处理不平衡数据集的逻辑回归方法
发布时间: 2023-12-17 08:01:13 阅读量: 74 订阅数: 24 

logistic regression (逻辑回归实验数据)
# 章节一:不平衡数据集的问题
## 1.1 什么是不平衡数据集
在机器学习和数据挖掘中,不平衡数据集是指目标变量的类别分布存在非常不平衡的情况。通常,指一个类别的样本数量远远少于其他类别的样本数量。例如,在一个二分类问题中,其中一个类别的样本只占总样本数量的很小一部分,而另一个类别的样本数量非常大。
## 1.2 不平衡数据集带来的挑战
处理不平衡数据集时,会面临以下挑战:
- **训练偏倚(Training Bias)**:由于样本分布不平衡,模型更容易倾向于学习出对多数类的预测,而对少数类的预测效果不好。
- **不准确评估(Inaccurate Evaluation)**:传统的性能评估指标(如准确率)在不平衡数据集中往往不足以反映模型的真实性能,因为其中一个类别的样本数量过多可能使模型在这个类别上准确率很高,但在少数类别上准确率很低。
- **过拟合(Overfitting)**:由于训练集中某些类别的样本数量过少,模型可能会过度拟合这些少数类的样本,导致在真实情况下无法很好地泛化。
## 1.3 不平衡数据集对逻辑回归的影响
逻辑回归是一种常用的分类算法,但在不平衡数据集中使用逻辑回归可能会遇到一些问题。由于逻辑回归基于最大似然估计来估计模型参数,它对训练数据中的样本分布敏感。在不平衡数据集中,多数类样本过多的情况下,逻辑回归可能会倾向于预测出多数类,并且少数类样本数量少时难以拟合其真实分布,导致对少数类的预测效果较差。
## 章节二:常见的处理不平衡数据集的方法
不平衡数据集是指在分类问题中,不同类别的样本数量差别很大。在现实场景中,这样的数据集非常常见,例如信用卡欺诈检测、罕见疾病诊断等。处理不平衡数据集是机器学习和数据挖掘中的一个重要问题,针对不平衡数据集,常见的处理方法包括过采样、欠采样和使用集成方法。接下来将分别介绍这些方法。
### 2.1 过采样方法
过采样方法是通过增加少数类样本的方法来平衡数据集。常见的过采样方法包括随机过采样、SMOTE(Synthetic Minority Over-sampling Technique)等。随机过采样是简单粗暴的复制少数类样本,由此增加少数类样本的数量,直接解决了数据不平衡的问题。而SMOTE则是一种生成合成样本的方法,它通过对少数类样本进行插值,产生新的少数类样本,从而平衡数据集。
### 2.2 欠采样方法
与过采样相反,欠采样方法是通过减少多数类样本的方法来平衡数据集。常见的欠采样方法包括随机欠采样、NearMiss等。随机欠采样是直接丢弃多数类样本,从而减少多数类样本的数量,使得数据集平衡。而NearMiss是一种基于距离的欠采样方法,它会保留那些离少数类样本较近的多数类样本,以保证分类边界的清晰度。
### 2.3 使用集成方法
集成方法是通过结合多个分类器的预测结果来得到最终的分类结果,常见的集成方法包括Bagging、Boosting等。对于不平衡数据集,可以通过集成方法来平衡数据集,例如使用不同权重的分类器来处理少数类和多数类样本。
## Chapter 3: Review of Logistic Regression Model
Logistic Regression is a commonly used method when dealing with imbalanced datasets. In this chapter, we will review the basic principles of Logistic Regression and its application in imbalanced datasets.
### 3.1 Logistic Regression Basics
Logistic Regression is a supervised learning algorithm used for binary classification problems. It predicts the probability of an event occurring by fitting the input features to a logistic function. The logistic function, also known as the sigmoid function, is defined as:
where `x` represents the input features and `β` represents the coefficients of the logistic regression model.
The logistic regression model can be trained using maximum likelihood estimation, which aims to find the coefficients that maximize the likelihood of the

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了logistic回归在各个领域的应用和相关技术。从入门指南开始,逐步介绍了逻辑回归模型的数学原理、参数估计方法和基于梯度下降的训练技术,以及评价指标和性能度量。此外,专栏还讨论了特征选择对逻辑回归模型性能的影响,以及处理不平衡数据集和多类别问题的方法。同时,还探讨了正则化的意义和作用,以及在异常检测、离群点分析、推荐系统、文本分类、图像识别、金融风控、时间序列预测、医学诊断和社交网络分析中的应用。最后,专栏也对逻辑回归模型的解释性和可解释性进行了探讨,为读者提供了全面的视角和应用指南。通过本专栏的学习,读者将对logistic回归有着更深入的了解,并能够在实际应用中灵活运用。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电子组件可靠性快速入门:IEC 61709标准的10个关键点解析
# 摘要
电子组件可靠性是电子系统稳定运行的基石。本文系统地介绍了电子组件可靠性的基础概念,并详细探讨了IEC 61709标准的重要性和关键内容。文章从多个关键点深入分析了电子组件的可靠性定义、使用环境、寿命预测等方面,以及它们对于电子组件可靠性的具体影响。此外,本文还研究了IEC 61709标准在实际应用中的执行情况,包括可靠性测试、电子组件选型指导和故障诊断管理策略。最后,文章展望了IEC 61709标准面临的挑战及未来趋势,特别是新技术对可靠性研究的推动作用以及标准的适应性更新。
# 关键字
电子组件可靠性;IEC 61709标准;寿命预测;故障诊断;可靠性测试;新技术应用
参考资源
KEPServerEX扩展插件应用:增强功能与定制解决方案的终极指南
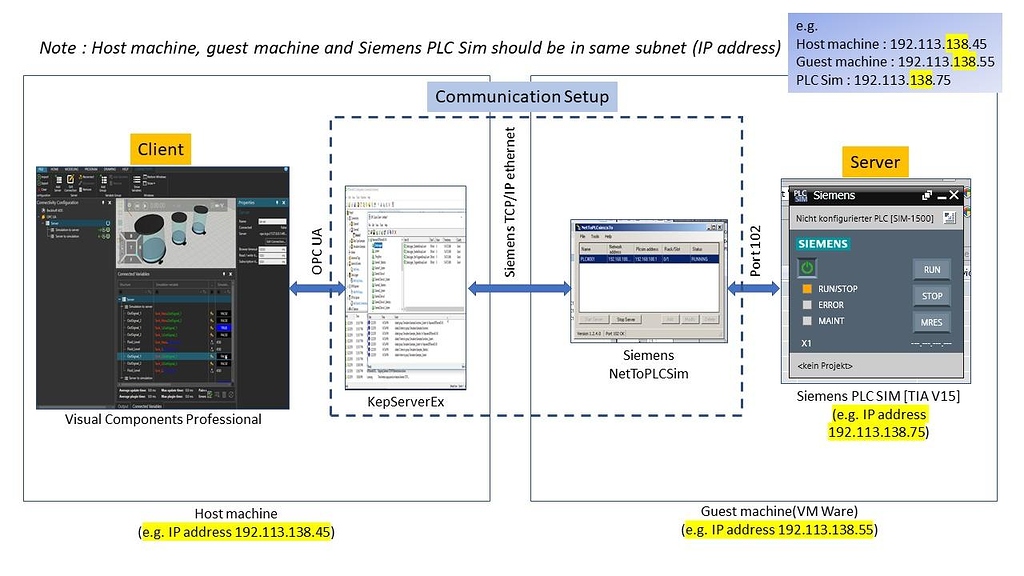
# 摘要
本文全面介绍了KEPServerEX扩展插件的概况、核心功能、实践案例、定制解决方案以及未来的展望和社区资源。首先概述了KEPServerEX扩展插件的基础知识,随后详细解析了其核心功能,包括对多种通信协议的支持、数据采集处理流程以及实时监控与报警机制。第三章通过
【Simulink与HDL协同仿真】:打造电路设计无缝流程

# 摘要
本文全面介绍了Simulink与HDL协同仿真技术的概念、优势、搭建与应用过程,并详细探讨了各自仿真环境的配置、模型创建与仿真、以及与外部代码和FPGA的集成方法。文章进一步阐述了协同仿真中的策略、案例分析、面临的挑战及解决方案,提出了参数化模型与自定义模块的高级应用方法,并对实时仿真和硬件实现进行了深入探讨。最
高级数值方法:如何将哈工大考题应用于实际工程问题
# 摘要
数值方法作为工程计算中不可或缺的工具,在理论研究和实际应用中均显示出其重要价值。本文首先概述了数值方法的基本理论,包括数值分析的概念、误差分类、稳定性和收敛性原则,以及插值和拟合技术。随后,文章通过分析哈工大的考题案例,探讨了数值方法在理论应用和实际问
深度解析XD01:掌握客户主数据界面,优化企业数据管理

# 摘要
客户主数据界面作为企业信息系统的核心组件,对于确保数据的准确性和一致性至关重要。本文旨在探讨客户主数据界面的概念、理论基础以及优化实践,并分析技术实现的不同方法。通过分析客户数据的定义、分类、以及标准化与一致性的重要性,本文为设计出高效的主数据界面提供了理论支撑。进一步地,文章通过讨论数据清洗、整合技巧及用户体验优化,指出了实践中的优化路径。本文还详细阐述了技术栈选择、开发实践和安
Java中的并发编程:优化天气预报应用资源利用的高级技巧
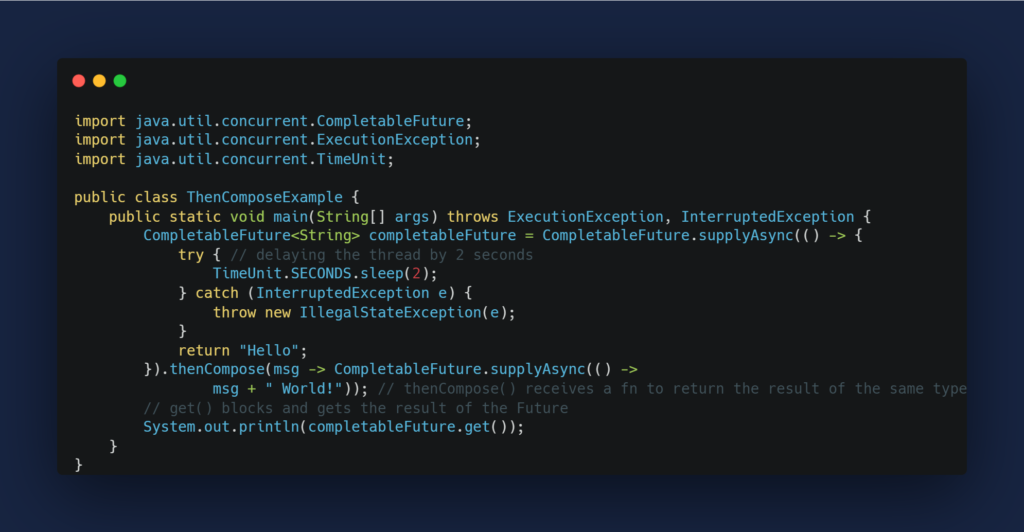
# 摘要
本论文针对Java并发编程技术进行了深入探讨,涵盖了并发基础、线程管理、内存模型、锁优化、并发集合及设计模式等关键内容。首先介绍了并发编程的基本概念和Java并发工具,然后详细讨论了线程的创建与管理、线程间的协作与通信以及线程安全与性能优化的策略。接着,研究了Java内存模型的基础知识和锁的分类与优化技术。此外,探讨了并发集合框架的设计原理和
计算机组成原理:并行计算模型的原理与实践
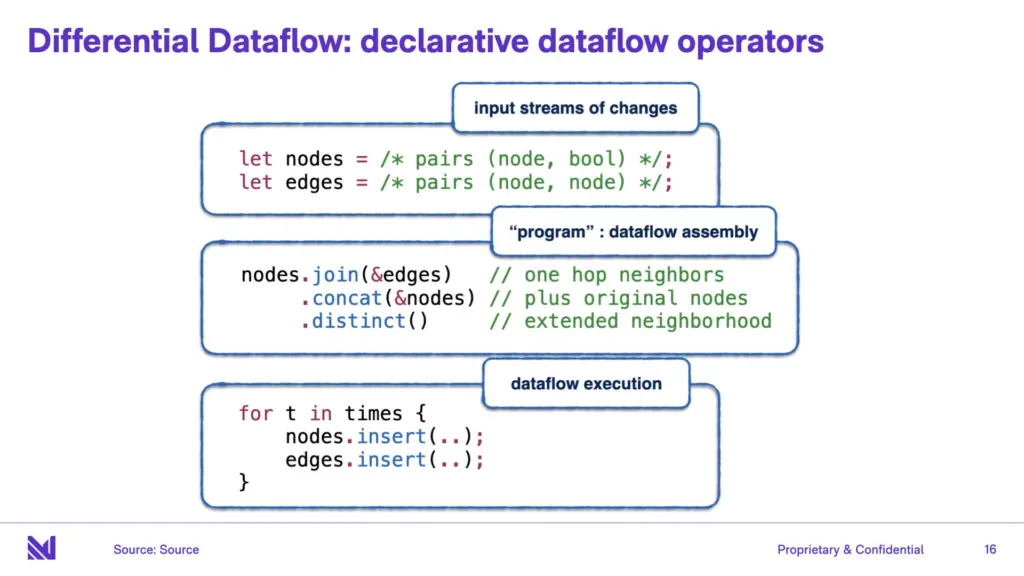
# 摘要
随着计算需求的增长,尤其是在大数据、科学计算和机器学习领域,对并行计算模型和相关技术的研究变得日益重要。本文首先概述了并行计算模型,并对其基础理论进行了探讨,包括并行算法设计原则、时间与空间复杂度分析,以及并行计算机体系结构。随后,文章深入分析了不同的并行编程技术,包括编程模型、语言和框架,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )