AWS Kinesis流式处理与数据分析
发布时间: 2024-01-07 06:43:19 阅读量: 43 订阅数: 23 
# 1. AWS Kinesis简介
## 1.1 什么是AWS Kinesis
AWS Kinesis是亚马逊Web服务(Amazon Web Services,AWS)提供的一项流式处理服务。它可以帮助用户高效地收集、处理和分析海量实时数据流,实现低延迟的数据处理和实时决策。
AWS Kinesis提供了三个核心组件:Kinesis数据流(Kinesis Data Streams)、Kinesis数据火箭(Kinesis Data Firehose)和Kinesis数据分析(Kinesis Data Analytics)。这些组件结合起来,构成了一整套完善的流式数据处理和分析解决方案。
## 1.2 Kinesis在流式处理中的作用
在传统的数据处理方案中,我们常常使用批处理的方式,周期性地对数据进行分析和处理。然而,随着互联网的快速发展,越来越多的数据以实时流的形式产生。传统的批处理方式已经无法满足对实时数据流的处理需求。
这时,AWS Kinesis就成为了一种强大的解决方案。它可以帮助我们接收、存储和处理来自多个数据源的实时数据流,并提供各种工具和服务,以便我们能够对这些数据进行快速、实时的分析和处理。
## 1.3 Kinesis与传统批处理的对比
与传统的批处理方式相比,Kinesis具有以下几点优势:
- 实时性:Kinesis能够以毫秒级的延迟接收和处理数据,实现真正的实时数据处理和决策。
- 弹性伸缩:Kinesis提供了自动伸缩的能力,可以根据实际的数据流量进行动态调整,确保系统的可靠性和高效性。
- 容错性:Kinesis具有高可用性和容错性,可以提供持久性的数据存储和数据保护机制,确保数据不会因为故障而丢失。
- 灵活性:Kinesis支持多种不同类型的数据流,包括结构化数据、半结构化数据和非结构化数据,能够满足不同应用场景的需求。
通过以上对比,我们可以看出,Kinesis在处理实时数据流方面具有明显的优势,为我们提供了更加灵活、高效和可靠的流式处理解决方案。
# 2. Kinesis基本概念
### 2.1 Kinesis数据流
Kinesis数据流是AWS提供的一种可持久化、可伸缩的实时数据流服务。它允许您收集和处理大量实时数据,如日志、事件和传感器读数,并即时分析这些数据。Kinesis数据流具有高吞吐量和低延迟的特点,可以处理高频率的数据输入和输出。
```python
// 创建Kinesis数据流
import boto3
kinesis = boto3.client('kinesis')
response = kinesis.create_stream(
StreamName='my-stream',
ShardCount=1
)
print(response)
```
代码解释:
- 第1行: 导入boto3库,用于连接AWS的Kinesis服务。
- 第3行: 创建Kinesis客户端实例。
- 第4-8行: 调用`create_stream`方法创建一个名为`my-stream`的数据流,指定数据流中的分片数为1。
- 第9行: 打印创建数据流的响应。
结果输出:
```
{
'ResponseMetadata': {
'RequestId': 'xxxx',
'HTTPStatusCode': 200,
'HTTPHeaders': {
'x-amzn-requestid': 'xxxx',
...
},
'RetryAttempts': 0
}
}
```
### 2.2 Kinesis数据火箭
Kinesis数据火箭是一种用于发送数据到Kinesis数据流的工具。它可以收集各种数据源(如日志文件、数据库变更等)中的数据,并将其实时发送到数据流中。
```java
// 使用Java SDK构建Kinesis数据火箭
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.kinesis.KinesisClient;
import software.amazon.awssdk.services.kinesis.model.PutRecordRequest;
import software.amazon.awssdk.services.kinesis.model.PutRecordResponse;
public class KinesisDataRocket {
public static void main(String[] args) {
Region region = Region.US_WEST_2;
KinesisClient kinesisClient = KinesisClient.builder().region(region).build();
String streamName = "my-stream";
String partitionKey = "partition-1";
String data = "Hello, Kinesis!";
PutRecordRequest putRecordRequest = PutRecordRequest.builder()
.streamName(streamName)
.partitionKey(partitionKey)
.data(SdkBytes.fromUtf8String(data))
.build();
PutRecordResponse putRecordResponse = kinesisClient.putRecord(putRecordRequest);
System.out.println("Put record: " + putRecordResponse.toString());
}
}
```
代码解释:
- 第6行: 设置所在的AWS区域为US West (Oregon)。
- 第7行: 创建Kinesis客户端实例。
- 第9-11行: 定义发送数据的数据流名称、分区键和数据内容。
- 第13-18行: 构建`PutRecordRequest`对象,并传入数据流名称、分区键和数据内容。
- 第20行: 调用`putRecord`方法发送数据到数据流中,并获取响应。
- 第21行: 打印发送数据的响应。
结果输出:
```
Put record:
{kinesisResponseMetadata={.isSuccessful=true, kinesisRequestId=xxxx, responseAttributes=null}}
```
### 2.3 Kinesis数据分析
Kinesis数据分析可以帮助您实时处理和分析Kinesis数据流中的数据。您可以使用Amazon Kinesis Data Analytics服务创建和运行SQL查询,对实时数据进行过滤、聚合和转换,并从中获得有价值的信息。
```javascript
// 使用JavaScript通过Kinesis数据分析查询数据
const AWS = require('aws-sdk');
AWS.config.update({region: 'us-west-2'});
const kinesisAnalytics = new AWS.KinesisAnalytics();
const params = {
ApplicationName: 'my-analytics-app',
RecordFormat: 'CSV',
RoleARN: 'arn:aws:iam::XXX:role/service-role/KinesisAnaly
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"aws认证概述"为题,系统地介绍了在AWS云计算平台上的各种认证文档,并涵盖了众多关键课题。从AWS基础认证到高级安全,从基础设施即代码部署到容器化技术,从监控运维到物联网应用开发,本专栏一一详解了AWS认证考试所需的知识点和实践技巧。专栏内部包含了《AWS基础认证考试指南》、《AWS身份和访问管理IAM详解》、《AWS EC2实例的部署和管理》、《深入了解AWS S3存储服务》等文章,完整地覆盖了AWS认证考试要求的各项知识点和技能。通过本专栏的学习,读者将能够全面掌握AWS云计算平台的各项服务和功能,为通过AWS认证考试打下坚实基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MySQL 5.6新特性深度剖析】:解锁升级关键,助你领先一步

# 摘要
MySQL 5.6作为数据库领域的重要更新,引入了多项新特性以增强其性能、可用性和扩展性。本文对MySQL 5.6的存储引擎与优化器的改进、高可用性与复制功能的增强、以及分区表和并行查询处理的扩展等方面进行了深入探讨。同时,文章分析了性能模式、信息模式的扩展和编程接口(API)的改进,并通过实践案例分析,展示了如何部署和优化My
【ADS雷达TR组件设计速成】:零基础到专家的进阶路径
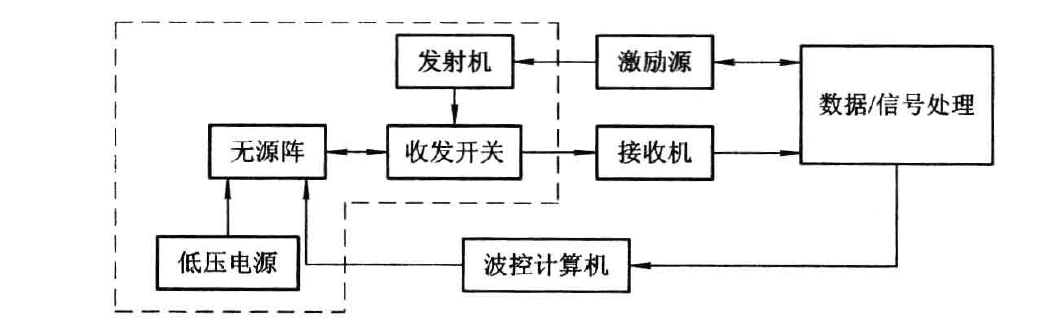
# 摘要
本文全面介绍了ADS雷达TR组件的基础概念、设计原理与方法、设计实践,以及高级话题和案例研究。首先,我们从功能与结构入手,详细阐述了TR组件的工作原理和技术参数。接着,探讨了TR组件信号处理过程中的放大、调制、接收与解调技术,并给出了详细的设计流程,包括需求分析、系统设计、硬件选择与布局规划。在设计实践中,文章讨
SITAN算法核心揭秘:深入理解PWM信号调制原理及其应用
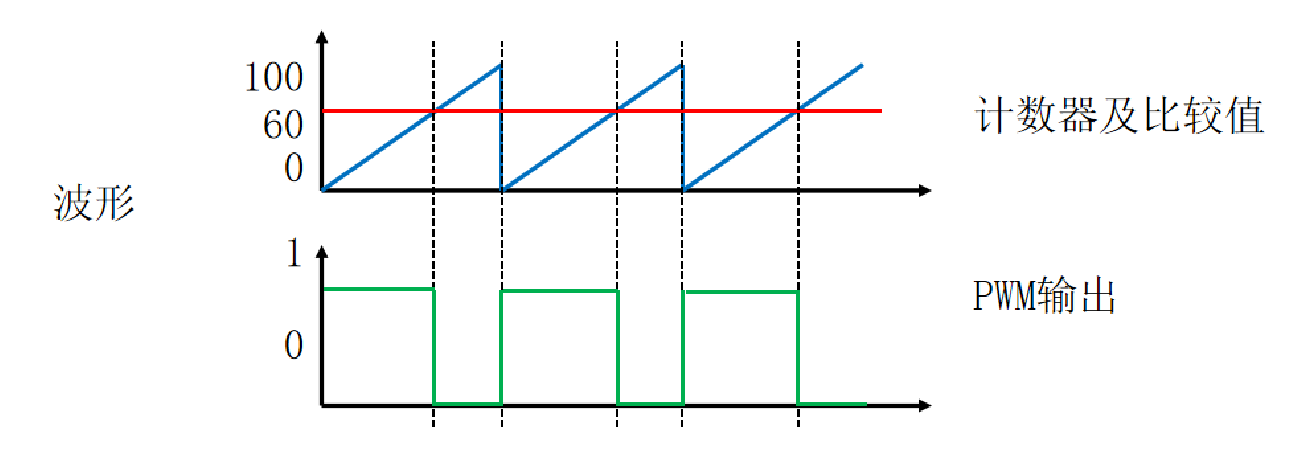
# 摘要
本文综合介绍了SITAN算法与PWM(脉冲宽度调制)信号调制的基本原理和应用实践。首先概述了SITAN算法和PWM信号调制的基础知识,包括SITAN算法的工作机制及其与传统算法的比较。随后,深入探讨了PWM信号的理论基础,包括其定义、关键参数以及数学模型,并着重分析了调制频率和占空比对信号性能的影响。第三部分则重点讲述SITAN算法在PWM调制中的应用,以及在电力电子领域中的具体案例分析。最后,文中探讨了P
【机器人编程实战】:揭秘RAPID指令在工业自动化中的高效运用

# 摘要
机器人编程是自动化技术的核心,其中RAPID语言因其专用性和高效性,在工业机器人领域得到了广泛应用。本文首先介绍机器人编程的基础知识和RAPID语言的基本概念,随后深入探讨了RAPID编程的数据结构、模块使用、控制指令、错误处理、并发编程等关键要素。通过实战演练,本文分
深入解读MIPI屏规格书:M101WXBI40-02A-280-2.6-V1.0案例研究
# 摘要
本文旨在详细介绍MIPI接口在显示屏领域的应用及其重要性,重点分析了M101WXBI40-02A-280-2.6-V1.0屏的硬件规格,软件驱动开发要点,以及在嵌入式系统中的应用部署。通过对该屏的物理参数、性能指标、通信协议及接口时序的详细解析,阐述了其在图像渲染、显示控制、电源管理和节能特性方面的主要技术特点。同时,本文还介绍了该屏在实际应用中的案例研究,提供了性能测试与分析,以及应用优化策略。最后,展望了MIPI屏技术的未来发展趋势,讨论了与新兴技术的融合以及环境与健康方面的考量。
# 关键字
MIPI接口;显示屏;硬件规格;软件驱动;性能测试;技术发展展望
参考资源链接:[
【Minitab16终极指南】:解锁统计分析的秘密武器
# 摘要
本文全面介绍了Minitab 16统计分析软件的功能与应用。首先概述了Minitab 16的界面布局和基础操作,接着深入探讨了其在进行基本统计分析、回归分析、方差分析以及质量控制等方面的高级分析方法。通过具体案例,文章展现了Minitab 16在工业制造、医疗健康和金融市场等领域的实际应用,并提出了一系列提升分析效率和准确性的操作技巧与最佳实践。最后,本文还讨论了Minit
【Faro Focus3D速成秘籍】:3步带你从零基础到实战专家

# 摘要
本文全面介绍了Faro Focus3D三维激光扫描仪的特点、基础理论、操作方法及高级应用。首先,概述了Focus3D扫描仪的功能及其在三维激光扫描领域中的应用。接着,探讨了三维激光扫描的基础理论,包括工作原理、优势分析以及数据处理流程。文章第三章重点阐述了Focus3D的实际操作方法,如设备操作、现场扫描技巧和数据管理。在案例分析部分,本文深入研究了
C++科学计算库的精选手册:从BLAS到自定义算法的深度解析

# 摘要
本文旨在探讨C++科学计算库的多个方面,从基础线性代数子程序库(BLAS)开始,详细介绍了其架构、功能及性能优化,并展示了在C++项目中的应用。随后,文章深入探讨了LAPACK库在数值线性代数中的应用和自定义算法的实现,以及并行计算库的使用和性能评估。最后,本文总结了现
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )