```python
import requests
from concurrent.futures import ThreadPoolExecutor
def fetch_url(url):
try:
response = requests.get(url, timeout=5)
return (url, response.status_code)
except Exception as e:
return (url, None)
def main():
urls = ['***', '***', ...]
with ThreadPoolExecutor(max_workers=5) as executor:
results = list(executor.map(fetch_url, urls))
for url, status in results:
print(f"{url}: {status}")
if __name__ == "__main__":
main()
```
在这个例子中,我们使用`requests`库来获取网页内容,并使用`ThreadPoolExecutor`来并发地执行HTTP请求。
#### 2.3.2 多线程在数据分析中的应用
多线程也可以用于数据分析任务,例如并行处理大型数据集。以下是一个使用多线程进行数据处理的示例:
```python
import pandas as pd
from concurrent.futures import ThreadPoolExecutor
def process_data(chunk):
# 对数据块进行处理
return chunk.apply(some_function)
def main():
data = pd.read_csv('large_dataset.csv')
chunks = [chunk for chunk in pd.read_csv('large_dataset.csv', chunksize=10000)]
with ThreadPoolExecutor(max_workers=4) as executor:
results = list(executor.map(process_data, chunks))
# 合并结果
result = pd.concat(results)
if __name__ == "__main__":
main()
```
在这个例子中,我们将大型数据集分割成多个块,并使用线程池并发地处理每个数据块。然后,将所有的结果合并起来。
这个章节介绍了Python多线程编程的基本概念、高级应用以及实战案例。通过本章节的介绍,读者应该能够理解线程的基本原理,掌握线程的创建和管理,了解线程同步机制,以及如何在实战中应用多线程编程。
# 3. Python多进程编程
## 3.1 多进程的基本概念
### 3.1.1 进程的创建和管理
在Python中,多进程编程通常是通过`multiprocessing`模块来实现的。该模块提供了一个与`threading`模块类似的API,但它是用于管理进程而不是线程。进程是操作系统能够进行运算调度的最小单位,它包含了一个完整的运行环境。Python通过`multiprocessing`模块中的`Process`类来创建和管理进程。
创建一个进程的基本步骤如下:
1. 导入`multiprocessing`模块

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 核心库学习专栏!本专栏旨在全面深入地介绍 Python 核心库的各个方面,帮助您掌握其核心特性和实践应用。从数据结构和算法到面向对象编程、单元测试、性能优化、并发编程、网络编程、正则表达式、图形用户界面开发、科学计算、数据库交互和 RESTful API 构建,我们涵盖了 Python 核心库的方方面面。通过循序渐进的讲解和丰富的案例分析,本专栏将为您提供一步到位的核心库使用秘诀,助您打造高效、可维护且功能强大的 Python 代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【电子密码锁用户交互设计】:提升用户体验的关键要素与设计思路

# 1. 电子密码锁概述与用户交互的重要性
## 1.1 电子密码锁简介
电子密码锁作为现代智能家居的入口,正逐步替代传统的物理钥匙,它通过数字代码输入来实现门锁的开闭。随着技术的发展,电子密码锁正变得更加智能与安全,集成指纹、蓝牙、Wi-Fi等多种开锁方式。
## 1.2 用户交互
【制造业时间研究:流程优化的深度分析】

# 1. 制造业时间研究概念解析
在现代制造业中,时间研究的概念是提高效率和盈利能力的关键。它是工业工程领域的一个分支,旨在精确测量完成特定工作所需的时间。时间研究不仅限于识别和减少浪费,而且关注于创造一个更为流畅、高效的工作环境。通过对流程的时间分析,企业能够优化生产布局,减少非增值活动,从而缩短生产周期,提高客户满意度。
在这一章中,我们将解释时间研究的核心理念和定义,探讨其在制造业中的作用和重要性。通过
数据库备份与恢复:实验中的备份与还原操作详解

# 1. 数据库备份与恢复概述
在信息技术高速发展的今天,数据已成为企业最宝贵的资产之一。为了防止数据丢失或损坏,数据库备份与恢复显得尤为重要。备份是一个预防性过程,它创建了数据的一个或多个副本,以备在原始数据丢失或损坏时可以进行恢复。数据库恢复则是指在发生故障后,将备份的数据重新载入到数据库系统中的过程。本章将为读者提供一个关于
Vue组件设计模式:提升代码复用性和可维护性的策略

# 1. Vue组件设计模式的理论基础
在构建复杂前端应用程序时,组件化是一种常见的设计方法,Vue.js框架以其组件系统而著称,允许开发者将UI分成独立、可复用的部分。Vue组件设计模式不仅是编写可维护和可扩展代码的基础,也是实现应用程序业务逻辑的关键。
## 组件的定义与重要性
组件是Vue中的核心概念,它可以封装HTML、CSS和JavaScript代码,以供复用。理解
直播推流成本控制指南:PLDroidMediaStreaming资源管理与优化方案
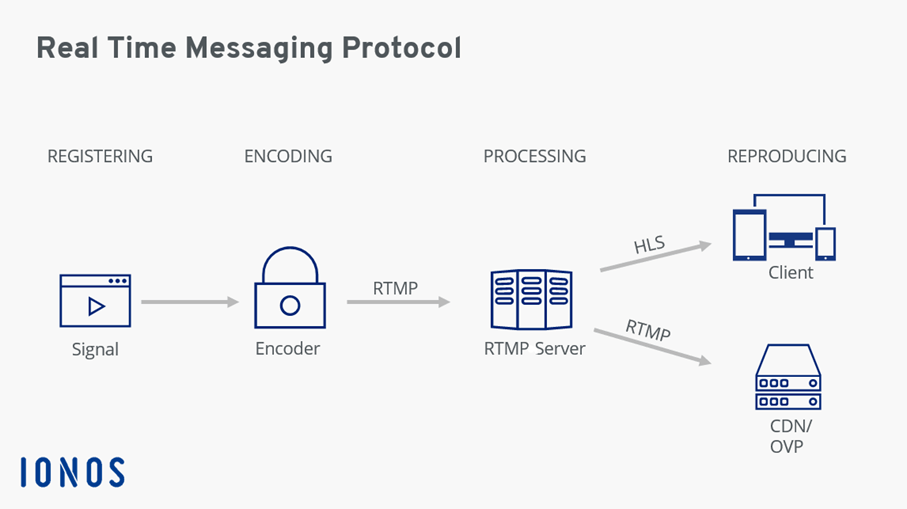
# 1. 直播推流成本控制概述
## 1.1 成本控制的重要性
直播业务尽管在近年来获得了爆发式的增长,但随之而来的成本压力也不容忽视。对于直播平台来说,优化成本控制不仅能够提升财务表现,还能增强市场竞争力。成本控制是确保直播服务长期稳定运
脉冲宽度调制(PWM)在负载调制放大器中的应用:实例与技巧

# 1. 脉冲宽度调制(PWM)基础与原理
脉冲宽度调制(PWM)是一种广泛应用于电子学和电力电子学的技术,它通过改变脉冲的宽度来调节负载上的平均电压或功率。PWM技术的核心在于脉冲信号的调制,这涉及到开关器件(如晶体管)的开启与关闭的时间比例,即占空比的调整。在占空比增加的情况下,负载上的平均电压或功率也会相
【多元回归预测】:MATLAB高级分析在地基沉降预测中的应用

# 1. 多元回归分析基础
在数据分析和统计领域,回归分析是一种强大的工具,用于研究变量之间的关系。本章将介绍回归分析的基础知识,以及多
Python编程风格

# 1. Python编程风格概述
Python作为一门高级编程语言,其简洁明了的语法吸引了全球众多开发者。其编程风格不仅体现在代码的可读性上,还包括代码的编写习惯和逻辑构建方式。好的编程风格能够提高代码的可维护性,便于团队协作和代码审查。本章我们将探索Python编程风格的基础,为后续深入学习Python编码规范、最佳实践以及性能优化奠定基础。
在开始编码之前,开发者需要了解和掌握Python的一些核心
编程深度解析:音乐跑马灯算法优化与资源利用高级教程

# 1. 音乐跑马灯算法的理论基础
音乐跑马灯算法是一种将音乐节奏与视觉效果结合的技术,它能够根据音频信号的变化动态生成与之匹配的视觉图案,这种算法在电子音乐节和游戏开发中尤为常见。本章节将介绍该算法的理论基础,为后续章节中的实现流程、优化策略和资源利用等内容打下基础。
## 算法的核心原理
音乐跑马灯算法的核心在于将音频信号通过快速傅里叶变换(FFT)解析出频率、
【SpringBoot日志管理】:有效记录和分析网站运行日志的策略

# 1. SpringBoot日志管理概述
在当代的软件开发过程中,日志管理是一个关键组成部分,它对于软件的监控、调试、问题诊断以及性能分析起着至关重要的作用。SpringBoot作为Java领域中最流行的微服务框架之一,它内置了强大的日志管理功能,能够帮助开发者高效地收集和管理日志信息。本文将从概述SpringBoot日志管理的基础
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )