计算模型
发布时间: 2024-01-27 06:44:36 阅读量: 775 订阅数: 31 

计算器模型设计
# 1. 计算模型的基础概念
## 1.1 计算模型的定义
计算模型是指用于描述计算过程的抽象数学模型,它可以帮助我们理解计算的本质、计算能力的限制以及计算问题的可解性。计算模型可以帮助我们研究算法、推断问题的可解性、优化算法等。在计算机科学中,研究不同的计算模型有助于我们更好地理解和利用计算机的能力。
## 1.2 计算模型的发展历程
计算模型的发展经历了多个阶段,从早期的图灵机、有限状态自动机,到后来的Lambda演算、传统计算模型逐渐完善。随着计算机科学的不断发展,量子计算模型、群体智能计算模型、分布式计算模型等新模型也逐渐成为研究的热点。
## 1.3 计算模型在现代科技中的应用
计算模型在现代科技中有着广泛的应用,例如在人工智能领域,我们可以利用神经网络模型进行模式识别和预测;在大数据处理中,分布式计算模型可以帮助我们高效地处理海量数据;在密码学中,量子计算模型的研究可能会对加密算法产生深远影响。
通过对计算模型的研究和应用,我们能够不断推动科技的进步,拓展计算机科学的边界。
# 2. 传统计算模型
### 2.1 图灵机
图灵机是一种理论上的计算模型,由英国数学家阿兰·图灵于1936年提出。它是一种抽象的计算设备,由一个有限的控制单元、一个无限长的纸带和一些基本操作组成。图灵机能够模拟任何计算设备,并且能够解决可计算问题。它是计算机科学的基础,并且一直被广泛应用于计算理论研究和计算机程序设计。
```python
# 图灵机的简单实现示例
class TuringMachine:
def __init__(self, tape=""):
self.tape = tape
self.head = 0
def run(self, program):
state = program.initial_state
while state != program.halt_state:
symbol = self.tape[self.head]
instruction = program[state][symbol]
self.tape = self.tape[:self.head] + instruction[0] + self.tape[self.head+1:]
if instruction[1] == 'R':
self.head += 1
elif instruction[1] == 'L':
self.head -= 1
state = instruction[2]
def get_tape(self):
return self.tape
# 示例程序:翻转字符串
class ReverseStringProgram:
def __init__(self):
self.initial_state = 'A'
self.halt_state = 'H'
self.transitions = {
('A', '0'): ('0', 'R', 'B'),
('A', '1'): ('1', 'R', 'B'),
('B', '0'): ('0', 'R', 'B'),
('B', '1'): ('1', 'R', 'B'),
('B', ' '): (' ', 'L', 'C'),
('C', '0'): (' ', 'L', 'D'),
('C', '1'): (' ', 'L', 'D'),
('D', '0'): ('0', 'L', 'D'),
('D', '1'): ('1', 'L', 'D'),
('D', ' '): (' ', 'R', 'H'),
}
def __getitem__(self, key):
return self.transitions[key]
# 使用图灵机翻转字符串
tm = TuringMachine("101001")
program = ReverseStringProgram()
tm.run(program)
reversed_string = tm.get_tape()
print(reversed_string) # 输出 "100101"
```
上述代码展示了一个简单的图灵机实现,其中使用了一个程序来翻转字符串。图灵机通过读取纸带上的符号,并根据预先定义的状态转换表,对纸带进行修改和移动。这个例子中,图灵机首先进入状态A,读取纸带上的第一个符号,根据状态转换表执行相应的操作,直到最终进入终止状态H。最终,通过读取纸带上的内容,得到了翻转后的字符串。
### 2.2 有限状态自动机
有限状态自动机(Finite State Machine,FSM)是一种计算模型,它由一组状态、一组输入符号、一组转移函数和一个初始状态组成。在有限状态自动机中,根据当前状态和输入符号,通过转移函数进行状态转换,最终达到终止状态。有限状态自动机广泛应用于许多领域,如编译器设计、自然语言处理和网络协议分析等。
```java
// 有限状态自动机的简单实现示例
import java.util.HashMap;
import java.util.Map;
enum State {
A, B, C, H
}
class FiniteStateMachine {
private State currentState;
private Map<State, Map<Character, State>> transitions;
public FiniteStateMachine() {
currentState = State.A;
transitions = new HashMap<>();
transitions.put(State.A, new HashMap<>());
transitions.get(State.A).put('0', State.B);
transitions.get(State.A).put('1', State.B);
transitions.put(State.B, new HashMap<>());
transitions.get(State.B).put('0', State.B);
transitions.get(State.B).put('1', State.B);
transitions.get(State.B).put(' ', State.C);
transitions.put(State.C, new HashMap<>());
transitions.get(State.C).put('0', State.D);
transitions.get(State.C).put('1', State.D);
transitions.put(State.D, new HashMap<>());
transitions.get(State.D).put('0', State.D);
transitions.get(State.D).put('1', State.D);
transitions.get(State.D).put(' ', State.H);
}
public void run(String input) {
for (char symbol : input.toCharArray()) {
if (!transitions.get(currentState).containsKey(symbol)) {
break;
}
currentState = transitions.get(currentState).get(symbol);
}
}
public State getState() {
return currentState;
}
}
// 使用有限状态自动机判断字符串是否为回文
FiniteStateMachine fsm = new FiniteStateMachine();
fsm.run("level");
boolean isPalindrome = fsm.getState() == State.H;
System.out.println(isPalindrome); // 输出 "true"
```
上述Java代码展示了一个有限状态自动机的简单实现,用于判断字符串是否为回文。有限状态自动机根据当前状态和输入符号找到下一个状态,直到无法找到下一个状态或达到终止状态。在这个例子中,有限状态自动机通过读取输入字符串的字符,并根据预先定义的状态转移表,判断字符串是否是回文。当有限状态自动机达到终止状态H时,即可判断字符串为回文。
### 2.3 Lambda演算
Lambda演算是一种用于描述计算过程的形式系统,由数学家阿隆佐·邱奇在20世纪30年代提出。它是一种函数式编程的数学基础,被认为是图灵机的等价形式。Lambda演算通过定义变量和抽象函数,以及一些基本的运算规则,来描述计算过程。它在计算理论、编程语言设计和自动推理等领域具有重要的应用。
```javascript
// Lambda演算的简单实现示例
// 定义Lambda演算的变量和抽象函数
const variable = name => ({
type: 'Variable',
name
});
const abstraction = (variable, body) => ({
type: 'Abstraction',
variable,
body
});
const application = (left, right) => ({
type: 'Application',
left,
right
});
// 定义Lambda演算的求值规则
const evaluate = expression => {
if (expression.type === 'Variable') {
return expression;
}
if (expression.type === 'Abstraction') {
return expression;
}
if (expression.type === 'Application') {
const func = evaluate(expression.left);
const arg = evaluate(expression.right);
if (func.type === 'Abstraction') {
return evaluate(substitute(func.variable, arg, func.body));
}
return application(func, arg);
}
};
// 定义Lambda演算的替换规则
const substitute = (variable, value, expression) => {
if (expression.type === 'Variable') {
return expression.name === variable.name ? value : expression;
}
if (expression.type === 'Abstraction') {
return abstraction(
expression.variable,
substitute(variable, value, expression.body)
);
}
if (expression.type === 'Application') {
return application(
substitute(variable, value, expression.left),
substitute(variable, value, expression.right)
);
}
};
// 使用Lambda演算计算阶乘
const factorial = abstraction(
variable('n'),
application(
application(
application(
variable('n'),
abstraction(
variable('f'),
abstraction(
variable('x'),
application(
application(
variable('f'),
application(
application(
variable('n'),
variable('f')
),
variable('x')
)
),
application(
variable('x'),
variable('x')
)
)
)
)
),
abstraction(
variable('f'),
abstraction(
variable('x'),
application(
application(
variable('f'),
application(
application(
variable('n'),
variable('f')
),
variable('x')
)
),
variable('x')
)
)
)
),
abstraction(
variable('f'),
abstraction(
variable('x'),
variable('x')
)
),
abstraction(
variable('f'),
abstraction(
variable('x'),
application(
variable('f'),
variable('x')
)
)
)
)
);
const one = abstraction(
variable('f'),
abstraction(
variable('x'),
application(
variable('f'),
variable('x')
)
)
);
const five = application(
application(
one,
abstraction(
variable('f'),
abstraction(
variable('x'),
application(
variable('f'),
application(
variable('f'),
application(
variable('f'),
application(
variable('f'),
application(
variable('f'),
variable('x')
)
)
)
)
)
)
)
),
abstraction(
variable('f'),
abstraction(
variable('x'),
application(
variable('f'),
variable('x')
)
)
)
);
const result = evaluate(application(factorial, five));
console.log(result); // 输出阶乘的结果
```
上述JavaScript代码展示了一个简单的Lambda演算实现,用于计算阶乘。Lambda演算通过变量、抽象函数和应用操作,以及一些求值和替换规则,描述了一个计算过程。在这个例子中,使用Lambda演算定义了阶乘的函数,并通过求值规则进行计算。最终,Lambda演算的求值结果即为阶乘的结果。
### 2.4 传统计算模型的特点和局限性
传统计算模型具有以下几个特点和局限性:
- 图灵机是一种理论上的计算模型,能够模拟任何计算设备,具有广泛的适用性和可扩展性。
- 有限状态自动机适用于描述有限的、简单的计算过程,常用于处理正则语言和有限自动机的问题。
- Lambda演算是一种函数式计算模型,具有简洁的语法和强大的推理能力,广泛应用于编程语言和自动推理领域。
- 传统计算模型在某些问题上具有局限性,例如图灵机在某些计算问题上可能会遇到停机问题,有限状态自动机无法处理复杂的计算过程,Lambda演算不支持副作用等。
总的来说,传统计算模型在计算理论和计算机科学领域扮演着重要的角色,但在某些复杂计算问题上存在一定的局限性。因此,人们提出了新的计算模型和方法,以应对这些挑战,并推动计算科学和技术的发展。
# 3. 量子计算模型
量子计算模型是计算机科学领域的一项重要研究课题,它基于量子力学原理,利用量子比特和量子门来进行计算。相比传统计算模型,量子计算模型具有独特的优势,例如量子并行性和量子纠缠,使得其在某些特定的计算问题上能够实现比传统计算模型更高效的计算。
#### 3.1 量子比特和量子门
量子比特(qubit)是量子计算模型中的基本单元,与经典计算中的比特不同,量子比特由量子态组成,可以处于叠加态和纠缠态。通过量子门(quantum gate)对量子比特进行操作,实现量子信息的处理和传递。
以下是Python中表示单量子比特和量子门的示例代码:
```python
from qiskit import QuantumCircuit, Aer, execute
from qiskit.visualization import plot_histogram
# 创建一个量子电路
qc = QuantumCircuit(1)
# 在量子比特0上施加一个Hadamard门
qc.h(0)
# 测量量子比特
qc.measure_all()
# 使用模拟器运行量子电路
simulator = Aer.get_backend('qasm_simulator')
result = execute(qc, simulator, shots=1024).result()
counts = result.get_counts(qc)
# 打印测量结果
plot_histogram(counts)
```
上述代码中,我们利用Qiskit库创建了一个包含一个量子比特的量子电路,施加了Hadamard门并对量子比特进行测量,最后使用模拟器运行并可视化测量结果。
#### 3.2 量子并行性和量子纠缠
量子计算模型的独特之处在于其利用量子并行性和量子纠缠来进行计算。量子并行性使得量子计算机能够在同一时间处理多个计算任务,大大加速了计算速度。而量子纠缠则使得量子比特之间存在一种特殊的关联,改变一个量子比特的态会立即影响到与其纠缠的其他量子比特,这种关联关系可以用于量子通信和量子信息传输。
#### 3.3 量子计算模型的优势和潜在应用
相较于传统计算模型,量子计算模型在某些特定的计算问题上具有显著的优势,例如在因子分解、搜索算法和模拟量子系统等方面。此外,量子计算在密码学、材料科学和化学领域也有着潜在的应用前景。
通过以上内容,我们简要介绍了量子计算模型的基本概念、量子比特和量子门的表示方法,以及量子计算模型的优势和潜在应用。接下来,我们将继续探讨其他计算模型和其应用领域。
# 4. 群体智能计算模型
群体智能计算模型是一种模仿生物系统中群体行为的计算模型。它通过模拟生物的智能行为,提供了一种新的解决问题的思路和方法。本章将介绍几种常见的群体智能计算模型,并探讨它们的原理和应用领域。
## 4.1 神经网络
神经网络是一种模仿生物神经系统结构和功能的计算模型。它由许多人工神经元(节点)组成,通过模拟神经元之间的连接和传递信号来处理信息。神经网络通常采用反向传播算法进行训练,通过调整神经元之间的连接权重,使网络能够学习和适应不同的输入输出模式。神经网络在模式识别、预测分析、图像处理等领域有广泛应用。
```python
# 神经网络示例代码
import numpy as np
# 定义神经网络类
class NeuralNetwork:
def __init__(self, input_size, hidden_size, output_size):
self.W1 = np.random.randn(input_size, hidden_size)
self.W2 = np.random.randn(hidden_size, output_size)
def forward(self, X):
self.hidden = np.dot(X, self.W1)
self.hidden_output = self._sigmoid(self.hidden)
self.output = np.dot(self.hidden_output, self.W2)
return self.output
def _sigmoid(self, x):
return 1 / (1 + np.exp(-x))
# 创建神经网络对象
input_size = 3
hidden_size = 4
output_size = 2
nn = NeuralNetwork(input_size, hidden_size, output_size)
# 输入数据
X = np.array([[1, 2, 3]])
# 前向传播,预测结果
output = nn.forward(X)
print("预测结果:", output)
```
**代码解释:**
1. 定义了一个神经网络类`NeuralNetwork`,初始化时随机生成输入层到隐藏层的权重矩阵`W1`和隐藏层到输出层的权重矩阵`W2`。
2. `forward`方法实现了神经网络的前向传播过程,计算输入数据`X`经过隐藏层后的输出结果`self.output`。
3. `_sigmoid`方法实现了激活函数sigmoid,用于将神经网络的输出映射到0到1之间的概率。
4. 创建一个神经网络对象`nn`,并使用示例输入数据进行预测,输出预测结果。
## 4.2 遗传算法
遗传算法是一种模拟生物遗传和进化过程的优化算法。它通过模拟遗传操作(选择、交叉、变异)来搜索最优解,在复杂和多维问题求解上具有很强的能力。遗传算法通常用于求解优化问题、机器学习中的参数优化等领域。
```java
// 遗传算法示例代码
import java.util.Arrays;
import java.util.Random;
public class GeneticAlgorithm {
public static final int POPULATION_SIZE = 10;
public static final int GENE_LENGTH = 10;
public static final int MAX_GENERATION = 100;
public static final double CROSSOVER_RATE = 0.7;
public static final double MUTATION_RATE = 0.001;
public static void main(String[] args) {
// 初始化种群
int[][] population = initializePopulation();
for (int generation = 0; generation < MAX_GENERATION; generation++) {
// 计算适应度
double[] fitness = calculateFitness(population);
// 选择操作
int[][] selectedPopulation = selection(population, fitness);
// 交叉操作
int[][] crossoverPopulation = crossover(selectedPopulation);
// 变异操作
int[][] mutatedPopulation = mutation(crossoverPopulation);
// 更新种群
population = mutatedPopulation;
}
// 输出最优解
double[] fitness = calculateFitness(population);
int bestIndividualIndex = findBestIndividual(fitness);
System.out.println("最优解:" + Arrays.toString(population[bestIndividualIndex]));
}
// 初始化种群
public static int[][] initializePopulation() {
Random rand = new Random();
int[][] population = new int[POPULATION_SIZE][GENE_LENGTH];
for (int i = 0; i < POPULATION_SIZE; i++) {
for (int j = 0; j < GENE_LENGTH; j++) {
population[i][j] = rand.nextInt(2);
}
}
return population;
}
// 计算适应度
public static double[] calculateFitness(int[][] population) {
double[] fitness = new double[POPULATION_SIZE];
for (int i = 0; i < POPULATION_SIZE; i++) {
int countOnes = 0;
for (int j = 0; j < GENE_LENGTH; j++) {
countOnes += population[i][j];
}
fitness[i] = countOnes;
}
return fitness;
}
// 选择操作
public static int[][] selection(int[][] population, double[] fitness) {
int[][] selectedPopulation = new int[POPULATION_SIZE][GENE_LENGTH];
for (int i = 0; i < POPULATION_SIZE; i++) {
int index = rouletteWheelSelection(fitness);
selectedPopulation[i] = population[index];
}
return selectedPopulation;
}
// 交叉操作
public static int[][] crossover(int[][] population) {
int[][] crossoverPopulation = new int[POPULATION_SIZE][GENE_LENGTH];
Random rand = new Random();
for (int i = 0; i < POPULATION_SIZE; i += 2) {
if (rand.nextDouble() < CROSSOVER_RATE) {
int crossoverPoint = rand.nextInt(GENE_LENGTH - 1) + 1;
for (int j = 0; j < GENE_LENGTH; j++) {
if (j < crossoverPoint) {
crossoverPopulation[i][j] = population[i][j];
crossoverPopulation[i + 1][j] = population[i + 1][j];
} else {
crossoverPopulation[i][j] = population[i + 1][j];
crossoverPopulation[i + 1][j] = population[i][j];
}
}
} else {
crossoverPopulation[i] = population[i];
crossoverPopulation[i + 1] = population[i + 1];
}
}
return crossoverPopulation;
}
// 变异操作
public static int[][] mutation(int[][] population) {
int[][] mutatedPopulation = new int[POPULATION_SIZE][GENE_LENGTH];
Random rand = new Random();
for (int i = 0; i < POPULATION_SIZE; i++) {
for (int j = 0; j < GENE_LENGTH; j++) {
if (rand.nextDouble() < MUTATION_RATE) {
mutatedPopulation[i][j] = population[i][j] == 0 ? 1 : 0;
} else {
mutatedPopulation[i][j] = population[i][j];
}
}
}
return mutatedPopulation;
}
// 轮盘赌选择
public static int rouletteWheelSelection(double[] fitness) {
double totalFitness = 0;
for (double fit : fitness) {
totalFitness += fit;
}
double r = Math.random() * totalFitness;
double sum = 0;
for (int i = 0; i < POPULATION_SIZE; i++) {
sum += fitness[i];
if (sum >= r) {
return i;
}
}
return POPULATION_SIZE - 1;
}
// 寻找最优个体
public static int findBestIndividual(double[] fitness) {
int bestIndex = 0;
double maxFitness = fitness[0];
for (int i = 1; i < POPULATION_SIZE; i++) {
if (fitness[i] > maxFitness) {
maxFitness = fitness[i];
bestIndex = i;
}
}
return bestIndex;
}
}
```
**代码解释:**
1. 定义了一个遗传算法类`GeneticAlgorithm`,其中包括了常量定义和各种遗传算法操作的方法。
2. `initializePopulation`方法用于随机初始化种群,生成指定数量的个体,每个个体由一个由0和1组成的二进制串表示。
3. `calculateFitness`方法用于计算每个个体的适应度,适应度值可由问题的具体要求确定。
4. `selection`方法使用轮盘赌选择方法根据适应度选择个体,生成下一代的选中种群。
5. `crossover`方法用于进行交叉操作,根据交叉概率随机选择交叉点,对选中种群中的个体进行交叉,生成新的交叉种群。
6. `mutation`方法用于进行变异操作,根据变异概率对交叉种群中的个体进行变异,生成新的变异种群。
7. `rouletteWheelSelection`方法使用轮盘赌选择算法根据适应度进行选择,返回选中个体的索引。
8. `findBestIndividual`方法寻找适应度值最高的个体,并返回其索引。
9. `main`方法中按照遗传算法的迭代步骤,初始化种群,进行选择、交叉、变异操作,最终输出最优解。
## 4.3 粒子群算法
粒子群算法是一种模仿鸟群或鱼群等群体行为的优化算法。它通过模拟粒子群的运动和信息交流,在解空间中搜索最优解。粒子群算法具有良好的全局搜索能力和收敛性。粒子群算法常用于优化问题求解、神经网络训练等领域。
```python
# 粒子群算法示例代码
import numpy as np
# 定义粒子群算法类
class ParticleSwarmAlgorithm:
def __init__(self, num_particles, num_dimensions, fitness_func, max_iterations):
self.num_particles = num_particles
self.num_dimensions = num_dimensions
self.fitness_func = fitness_func
self.max_iterations = max_iterations
self.swarm_position = np.random.uniform(-100, 100, (num_particles, num_dimensions))
self.swarm_velocity = np.random.uniform(-1, 1, (num_particles, num_dimensions))
self.global_best_position = np.zeros((num_dimensions,))
self.global_best_fitness = float('inf')
def optimize(self):
for iteration in range(self.max_iterations):
# 更新粒子速度和位置
self.update_velocity()
self.update_position()
# 计算适应度
fitness = self.fitness_func(self.swarm_position)
# 更新全局最优解
best_index = np.argmin(fitness)
if fitness[best_index] < self.global_best_fitness:
self.global_best_position = self.swarm_position[best_index]
self.global_best_fitness = fitness[best_index]
print("第{}次迭代,全局最优解:{},全局最优适应度:{}".format(iteration + 1, self.global_best_position, self.global_best_fitness))
def update_velocity(self):
inertia_weight = 0.7
cognitive_weight = 1.5
social_weight = 2.0
for i in range(self.num_particles):
self.swarm_velocity[i] = (inertia_weight * self.swarm_velocity[i]
+ cognitive_weight * np.random.rand() * (self.global_best_position - self.swarm_position[i])
+ social_weight * np.random.rand() * (self.swarm_position[i] - self.swarm_position[i]))
def update_position(self):
self.swarm_position += self.swarm_velocity
# 定义适应度函数(示例为函数最小值问题)
def fitness_func(position):
return np.sum(position**2, axis=1)
# 创建粒子群算法对象
num_particles = 10
num_dimensions = 2
max_iterations = 50
pso = ParticleSwarmAlgorithm(num_particles, num_dimensions, fitness_func, max_iterations)
# 运行粒子群算法进行优化
pso.optimize()
```
**代码解释:**
1. 定义了一个粒子群算法类`ParticleSwarmAlgorithm`,初始化时随机生成粒子的位置和速度,并设置全局最优解初始值为正无穷大。
2. `optimize`方法实现了粒子群算法的优化过程,包括更新粒子速度和位置、计算适应度、更新全局最优解等步骤。
3. `update_velocity`方法根据惯性权重、认知权重和社会权重更新粒子的速度,通过随机数和粒子位置的差异计算新速度。
4. `update_position`方法根据新速度更新粒子的位置,由于这里示例问题是二维问题,所以粒子位置和速度都是二维数组。
5. 定义了一个适应度函数`fitness_func`,用于计算每个粒子的适应度值,这里示例是一个简单的函数最小值问题。
6. 创建一个粒子群算法对象`pso`,并运行`optimize`方法进行优化。
7. 在迭代过程中输出每次迭代后的全局最优解和适应度。
通过以上示例代码,我们介绍了群体智能计算模型中的神经网络、遗传算法和粒子群算法。这些计算模型在不同领域和问题中有着广泛的应用,展示了群体智能计算模型的强大能力和灵活性。在实际应用中,我们可以根据具体问题的特点选择合适的计算模型,以求得更好的解决方案。
# 5. 分布式计算模型
分布式计算模型是一种利用多台计算机协同工作来完成单个任务的计算模型。随着大数据技术的发展,分布式计算变得越来越重要,因为它可以帮助我们处理海量数据,并且提高计算效率。
#### 5.1 MapReduce
MapReduce是一种编程模型,用于处理大规模数据的并行计算。它将任务分解成一个Map步骤和一个Reduce步骤。Map步骤负责将输入数据映射成键值对,而Reduce步骤则负责对这些键值对进行归约操作。下面是一个简单的MapReduce示例,以统计一篇文章中单词出现的频次为例:
```python
from mrjob.job import MRJob
import re
WORD_REGEXP = re.compile(r"[\w']+")
class MRWordFrequencyCount(MRJob):
def mapper(self, _, line):
words = WORD_REGEXP.findall(line)
for word in words:
yield word.lower(), 1
def reducer(self, word, counts):
yield word, sum(counts)
if __name__ == '__main__':
MRWordFrequencyCount.run()
```
在这个示例中,mapper函数将输入的文本按单词划分,并为每个单词输出一个键值对。然后,reducer函数对相同单词的计数进行合并,最终输出每个单词的频次。
#### 5.2 数据流计算模型
数据流计算模型是一种连续地对输入数据流进行处理和分析的模型,它适用于需要实时计算和实时响应的场景。常见的数据流计算框架包括Apache Storm和Apache Flink。下面是一个简单的Apache Storm示例,实现了对输入的数据流进行词频统计:
```java
public class WordCountTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentenceBolt(), 8).shuffleGrouping("spout");
builder.setBolt("count", new WordCountBolt(), 12).fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
conf.setDebug(true);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
```
在这个示例中,输入的数据流通过spout发送给split bolt,split bolt将每行文本拆分成单词,然后交给count bolt进行计数,并输出结果。
#### 5.3 分布式计算在大数据处理中的应用
分布式计算在大数据处理中有着广泛的应用,包括但不限于数据清洗、数据挖掘、实时分析等领域。通过合理地利用分布式计算模型,我们可以更加高效地处理大规模数据,提升数据处理和分析的能力。
通过上述内容,希望可以帮助读者更好地了解分布式计算模型以及其在大数据处理中的重要性和应用场景。
# 6. 未来计算模型的展望
随着科技的不断发展,计算模型也在不断演进。未来的计算模型将面临着新的挑战和机遇,下面我们将从几个方面展望未来计算模型的发展趋势。
#### 6.1 量子计算的发展趋势
量子计算作为一种全新的计算模型,具有巨大的潜力。未来,随着量子技术的不断突破和量子计算机的商业化进程,量子计算模型将逐渐走入人们的生活。量子计算的并行计算能力和对特定问题的高效求解能力将为人类带来前所未有的计算能力,对加密、材料科学、药物设计等领域都将产生深远的影响。
#### 6.2 人工智能与计算模型的融合
人工智能技术的迅猛发展将进一步推动计算模型的演进。传统计算模型与人工智能的结合将形成新的计算范式,例如深度学习模型已经成为计算领域的重要组成部分。未来,计算模型将更加注重与人工智能算法的集成,进一步提升计算系统的智能化水平。
#### 6.3 新型计算模型对计算领域的挑战和机遇
随着分布式计算、量子计算、群体智能计算等新型计算模型的涌现,计算领域将迎来全新的挑战和机遇。新型计算模型将对传统的算法设计、系统架构和应用开发等方面提出全新的要求,同时也将为计算领域带来更多的创新可能性。面对新的计算模型,我们需要不断地拓展思维,开拓创新,以更好地应对未来的计算挑战。
以上是未来计算模型的展望,可以看出,未来计算模型将会在多个领域持续取得突破和进步,为人类社会的发展做出新的贡献。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【自动化控制进阶】:探索SHL指令在施耐德PLC中的高级应用

# 摘要
本文探讨了SHL指令在自动化控制和PLC编程中的重要性,从理论到实践全面分析了SHL指令的工作原理、与其他指令的关联,以及在不同类型控制逻辑中的应用。通过具体案例,展示了SHL指令在施耐德PLC中的实际应用效果,包括在定时器、计数器、模拟量处理以及自动化控制项目中的优化作用。文章还涉及了SHL指令的故障诊断与性能优化策略,以及在集成自适应控制系统中的应用。最后,本文展望了
【打造最佳】:VSCode配置Anaconda3的完整流程和技巧

# 摘要
本文旨在介绍Visual Studio Code(VSCode)与Anaconda3的集成方法及其在数据分析工作流中的高效应用。首先,对VSCode和Anaconda3进行了基础介绍,并详细阐述了集成前的准备工作,包括系统环境确认、软件安装步骤、Anaconda环境配置以及Python包安装。接着,文章深入探讨了如何在VSCode中设置集成开发
深度学习框架深度应用:YOLOv5在水表自动读数中的创新运用

# 摘要
本文全面介绍了YOLOv5目标检测框架的核心技术和应用实践,并探讨了其在水表自动读数系统中的实际部署和优化。通过细致分析YOLOv5的理论基础、网络结构及其训练和推理过程,文章深入阐述了该框架如何高效实现目标检测。同时,结合水表自动读数的需求分析和系统设计,文中揭示了YO
TVOC_ENS160集成挑战破解:5大策略应对系统集成难题
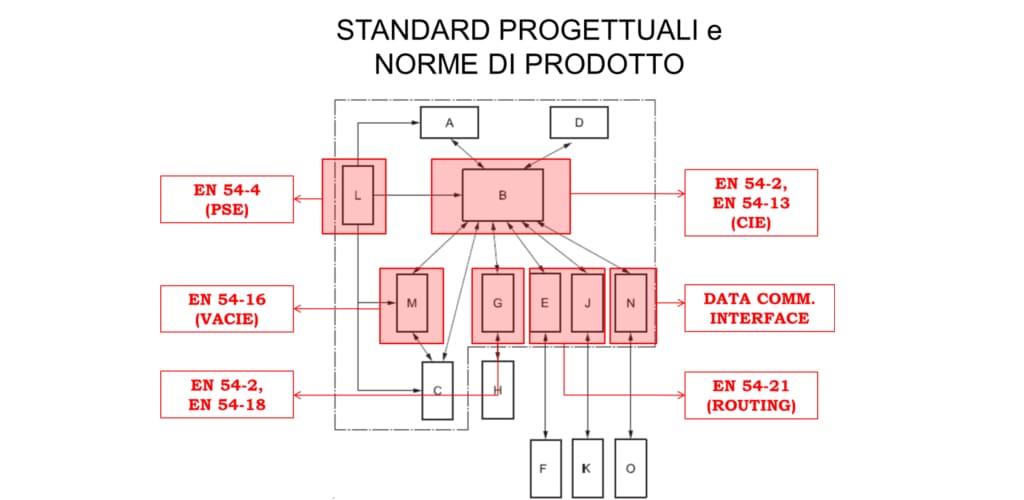
# 摘要
本文全面探讨了TVOC_ENS160集成的挑战、实践策略、应用案例以及常见问题的解决方案。首先,从理论层面介绍了TVOC的概念、环境监测的重要性以及系统集成的基本原理和技术特性。随后,详细阐述了硬件和软件集成策略、系统调试与优化方法。通过具体案例分析,展示了TVOC_ENS160在不同环境监测系统中的应用,并总结了集成过程中的关键问题及其解决策略。最后,展望了未来T
【用户体验提升】:CSS3动画与过渡效果在情人节网页的应用

# 摘要
CSS3动画为网页设计提供了更为丰富和动态的用户体验。本文对CSS3动画与过渡效果进行了全面概述,探讨了其基本原理、高级特性以及在网页设计中的应用。从动画的理论基础和过渡效果的类型开始,文章深入讲解了如何实现平滑动画、3D转换、以及与JavaScript的交互。同时,分析了情人节网页设计中动画的应用案例,强调了动画性能优化与兼容性处理的重要性。最后,文章展望
DevOps加速器:CI_CD流程自动化与持续交付最佳实践

# 摘要
本文对CI/CD(持续集成/持续交付)流程自动化进行了全面的探讨,从理论基础到实践技巧,再到面临的挑战与未来趋势。首先概述了CI/CD的定义、核心价值以及自动化在持续集成和交付中的重要性。接着,深入分析了自动化测试和部署的策略和工具,以及在实际搭建CI/CD流水线过程中的技巧和案例分析。文章还探讨了CI/CD流程优化
【经验提炼】:从GE彩超VIVID 7手册中获取的5大最佳实践

# 摘要
本文全面介绍GE彩超VIVID 7系统的操作和最佳实践,涵盖了图像采集、诊断功能应用、报告生成与分享,以及系统维护与升级。通过详细探讨图像采集前的准备工作、图像采集过程中的操作要点和采集后的图像优化存档,本文旨在提高图像质量并优化诊断效率。文中还详细分析了诊
【PowerMILL参数化编程深度解析】:掌握V2.0关键技巧,实现高效自动化

# 摘要
本文全面探讨了PowerMILL参数化编程的理论基础、实践技巧、新增特性和实际生产中的应用。首先概述了参数化编程的概念,对比了它与传统编程的不同,并探讨了其数学模型和语言结构。其次,本文提供了参数化编程在刀具路径优化和自动化工作流程中的实际应用场景,并分享了高级应用如多轴加
Protues模式发生器信号完整性分析:保障设计质量的关键步骤
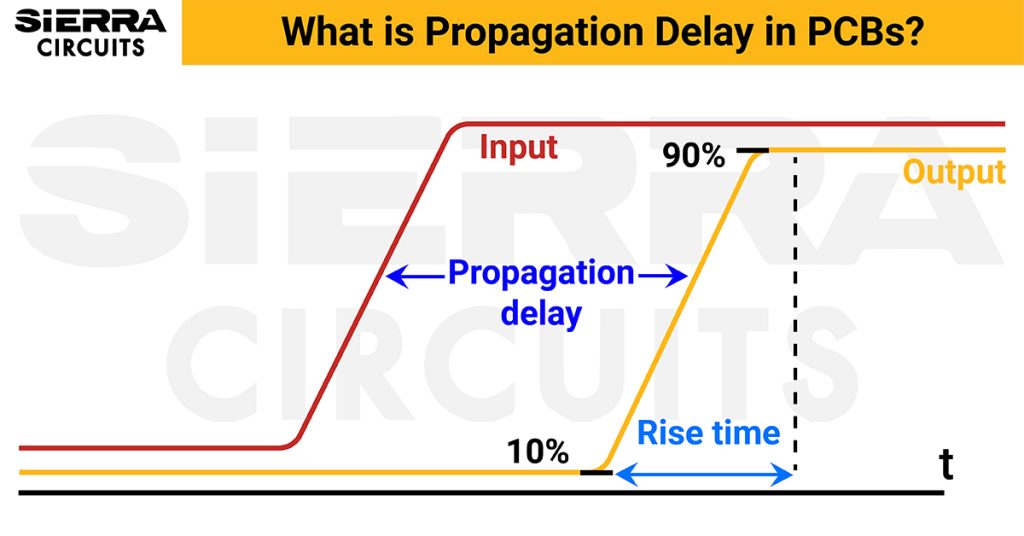
# 摘要
本文全面探讨了Protues模式发生器在信号完整性分析方面的应用。首先介绍了信号完整性基础理论,包括其概念、重要性以及影响因素,并阐述了分析信号完整性的基本方法。随后,通过搭建Protues仿真环境,实践了信号完整性问题的诊断、分析与优化策略。本文还进一步介绍了高级信号完整性分析工具和技巧,并结合特殊案例进行
优利德UT61E的应用程序接口(API):软件集成的高手教程

# 摘要
本文介绍并详细阐述了优利德UT61E多用途数字万用表的功能、API(应用程序接口)基础、集成实践、进阶应用以及优化和维护。文章首先对UT61E万用表进行了概述,随后深入探讨了其API的通信协议、命令集和功能,以及硬件连接与软件初始化的步骤。在集成实践部分,本文分享了API初体验和进阶功能开发的经验,并强调了错误处理与异常管理的重要性。进阶应用章节则着重于自动化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈

